










关于redis的安装与配置我之前有文章详细的介绍过,参考:https://blog.csdn.net/qq_41604569/article/details/123644888
今天我们主要聊下redis与python的结合,两大部分内容:
- redis使用
- redis + python 使用
在redis +python中,也会分为两部分来解读:
- redis + python本身的交互
- redis + django的交互
redis使用
环境:Windows 本地调试;
默认端口:6379;
1.开启服务
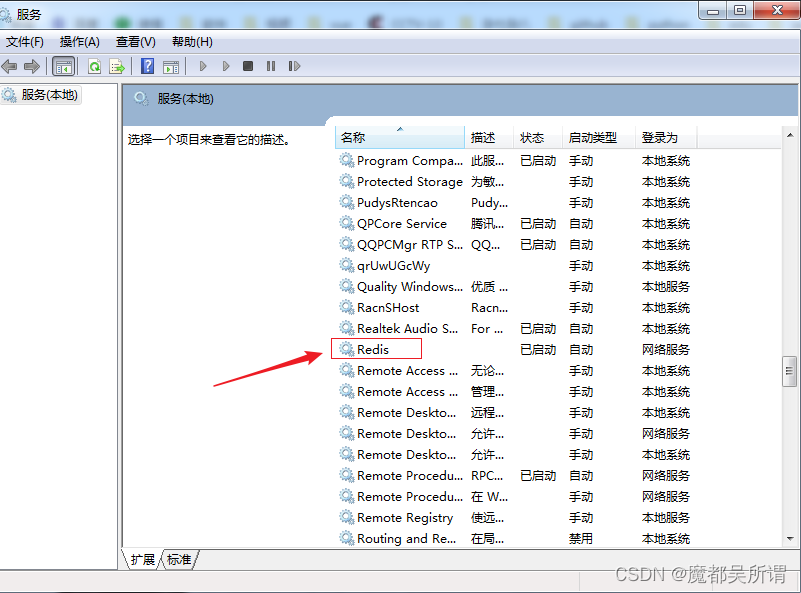
1.开启redis服务【前文有介绍】,这里只看下有没有开启服务,操作方法:
win+r === > services.msc === > 调出“服务”,找到redis,看下状态是否为:已启动;如果不是,查找原因;
客户端连接redis服务器
cmd:redis-cli.exe
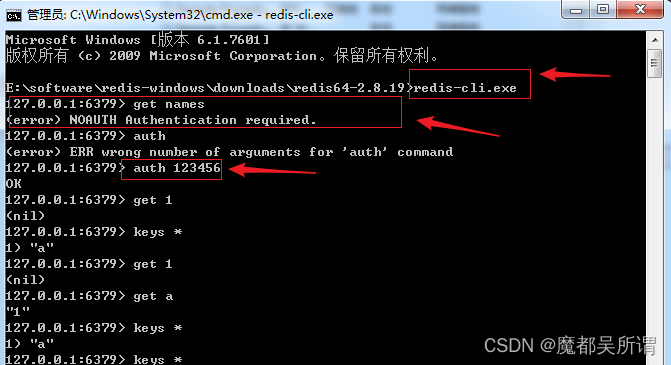
启动服务端后,获取下数据get names,提示:(error) NOAUTH Authentication required.没有权限;
使用命令:auth 13456 登录,这里的123456是我自己设置的redis密码;
登录成功之后就可以操作redis了;
2.简要介绍
redis是一种高级的键值对key:value存储系统,非关系型数据库(Nosql),其中value支持五种数据类型:
1.字符串(strings)
2.字符串列表(lists)
3.字符串集合(sets)
4.有序字符串集合(sorted sets)
5.哈希(hashes)
这节内容不做详细展开,仅就字符串 数据类型举例,其常用的两种方法:set与get
127.0.0.1:6379> set name wusuowei
OK
127.0.0.1:6379> get name
"wusuowei"
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> get age
"18"
通过上面,比较清晰的看出,redis设置与读取数据的格式,set:用作设置,get:用作读取;
情况redi缓存命令:
flushall : 清空之后,在获取返回(nil)表示空值;
实例:
127.0.0.1:6379> set name wusuowei
OK
127.0.0.1:6379> get name
"wusuowei"
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> get age
"18"
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379>
redis + python 使用
redis + python本身的交互
1.安装:
pip install redis
2.连接:
常用两种方式:
方式一:普通连接【与python连接mysql类似】
import redis # 导入redis模块
r = redis.Redis(host='localhost', port=6379, password="123456",
decode_responses=True)
# key是"name" value是"wusuowei" 将键值对存入redis缓存
r.set('name', 'wusuowei')
print(r['name'])
print(r.get('name')) # 取出键name对应的值
print(r.get('age')) # 取出键name对应的值
print(type(r.get('name')))
# wusuowei
# wusuowei
# None
# <class 'str'>
方式二:连接池 【connection pool】
好处:
默认,每个Redis实例都会维护一个自己的连接池;使用连接池来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。
import redis
# 建立redis的连接池
Pool = redis.ConnectionPool(host='127.0.0.1', port=6379, password="123456", decode_responses=True, max_connections=10)
# 从池子中拿一个链接
r = redis.Redis(connection_pool=Pool)
r.set('name', 'wusuowei') # key是"name" value是"wusuowei" 将键值对存入redis缓存
print(r['name'])
print(r.get('name')) # 取出键name对应的值
print(r.get('age')) # 取出键name对应的值
# wusuowei
# wusuowei
# None
redis + django的交互
1.安装:
pip install django-redis
2.连接:
进入Django shell模式:python manage.py shell
导包:
from django.core.cache import cache
(env) E:\java_pythProject>python manage.py shell
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from django.core.cache import cache
>>> cache.set('name','wusuowei')
True
>>> cache.get('name')
'wusuowei'
>>> cache.get('age')
>>> exit()
(env) E:\java_pythProject>
这里就简单介绍了下redis+python的简单使用,涉及内容不多,很容易消化,大家空闲时间多看看,see you~~~
















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











