







转发,原文地址:https://www.cnblogs.com/admln/p/hadoop2-work-excute-yarn.html
YARN是hadoop系统上的资源统一管理平台,其主要作用是实现集群资源的统一管理和调度(目前还不完善,只支持粗粒度的CPU和内存的的调配);
它的基本思想是将Mapreduce的jobtracker拆分成两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统资源的管理和分配,而ApplicationMaster则负责单个应用程序的管理;
YARN上的应用按其运行的生命周期的长短分为长应用和短应用。
1.短应用通常是分析作业,作业从提交到完成,所耗时间是有限的,作业完成后,其占用的资源就会被释放,归还给YARN再次分配
2.长应用通常是一些服务,启动后除非意外或人为终止,将一直运行下去。长应用通常长期占用集群上的一些资源,且运行期间对资源的需求也时常变化。
YARN在2.2.0版本以后增强了对长应用的支持。
用户向YARN提交一个应用程序后,YARN将分为两个阶段运行改应用程序:第一个阶段是启动ApplicationMaster;第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行成功。
YARN的工作流程可以分为以下几个步骤:
1.用户向YARN提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等;
2.ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在整个Container中启动应用程序的ApplicationMaster;
3ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7;
4.ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源;
5.一旦ApplicationMaster申请到资源后,则与对应的NodeManager通信,要求其启动任务;
6.NodeManager为任务设置好运行环境(包括环境变量、jar包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
7.各个任务通过某RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
在应用程序运行过程中,用户可以随时通过RPC向ApplicationMaster查询应用程序的当前运行状态;
8.应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。

在单机程序设计中,为了快速处理一个大的数据集,通常采用多线程并行编程,大体流程如下:先有操作系统启动一个主线程,由它负责数据气氛、任务分配、子线程启动和销毁等工作,而各个子线程只负责计算自己的数据,当所有子线程处理完数据后,主线程再退出;
类比理解,YARN上的应用程序运行过程与之非常相近,只不过它是集群上的分布式并行编程。可以将YARN看做一个云操作系统,它负责为应用程序启动ApplicationMaster(相当于主线程),然后再由ApplicationMaster负责数据气氛、任务分配、启动和监控等工作,而由ApplicationMaster启动其他各个Node的Task(相当于子线程)仅负责计算任务,当所有任务计算完成后,ApplicationMaster认为应用程序运行完成,然后退出。
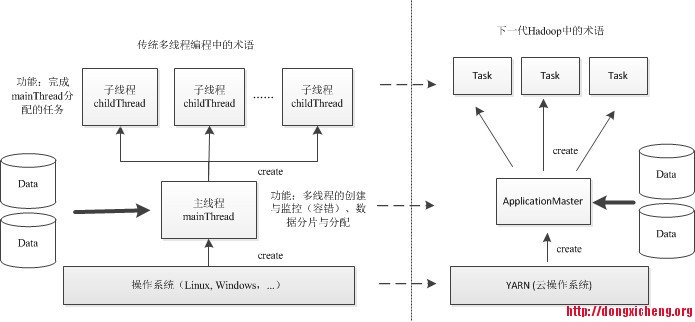
YARN上协议层面的通信动作

上图涉及三个RPC协议:
-
ApplicationClientProtocol: Client-RM之间的协议,主要用于应用的提交;
-
ApplicationMasterProtocol: AM-RM之间的协议,AM通过该协议向RM注册并申请资源;
-
ContainerManagementProtocol: AM-NM之间的协议,AM通过该协议控制NM启动容器。
YARN上程序层面的调用动作

可以看出,客户端的主要作用就是应用的提交和监控应用运行。
程序跟踪
从http://www.cnblogs.com/admln/p/hadoop2-work-excute-submit.html 的
JobSubmitter.java
status = submitClient.submitJob( jobId, submitJobDir.toString(), job.getCredentials());
接起

1 @Override 2 public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts) 3 throws IOException, InterruptedException { 4 5 addHistoryToken(ts); 6 7 // Construct necessary information to start the MR AM 8 ApplicationSubmissionContext appContext = 9 createApplicationSubmissionContext(conf, jobSubmitDir, ts); 10 11 // Submit to ResourceManager 12 try { 13 ApplicationId applicationId = 14 resMgrDelegate.submitApplication(appContext); 15 16 ApplicationReport appMaster = resMgrDelegate 17 .getApplicationReport(applicationId); 18 String diagnostics = 19 (appMaster == null ? 20 "application report is null" : appMaster.getDiagnostics()); 21 if (appMaster == null 22 || appMaster.getYarnApplicationState() == YarnApplicationState.FAILED 23 || appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) { 24 throw new IOException("Failed to run job : " + 25 diagnostics); 26 } 27 return clientCache.getClient(jobId).getJobStatus(jobId); 28 } catch (YarnException e) { 29 throw new IOException(e); 30 } 31 }
其中最重要的语句之一就是
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
读注释可知它用于启动AppMaster前构造必要的信息
1 public ApplicationSubmissionContext createApplicationSubmissionContext( 2 Configuration jobConf, 3 String jobSubmitDir, Credentials ts) throws IOException { 4 ApplicationId applicationId = resMgrDelegate.getApplicationId(); 5 6 // Setup resource requirements 7 Resource capability = recordFactory.newRecordInstance(Resource.class); 8 capability.setMemory( 9 conf.getInt( 10 MRJobConfig.MR_AM_VMEM_MB, MRJobConfig.DEFAULT_MR_AM_VMEM_MB 11 ) 12 ); 13 capability.setVirtualCores( 14 conf.getInt( 15 MRJobConfig.MR_AM_CPU_VCORES, MRJobConfig.DEFAULT_MR_AM_CPU_VCORES 16 ) 17 ); 18 LOG.debug("AppMaster capability = " + capability); 19 20 // Setup LocalResources 21 Map<String, LocalResource> localResources = 22 new HashMap<String, LocalResource>(); 23 24 Path jobConfPath = new Path(jobSubmitDir, MRJobConfig.JOB_CONF_FILE); 25 26 URL yarnUrlForJobSubmitDir = ConverterUtils 27 .getYarnUrlFromPath(defaultFileContext.getDefaultFileSystem() 28 .resolvePath( 29 defaultFileContext.makeQualified(new Path(jobSubmitDir)))); 30 LOG.debug("Creating setup context, jobSubmitDir url is " 31 + yarnUrlForJobSubmitDir); 32 33 localResources.put(MRJobConfig.JOB_CONF_FILE, 34 createApplicationResource(defaultFileContext, 35 jobConfPath, LocalResourceType.FILE)); 36 if (jobConf.get(MRJobConfig.JAR) != null) { 37 Path jobJarPath = new Path(jobConf.get(MRJobConfig.JAR)); 38 LocalResource rc = createApplicationResource(defaultFileContext, 39 jobJarPath, 40 LocalResourceType.PATTERN); 41 String pattern = conf.getPattern(JobContext.JAR_UNPACK_PATTERN, 42 JobConf.UNPACK_JAR_PATTERN_DEFAULT).pattern(); 43 rc.setPattern(pattern); 44 localResources.put(MRJobConfig.JOB_JAR, rc); 45 } else { 46 // Job jar may be null. For e.g, for pipes, the job jar is the hadoop 47 // mapreduce jar itself which is already on the classpath. 48 LOG.info("Job jar is not present. " 49 + "Not adding any jar to the list of resources."); 50 } 51 52 // TODO gross hack 53 for (String s : new String[] { 54 MRJobConfig.JOB_SPLIT, 55 MRJobConfig.JOB_SPLIT_METAINFO }) { 56 localResources.put( 57 MRJobConfig.JOB_SUBMIT_DIR + "/" + s, 58 createApplicationResource(defaultFileContext, 59 new Path(jobSubmitDir, s), LocalResourceType.FILE)); 60 } 61 62 // Setup security tokens 63 DataOutputBuffer dob = new DataOutputBuffer(); 64 ts.writeTokenStorageToStream(dob); 65 ByteBuffer securityTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength()); 66 67 // Setup the command to run the AM 68 List<String> vargs = new ArrayList<String>(8); 69 vargs.add(Environment.JAVA_HOME.$() + "/bin/java"); 70 71 // TODO: why do we use 'conf' some places and 'jobConf' others? 72 long logSize = TaskLog.getTaskLogLength(new JobConf(conf)); 73 String logLevel = jobConf.get( 74 MRJobConfig.MR_AM_LOG_LEVEL, MRJobConfig.DEFAULT_MR_AM_LOG_LEVEL); 75 MRApps.addLog4jSystemProperties(logLevel, logSize, vargs); 76 77 // Check for Java Lib Path usage in MAP and REDUCE configs 78 warnForJavaLibPath(conf.get(MRJobConfig.MAP_JAVA_OPTS,""), "map", 79 MRJobConfig.MAP_JAVA_OPTS, MRJobConfig.MAP_ENV); 80 warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS,""), "map", 81 MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); 82 warnForJavaLibPath(conf.get(MRJobConfig.REDUCE_JAVA_OPTS,""), "reduce", 83 MRJobConfig.REDUCE_JAVA_OPTS, MRJobConfig.REDUCE_ENV); 84 warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS,""), "reduce", 85 MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); 86 87 // Add AM admin command opts before user command opts 88 // so that it can be overridden by user 89 String mrAppMasterAdminOptions = conf.get(MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, 90 MRJobConfig.DEFAULT_MR_AM_ADMIN_COMMAND_OPTS); 91 warnForJavaLibPath(mrAppMasterAdminOptions, "app master", 92 MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.MR_AM_ADMIN_USER_ENV); 93 vargs.add(mrAppMasterAdminOptions); 94 95 // Add AM user command opts 96 String mrAppMasterUserOptions = conf.get(MRJobConfig.MR_AM_COMMAND_OPTS, 97 MRJobConfig.DEFAULT_MR_AM_COMMAND_OPTS); 98 warnForJavaLibPath(mrAppMasterUserOptions, "app master", 99 MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.MR_AM_ENV); 100 vargs.add(mrAppMasterUserOptions); 101 102 vargs.add(MRJobConfig.APPLICATION_MASTER_CLASS); 103 vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + 104 Path.SEPARATOR + ApplicationConstants.STDOUT); 105 vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + 106 Path.SEPARATOR + ApplicationConstants.STDERR); 107 108 109 Vector<String> vargsFinal = new Vector<String>(8); 110 // Final command 111 StringBuilder mergedCommand = new StringBuilder(); 112 for (CharSequence str : vargs) { 113 mergedCommand.append(str).append(" "); 114 } 115 vargsFinal.add(mergedCommand.toString()); 116 117 LOG.debug("Command to launch container for ApplicationMaster is : " 118 + mergedCommand); 119 120 // Setup the CLASSPATH in environment 121 // i.e. add { Hadoop jars, job jar, CWD } to classpath. 122 Map<String, String> environment = new HashMap<String, String>(); 123 MRApps.setClasspath(environment, conf); 124 125 // Setup the environment variables for Admin first 126 MRApps.setEnvFromInputString(environment, 127 conf.get(MRJobConfig.MR_AM_ADMIN_USER_ENV)); 128 // Setup the environment variables (LD_LIBRARY_PATH, etc) 129 MRApps.setEnvFromInputString(environment, 130 conf.get(MRJobConfig.MR_AM_ENV)); 131 132 // Parse distributed cache 133 MRApps.setupDistributedCache(jobConf, localResources); 134 135 Map<ApplicationAccessType, String> acls 136 = new HashMap<ApplicationAccessType, String>(2); 137 acls.put(ApplicationAccessType.VIEW_APP, jobConf.get( 138 MRJobConfig.JOB_ACL_VIEW_JOB, MRJobConfig.DEFAULT_JOB_ACL_VIEW_JOB)); 139 acls.put(ApplicationAccessType.MODIFY_APP, jobConf.get( 140 MRJobConfig.JOB_ACL_MODIFY_JOB, 141 MRJobConfig.DEFAULT_JOB_ACL_MODIFY_JOB)); 142 143 // Setup ContainerLaunchContext for AM container 144 ContainerLaunchContext amContainer = 145 ContainerLaunchContext.newInstance(localResources, environment, 146 vargsFinal, null, securityTokens, acls); 147 148 149 // Set up the ApplicationSubmissionContext 150 ApplicationSubmissionContext appContext = 151 recordFactory.newRecordInstance(ApplicationSubmissionContext.class); 152 appContext.setApplicationId(applicationId); // ApplicationId 153 appContext.setQueue( // Queue name 154 jobConf.get(JobContext.QUEUE_NAME, 155 YarnConfiguration.DEFAULT_QUEUE_NAME)); 156 appContext.setApplicationName( // Job name 157 jobConf.get(JobContext.JOB_NAME, 158 YarnConfiguration.DEFAULT_APPLICATION_NAME)); 159 appContext.setCancelTokensWhenComplete( 160 conf.getBoolean(MRJobConfig.JOB_CANCEL_DELEGATION_TOKEN, true)); 161 appContext.setAMContainerSpec(amContainer); // AM Container 162 appContext.setMaxAppAttempts( 163 conf.getInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 164 MRJobConfig.DEFAULT_MR_AM_MAX_ATTEMPTS)); 165 appContext.setResource(capability); 166 appContext.setApplicationType(MRJobConfig.MR_APPLICATION_TYPE); 167 return appContext; 168 }
其中
ApplicationId applicationId = resMgrDelegate.getApplicationId();
就对应上图中的第一步,向ResourceManager申请ID;
其中包括了内存、CPU的分配,资源(程序、配置等)路径的配置,启动AppMaster的命令,检查java环境等等;
这些就对应上图中的第二步,初始化AM的配置;
而submitJob()方法中最重要语句之二就是
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
它用于将AM提交到RM,对应于上图中的第三步;
submitApplication()方法是由YarnClientImpl.java实现的,即:
1 @Override 2 public ApplicationId 3 submitApplication(ApplicationSubmissionContext appContext) 4 throws YarnException, IOException { 5 ApplicationId applicationId = appContext.getApplicationId(); 6 appContext.setApplicationId(applicationId); 7 SubmitApplicationRequest request = 8 Records.newRecord(SubmitApplicationRequest.class); 9 request.setApplicationSubmissionContext(appContext); 10 rmClient.submitApplication(request); 11 12 int pollCount = 0; 13 while (true) { 14 YarnApplicationState state = 15 getApplicationReport(applicationId).getYarnApplicationState(); 16 if (!state.equals(YarnApplicationState.NEW) && 17 !state.equals(YarnApplicationState.NEW_SAVING)) { 18 break; 19 } 20 // Notify the client through the log every 10 poll, in case the client 21 // is blocked here too long. 22 if (++pollCount % 10 == 0) { 23 LOG.info("Application submission is not finished, " + 24 "submitted application " + applicationId + 25 " is still in " + state); 26 } 27 try { 28 Thread.sleep(statePollIntervalMillis); 29 } catch (InterruptedException ie) { 30 } 31 } 32 33 34 LOG.info("Submitted application " + applicationId + " to ResourceManager" 35 + " at " + rmAddress); 36 return applicationId; 37 }
这个方法主要构造了一个请求,并将这个请求调用相关协议发出,即:
rmClient.submitApplication(request);
客户端类结构:
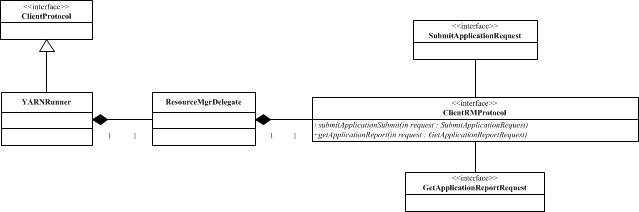
到这里客户端除了查询监控基本上没有什么动作了,之后就按照上面的协议通信图来进行了。
由于YARN的各种协议、接口、封装等,就简单从协议层面分析大概流程走向
(在查看协议代码的时候经常会看到google的字样,有点老祖宗的感觉)
客户端和RM之间的协议类是ApplicationClientProtocol
客户端和RM之间的通信动作包括:
1.获取应用ID
public abstract void getNewApplication( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.GetNewApplicationRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.GetNewApplicationResponseProto> done);
2.把应用提交到RM上
public abstract void submitApplication( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.SubmitApplicationRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.SubmitApplicationResponseProto> done);
具体步骤:
-
客户端通过getNewApplication方法从RM上获取应用ID;
-
客户端将应用相关的运行配置封装到ApplicationSubmissionContext中,通过submitApplication方法将应用提交到RM上;
-
RM根据ApplicationSubmissionContext上封装的内容启动AM;
-
客户端通过AM或RM获取应用的运行状态,并控制应用的运行过程。
在获取应用程序ID后,客户端封装应用相关的配置到ApplicationSubmissionContext中,通过submitApplication方法提交到RM上。
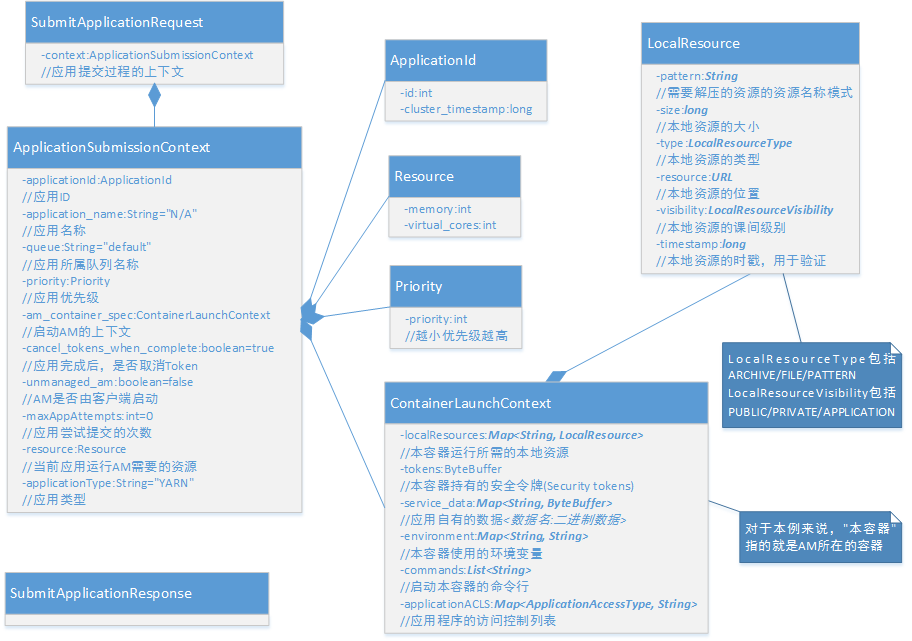
ApplicationSubmissionContext主要包括如下几个部分:
-
applicationId: 通过getNewApplication获取的应用ID;
-
applicationName: 应用名称,将显示在YARN的web界面上;
-
applicationType: 应用类型,默认为”YARN”;
-
priority: 应用优先级,数值越小,优先级越高;
-
queue: 应用所属队列,不同应用可以属于不同的队列,使用不同的调度算法;
-
unmanagedAM: 布尔类型,表示AM是否由客户端启动(AM既可以运行在YARN平台之上,也可以运行在YARN平台之外。运行在YARN平台之上的AM通过RM启动,其运行所需的资源受YARN控制);
-
cancelTokensWhenComplete: 应用完成后,是否取消安全令牌;
-
maxAppAttempts: AM启动失败后,最大的尝试重启次数;
-
resource: 启动AM所需的资源(虚拟CPU数/内存),虚拟CPU核数是一个归一化的值;
-
amContainerSpec: 启动AM容器的上下文,主要包括如下内容:
-
tokens: AM所持有的安全令牌;
-
serviceData: 应用私有的数据,是一个Map,键为数据名,值为数据的二进制块;
-
environment: AM使用的环境变量;
-
commands: 启动AM的命令列表;
-
applicationACLs:应程序访问控制列表;
-
localResource: AM启动需要的本地资源列表,主要是一些外部文件、压缩包等。
之后就是RM创建AM,并执行某些动作了
AM的主要功能是按照业务需求,从RM处申请资源,并利用这些资源完成业务逻辑。因此,AM既需要与RM通信,又需要与NM通信。这里涉及两个协议,分别是AM-RM协议(ApplicationMasterProtocol)和AM-NM协议(ContainerManagementProtocol)
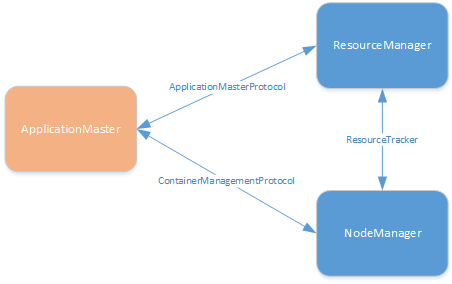
首先是AM-RM
AM-RM之间使用ApplicationMasterProtocol协议进行通信,该协议提供如下几个方法:
//向RM注册AM
public abstract void registerApplicationMaster( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.RegisterApplicationMasterRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.RegisterApplicationMasterResponseProto> done);
//告知RM,应用已结束
public abstract void finishApplicationMaster( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.FinishApplicationMasterRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.FinishApplicationMasterResponseProto> done);
//向RM申请/归还资源,维持心跳
public abstract void allocate( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.AllocateRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.AllocateResponseProto> done);
客户端向RM提交应用后,RM会根据提交的信息,分配一定的资源来启动AM,AM启动后调用ApplicationMasterProtocol协议的registerApplicationMaster方法主动向RM注册。完成注册后,AM通过ApplicationMasterProtocol协议的allocate方法向RM申请运行任务的资源,获取资源后,通过ContainerManagementProtocol在NM上启动资源容器,完成任务。应用完成后,AM通过ApplicationMasterProtocol协议的finishApplicationMaster方法向RM汇报应用的最终状态,并注销AM。
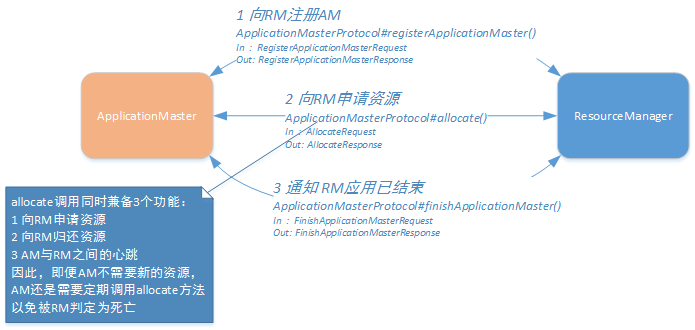
需要注意的是,ApplicationMasterProtocol#allocate()方法还兼顾维持AM-RM心跳的作用,因此,即便应用运行过程中有一段时间无需申请任何资源,AM都需要周期性的调用相应该方法,以避免触发RM的容错机制。
其次是AM-NM
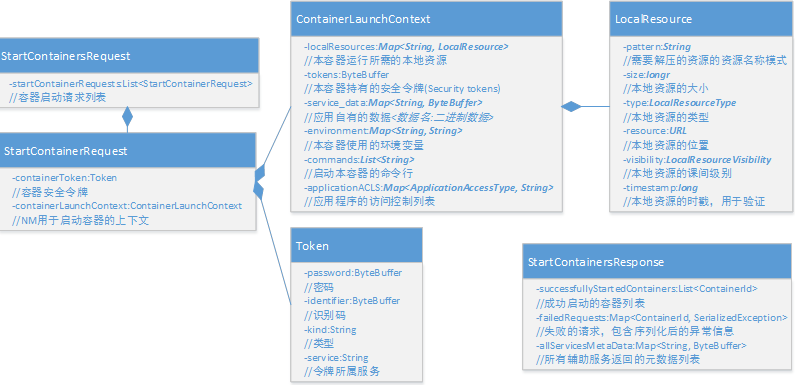
AM通过ContainerManagementProtocol协议与NM交互,包括3个方面的功能:启动容器、查询容器状态、停止容器
//启动容器
public abstract void startContainers( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.StartContainersRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.StartContainersResponseProto> done);
//查询容器状态
public abstract void getContainerStatuses( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.GetContainerStatusesRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.GetContainerStatusesResponseProto> done);
//停止容器
public abstract void stopContainers( com.google.protobuf.RpcController controller, org.apache.hadoop.yarn.proto.YarnServiceProtos.StopContainersRequestProto request, com.google.protobuf.RpcCallback<org.apache.hadoop.yarn.proto.YarnServiceProtos.StopContainersResponseProto> done);

AM通过ContainerManagementProtocol# startContainers()方法启动一个NM上的容器,AM通过该接口向NM提供启动容器的必要配置,包括分配到的资源、安全令牌、启动容器的环境变量和命令等,这些信息都被封装在StartContainersRequest中。NM收到请求后,会启动相应的容器,并返回启动成功的容器列表和失败的容器列表,同时还返回其上相应的辅助服务元数据
至此,就剩下NM上container的MAP和REDUCE过程了。














 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









