







ES学习
第一篇:ElasticSearch 邂逅ES
第二篇:ElasticSearch入门
第三篇:ElasticSearch JavaAPI操作
第四篇:Windows单点和集群配置
第五篇:Linux单点和集群配置
第六篇:ElasticSearch核心概念
第七篇:ElasticSearch系统架构
第八篇:ElasticSearch分布式集群
第九篇:ElasticSearch路由计算
Part2:ElasticSearch入门
2.1 ElasticSearch安装
2.1.1 下载软件
- 官网:https://www.elastic.co/cn/elasticsearch/
- 使用版本:7.8.0
- 下载地址(可选版本):https://www.elastic.co/cn/downloads/past-releases#elasticsearch
- Windows版本
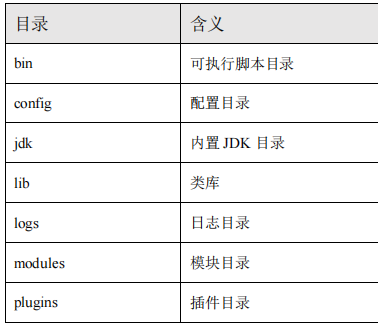
2.1.2 目录结构

- 解压后,可以进入bin目录,然后点击elasticsearch.bat文件启动ES
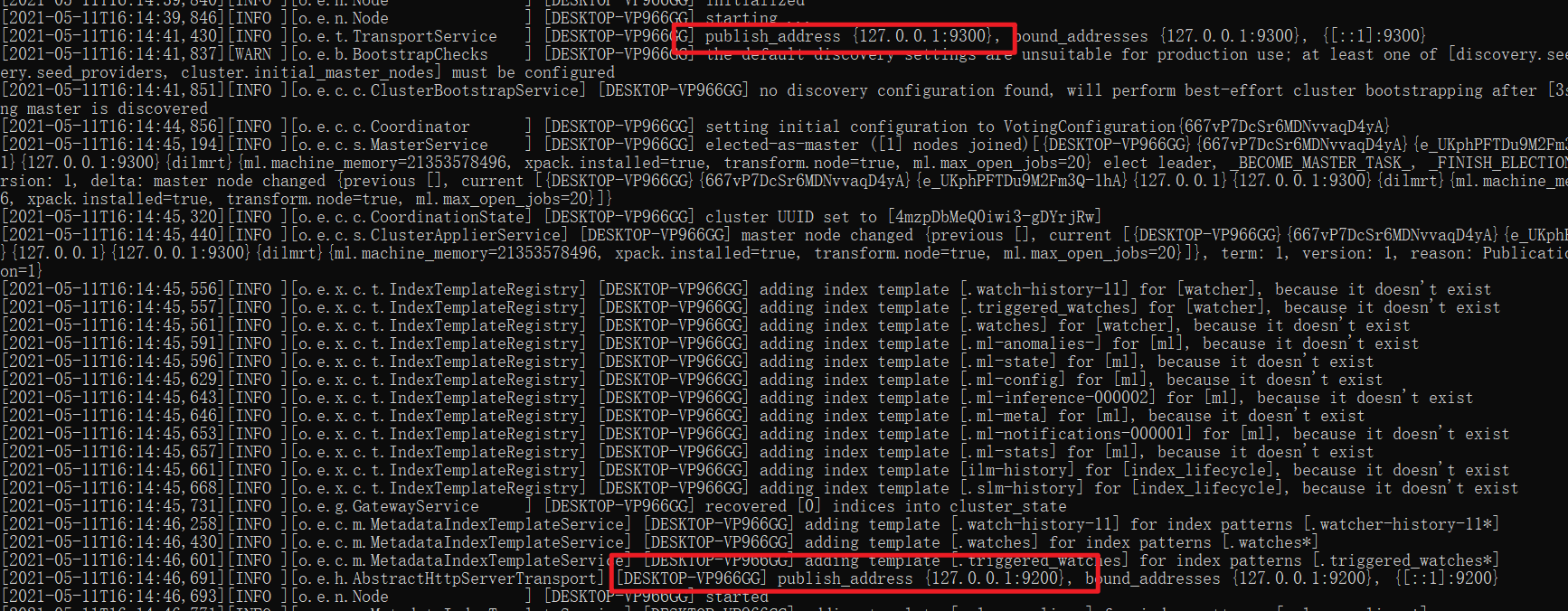
- 这里面有两个端口号:9300是ElasticSearch集群间组件的通信端口,9200是浏览器访问http协议Restful端口。
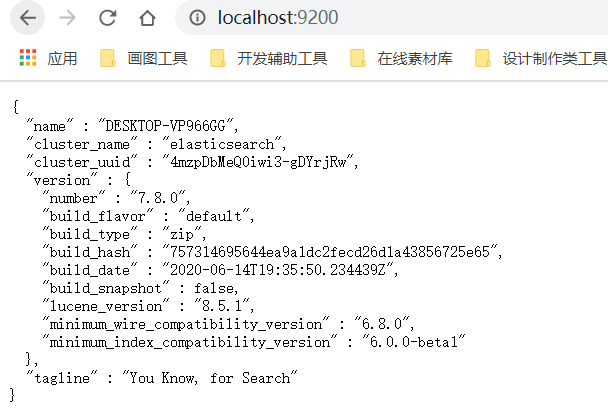
- 打开浏览器http://localhost:9200,测试
- 由于ElasticSearch是使用Java开发的,所以必须存在JDK环境,如果系统中配置了JAVA_HOME,那么会使用系统中的JDK,否则使用ElasticSearch自带的JDK
2.2 ElasticSearch基本操作
2.2.1 RestFul
- REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
- 在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和DELETE。
- 在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
2.2.2 客户端安装
- 如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件
- Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman 中文版能够发送任何类型的 HTTP 请求 (GET, HEAD, POST, PUT…),不仅能够表单提交,且可以附带任意类型请求体。
- 下载地址:https://www.getpostman.com/apps
2.2.3 数据格式
-
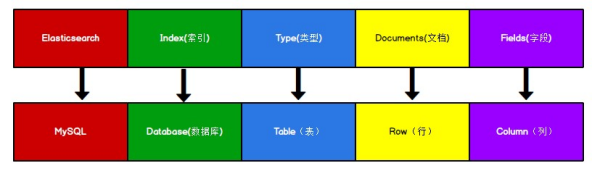
ElasticSearch是面向文档型数据库,一条数据就是一个文档。
-
ElasticSearch和Mysql存储概念对比
-
-
这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
{ "name":"John", "sex":"Male", "age":25, "birthDate":"1990/05/01", "about":"I love to go rock climbing", "interests":[ "sports", "music" ] }
-
2.2.4 倒排索引
-
正排索引
id content 1001 my name is li bai 1002 my name is li bai da- 可以根据文章编号去快速查询文章内容,因为设定id为主键,额外加索引会效率提升
-
倒排索引
keyword id my 1001,1002 name 1001,1002 is 1001,1002 li 1001,1002 bai 1001,1002 da 1002
2.2.5 HTTP操作
2.2.5.1 索引操作
2.2.5.1.1 创建索引
-
对比关系型数据库,创建索引就等同于创建数据库。
-
在Postman中,想ES服务器发送PUT请求,http://127.0.0.1:9200/shopping,创建索引库默认分片1片,在7.0.0之前是5片。
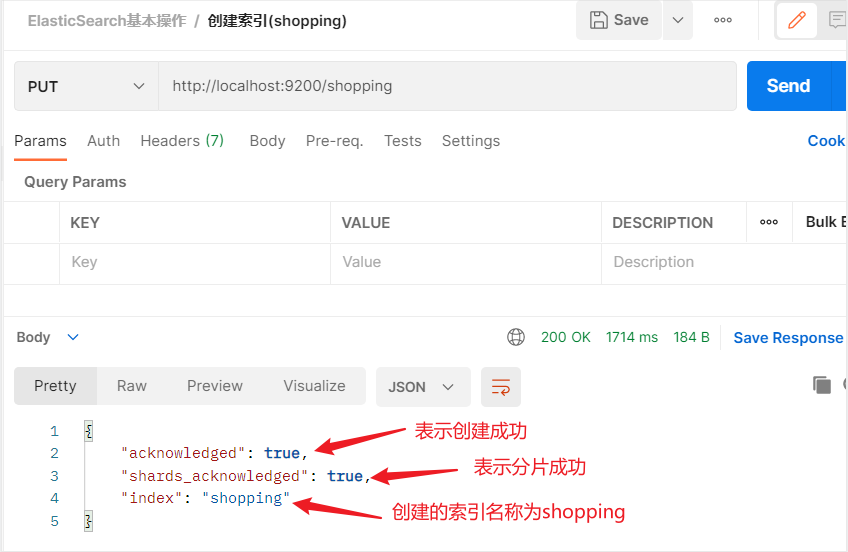
-
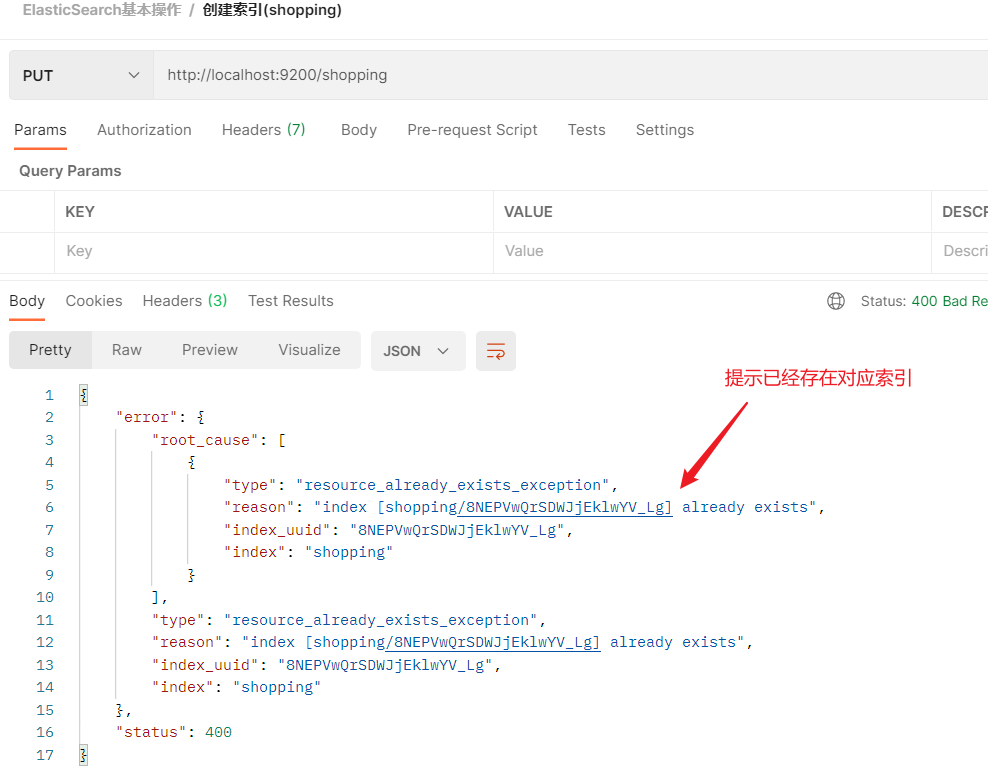
PUT请求满足幂等性,已经创建的索引,再次发起PUT请求时会报错
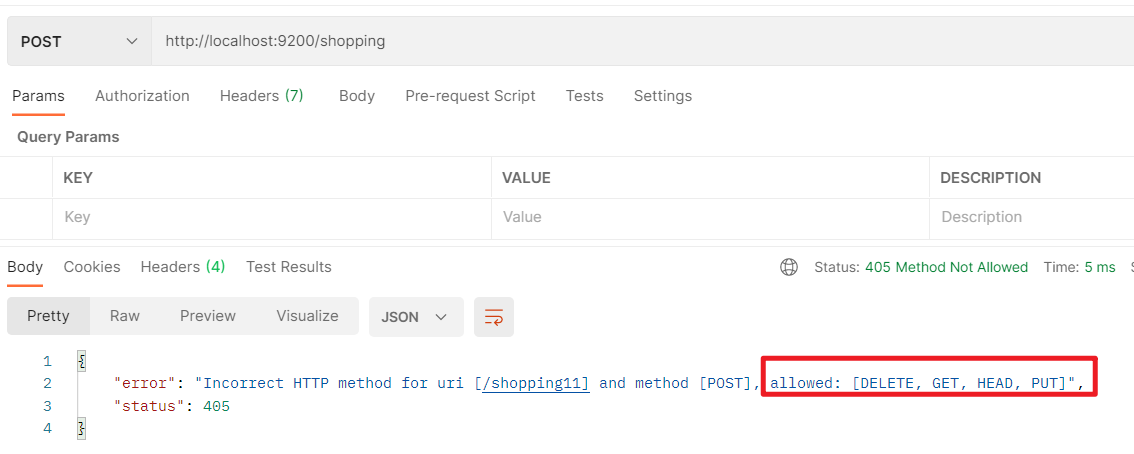
-
POST请求在ES中时不被允许使用的,不具有幂等性,只能使用DELETE\GET\HEAD\PUT
2.2.5.1.2 查看指定索引
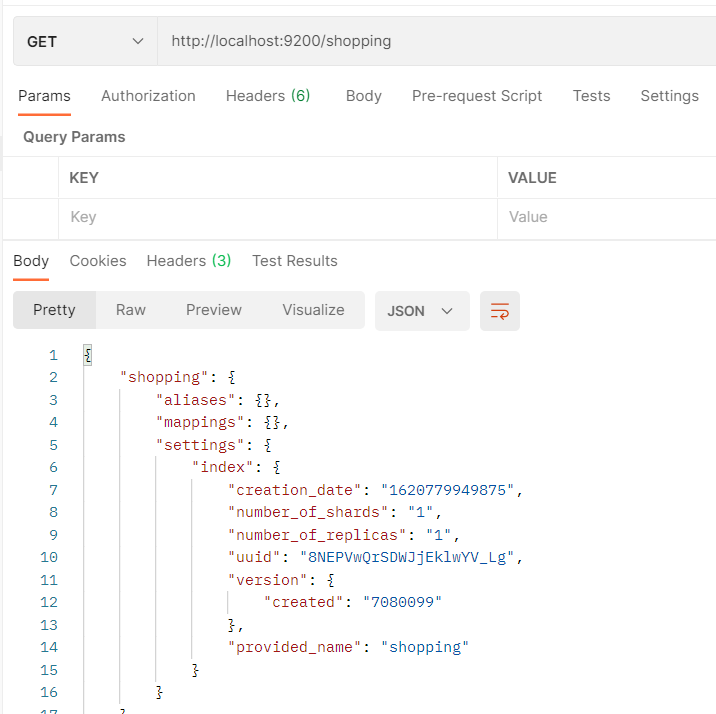
- Postman中,向ES服务器发送GET请求:http://localhost:9200/shopping
- 属性介绍

2.2.5.3 查看所有索引
-
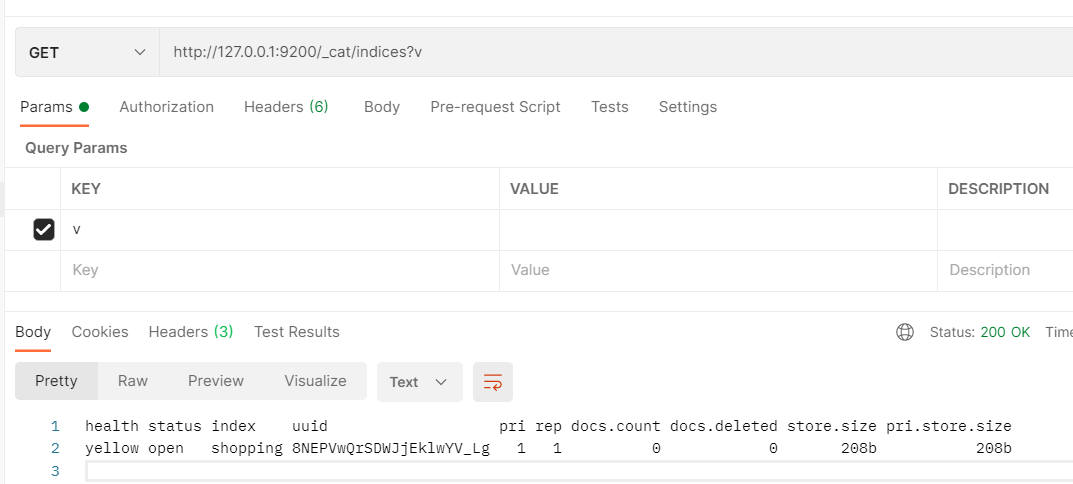
Postman中,向ES服务器发送GET请求:http://127.0.0.1:9200/_cat/indices?v
-
_cat表示查看的意思,indices表示索引–》表示查看当前ES服务器中的所有索引。类似于Mysql中show tables。
-
传递的参数v表示给查询结果添加列头(详细信息)
-
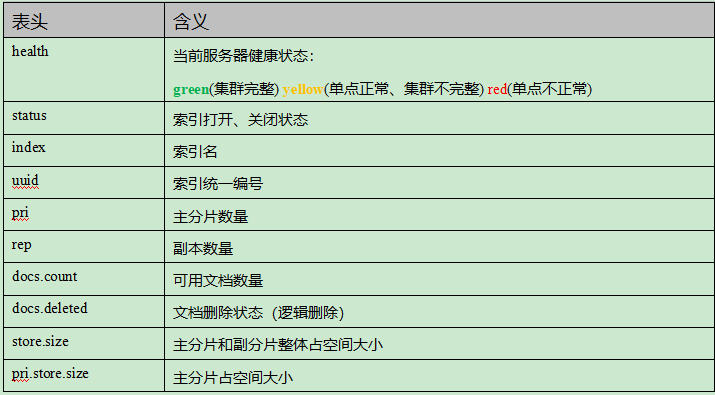
列头介绍
2.2.5.4 删除索引
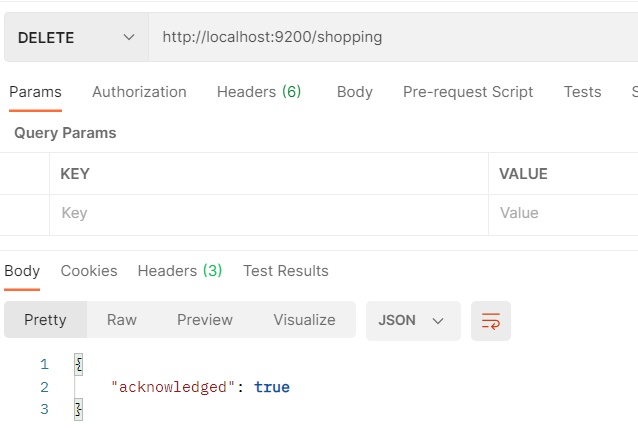
- Postman中,向ES服务器发送DELETE请求:http://127.0.0.1:9200/shopping
- 同样DELETE操作也具备幂等性,删除成功后再次删除也会出错
2.2.5.2 文档操作
2.2.5.2.1 创建文档
-
索引已经可以进行创建了,下一步创建文档,然后添加数据。
-
这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为JSON
-
索引后面必须使用_doc来指明是文档。
-
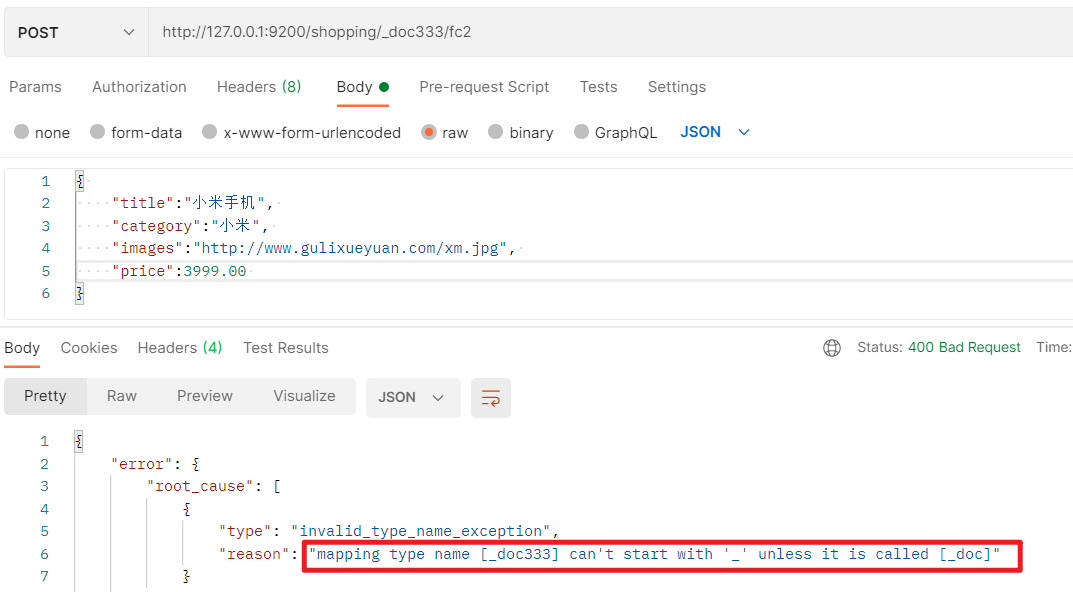
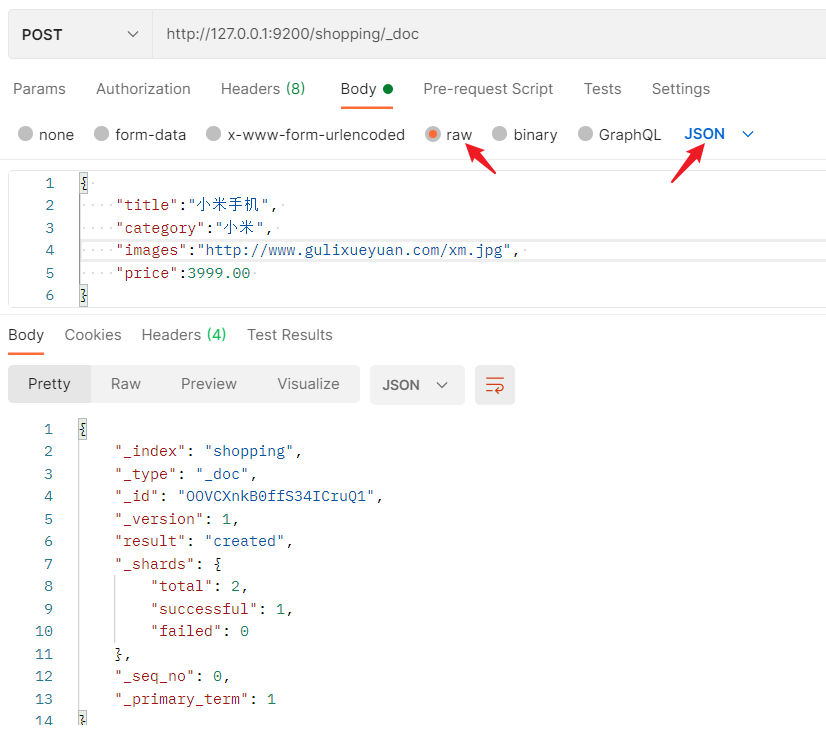
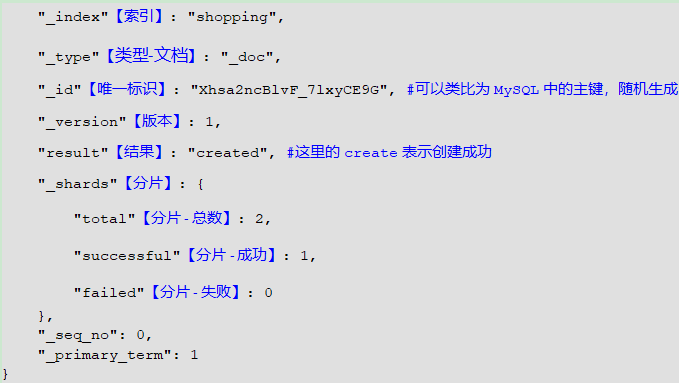
Postman中,向ES服务器发POST请求:http://127.0.0.1/shopping/_doc
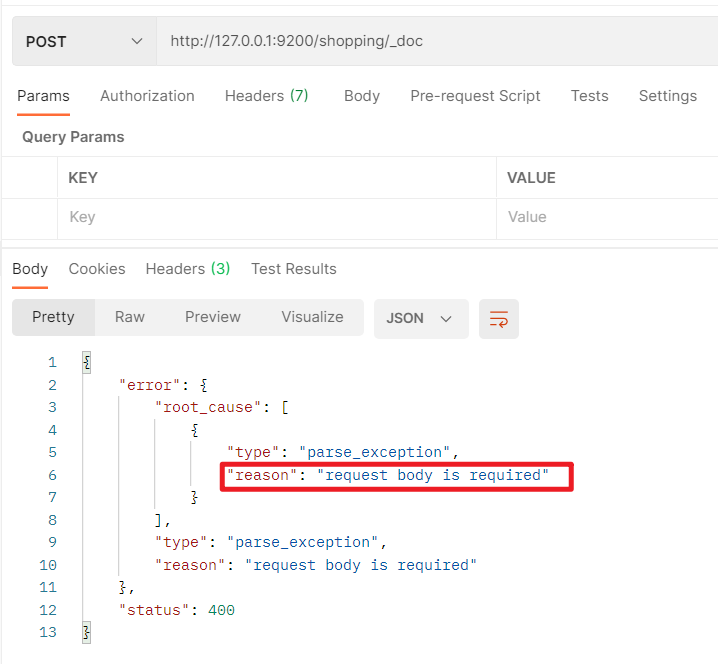
- 发送请求之后,发现报错了–>必须要填写请求体
-
填写请求体,重新发起请求
{ "title":"小米手机", "category":"小米", "images":"http://www.gulixueyuan.com/xm.jpg", "price":3999.00 } -
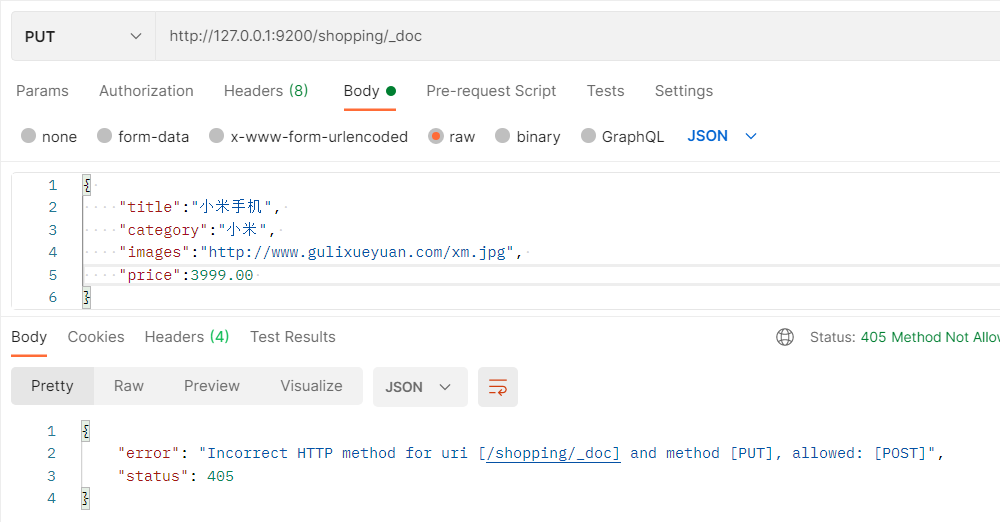
在创建文档时就只能使用POST请求了,不能使用PUT请求,这里只能允许POST请求(指定ID后可使用PUT)
2.2.5.2.2 创建文档指定Id
- 文档创建时,如果没有指定数据的唯一表示ID,默认情况下,ES服务器会随机生成一个。如果想要自定义唯一性标识,需要在创建的时候指定。
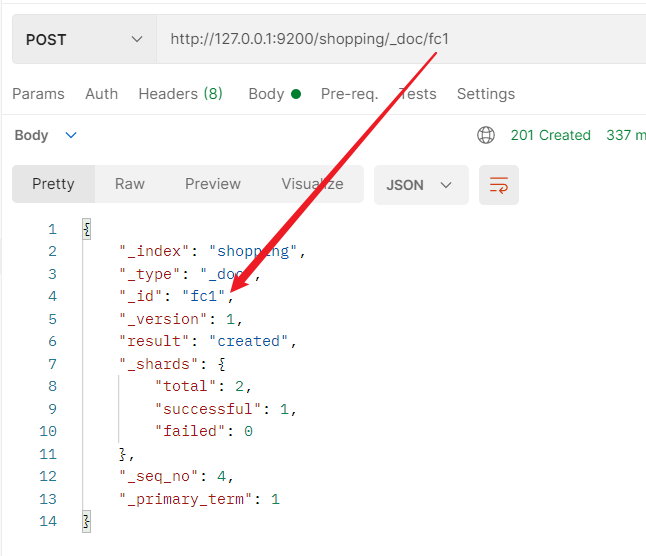
2.2.5.2.3 使用create创建文档
-
指定id创建文档时,除了使用doc还可以使用create,支持POST和PUT请求。
-
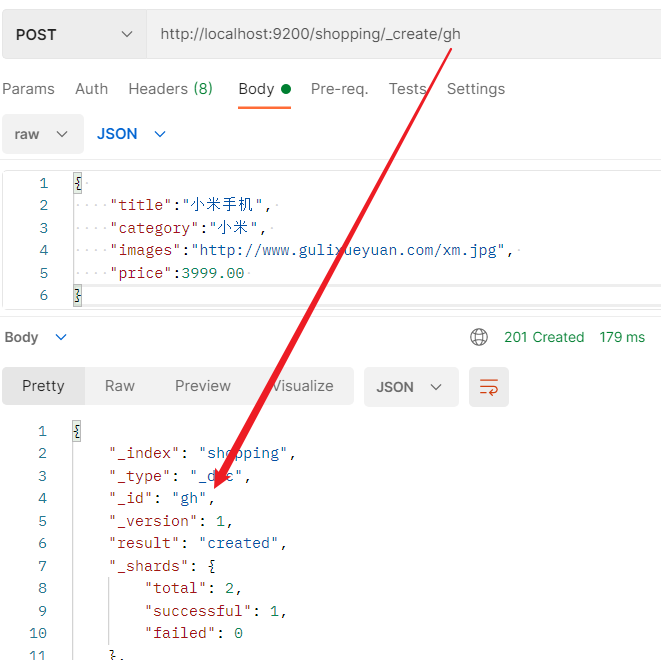
-
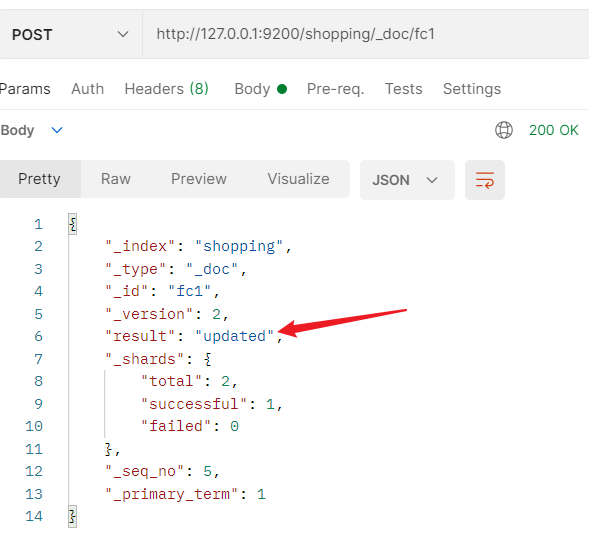
创建文档可以重复发起多次请求,如果_index中没有对应id的文档,那么为创建且id随机生成,否则为更新,现在重新创建一个id为fc1的文档,可以看到result是updated.
-
此外,如果在创建文档的时候,指定了主键id的值,那么请求方式也可以使用PUT
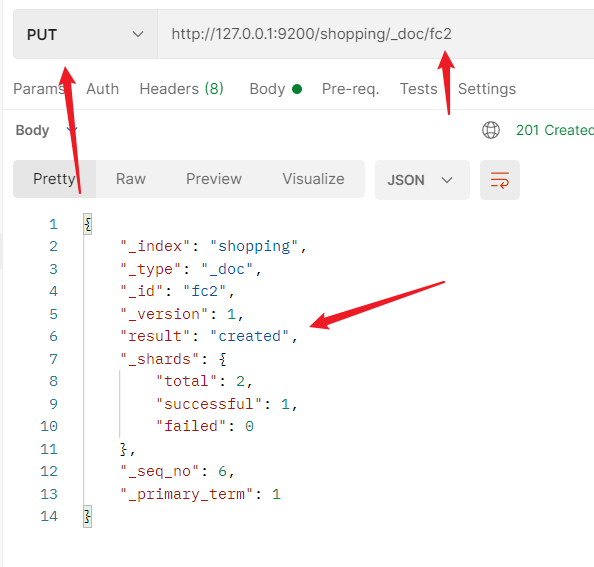
2.2.5.2.4 查询文档-指定id
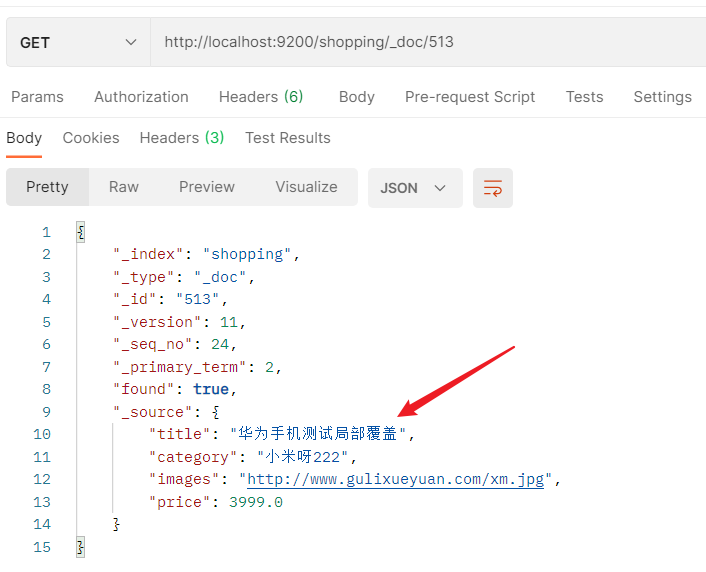
- 查看文档时,需要指明文档的唯一性标识,类似于Mysql的主键查询数据。
- Postman中,向ES发送GET请求:http://127.0.0.1:9200/shopping/_doc/fc
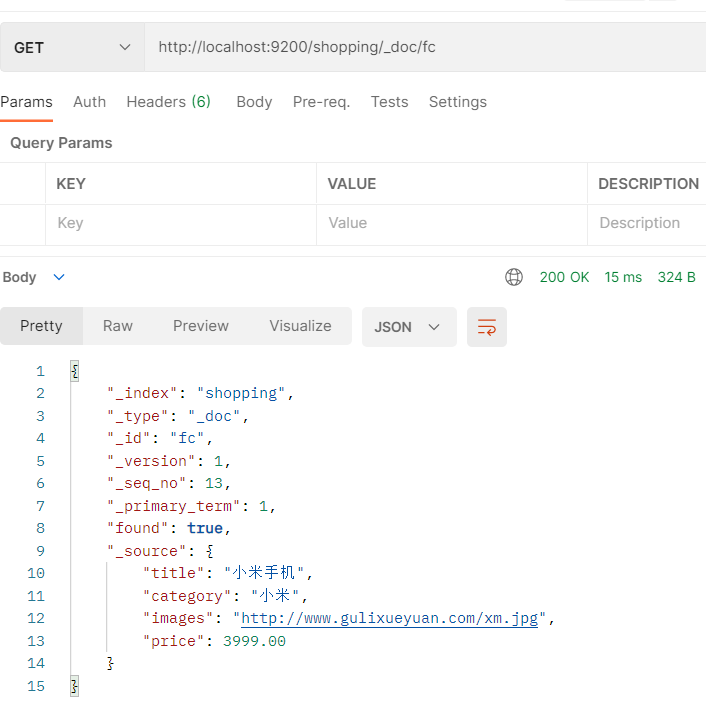
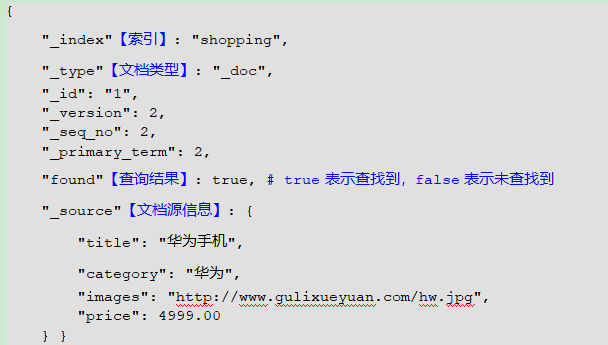
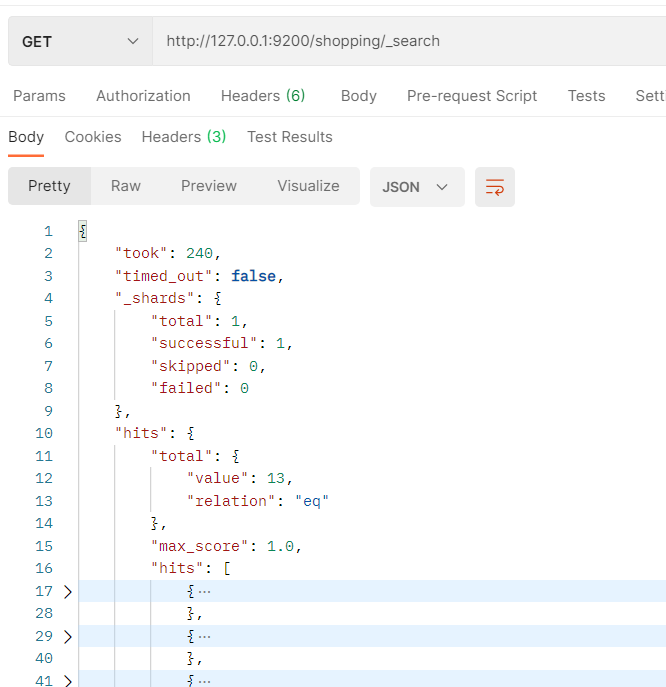
2.2.5.2.5 查询所有的文档_search
- 查询索引下的所有文档,使用_search
2.2.5.2.6 修改文档-全量修改
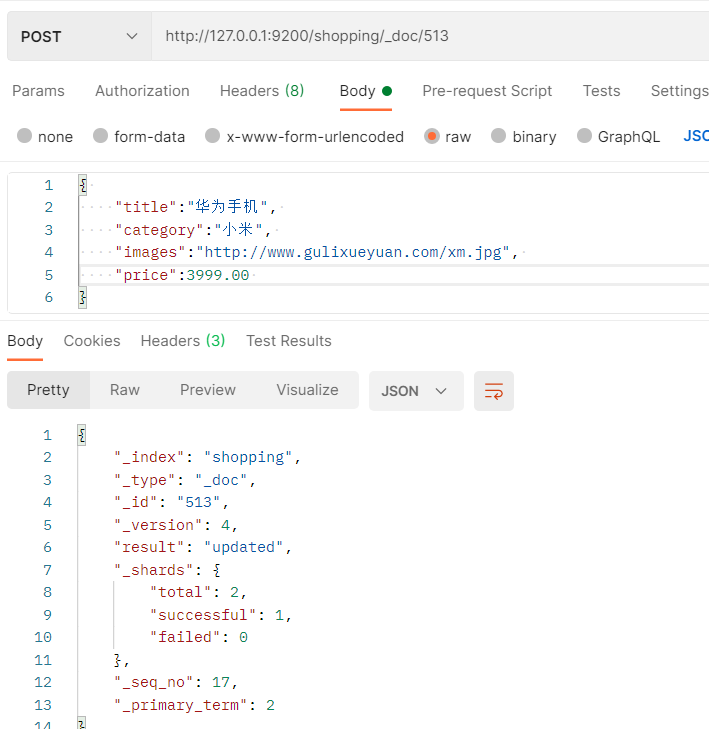
- 和新增文档一样,输入相同的URL地址请求,如果请求体变化,会将原有的数据内容覆盖在Postman中,向ES服务器发POST请求:http://127.0.0.1:9200/shopping/_doc/1
- 需要特别注意的是,这里的修改,会直接将对应id的请求体直接替换,不会根据属性名称进行匹配的替换。
- 支持PUT请求

2.2.5.2.7 修改文档-局部修改
- 对于数据的修改,也可以只修改指定数据的局部信息。
- 局部更新,不同的输入内容,一般会导致每次更新结果不相同,不是幂等性。不支持PUT请求。
- Postman中,向ES服务器发送POST请求:http://127.0.0.1:9200/shopping/_update/513
- 这样的话,使用_update可以只对指定文档中数据的指定内容进行局部修改了。
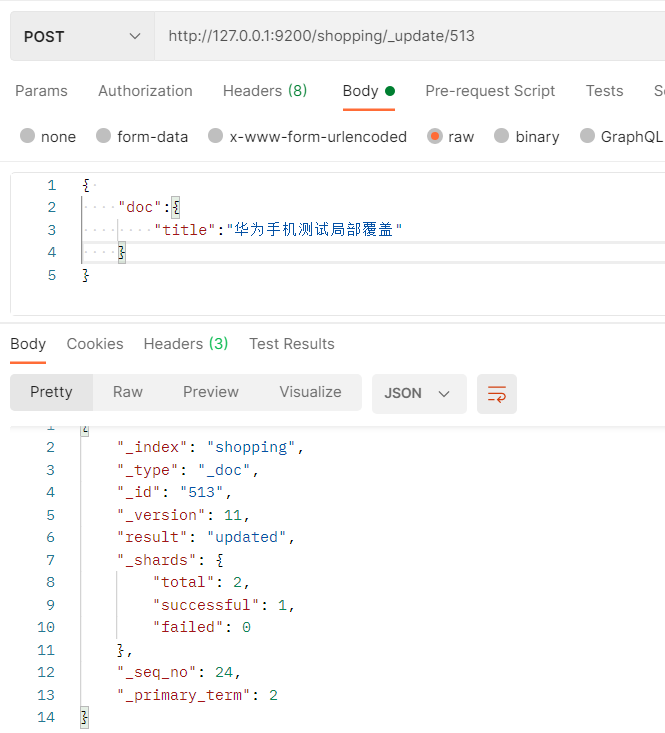
2.2.5.2.8 删除文档-根据id
- 进行文档的删除时,不会立即将文档从磁盘上删除掉,只是被标记为已删除(逻辑上删除状态)
- 在Postman中,向ES服务器发DELETE请求:http://127.0.0.1:9200/shopping/_doc/1
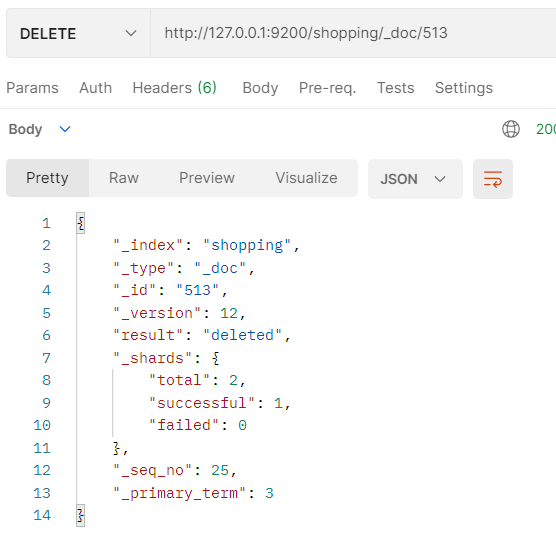
- result为“deleted"表示已经删除了
- 再次删除,会显示文档找不到,result:“not_found”
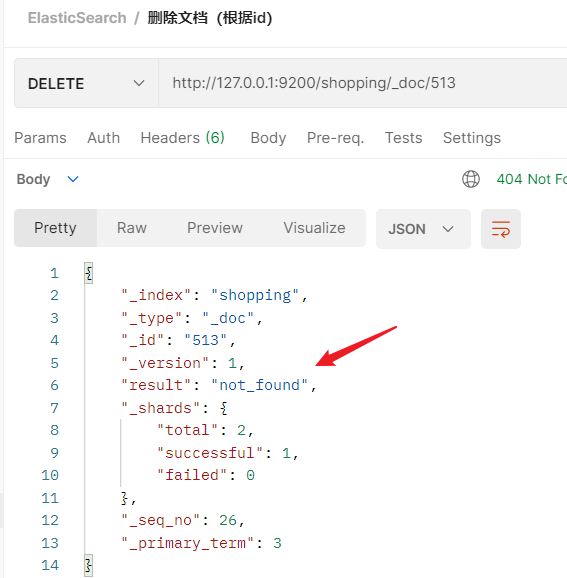
2.2.5.2.9 删除文档-条件删除
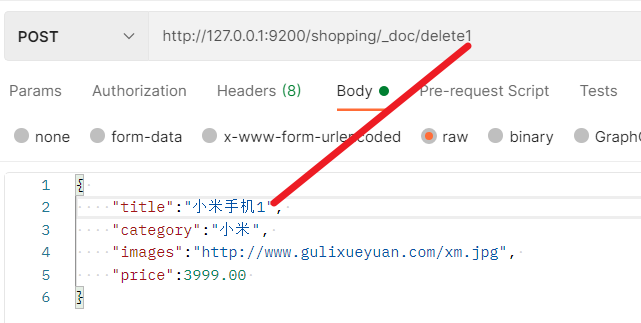
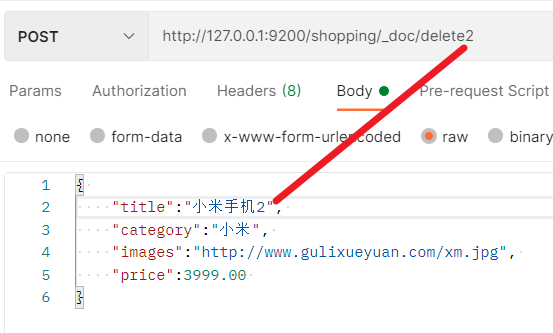
- 可以根据文档的唯一性标识进行删除,在实际操作过程中,也可以条件来对多条数据进行删除
- 先添加几条数据做测试
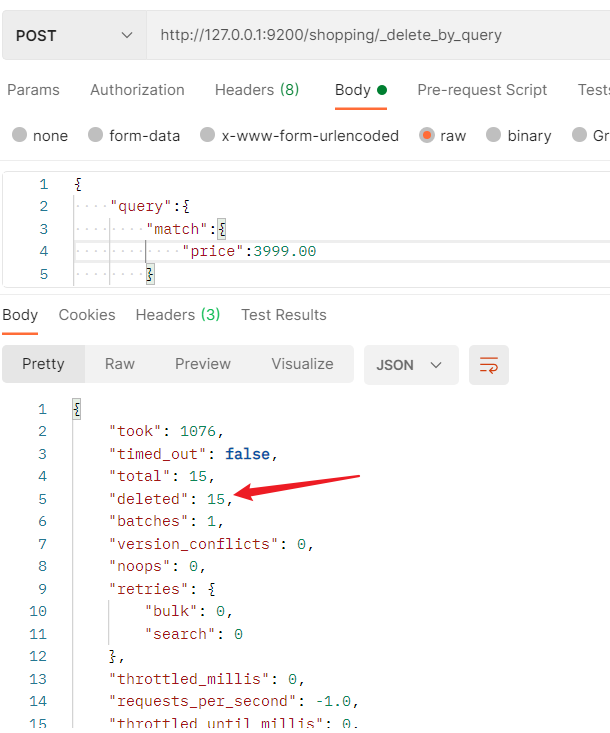
- 执行批量删除操作,这里将price匹配3999.00的所有文档全部都删除掉了
2.2.5.3 查询文档
- 介绍功能前,先准备一些数据,按之前创建文档的方式添加一些即可
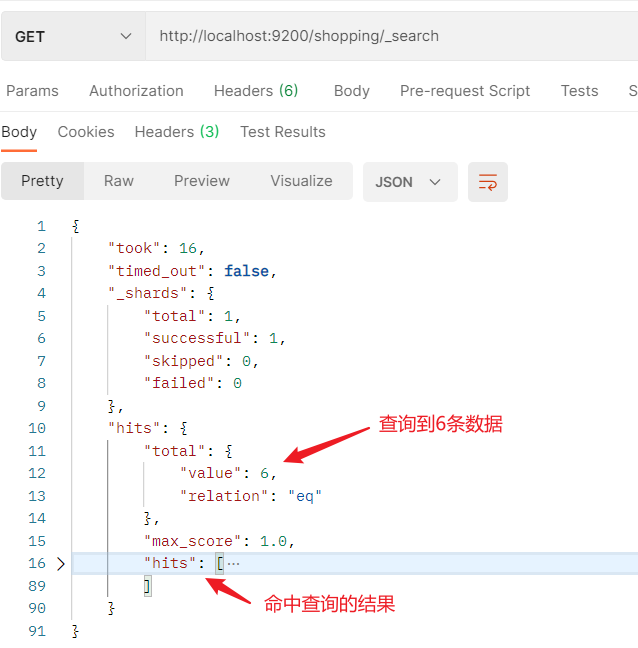
2.2.5.3.1 查询所有文档
- 使用_search进行查询
2.2.5.3.2 条件查询
- 匹配查询
- match进行匹配
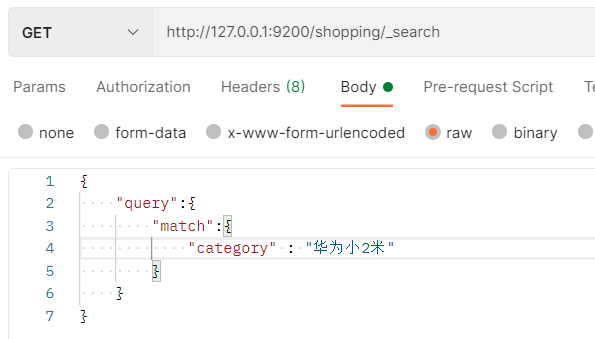
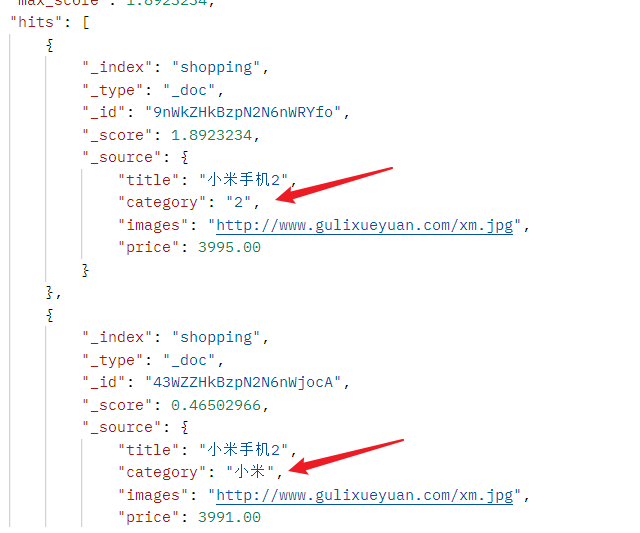
- 这里的查询结果进行了分词匹配,查询条件是“华为小2米”,可以匹配数据中的category的"小"、”米“、”2“、”小米“等等情况。
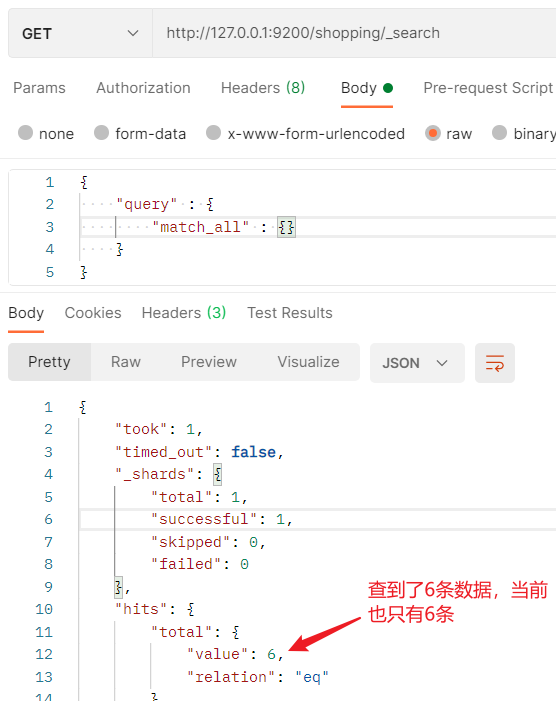
- 全量查询(全部查询)
- match_all
2.2.5.3.3 分页查询
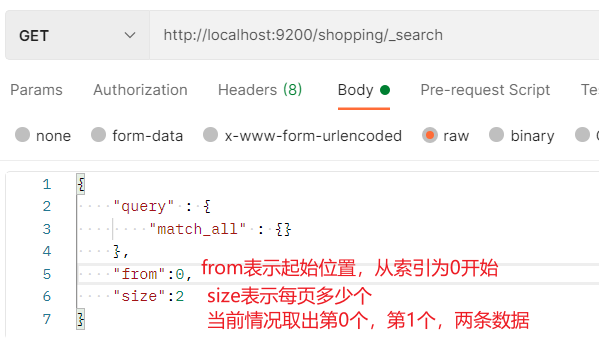
- 数据量过大时,全部显示的话数据量显示太多,可以设置分页进行调整。
- 分页查询会给予query查询到的结果进行分页,from指定从哪一条索引记录开始,size表示每页多少条,如from=4,size=2,表示取出第五条,第六条记录
- 设所求页码数为n,每页size条数据,那么第n页的from值为:(n-1)*size
2.2.5.3.4 过滤查询字段
- 使用_source,可以多个指定,指定的字段会显示出来。
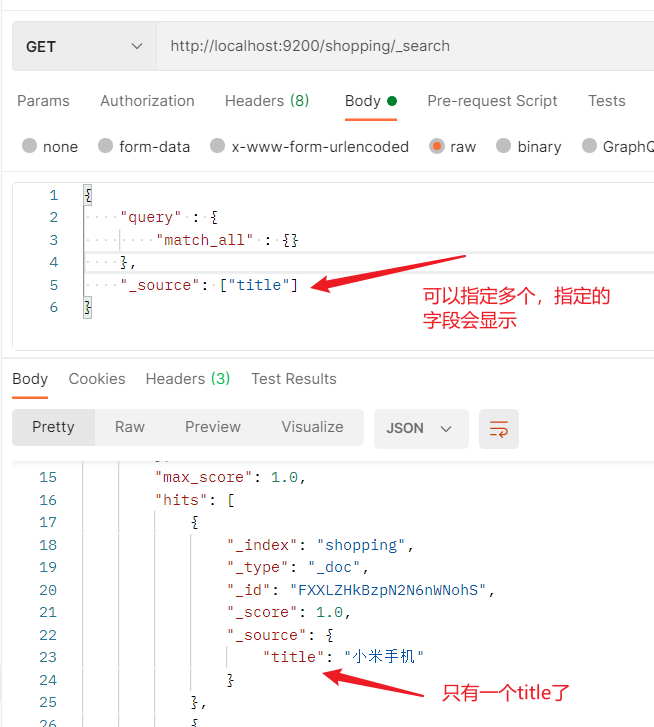
2.2.5.3.5 查询排序
- 对查询结果进行排序,使用sort。
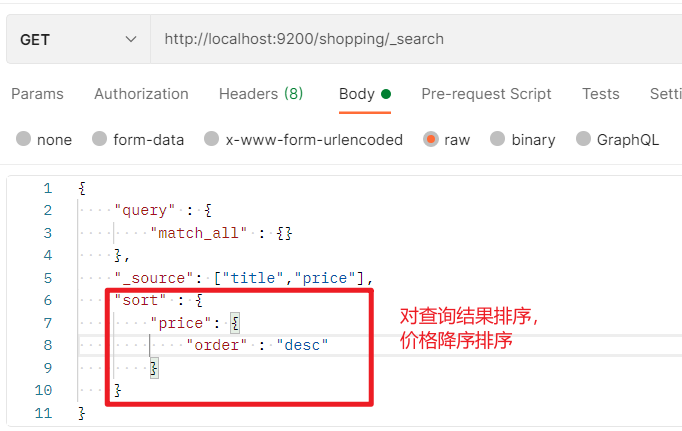
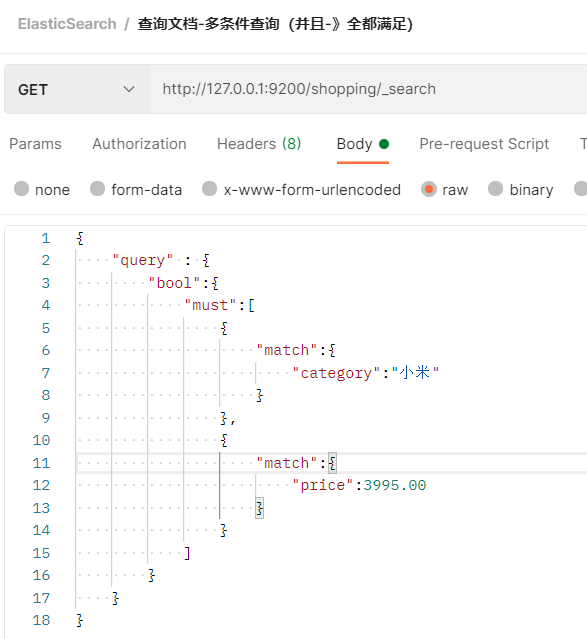
2.2.5.3.6 多条件查询
- 多条件查询的参数使用bool来标识
- 与关系(类似Mysql中的and),使用must参数
- category匹配小米,这里的match匹配并不是精确匹配,前面提到过,价格是3995
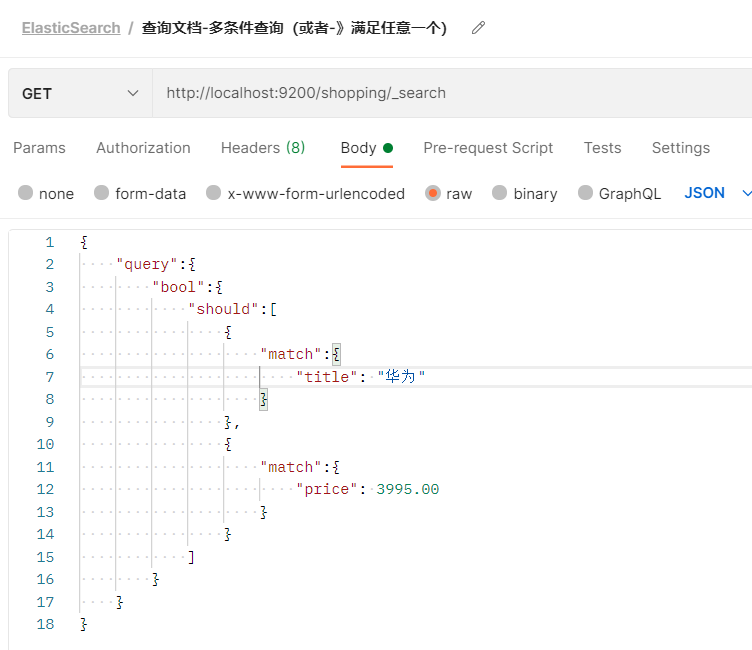
- 或关系(类似Mysql中的or),使用should参数,满足任意一个条件即可成立
- title需要匹配华为,价格是3995
2.2.5.3.7 范围查询
- 使用range参数
- 查询category匹配小米或者华为,并且价格大于3990,小于3996的文档
- 不支持ge,le

2.2.5.3.8 全文检索
- ES在保存文档数据的时候,会将数据文字进行分词,进行拆解操作,并将拆解后的数据保存到倒排索引中,这样的话,即使使用文字的一部分内容也可以检索到数据,这种方式就称为全文检索。
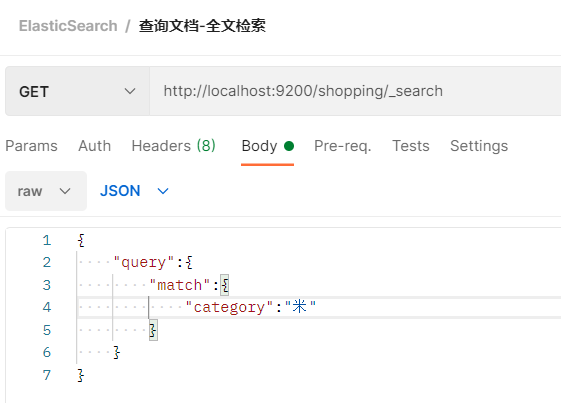
- 比如之前提到的match,这里匹配category:米,就能匹配到小米,大米等等带米字的数据,再举个例子来说,category:小华,就能匹配到(小米,华为等等),就是因为查询条件进行了分词
2.2.5.3.9 完全匹配
- 上面提到了match中的查询条件并非是精确匹配,ES会对查询内容分词后检索,如果想要做到更加精确一点的匹配,可以使用match_phrase。
- 这里同样也不是完全的精确匹配,只是这样子查询时,ES不会对查询内容进行分词处理
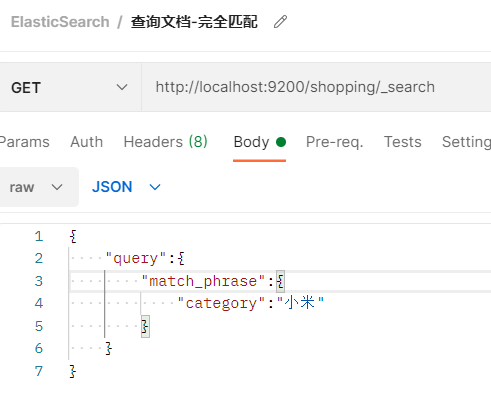
- 小米能够匹配(小米3,3小米,小米手机等等),但是不是匹配米,小这样子,换句话说,这种方式会把查询条件看做整体进行匹配查询。
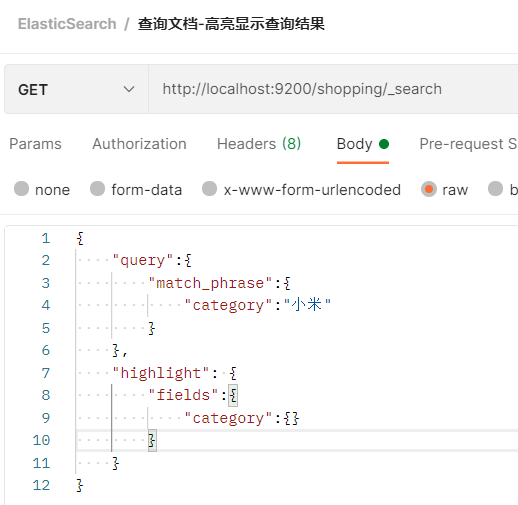
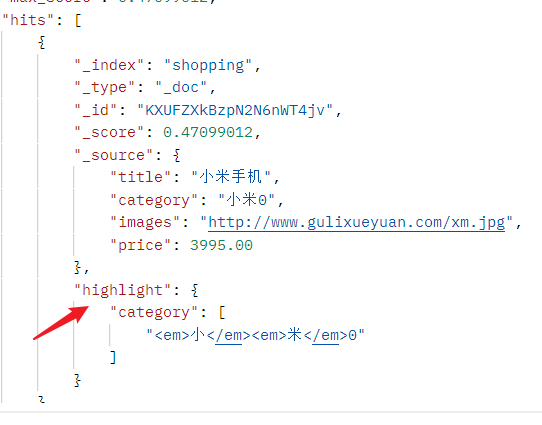
2.2.5.3.10 高亮查询
- 可以用高亮的形式显示查询结果中的查询内容
2.2.5.3.11 聚合查询
-
使用聚合查询可以对查询结果进行分组、统计分析等操作
-
使用aggs参数表示聚合操作
{ "took": 2, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 6, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "shopping", "_type": "_doc", "_id": "KXUFZXkBzpN2N6nWT4jv", "_score": 1.0, "_source": { "title": "小米手机", "category": "小米0", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3995.00 } }, { "_index": "shopping", "_type": "_doc", "_id": "KnUFZXkBzpN2N6nWYoiY", "_score": 1.0, "_source": { "title": "小米手机", "category": "小米1", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3996.00 } }, { "_index": "shopping", "_type": "_doc", "_id": "K3UFZXkBzpN2N6nWeYig", "_score": 1.0, "_source": { "title": "小米手机", "category": "小米2", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3997.00 } }, { "_index": "shopping", "_type": "_doc", "_id": "LHUFZXkBzpN2N6nWi4iQ", "_score": 1.0, "_source": { "title": "小米手机", "category": "小米3", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3998.00 } }, { "_index": "shopping", "_type": "_doc", "_id": "o_fPd3kBIj1-IRHmgB-q", "_score": 1.0, "_source": { "title": "小米手机", "category": "小米3", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 39955.00 } }, { "_index": "shopping", "_type": "_doc", "_id": "qPfbd3kBIj1-IRHmyh9B", "_score": 1.0, "_source": { "title": "华为手机", "category": "华为", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3993.00 } } ] }, "aggregations": { "price_group": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": 3993.0, "doc_count": 1 }, { "key": 3995.0, "doc_count": 1 }, { "key": 3996.0, "doc_count": 1 }, { "key": 3997.0, "doc_count": 1 }, { "key": 3998.0, "doc_count": 1 }, { "key": 39955.0, "doc_count": 1 } ] } } }- 从上面结果中可以看到,执行查询操作之后,不仅为我们查询出了原始数据(未进行聚合操作的数据),以及聚合操作执行之后的数据
-
如果我们只想获取聚合操作后的数据(统计结果),可以使用下面这种方式
-
上面的操作是分组操作,根据特定字段进行分组统计,常见统计参数如下:
- 分组:terms
- 求平均值:avg

2.2.5.4 映射操作
- 有了索引库,等于有了数据库中的database。接下来就需要创建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
- 创建表需要设置字段名称、类型、长度、约束等等,索引库也是一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射。
- 先创建一个索引,做测试
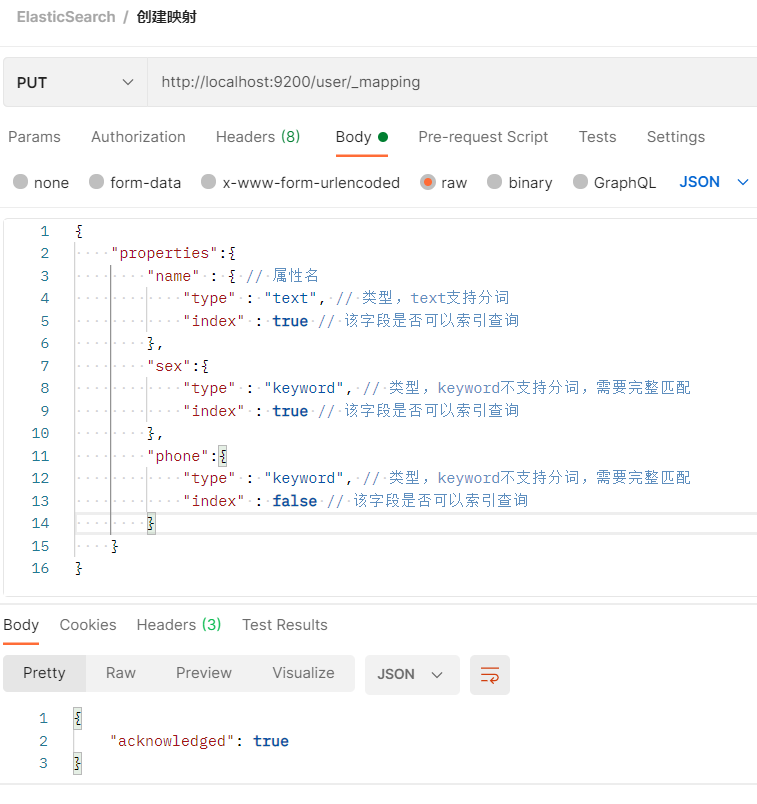
2.2.5.4.1 创建映射
- 在Postman中,向ES服务器发送PUT请求:http://localhost:9200/user/_mapping
- 映射数据说明
- 字段名:可以任意填写,指定属性
- type:类型,ES中支持很多数据类型,常见有:
- String类型
- text:可分词
- keyword:不可分词,数据作为完整字段进行匹配
- Numberical数值类型
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String类型
- index:是否索引,默认为true,如果不进行配置,所有字段都会被索引。
- true:字段会被索引,可以用来搜索
- false:字段不会被索引,不能用来搜索
- store:是否将数据进行独立存储,默认为false
- 原始的文本会存储在_source里面,默认情况下提取出来的字段都不是独立存储的,是从source里面提取出来的。如果需要独立存储某个字段,可以设置“store":true即可,获取独立存储的字段要比从source中解析快,但是会额外占用一定空间。
- analyzer:分词器,这里的ik_max_word即使用ik分词器。
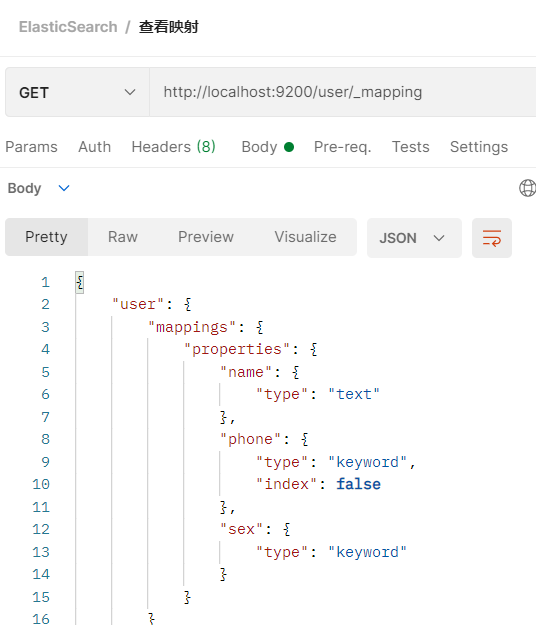
2.2.5.4.2 查看映射
- 在Postman中,向ES服务器发送GET请求:http://localhost:9200/user/_mapping
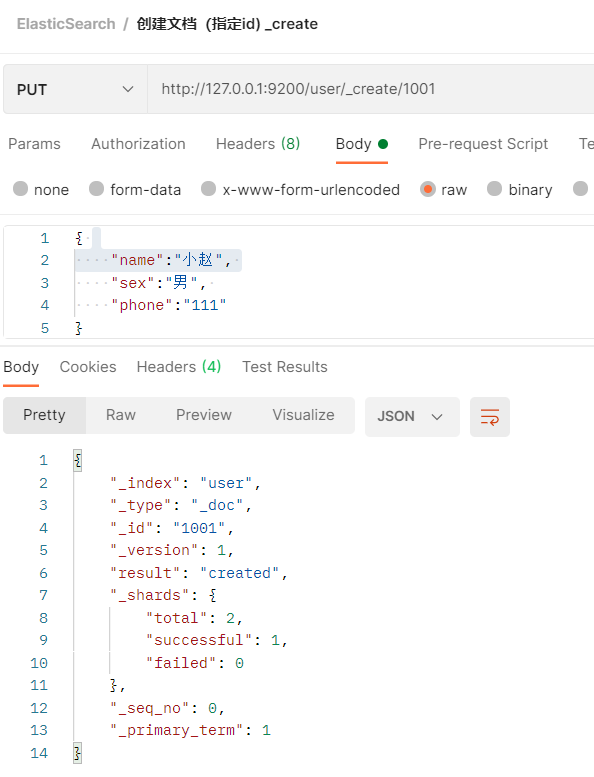
- 创建文档数据做测试
- 查询文档数据
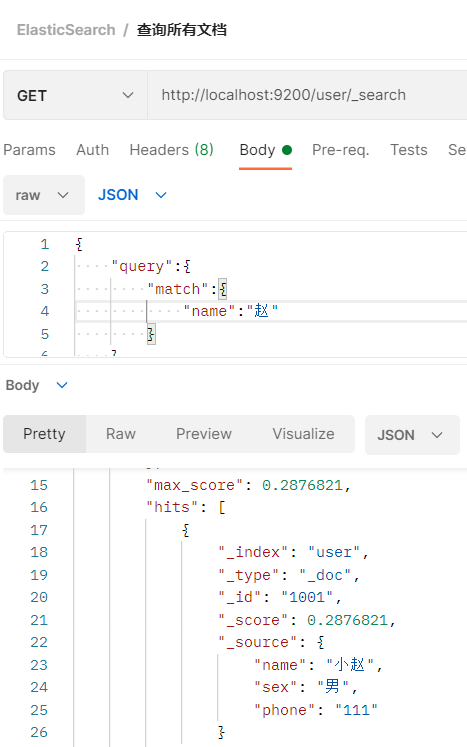
- name属性可以支持分词检索
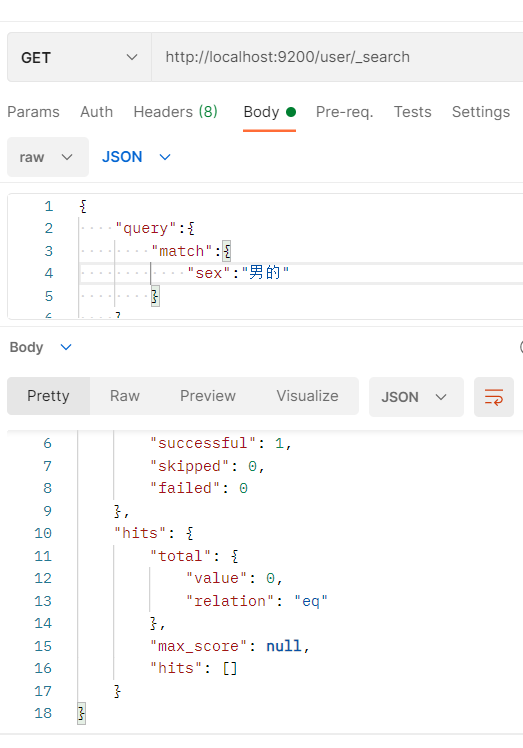
- sex属性类型为keyword不支持分词检索
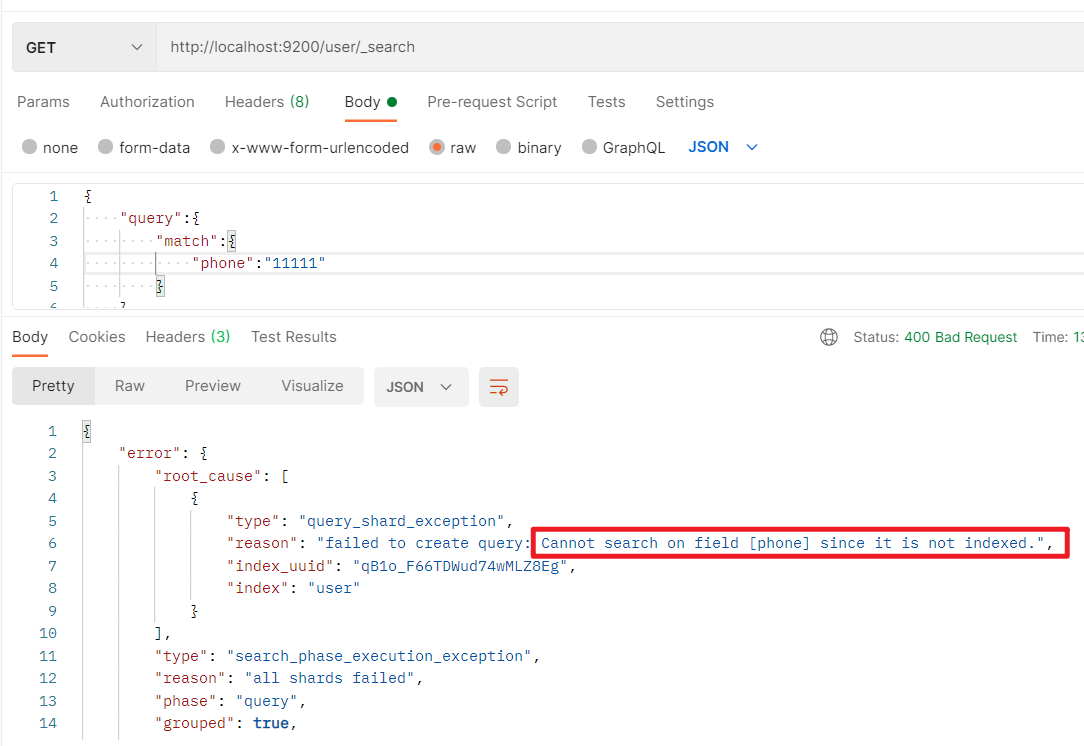
- 因为phone字段设置的index为false,不支持索引查询,该字段无法作为检索条件
- name属性可以支持分词检索
alyzer:分词器,这里的ik_max_word即使用ik分词器。
2.2.5.4.2 查看映射
-
在Postman中,向ES服务器发送GET请求:http://localhost:9200/user/_mapping
-
创建文档数据做测试
-
查询文档数据
-
name属性可以支持分词检索
-
sex属性类型为keyword不支持分词检索
-
因为phone字段设置的index为false,不支持索引查询,该字段无法作为检索条件
-




















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









