







在项目总结中,遇到系统后台利用浏览器拉起一个已知路径页面的需求,趁着机会整理下。实现起来比较简单,浏览器默认谷歌。
一、技术原理
Selenium:Selenium 是一个用于自动化 Web 浏览器的工具,可模拟用户在浏览器中的各种操作,如点击、输入、提交表单等。通过 Selenium,可编写 Python 脚本控制浏览器行为;
WebDriver:WebDriver 是 Selenium 中用于控制浏览器的接口。它提供了一组用于操作浏览器的方法和属性,可通过编程方式与浏览器进行交互;
ChromeDriver:ChromeDriver 是 Chrome 浏览器的 WebDriver 实现,它允许 Selenium 控制 Chrome 浏览器的行为。在使用 Selenium 控制 Chrome 浏览器之前,下载配置即可;
定位元素:在自动化测试或者操作网页时,通常需要找到页面上的特定元素(如按钮、输入框等),然后对其进行操作。Selenium 提供了多种方式来定位元素,包括通过 ID、类名、标签名、XPath 等。在这个示例中,我们使用 XPath 来定位要点击的按钮;
等待页面加载:由于网页可能需要一些时间来加载和渲染,在进行操作之前,通常需等待页面加载完成;
在py脚本中,使用 driver.implicitly_wait(10),利用了 Selenium 提供的隐式等待机制(隐式/显式),等待特定的元素出现或某些条件满足后再执行操作
利用chrome_options.add_argument("window-size=1920x1080"),设置浏览器窗口的大小为 1920x1080 像素
利用chrome_options.add_argument("--no-sandbox"):禁用沙盒模式,防止未知权限问题
模拟用户行为:一旦找到了要操作的元素,就可以模拟用户在浏览器中的行为,如点击按钮、输入文本等。在示例中,使用driver.get(url)方法打开指定的 URL。
二、过程记录
脚本之前已download,详见文末参考链接;执行py脚本报错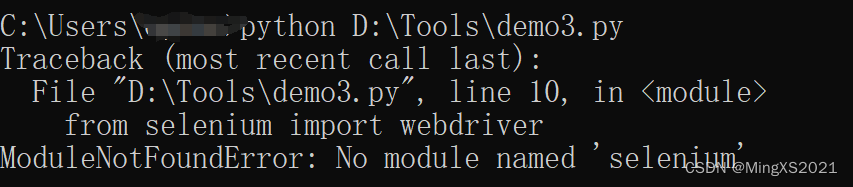 依赖缺失,windosw后台安装:pip install selenium
依赖缺失,windosw后台安装:pip install selenium
查看chrome://version/
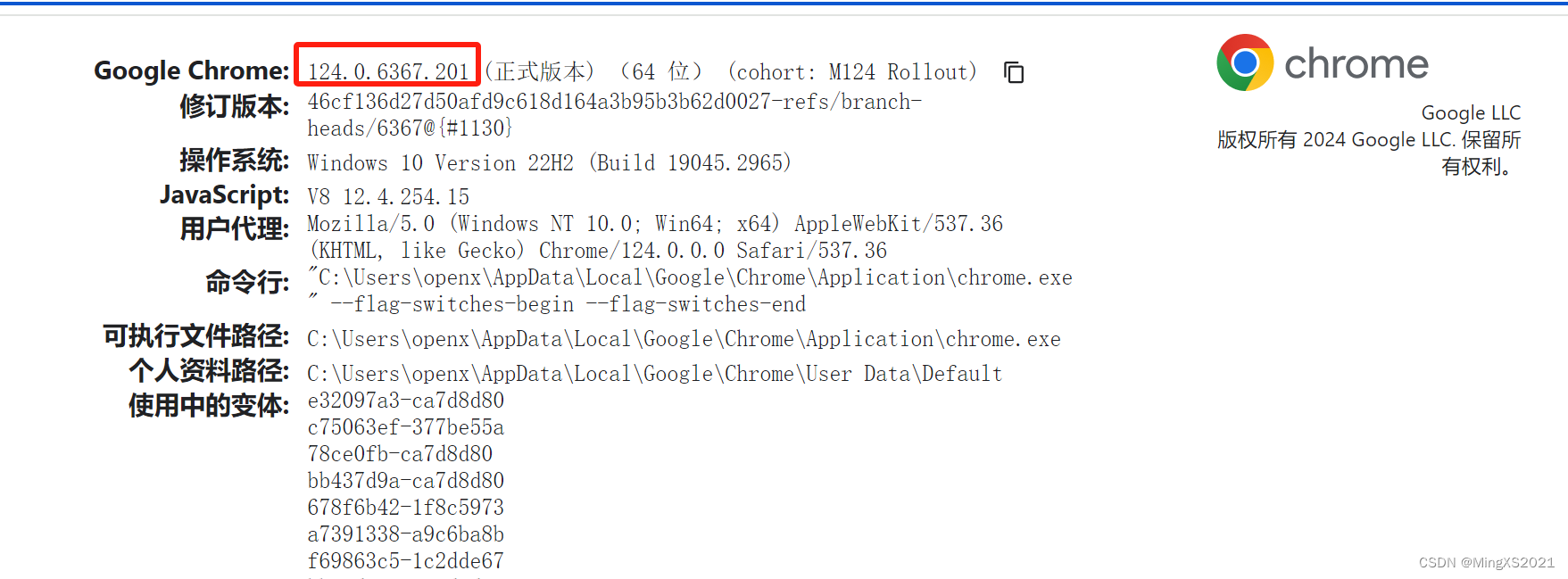
下载对应124版本chromedriver,详见文末参考链接,复制到Python安装根目录下
做了脚本路径和chromedriver.exe的配置检查

运行python,执行后,正常打开浏览器,会有如下提示

参考链接:【python】简单实现打开浏览器并自动点击跳转_windows脚本点击打开浏览器跳转网页路径点击网页按钮-CSDN博客selenium安装谷歌浏览器驱动chromedriver 122/123/124新版本_chromedriver123-CSDN博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











