







12.9
我终于更新博客了!呜呜呜最近有点小懒各位爸爸们体谅一下。最开始是打算整理这次算法作业的,但这次的算法作业也太简单了8(狗头保命)。Greedy,目光短浅算法的作业就是猜一猜思路一条道走到黑就可以了。这次更新一些矩阵编程和机器学习相关的内容。
np.argsort
在奇异值分解的编程作业中,要对求出的特征值进行大小排序,之后相应的左右矩阵要按照最大特征值的顺序进行列变换。
np.argsort的作业是返回一个数组从小到大的索引,我查了一下只能返回从小到大不能返回从大到小,于是可以这样操作:
sortid = np.argsort(R_)[::-1]
其中R是得到的特征值数组。在后面加上[: : -1]即可实现特征值从大到小的索引,那如何根据索引进行列变换呢?
U = U[:,sortid]
左部分冒号代表取所有行。之前见过的都是U=U[:,1]这样的,意思为取U的第二列。比较少看到后面跟一个(索引)数组。这样列向量就按索引重新排列了,举个例子:
 说到行(列)向量交换再提一嘴,如果只是想单独交换两行(列),我用temp来存储临时数据的方式完全不管用,如图:
说到行(列)向量交换再提一嘴,如果只是想单独交换两行(列),我用temp来存储临时数据的方式完全不管用,如图:
 A[2]=temp语句并没有按我们想象中执行,深究原因我发现temp的值随着A[1]变化自己也悄悄发生了变化!
A[2]=temp语句并没有按我们想象中执行,深究原因我发现temp的值随着A[1]变化自己也悄悄发生了变化!
 真的很离奇哈。。正确的做法还是按照索引的方法,只不过不能取所有的行(列)了,将指定的行进行索引调换即可。
真的很离奇哈。。正确的做法还是按照索引的方法,只不过不能取所有的行(列)了,将指定的行进行索引调换即可。

np.tril_indices
在Givens变换中,需要依次取对角线下方的元素进行变换。np.tril_indices函数就可以方便地拿到矩阵对角线下方元素的索引值。
np.tril_indices(行数,-1,列)
不需要具体的矩阵作为参数。-1只是相对于对角线的位置!如果将-1改成0,也要取包括对角线在内的索引值。可以这样理解:每加1,分割线就上移一行。返回的值有两个数组,行索引和列索引,最好得用两个东西去接。如果只用一个东西去接,就变成了集合数组。
 这样我们就得到了对角线下方的坐标[1,0],[2,0],[2,1],现在要将两个数组结合进行遍历,我们就用到了zip函数。
这样我们就得到了对角线下方的坐标[1,0],[2,0],[2,1],现在要将两个数组结合进行遍历,我们就用到了zip函数。
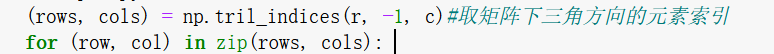 zip函数也用得很少,留个印象,以后肯定要用到。
zip函数也用得很少,留个印象,以后肯定要用到。
分割线
被大佬带着打完了比赛,其实还是有学到一些东西的。
当初我找的BERT模板实在是简陋,没有用one-hot向量,没有激活函数,没有Dropout,说一些踩过的坑吧
损失函数
对于训练集的标签,模板是直接采用10进制保存没有进行任何转换,所以在对模型进行训练的时候,损失函数为:
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
注意到不管是准确率还是损失函数都用上了SparseCategorical,因为这个函数是专门给10进制标签作判定的。from_logits=True的原因是没有使用激活函数(这个模板真的拉垮),如果有就改成False。(默认值就是False)
将标签集变成one-hot向量所使用的函数是:
label = tf.cast(label, dtype=tf.int32)
label = tf.squeeze(label)
label = tf.one_hot(label, depth=10) #十分类
变成one-hot向量之后,损失函数改成:
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
metric = tf.keras.metrics.CategoricalAccuracy('accuracy')
没有了前面的Sparse
还有一个点,如果要预测精确率和召回率,使用函数:
metrics=[tf.keras.metrics.Recall(), tf.keras.metrics.Precision()]
但前提是模型输出的评分结果都为正数!
所以得在前头补充一个softmax激活函数。
下期再见,Bye呀~















 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









