




 本文详细记录了作者在解决复杂数据结构问题时遇到的挑战及解决方案,特别是在使用线段树和懒惰传播技术时的常见错误和调试技巧。通过实例分析,作者分享了如何避免节点标记混乱、初始化不当、更新顺序错误等问题,并强调了freopen函数在调试过程中的注意事项。
本文详细记录了作者在解决复杂数据结构问题时遇到的挑战及解决方案,特别是在使用线段树和懒惰传播技术时的常见错误和调试技巧。通过实例分析,作者分享了如何避免节点标记混乱、初始化不当、更新顺序错误等问题,并强调了freopen函数在调试过程中的注意事项。
WA到哭啊,怎么还不过,从下午6点搞到晚上10点,怎么一直WA啊!
------------------------------------------------------------------------------------------------------------------------------
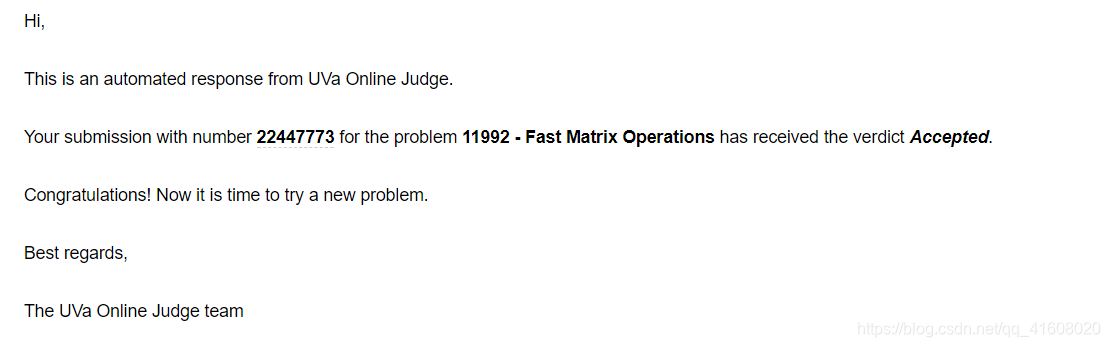
偶,耶,****,fuck,终于过了啊,原来最大的bug是freopen,囧囧囧。
说一次本蒟蒻错的好几个点
1.在每个节点上附上20+个标记值,作为20+颗线段树,第一次写注意写法,极易混淆。
2.setmark初始值要设为-1,不能设为0,每次更改后也要设为-1。
3.max和min要在每次操作的同时更新,要用新的函数求max,min,不能在原函数query上搞。
4.这个时候过了案例,但是对比自己搞的案例,发现在set后,原来的add值还是有效的,开始思考先后关系,set覆盖add,add可以在set后搞,所以每次set完一定要把set的节点的两个子节点的addmark清0!!!,在这里WA到死。
5.调试完程序freopen一定要删了啊,fuck,WA到爆炸啊,测了好久一直没测出问题。
AC代码
#include <iostream>
#include <algorithm>
#define ll long long
#define lson left,mid,k<<1,f
#define rson mid+1,right,k<<1|1,f
#define imid int mid=(left+right)>>1
using namespace std;
struct node
{
int l[21];
int r[21];
ll sum[21];
ll minn[21];
ll maxn[21];
ll addmark[21];
ll setmark[21];
}que[200005 * 4];
int ql, qr;
ll val;
void up(int k, int f)
{
que[k].sum[f] = que[k << 1].sum[f] + que[k << 1 | 1].sum[f];
que[k].minn[f] = min(que[k << 1].minn[f], que[k << 1 | 1].minn[f]);
que[k].maxn[f] = max(que[k << 1].maxn[f], que[k << 1 | 1].maxn[f]);
}
void down(int k, int f)
{
if (que[k].setmark[f] >= 0)
{
//que[k].addmark[f] = 0;//不需要
que[k << 1].addmark[f] = 0;//需要
que[k << 1 | 1].addmark[f] = 0;//需要
que[k << 1].setmark[f] = que[k].setmark[f];
que[k << 1 | 1].setmark[f] = que[k].setmark[f];
que[k << 1].sum[f] = que[k].setmark[f] * (que[k << 1].r[f] - que[k << 1].l[f] + 1);
que[k << 1 | 1].sum[f] = que[k].setmark[f] * (que[k << 1 | 1].r[f] - que[k << 1 | 1].l[f] + 1);
que[k << 1].maxn[f] = que[k].setmark[f];
que[k << 1].minn[f] = que[k].setmark[f];
que[k << 1 | 1].maxn[f] = que[k].setmark[f];
que[k << 1 | 1].minn[f] = que[k].setmark[f];
que[k].setmark[f] = -1;
}
if (que[k].addmark[f])
{
que[k << 1].addmark[f] += que[k].addmark[f];
que[k << 1 | 1].addmark[f] += que[k].addmark[f];
que[k << 1].sum[f] += que[k].addmark[f] * (que[k << 1].r[f] - que[k << 1].l[f] + 1);
que[k << 1 | 1].sum[f] += que[k].addmark[f] * (que[k << 1 | 1].r[f] - que[k << 1 | 1].l[f] + 1);
que[k << 1].maxn[f] += que[k].addmark[f];
que[k << 1].minn[f] += que[k].addmark[f];
que[k << 1 | 1].maxn[f] += que[k].addmark[f];
que[k << 1 | 1].minn[f] += que[k].addmark[f];
que[k].addmark[f] = 0;
}
}
void build(int left, int right, int k, int f)
{
que[k].l[f] = left;
que[k].r[f] = right;
que[k].addmark[f] = 0;
que[k].setmark[f] = -1;//初值 = -1
que[k].minn[f] = 0;
que[k].maxn[f] = 0;
if (left == right)
{
que[k].sum[f] = 0;
return;
}
imid;
build(lson);
build(rson);
up(k, f);
}
void updateadd(int left, int right, int k, int f)
{
if (qr < left || right < ql)
return;
if (ql <= left && right <= qr)
{
que[k].addmark[f] += val;
que[k].sum[f] += val * (que[k].r[f] - que[k].l[f] + 1);
que[k].maxn[f] += val;
que[k].minn[f] += val;
return;
}
imid;
down(k, f);
updateadd(lson);
updateadd(rson);
up(k, f);
}
void updateset(int left, int right, int k, int f)
{
if (qr < left || right < ql)
return;
if (ql <= left && right <= qr)
{
que[k].setmark[f] = val;
que[k].addmark[f] = 0;
que[k].sum[f] = val * (que[k].r[f] - que[k].l[f] + 1);
que[k].maxn[f] = val;
que[k].minn[f] = val;
return;
}
imid;
down(k, f);
updateset(lson);
updateset(rson);
up(k, f);
}
ll query(int left, int right, int k, int f)
{
if (qr < left || right < ql)
return 0;
if (ql <= left && right <= qr)
return que[k].sum[f];
imid;
down(k, f);
return query(lson) + query(rson);
}
ll querymax(int left, int right, int k, int f)
{
if (qr < left || right < ql)
return 0;
if (ql <= left && right <= qr)
return que[k].maxn[f];
imid;
down(k, f);
return max(querymax(lson), querymax(rson));
}
ll querymin(int left, int right, int k, int f)
{
if (qr < left || right < ql)
return 9999999999;
if (ql <= left && right <= qr)
return que[k].minn[f];
imid;
down(k, f);
return min(querymin(lson), querymin(rson));
}
int main()
{
int r, c, m;
int op, q1, q2, w1, w2;
//freopen("input.txt", "r", stdin);
//freopen("output.txt", "w+", stdout);
while (scanf("%d%d%d", &r, &c, &m) > 0)
{
if (r == 0)
return 0;
for (int i = 1; i <= r; i++)
build(1, c, 1, i);
while (m--)
{
scanf("%d", &op);
if (op == 1)
{
scanf("%d%d%d%d%lld", &q1, &w1, &q2, &w2, &val);
ql = w1;
qr = w2;
for (int i = q1; i <= q2; i++)
updateadd(1, c, 1, i);
}
else if (op == 2)
{
scanf("%d%d%d%d%lld", &q1, &w1, &q2, &w2, &val);
ql = w1;
qr = w2;
for (int i = q1; i <= q2; i++)
updateset(1, c, 1, i);
}
else if (op == 3)
{
ll ans = 0, minn = 9999999999, maxn = 0;
scanf("%d%d%d%d", &q1, &w1, &q2, &w2);
ql = w1;
qr = w2;
for (int i = q1; i <= q2; i++)
{
ans += query(1, c, 1, i);
minn = min(minn, querymin(1, c, 1, i));
maxn = max(maxn, querymax(1, c, 1, i));
}
printf("%lld %lld %lld\n", ans, minn, maxn);
}
}
}
}

















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









