










事例一: 单字典排序
描述:一个字典有多对键值组成,将其按照键进行排序、按照值进行排序等场景,直接看代码:
a = {'2': 'b', '5': 'e', '1': 'a'}
print(sorted(a.items(), key=lambda x: x[0], reverse=False)) # 按键排序 小到大
print(sorted(a.items(), key=lambda x: x[0], reverse=True)) # 按键排序 大到小
print(sorted(a.items(), key=lambda x: x[1], reverse=False)) # 按值排序 小到大
print(sorted(a.items(), key=lambda x: x[1], reverse=True)) # 按值排序 大到小
print(sorted(a.keys(), key=lambda x: x[0], reverse=False)) # 只对键排序 小到大
print(sorted(a.keys(), key=lambda x: x[0], reverse=True)) # 只对键排序 大到小
# 结果
'''
[('1', 'a'), ('2', 'b'), ('5', 'e')]
[('5', 'e'), ('2', 'b'), ('1', 'a')]
[('1', 'a'), ('2', 'b'), ('5', 'e')]
[('5', 'e'), ('2', 'b'), ('1', 'a')]
['1', '2', '5']
['5', '2', '1']
'''
上面的多种排序形式都完成了单字典的排序,观察细心的小伙伴想必一定发现了:1.原字典给我们的数据类型都是字典形式;2.我们获取到的结果都是列表嵌套元祖形式;这两点很明显不太符合我们实际的预期,一般场景下都是你给我什么数据类型,我返回给你什么数据类型,鉴于这一点,我们可以将获取到的结果做下简单的数据加工即可,现在单独拿第一个按键排序 小到大为例来单独说下怎么获取到一个字典的结果,具体的代码:
方法一:中规中矩式
a = {'2': 'b', '5': 'e', '1': 'a'}
res = sorted(a.items(), key=lambda x: x[0], reverse=False)
print(res) # [('1', 'a'), ('2', 'b'), ('5', 'e')]
res_dict = {} # 收集结果的空字典
for i in res:
res_dict[i[0]] = i[1]
print(res_dict) # {'1': 'a', '2': 'b', '5': 'e'}
方法二:一步到位式
a = {'2': 'b', '5': 'e', '1': 'a'}
res = sorted(a.items(), key=lambda x: x[0], reverse=False)
print(res)
print(dict(res))
'''
[('1', 'a'), ('2', 'b'), ('5', 'e')]
{'1': 'a', '2': 'b', '5': 'e'}
'''
这样我们通过上面两种方式都完成了数据类型的转化,优势已经很明显看的出来~~~;
事例二:列表字典排序
单条件
python 中在做排序中会有不少场景涉及到列表字典嵌套相关操作,比如这里有一个学生及其成绩对应的数据:
[
{'name': 'zhangsan', 'score': 69},
{'name': 'lisi', 'score': 89},
{'name': 'wangwu', 'score': 98},
{'name': 'wusuowei', 'score': 60},
{'name': 'zhouliu', 'score': 49},
{'name': 'tianqi', 'score': 30},
]
这么一串数据按score进行从高到低排序,如何进行排序呢~~~
品代码:
s = [
{'name': 'zhangsan', 'score': 69},
{'name': 'lisi', 'score': 89},
{'name': 'wangwu', 'score': 98},
{'name': 'wusuowei', 'score': 60},
{'name': 'zhouliu', 'score': 49},
{'name': 'tianqi', 'score': 30},
]
res1 = sorted(s, key=lambda i: i['score']) # 按score从小到大
res2 = sorted(s, key=lambda i: i['score'], reverse=False) # 按score从小到大
res3 = sorted(s, key=lambda i: i['score'], reverse=True) # 按score从大到小
res4 = sorted(s, key=lambda i: -i['score']) # 按score从大到小
print(res2)
print(res2) # 可以看出reverse的默认值就是False
print(res3)
print(res4)
结果:
[{'name': 'tianqi', 'score': 30}, {'name': 'zhouliu', 'score': 49}, {'name': 'wusuowei', 'score': 60}, {'name': 'zhangsan', 'score': 69}, {'name': 'lisi', 'score': 89}, {'name': 'wangwu', 'score': 98}]
[{'name': 'tianqi', 'score': 30}, {'name': 'zhouliu', 'score': 49}, {'name': 'wusuowei', 'score': 60}, {'name': 'zhangsan', 'score': 69}, {'name': 'lisi', 'score': 89}, {'name': 'wangwu', 'score': 98}]
[{'name': 'wangwu', 'score': 98}, {'name': 'lisi', 'score': 89}, {'name': 'zhangsan', 'score': 69}, {'name': 'wusuowei', 'score': 60}, {'name': 'zhouliu', 'score': 49}, {'name': 'tianqi', 'score': 30}]
[{'name': 'wangwu', 'score': 98}, {'name': 'lisi', 'score': 89}, {'name': 'zhangsan', 'score': 69}, {'name': 'wusuowei', 'score': 60}, {'name': 'zhouliu', 'score': 49}, {'name': 'tianqi', 'score': 30}]
多条件
刚才演示一个按照某一个key进行排序的事例,实际生产过程中难免会遇到按照多个key进行排序的场景,上数据:
s = [
{'name': 'zhangsan', 'score': 69, 'age': 18},
{'name': 'lisi', 'score': 89, 'age': 14},
{'name': 'wangwu', 'score': 98, 'age': 16},
{'name': 'wusuowei', 'score': 60, 'age': 17},
{'name': 'zhouliu', 'score': 49, 'age': 15},
{'name': 'tianqi', 'score': 30, 'age': 19},
{'name': 'wangjiu', 'score': 30, 'age': 18},
{'name': 'qiansan', 'score': 30, 'age': 20},
]
数据解读:
每一行数据代表一个样本,每一列数据代表一个属性;
我们先回顾下刚才的事例,按某一个值进行排序,这里举例还按score进行排序,代码:
res1 = sorted(s, key=lambda i: (i['score'])) # 按score从小到大
print(res1)
结果:
[{'name': 'tianqi', 'score': 30, 'age': 19},
{'name': 'wangjiu', 'score': 30, 'age': 18},
{'name': 'qiansan', 'score': 30, 'age': 20},
{'name': 'zhouliu', 'score': 49, 'age': 15},
{'name': 'wusuowei', 'score': 60, 'age': 17},
{'name': 'zhangsan', 'score': 69, 'age': 18},
{'name': 'lisi', 'score': 89, 'age': 14},
{'name': 'wangwu', 'score': 98, 'age': 16}]
很明显看的出来是按照score从小到大进行了排序,但是我们还发现了一个问题就是在出现相同score=30的时候排序就没有规律可言了:
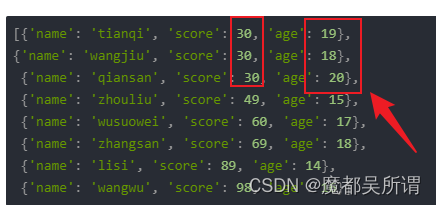
这个结果一般还没处理到最后。还是可以做进一步的数据优化,来完成这一部分排序,让结果显得更有序~~~,那就开始干吧:
代码:
res1 = sorted(s, key=lambda i: (i['score'], i['age'])) # 按score从小到大
print(res1)
结果:
[
{'name': 'wangjiu', 'score': 30, 'age': 18},
{'name': 'tianqi', 'score': 30, 'age': 19},
{'name': 'qiansan', 'score': 30, 'age': 20},
{'name': 'zhouliu', 'score': 49, 'age': 15},
{'name': 'wusuowei', 'score': 60, 'age': 17},
{'name': 'zhangsan', 'score': 69, 'age': 18},
{'name': 'lisi', 'score': 89, 'age': 14},
{'name': 'wangwu', 'score': 98, 'age': 16}]
在排序时多做了一个条件过滤:
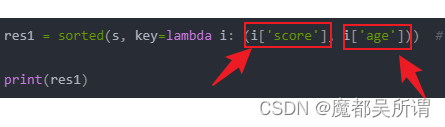
结果上排序也明显的看的出来:

欢迎关注v x 公众号:魔都吴所谓
有什么问题后台留言

















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











