









目录
易混淆

3.5指针
指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。就像其他变量或常量一样
注意:
指针类型存储的是所指向变量的地址,所以32位机器只需要32bit,而64位机器需要64bit。
同一设备下,指针类型的字节长度都是一样的,32位机器为32bit,及8byte;64位机器同理,64bit,16byte。
以下以32位机器作为演示:
printf("int * = %d\n",sizeof(int *));
printf("char * = %d\n",sizeof(char *));
printf("short * = %d\n",sizeof(short *));
printf("long * = %d\n",sizeof(long *));
printf("float * = %d\n",sizeof(float *));
printf("double * = %d\n",sizeof(double *));
int * = 4;
char * = 4;
short * = 4;
long * = 4;
float * = 4;
double * = 4;此例子足以证明上述内容。64位机器输出结果为8
指针在内存中是如何储存的呢?以0xff00储存int为例

指针也是储存在内存中,也有对应的指向储存指针内存的指针,只不过这个储存在内存中的是地址。
关于指针的定义方式,及为什么要如此定义
指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。指针变量声明的一般形式为:
type *var-name;关于type可以分为两种,第一种为常规数据类型,第二种为void,及万能指针。
指针在内存中占用的字节数和操作系统有关,与指针的类型无关,那么定义指针变量的时候,为什么要指定数据类型呢?如果指定为void又该如何使用该指针呢?
关于第一个问题
其一:
指定指针的类型,是为了方便操作该指针指向的这段内存中的内容,输出或改变指针指向的内存中的内容,需要知道这段内容的数据类型。
以int为例:
int a = 10;//定义整形变量a
int * p = &a;//定义指针,并指向int型变量a
*p = 20;//修改a为20 
//变量a的地址
printf("Address of a variable: %p\n", &a );
//在指针变量中存储的地址 ,其中%p表示输出指针的值
printf("Address stored in p variable: %p\n", p );//假设程序输出如下:
Address of a variable: ff00
Address stored in p variable: ff00通过打印p,我们可以知道,p为0xff00,那么p只是保存了a的首地址,在*p= 20;操作时,系统该如何判断,到底该修改对少字节内存中的数据?这个时候就要看p的数据类型了,这也是为什么我们要声明指针数据类型的原因了,在修改所指向内存中的内容时,我们需要知道,我们应该修改多少个字节中内存中的内容。
再举一个例子,打印数组的例子,字符串
其二:
输出阶段,我们注意printf的输出格式
printf("<格式化字符串>", <参量表>);其中参量表代表的就是指向该内存的首地址(大部分),而格式化字符串中,也是表明从首地址开始,要包含多少个字节,以什么变量形式,输出内容。
综上,这就是为什么要声明指针变量的数据类型。
那么在使用new申请指针空间的时候,有一些细节需要注意:
int *p1 = new int[10];
int *p2 = new int[10](); P1申请的空间是随机值,而P2申请的空间已经初始化,这是非常少见的一种定义方法。
3.5.1万能指针
万能指针的赋值和常规其他指针一样,但是其他操作稍有不同。
定义方式如下:
void * p;在进行赋值操作的时候要务必注意,需要对其类型进行强制转换:
int b = 10;//定义变量
void * p = &b;//定义万能指针,并完成初始化
*(int *)p = 100;//修改b的内容
printf("%d\n",b);
printf("%d\n",*(int *)p);输出结果如下:
100
100
关于万能指针的赋值,可以在定义阶段就进行赋值,因为p不管是什么类型,都是只保存首地址,而指针类型的大小又是和操作系统有关,所以不管数量类型,&变量 = 指针,在一台操作系统中,这是一个恒等式,&变量也是找出该变量内存的首地址,等式两边内存占用的字节数是相同的,所以完全可以这样赋值。
其中,因为必须要指定指针的数据类型,所以对于万能指针,在其他操作的时候需要强制转换类型:
首先,先强制转换类型:(int *)p,将其转换为int类型,告诉计算机,之后的操作,需要对连续四个字节进行操作。
其次,再访问其内存指向的内容并修改,*(int *)p=100;

3.5.2指针和数组
注意:
1:数组名是常量,不能修改
2:数组名是数组的首地址——是数组第一个元素的地址,可以使用指针来代替数组进行操作(此行为称为指针的降级操作)
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int * p = arr;
int num = sizeof(arr)/sizeof(int);
for(int i = 0;i<num;i++)
{
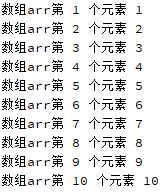
qDebug()<<"数组arr第"<<i+1<<"个元素"<<p[i];
}输出结果:
其中sizeof关键字的解释,后面会再次强调。
除此之外,还可以利用指针加减来进行输出:
3.5.3关于指针的加减
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int * p = arr;
int num = sizeof(arr)/sizeof(int);
for(int i = 0;i<num;i++)
{
qDebug()<<"数组arr第"<<i+1<<"个元素"<<*(p+i);
}输出如下:

注意两次使用指针的方式:
qDebug()<<"数组arr第"<<i+1<<"个元素"<<p[i];
qDebug()<<"数组arr第"<<i+1<<"个元素"<<*(p+i);p指向的是某段内存的地址,并且其数据类型为int *,对指针的加减,相当于移动这个指针
一个类型为 T 的指针的移动,以 sizeof(T) 为移动单位。 原理是c语言中的指针加减后,会根据指针的类型采用不同的偏移量。
int* a;int* b = a+1;则 b - a = sizeof(int)
char* a; char* b = a+1; 则b - a = sizeof(char) 下面解释一下通过*(p+1)是如何遍历整个数组的:
首先输出一下地址:
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int * p = arr;
int num = sizeof(arr)/sizeof(int);
for(int i = 0;i<num;i++)
{
qDebug()<<"数组arr第"<<i+1<<"个元素"<<*(p+i)<<"地址为(1):"<<p+i<<"地址为(2):"<<arr+i;
} 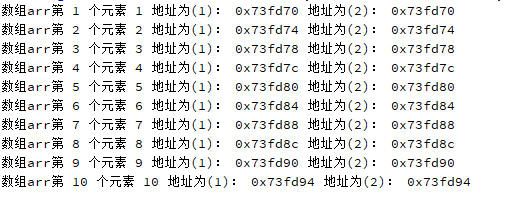
实际的储存方式也是如此,arr为数组名,指向第一个元素的地址,将arr的地址赋值给p后,p和arr指向的都是相同内存段,保存着相同的地址,对arr/p进行移动(加/减)操作,都是根据其数据类型进行移动
因为都是int类型,所以一次地址加4( sizeof(int))

3.5.4指针和字符串(字符数组和字符指针)
在C语言中,字符数组存放在全局数据区或栈区,可读可写。字符指针存放在常量区,只读不能写。
char str1[] = "hello world";
char str2[] = "hello world"; char str1[] = "hello world";
char str2[] = "hello world";
qDebug()<<"str1:"<<str1;
qDebug()<<"str2:"<<str2;
str1[0] = 'a';
qDebug()<<"str1:"<<str1;输出:
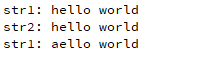
以上两个字符串是占用了不同的内存,而且是可以改变的。
char * str3 = "hello world";
char * str4 = "hello world";无法修改,为常量。只可以读,不可以写
程序会直接将hello world保存至常量区,所以str3和str4是相等的,指向同一块内存空间。
常量区中的内容一般无法修改,但是有些编译器是允许程序进行修改的。

关于字符数组的赋值过程:
①编译器现将hello world复制到常量区
②之后再将其内容复制到栈区或者其他分区(这个要看char str[]是在哪儿定义的了)
但是字符串指针不同,如果两个字符串指针赋予相同的字符串,只需要将指针指向相同的常量区地址即可。
char str1[] = "hello world";
char str2[] = "hello world";str1和str2占用的是不同的地址。
char * str3 = "hello world";
char * str4 = "hello world";str3和str4指向的是相同的地址。
3.5.5指针的步长及取值操作
3.5.3关于指针的加减中对此部分也有讲解:
一个类型为 T 的指针的移动,以 sizeof(T) 为移动单位。 原理是c语言中的指针加减后,会根据指针的类型采用不同的偏移量。
int* a;int* b = a+1;则 b - a = sizeof(int)
char* a; char* b = a+1; 则b - a = sizeof(char) 指针的类型,不单单决定了指针的步长,还决定解引用的时候从给定地址开始取类型大小的字节数(3.5一开始就有赘述此部分)
以下有两个例子
(1)
typedef struct
{
double T_a;
double T_b;
}T; T student;
qDebug()<<"student占用空间:"<<sizeof(student);
student.T_a = 1;
student.T_d = 10.11111;
qDebug()<<"通过指针的方式取出T_d的值:"<<* (double *)( (char *)&student + 4 );输出结果:
![]()
&student:取结构体的地址。
(char *):强制转换为char *类型,因为步长为1。
+ 4:因为要去double T_d中的内容,需要跳过int 类型的T_a。
之后强制转换类型为double ,并从中取值。
以上过程中
第一次类型转换是为了步长考虑。
第二次类型转换是为了取值告诉指针取多少个内存中的值 。
类也是一样的:
class Test{
public:
int a;
int b;
virtual void fun() {}
Test(int temp1 = 0, int temp2 = 0)
{
a=temp1 ;
b=temp2 ;
}
int getA()
{
return a;
}
int getB()
{
return b;
}
};
int main()
{
Test obj(5, 10);
// Changing a and b
int* pInt = (int*)&obj;
*(pInt+0) = 100;
*(pInt+1) = 200;
cout << "a = " << obj.getA() << endl;
cout << "b = " << obj.getB() << endl;
return 0;
}因为虚函数的问题,所以有一个四个字节的虚函数指针,所以:
*(pInt+0) = 100;指向的不是a,二十虚函数指针
*(pInt+1) = 200;pInt是int类型,步长4个字节,所以这句话才是给a赋值的语句
b的变量没有变,所以,结果为200,10;b的值不变。
(2)
char buf[20] = { 0 };
int a = 100;
memcpy(buf+1,&a,sizeof(int));
char * p = buf;
printf("*(int * )(p3+1) = %d\n",*(int *)(p + 1));具体说明同上,结果 显然为100。
int *这个强制转换类型的过程,就是为了之后从p+1这个首地址开始,知道要从首地址开始,要往后偏移多少
参考内容:https://blog.csdn.net/on_1y/article/details/13030439
题目1:
main()
{char
str[][10]={"China","Beijing"},*p=str;
printf("%s\n",p+10);
}str定义为一个二维字符数组,即为str[2][10],p指向这个数组的首指针,那么p+10指向这个数组第二维的首指针,所以输出字符串为Beijng。
(来源牛客网@lgg1205)
题目2:
int main(int argc, char **argv)
{
int a[4] = {1, 2, 3, 4};
int *ptr = (int *)(&a + 1);
printf("%d", *(ptr - 1));
}&a+1,因为sizeof(a) = 16,补偿是16个字节,一次加一操作,走过4个int类型的变量。
所以直接ptr目前指向的a[3] 后面的位置,自然,ptr-1就是指向a[3]
题目1和题目2区别在于,指向数字的指针,sizeof(int*) = 4,而数字名本身,sizeof(a) = 16;步长是完全不一样的。
3.5.6指针和函数
指针做函数参数:
- 输入:主调函数分配内存
- 输出:被调函数分配内存
函数,数组名作为参数,指针作为参数,指针作为返回值
题目:
void foobar(int a, int *b, int **c)
{
int *p = &a;
*p = 101;
*c = b;
b = p;
}
int main()
{
int a = 1;
int b = 2;
int c = 3;
int *p = &c;
foobar(a, &b, &p);
printf("a=%d, b=%d, c=%d, *p=%d\n", a, b, c, *p);
return (0);
}a=1, b=2, c=3, *p=2a传递的是值,没有任何影响
b传递的是指针,但是到了函数里面,没有尝试*b,修改b的值的操作
p传递的是指针,在函数中修改了指向,将其指向了b
3.5.7二级指针

int a = 10;
int * p = &a;
int ** pp = &p;
qDebug()<<"a的值:"<<a<<"a的地址:"<<&a;
qDebug()<<"p的值:"<<p<<"p的地址:"<<&p;
qDebug()<<"pp的值:"<<pp<<"pp的地址:"<<&pp;
qDebug()<<"p的值:"<<*pp;
qDebug()<<"a的值"<<**pp;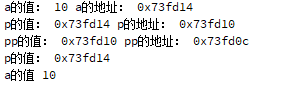
从以上内容即可看出:
一级指针指向普通变量的地址
二级指针指向一级指针的地址。
取值则是一个不断从嵌套的盒子中取出东西的过程。
在函数传参中,又是需要传递一级指针的地址,此时需要二级指针作为参数去进行接收。
void allocataSpace(char **pp)
{
char * temp = malloc(100);
memset(temp,0,100);
strcpy(temp,"hello world");
*pp = temp;
}
void test()
{
char * p = NULL;
allocataSpace(&p);
printf("p = %s\n",p);
}题目:
int main(void)
{
char *p[]={“TENCENT”,”CAMPUS”,”RECRUITING”};
char **pp[]={p+2,p+1,p};
char ***ppp=pp;
printf(“%s”,**++ppp);
printf(“%s”,*++*++ppp);
return 0;
} 
此题最坑的是,第二个printf中的ppp,是在第一条的基础上的。
答案:CAMPUS CAMPUS
3.5.8指针和数组再理解(数组指针)
int Array_a[4] = {0,1,2,3};
int Array_Da[4][5] =
{
{0,1,2,3,4},
{10,11,12,13,14},
{20,21,22,23,24},
{30,31,32,33,34}
};
qDebug()<<endl<<"一维数组大小,sizeof(Array_a):"<<sizeof(Array_a)
<<endl<<"一维数组大小,sizeof(Array_a)/sizeof(int):"<<sizeof(Array_a)/sizeof(int)
<<endl<<"一维数组,数组名:"<<Array_a
<<endl<<"一维数组,数组名取地址:"<<&Array_a
<<endl<<"一维数组,第一个元素的地址:"<<&Array_a[0]
<<endl<<"一维数组,数组名步长:"<<(char *)(Array_a+1) - (char *)Array_a
<<endl<<"一维数组,数组名取地址步长:"<<(char *)(&Array_a+1) - (char *)(&Array_a)
<<endl<<"通过坐标访问数组元素Array_a[0]:"<<Array_a[0]
<<endl<<"通过指针访问数组元素*Array_a(解引用):"<<*Array_a
<<endl;
qDebug()<<"二维数组大小,sizeof(Array_Da):"<<sizeof(Array_Da)
<<endl<<"一维数组大小,sizeof(Array_Da)/sizeof(int):"<<sizeof(Array_Da)/sizeof(int)
<<endl<<"二维数组,数组名:"<<Array_Da
<<endl<<"二维数组,数组名取地址:"<<&Array_Da
<<endl<<"二维数组,第一个元素取地址:"<<&Array_Da[0][0]
<<endl<<"二维数组,第一行第一列元素地址方式1:"<<Array_Da[0]
<<endl<<"二维数组,第一行第一列元素地址方式2:"<<&Array_Da[0][0]
<<endl<<"二维数组,数组名步长:"<<(char *)(Array_Da+1) - (char *)Array_Da
<<endl<<"二维数组,数组名取地址步长:"<<(char *)(&Array_Da+1) - (char *)(&Array_Da)
<<endl<<"通过坐标访问数组元素Array_Da[0][0]:"<<Array_Da[0][0]
<<endl<<"通过指针访问数组元素*Array_Da(解引用):"<<*Array_Da
<<endl<<"通过指针访问数组元素*Array_Da[0](解引用):"<<*Array_Da[0];输出:

首先看一维数组:
int Array_a[4] = {0,1,2,3};
qDebug()<<endl<<"一维数组大小,sizeof(Array_a):"<<sizeof(Array_a)
<<endl<<"一维数组大小,sizeof(Array_a)/sizeof(int):"<<sizeof(Array_a)/sizeof(int)
<<endl<<"一维数组,数组名:"<<Array_a
<<endl<<"一维数组,数组名取地址:"<<&Array_a
<<endl<<"一维数组,第一个元素的地址:"<<&Array_a[0]
<<endl<<"一维数组,数组名步长:"<<(char *)(Array_a+1) - (char *)Array_a
<<endl<<"一维数组,数组名取地址步长:"<<(char *)(&Array_a+1) - (char *)(&Array_a)
<<endl<<"通过坐标访问数组元素Array_a[0]:"<<Array_a[0]
<<endl<<"通过指针访问数组元素*Array_a(解引用):"<<*Array_a
<<endl;
数组名就是指向数组第一个元素的指针,从对 Array_a[0] 和*Array_a就可以看出来,二者相同,从&Array_a[0] 和 Array_a也可以看出来。
关键问题在于
1:数组名取地址时:
"一维数组,数组名步长:"<<(char *)(Array_a+1) - (char *)Array_a
"一维数组,数组名取地址步长:"<<(char *)(&Array_a+1) - (char *)(&Array_a)输出:
![]()
需要强行转换类型,才能看出来到底步长是几个byte(字节),如果不进行强制类型转换 ,都是int类型指针或者数组指针,输出结果一定是1的。
从上述输出我们可以看出,数组名步长是4个字节,也就是一个int,言外之意,通过数组名,此时也是等价于指向数组首地址的指针,是可以通过步长的变化访问数组这段连续内存中的任意一个元素的。
qDebug()<<"第一个元素:"<<*Array_a
<<endl<<"第二个元素:"<<*(Array_a + 1)
<<endl<<"第三个元素:"<<*(Array_a + 2)
<<endl<<"第四个元素:"<<*(Array_a + 3)
<<endl;
但是,当数组名取地址的时候,步长是整个数组所占用的字节数,即16字节,此时,取地址后的数组名,指向的是整个数组
2:sizeof(数组名)
qDebug()<<endl<<"一维数组大小,sizeof(Array_a):"<<sizeof(Array_a)
<<endl<<"一维数组大小,sizeof(Array_a)/sizeof(int):"<<sizeof(Array_a)/sizeof(int)输出:
![]()
在以上两种情况中,数组名不是指针,所以数组名不完全等价于指向数组首地址的指针,以上情况就是唯二的特例。
再看二维数组:
qDebug()<<"二维数组大小,sizeof(Array_Da):"<<sizeof(Array_Da)
<<endl<<"一维数组大小,sizeof(Array_Da)/sizeof(int):"<<sizeof(Array_Da)/sizeof(int)
<<endl<<"二维数组,数组名:"<<Array_Da
<<endl<<"二维数组,数组名取地址:"<<&Array_Da
<<endl<<"二维数组,第一个元素取地址:"<<&Array_Da[0][0]
<<endl<<"二维数组,第一行第一列元素地址方式1:"<<Array_Da[0]
<<endl<<"二维数组,第一行第一列元素地址方式2:"<<&Array_Da[0][0]
<<endl<<"二维数组,数组名步长:"<<(char *)(Array_Da+1) - (char *)Array_Da
<<endl<<"二维数组,数组名取地址步长:"<<(char *)(&Array_Da+1) - (char *)(&Array_Da)
<<endl<<"通过坐标访问数组元素Array_Da[0][0]:"<<Array_Da[0][0]
<<endl<<"通过指针访问数组元素*Array_Da(解引用):"<<*Array_Da
<<endl<<"通过指针访问数组元素*Array_Da[0](解引用):"<<*Array_Da[0];输出:

从二维数组中,可以看出,二维数组更像是两个一维数组的嵌套,
第一层Arrary_Da[X]保存的是Arrary_Da[X][Y]首元素的地址,相当于一层指针层,一层线性数据层
如下示例可以验证:
qDebug()<<"Array_Da[0][0]:"<<&Array_Da[0][0]
<<endl<<"*Array_Da[0]:"<<Array_Da[0]
<<endl<<"Array_Da[1][0]:"<<&Array_Da[1][0]
<<endl<<"*Array_Da[1]:"<<Array_Da[1]
<<endl<<"Array_Da[2][0]:"<<&Array_Da[2][0]
<<endl<<"*Array_Da[2]:"<<Array_Da[2]
<<endl<<"Array_Da[3][0]:"<<&Array_Da[3][0]
<<endl<<"*Array_Da[3]:"<<Array_Da[3];
输出:
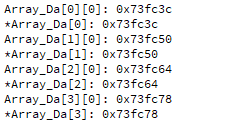
输出效果显而易见
当然从此部分也可以看出,二维数组名和一维数组名有着一样的性质,在唯二的情况下,是不等于指向首元素的指针的
3.5.9数组指针
指向数组的指针
一维数组:
int Array_a[4] = {0,1,2,3};
int (*PArr)[4] = &Array_a;
qDebug()<<"数组指针:"<<*PArr
<<endl<<"数组名"<<Array_a;输出:
二维数组:
int Array_Da[4][5] =
{
{0,1,2,3,4},
{10,11,12,13,14},
{20,21,22,23,24},
{30,31,32,33,34}
};
int (*DPArr)[4][5] = &Array_Da;
qDebug()<<"二维数组指针:"<<*DPArr
<<endl<<"二维数组名"<<Array_Da;输出:
![]()
总结:数组指针的定义方式:
一维数组定义方式:
Data_Type (* NameForpointer)【Size】 = & NameOfOne-dimensionalArray;
int Array_a[4] = {0,1,2,3};
int (*PArr)[4] = &Array_a;二维数组定义方式:
Data_Type (* NameForpointer)【SizeOfRow】【SizeOfCol】 = & NameOfTwo-dimensionalArray;
int Array_Da[4][5] =
{
{0,1,2,3,4},
{10,11,12,13,14},
{20,21,22,23,24},
{30,31,32,33,34}
};
int (*DPArr)[4][5] = &Array_Da;其他定义方式:
以一维数组为例:
使用关键字typedef,以下使用typedef和平时稍有区别
typedef int (Array_TYPE) [4];
Array_TYPE myarray;//等于定义int myarray [4];
//数组指针的定义如下:
Array_TYPE * PArray = &myarray;
数组指针指向整个数组,对齐解引用,就是数组名
3.5.10指针数组
数组指针和指针数组,非常容易混淆的内容,数组指针,终归是指针,指针数组,就是内容是指针的数组。
数组指针,是指向数组的指针,对变量名有要求,必须和*首先结合,这也就是为什么数组指针声明的时候,声明形式如下:
int (*p)[4];表示一个指向int类型有4个元素的数组的指针。
加括号是因为[]优先级高于*,如果不加,就变成了int *p[4];这表示有4个元素是int指针类型的数组。
判断方法1:
理清楚数组符号[]和谁搭配,就容易搞懂这些问题了。
比如char a[10],char和[10]搭配,意思是10个字符长的字符数组,a就是一个这样的字符数组。
那么char *a[10]呢?char*是字符指针,char*和[10]搭在一起,意思是10个字符指针长的字符指针数组,a就是这样一个字符指针数组。
而char(*a)[10]呢?因为有括号,*是和a结合在一起,而char是和[10]在一起,则是10个字符长的字符数组,*a是这样的一个字符数组,也就是说a是指向这样一个字符数组的指针。a是数组指针。
typedef char T[10]呢?char和[10]搭在一起,意思是10个字符长的一个数组,typedef定义了T是char[10]这样的一种数据类型。
T * a;*应该和a搭在一起,所以a就是指向T这样一种数据类型的指针,所以等价于char (*a)[10]
(来自于牛客网:@不会飞的小飞机)
判断方法2:
观察*和谁结合,普通指针的声明:int * p;
声明指针,*必须和变量名结合。int *p[4];显然[]先和p结合,然后int * 再和p[4]结合,指针数组。
int (*p)[4];p先和*结合,指针,指向谁,指向含有四个int类型元素的数组。
下面看两个例子:
题目1:
int *p[4] 与 int *(p[4] ) 等价
[]优先级比*高,p和[ ]结合,表示数组,且有4个元素,再和*结合,表示数组元素是指针类型。
显然是指针数组
题目2:
若有定义
| 1 2 |
|
char ( *a) [ 10 ] ;等价于上面定义,a是数组指针定义指针,指向包含了10个为char元素的数组,数组指针。
下面我们再看几道练习:
题目1:
若有定义:int *p[3];,则以下叙述中正确的是


若PAT是一个类,则程序运行时,语句“PAT(*ad)[3];”调用PAT的构造函数的次数是( )
PAT(*ad)[3];
ad首先是个指针;
ad是个指向有着三个PAT元素的数组的指针;
这里只是声明了指针,虽然指针指向的数组有三个PAT对象,但是没有实例化其中的对象,所以并没有调用构造函数。
(牛客网@小喜菜鸟)
3.5.11常量指针和指针常量
const修饰指针的两种形式:
指针常量:关键字顺序为 * 、 const(和中文顺序一致), 例如 int * const a,表示指针a是一个常量,初始化后不可更改指向(永远指向某个对象),但是指向的对象的值可以修改,如*a=10;
常量指针:关键字顺序为 const、* ,例如 const int * a (等同与int const * a) ,表示指针a所指向的对象是个常量(其值不可以改变),但指针a可以指向其它对象,如 *a=10;是错误的,a = b;是可以的
3.6函数指针
函数指针是指向函数的指针变量
一般形式:
//返回值 (*函数指针名称)(参数1,参数2,.....)
//假设现有函数
void testFunction(int c1,double c2,....){
}
//形式1
typedef void (*funPtr)(int,double,.....)
funPtr objFP= testFunction;
objFP(1,2.0,....);
//形式2
typedef void (funPtr)(int,double,.....)
funPtr * objFP= testFunction;
objFP(1,2.0,....);但是在类中使用函数指针需要多加注意
首先是在定义的时候一定要声明作用域
class Widget;
typedef void (Widget::*funPtr) (int,double);//我们需要声明作用域
class Widget : public QWidget
{
Q_OBJECT
public:
explicit Widget(QWidget *parent = 0);
~Widget();
void testFunction(int c1 = 1,double c2 = 2.0){
qDebug()<<c1<<c2;
}
};只有在声明了作用域之后,在赋值操作的时候 才能成功
在进行调用的时候务必要小心,必须使用以下形式才能成功,以下案例是在构造函数中实现的,如果是在其他cpp中,需要将this换成对象
构造函数:
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
funPtr mPtr = testFunction;
(this->*(mPtr))(1,2);//在调用函数指针的时候一定要使用这种形式
}其他cpp中(以main函数为例):
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
Widget w;
w.show();
//赋值操作的过程中一定要声明作用域
funPtr mPtr = Widget::testFunction;
//调用的时候需要使用到原来类的对象进行实质性的调用
(w.*(mPtr))(1,2);
return a.exec();
}















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









