






MySq&SQL
一、数据库的基本概念
1.1 什么是数据库
-
数据库(DataBase) 就是存储和管理数据的仓库
-
其本质是一个文件系统, 还是以文件的方式, 将数据保存在电脑上
1.2 为什么使用数据库
数据存储方式的比较
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 內存 | 速度快 | 不能够永久保存,数据是临时状态的 |
| 文件 | 数据是可以永久保存的 | 使用IO流操作文件, 不方便 |
| 数据库 | 1.数据可以永久保存 2.方便存储和管理数据 3.使用统一的方式操作数据库 (SQL) | 占用资源,有些数据库需要付费(比如Oracle数据库) |
通过上面的比较,我们可以看出,使用数据库存储数据, 用户可以非常方便对数据库中的数据进行增加, 删除, 修改及查询操作。
1.3开发中常见的数据库
| 数据库名 | 介绍 |
|---|---|
| MySql数据库 | 开源免费的数据库 因为免费开源、运作简单的特点,常作为中小型的项目的数据库首选 MySQL1996年开始运作,目前已经被Oracle公司收购了. MySql6.x开始收费 |
| Oracle数据库 | 收费的大型数据库,Oracle公司的核心产品。 安全性高 |
| DB2 | IBM公司的数据库产品,收费的超大型数据库. 常在银行系统中使用 |
| SQL Server | MicroSoft 微软公司收费的中型的数据库。 C#、.net等语言常使用。 但该数据库只能运行在windows机器上,扩展性、稳定性、安全性、性能都表现平平。 |
1.4为什么选择MySql?
-
功能强大,足以应付web应用开发
-
开源, 免费
二、 MySql的安装及配置
2.1 安装MySql
- 详见 MySql安装文档
2.2 卸载MySql
- 详见 MySql卸载文档
2.3 MySql环境变量配置
- 详见 MySql环境变量配置文档
2.4 MySql的启动与关闭
方式一:window服务启动 MySql
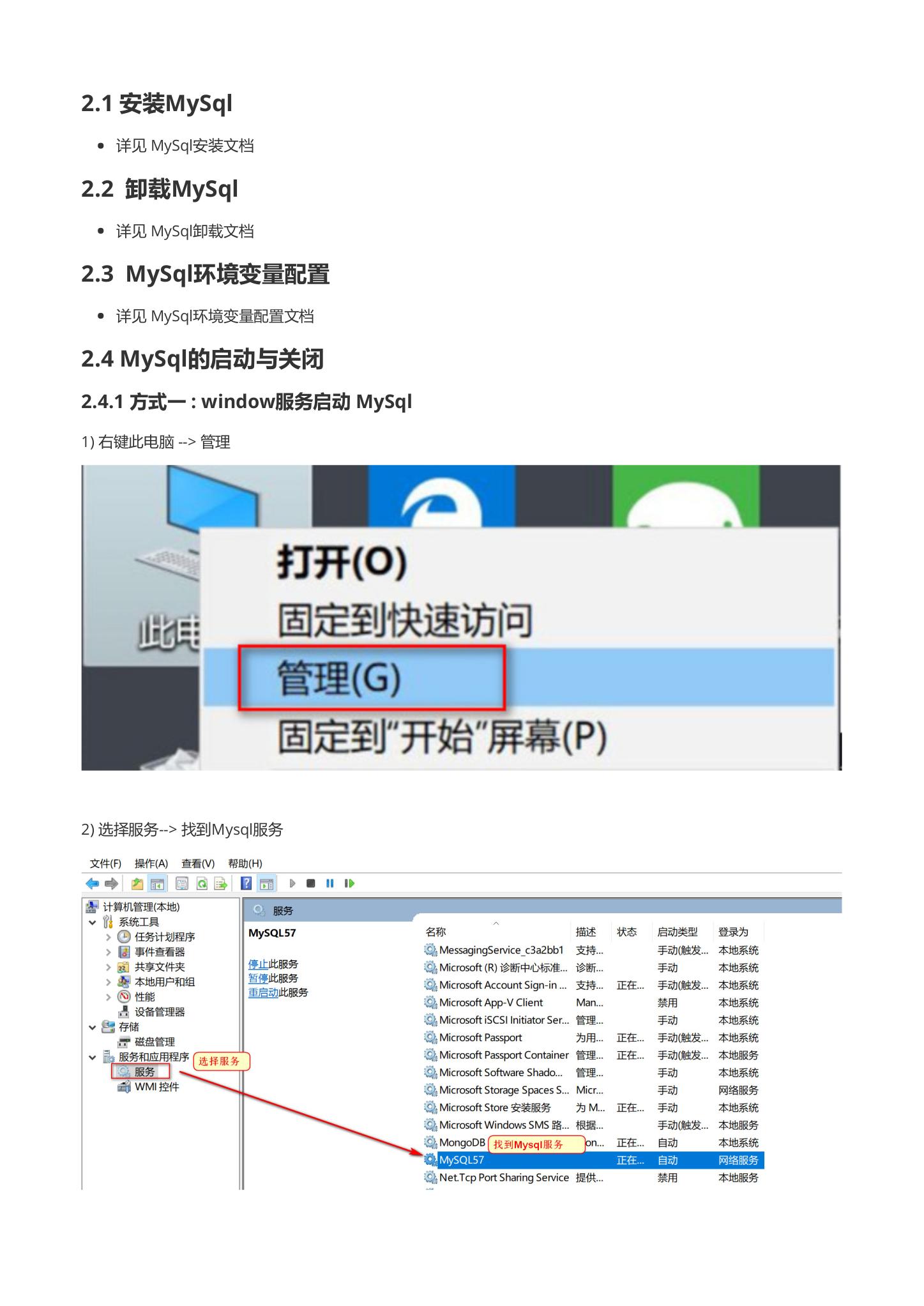
1.右键此电脑 --> 管理
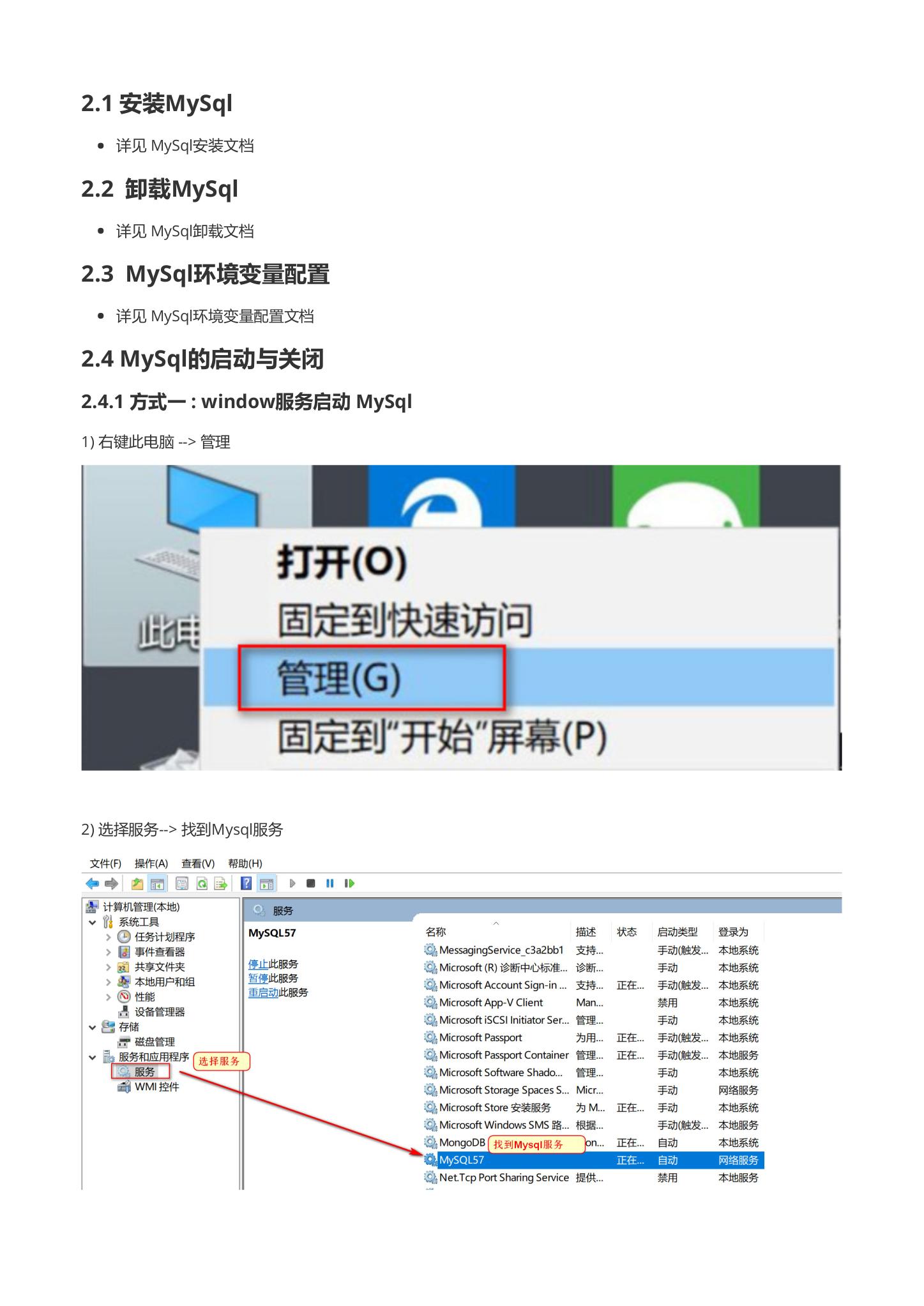
2. 选择服务–> 找到Mysql服务
3.右键选择 --> 启动或停止
| LL L... | 140 | 牛心小沙 | |
|---|---|---|---|
| OUMYSQLE | 正在... | 自动 | 网络服务 |
| :CNet.Top启动(S) | 正在... | 禁用 | 本地服务 |
| :CVNetlogo停止(0) | 手动 | 本地系统 | |
| O. Networ暂停(U) | 手动(触发... | 本地服务 | |
| O Networ恢复(M) | 手动(触发... | 本地系统 | |
| O. Networ重新启动(E) | 手动 | 本地系统 | |
| O. Networ所有任务(K)\( > \) | 手动(触发... | 本地系统 | |
| :C). Networ | 正在... | 手动 | 本地服务 |
| O. Networ刷新(F) | 正在... | 自动 | 网络服务 |
| O. Networ属性(R) | 手动(触发... | 本地系统 | |
| O. Networ帮助(H) | 正在... | 自动 | 本地服务 |
| O NVIDIA | 正在... | 自动 | 本地系统 |
方式二: DOS 命令方式启动
1.首先以管理员身份 打开命令行窗口
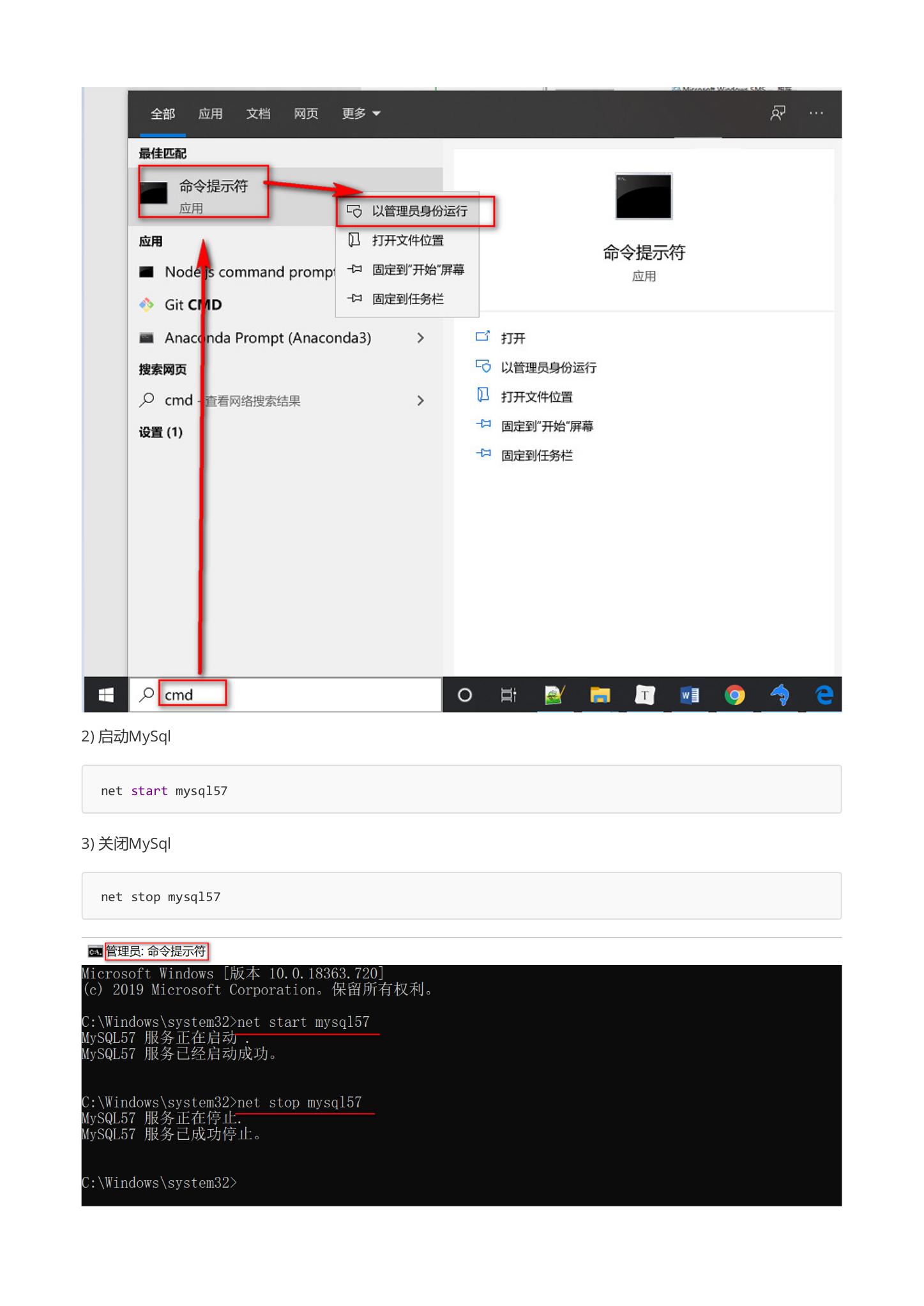
2. 启动MySql
3.关闭MySql
net stop mysql57
@… 管理员: 命令提示符 Microsoft Windows [版本 10.0.18363.720] © 2019 Microsoft Corporation。保留所有权利。 C:\Windows\system32>net start mysql57 MySQL57 服务正在启动 MySQL57 服务已经启动成功。 C:\Windows\system32>net stop mysq157 MySQL57 服务正在停止. MySQL57 服务已成功停止。 C:\Windows\system32>
2.5 命令行登录数据库
MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,使用安装时设置的密码即可登录。
| 命令 | 说明 |
|---|---|
| mysql -u 用户名 -p 密码 | 使用指定用户名和密码登录当前计算机中的MySQL数据库 |
| mysql -h 主机IP -u 用户名 -p 密码 | -h 指定IP 方式,进行登录 |
命令演示: mysql -uroot -p123456 mysql -h127.0.0.1 -uroot -p123456 退出命令 exit 或者 quit
2.6 MySql的目录结构
2.6.1.Mysql安装目录
MySql的默认安装目录在 C:\Program Files\MySQL\MySQL Server 5.7
| 目录 | 目录内容 |
|---|---|
| bin | 放置一些可执行文件 |
| docs | 文档 |
| include | 包含(头)文件 |
| lib | 依赖库 |
| share | 用于存放字符集、语言等信息。 |
2.6.2.Mysql配置文件 与 数据库及 数据表所在目录
本地磁盘 (C:) > ProgramData > MySQL > MySQL Server 5.7
| 名称 | 修改日期 | 类型 | 大小 |
|---|---|---|---|
| Data | 2020/4/16 18:03 | 文件夹 | |
| Uploads | 2020/4/16 18:03 | 文件夹 | |
| \( \square \) installer_config.xml | 2020/4/16 18:03 | XML 文档 | 1 KB |
| \( \square \) my.ini | 2020/4/16 18:03 | 配置设置 | 17 KB |
-
my.ini 文件 是 mysql 的配置文件,一般不建议去修改
-
1 my.ini 2020/4/16 18:03 配置设置 17 KB
-
data<目录> Mysql管理的数据库文件所在的目录
ProgramData > MySQL > MySQL Server 5.7
名称 data目录中保存的就是数据 修改日期 类型库(文件夹)与数据表(文件)的 Data 信息 2020/4/16 18:03 文件夹
- 几个概念
- 数据库:文件夹
- 表: 文件
- 数据: 文件中的记录
2.7 数据库管理系统
2.7.1.什么是数据库管理系统?
-
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理维护数据库的大型软件。
-
MySql就是一个 数据库管理系统软件, 安装了Mysql的电脑,我们叫它数据库服务器.
2.7.2.数据库管理系统的作用
- 用于建立、使用和维护数据库,对数据库进行统一的管理。
2.7.3.数据库管理系统、数据库和表之间的关系
- Mysql中管理着很多数据库,在实际开发环境中 一个数据库一般对应了一个的应用,数据库当中保存着多张表, 每一张表对应着不同的业务,表中保存着对应业务的数据。

2.9 数据库表
-
数据库中以表为组织单位存储数据
-
表类似我们Java中的类,每个字段都有对应的数据类型
那么我们使用熟悉的Java程序来与关系型数据对比,就会发现以下关系:
- 类 -----> 表
- 类中属性 ----> 表中字段
- 对象 ( - - - > ) 数据记录
三、 SQL(重点)
3.1 SQL的概念
3.1.1.什么是SQL?
- 结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
3.1.2.SQL 的作用
-
是所有关系型数据库的统一查询规范,不同的关系型数据库都支持SQL
-
所有的关系型数据库都可以使用SQL
-
不同数据库之间的SQL 有一些区别 方言
3.2 SQL通用语法
- SQL语句可以单行 或者 多行书写,以分号 结尾;(Sqlyog中可以不用写分号)
- 可以使用空格和缩进来增加语句的可读性。
- MySql中使用SQL不区分大小写,一般关键字大写,数据库名 表名列名 小写。
- 注释方式
| 注释语法 | 说明 |
|---|---|
| -- 空格 | 单行注释 |
| /* */ | 多行注释 |
| # | MySql特有的单行注释 |
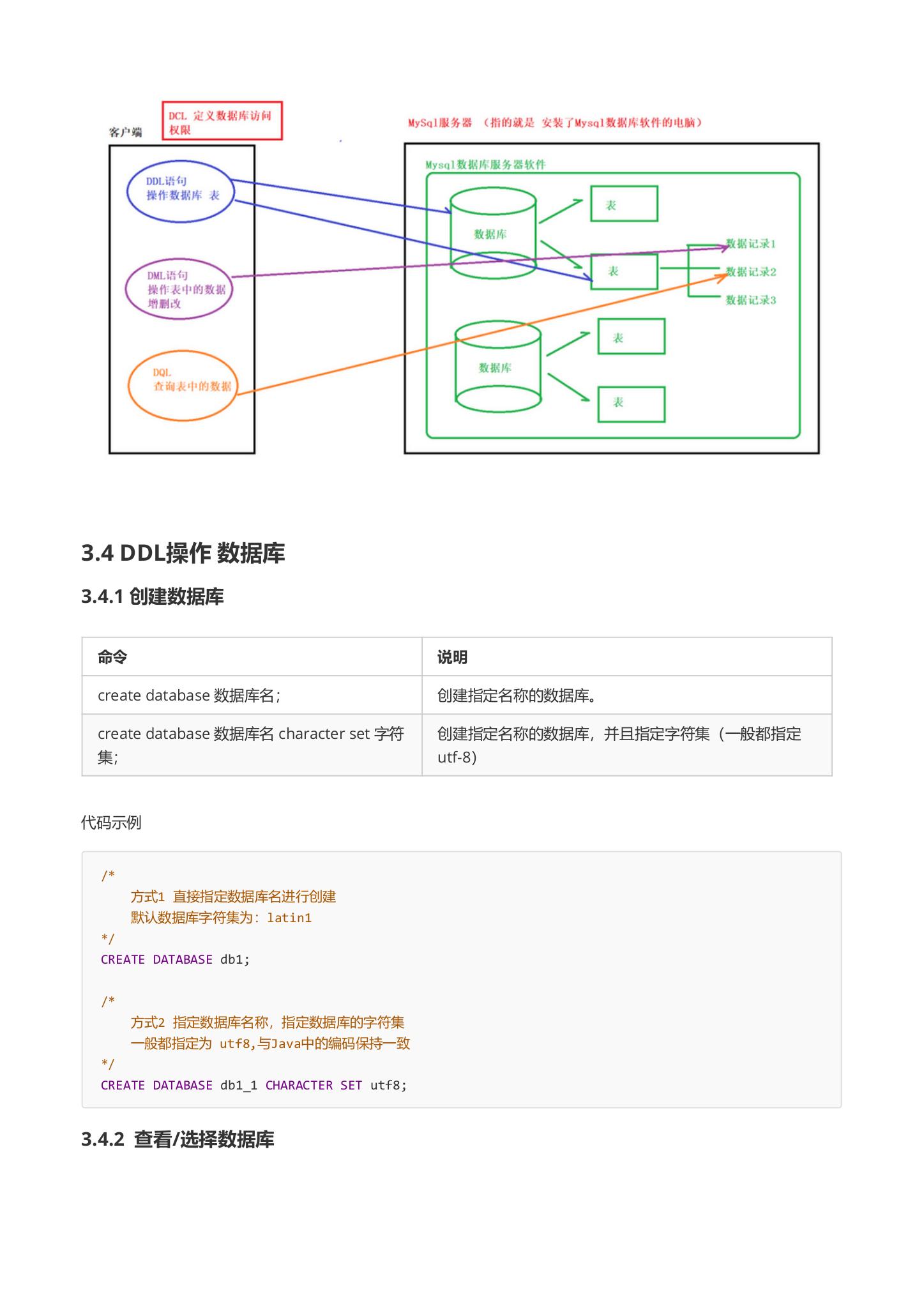
3.3 SQL的分类
| 分类 | 说明 |
|---|---|
| 数据定义语言 | 简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等. |
| 数据操作语言 | 简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新 |
| 数据查询语言 | 简称DQL(Data Query Language),用来查询数据库中表的记录。 |
| 数据控制语言 | 简称DCL(Daat Control Language),用来定义数据库的访问权限和安全级别 及创建用户。(了解) |
3.4 DDL操作 数据库
3.4.1 创建数据库
| 命令 | 说明 |
|---|---|
| create database 数据库名; | 创建指定名称的数据库。 |
| create database 数据库名 character set 字符 集; | 创建指定名称的数据库,并且指定字符集(一般都指定 utf-8) |
3.4.2 查看/选择数据库
| 命令 | 说明 |
|---|---|
| use 数据库 | 切換数据库 |
| select database(); | 查看当前正在使用的数据库 |
| show databases; | 查看Mysql中都有哪些数据库 |
| show create database 数据库名; | 查看一个数据库的定义信息 |
代码示例
-
切換数据库 从db1 切換到 db1_1
- USE db1_1;
-
查看当前正在使用的数据库
- SELECT DATABASE();
-
查看Mysql中有哪些数据库
- SHOW DATABASES;
-
查看一个数据库的定义信息
- SHOW CREATE DATABASE db1_1;
3.4.3 修改数据库
- 修改数据库字符集
| 命令 | 说明 |
|---|---|
| alter database 数据库名 character set 字符集; | 数据库的字符集修改操作 |
-
将数据库db1 的字符集 修改为 utf8
- ALTER DATABASE db1 CHARACTER SET utf8;
-
查看当前数据库的基本信息,发现编码已更改
- SHOW CREATE DATABASE db1;
3.4.4 删除数据库
| 命令 | 说明 |
|---|---|
| drop database 数据库名 | 从MySql中永久的删除某个数据库 |
3.5 DDL 操作 数据表
3.5.1 MySql常见的数据类型
1.常用的数据类型:
| 类型 | 描述 |
|---|---|
| int | 整型 |
| double | 浮点型 |
| varchar | 字符串型 |
| date | 日期类型,给是为 yyyy-MM-dd ,只有年月日,没有时分秒 |
2. 详细的数据类型:
MYSQL的数据类型
| 字段类型 | 中文说明 | 字段说明 | JAVA类型 |
|---|---|---|---|
| 字符串数据类型 | java.lang. String | ||
| char (n) | 固定长度 | 最多255个字符 | java.lang.String |
| varchar (n) | 可变长度 | 最多65535个字符 | java.lang.String |
| tinytext | 可变长度 | 最多255个字符 | java.lang.String |
| text | 可变长度 | 最多65535个字符 | java.lang.String |
| mediumtext | 可变长度 | 最多2的24次方-1个字符 | java.lang.String |
| longtext | 可变长度 | 最多2的32次方-1个字符 | java.lang.String |
| 日期类型 | |||
| date | 3字节,日期 | 格式:2014-09-18 | Date |
| time | 3字节,时间 | 格式:08:42:30 | Date |
| datetime | 8字节,日期时间 | 格式:2014-09-18 08:42:30 | Date |
| timestamp | \( 4 \) 字节,自动存储记录修改的时间 | java.sql.Timestamp | |
| year | 1字节,年份 | Date | |
| 整型类型 | |||
| tinyint | 1字节 | 范围(-128~127) | int |
| smallint | 2字节 | 范围(-32768~32767) | int |
| mediumint | 3字节 | 范围(-8388608~8388607) | int |
| int | 4字节 | 范围(-2147483648~2147483647) | int |
| bigint | 8字节 | 范围(+-9.22*10的18次方) | int |
| 浮点型 | |||
| float(m, d) | 4字节,单精度浮点型 | m总个数,d小数位 | float |
| double(m, d) | 8字节,双精度浮点型 | m总个数,d小数位 | double |
| decimal (m, d) | decimal是存储为字符串的浮点数 | double | |
注意:MySql中的 char类型与 varchar类型,都对应了 Java中的字符串类型,区别在于:
-
char类型是固定长度的: 根据定义的字符串长度分配足够的空间。
-
varchar类型是可变长度的: 只使用字符串长度所需的空间
比如:保存字符串 “abc”
x char(10) 占用10个字节
y varchar(10) 占用3个字节
适用场景:
- char类型适合存储 固定长度的字符串,比如 密码,性别一类
- varchar类型适合存储 在一定范围内,有长度变化的字符串
3.5.2 创建表
语法格式:
CREATE TABLE 表名(
字段名称1 字段类型(长度),
字段名称2 字段类型 注意 最后一列不要加逗号
);
- 需求1:创建商品分类表
- 表名:category
- 表中字段:
- 分类ID : cid ,为整型
- 分类名称:cname,为字符串类型,指定长度20
SQL实现
-- 切換到数据库 db1
USE db1;
-- 创建表
CREATE TABLE category(cid INT,cname VARCHAR(20));
- 需求2:创建测试表
- 表名: test1
- 表中字段:
- 测试ID : tid ,为整型
- 测试时间: tdate ,为年月日的日期类型
SQL实现
-- 创建测试表
CREATE TABLE test1(tid INT,tdate DATE);
- 需求3:快速创建一个表结构相同的表(复制表结构)
语法格式:
create table 新表明 like 旧表名
代码示例
-- 创建一个表结构与 test1 相同的 test2表
CREATE TABLE test2 LIKE test1;
-- 查看表结构
DESC test2;
3.5.3 查看表
| 命令 | 说明 |
|---|---|
| show tables; | 查看当前数据库中的所有表名 |
| desc 表名; | 查看数据表的结构 |
代码示例
-- 查看当前数据库中的所有表名
SHOW TABLES;
-- 显示当前数据表的结构
DESC category;
-- 查看创建表的SQL语句
SHOW CREATE TABLE category;
3.5.4 删除表
| 命令 | 说明 |
|---|---|
| drop table 表名; | 删除表(从数据库中永久删除某一张表) |
| drop table if exists 表名; | 判断表是否存在, 存在的话就删除,不存在就执行删除 |
代码示例
-- 直接删除 test1 表
DROP TABLE test1;
-- 先判断 再删除test2表
DROP TABLE IF EXISTS test2;
3.5.5 修改表
1.修改表名
- 语法格式 rename table 旧表名 to
-- 新表名需求: 将category表 改为 category1
RENAME TABLE category TO category1;
2.修改表的字符集
- 语法格式: alter table 表名 character set 字符集
-- 需求: 将category表的字符集 修改为gbk
alter table category character set gbk;
3.向表中添加列,关键字 ADD
- 语法格式: alert table 表名 add 字段名称 字段类型
-- 需求: 为分类表添加一个新的字段为分类描述 cdesc varchar(20)
ALTER TABLE category ADD cdesc VARCHAR(20);
4.修改表中列的 数据类型或长度 , 关键字 MODIFY
- 语法格式: alter table 表名 modify 字段名称 字段类型
-- 需求:对分类表的描述字段进行修改,类型varchar(50)
ALTER TABLE category MODIFY cdesc VARCHAR(50);
5.修改列名称,关键字 CHANGE
- 语法格式: alter table 表名 change 旧列名 新列名 类型(长度);
-- 需求: 对分类表中的 desc字段进行更换, 更换为 description varchar(30)
ALTER TABLE category CHANGE cdesc description VARCHAR(30);
6.删除列,关键字 DROP
- 语法格式:alter table 表名 drop 列名;
-- 需求:删除分类表中description这列
ALTER TABLE category DROP description;
3.6 DML 操作表中数据
SQL中的DML 用于对表中的数据进行增删改操作
3.6.1 插入数据
语法格式:insert into 表名 (字段名1,字段名2…) values(字段值1,字段值2…);
1.代码准备
- 创建一个学生表:
/*
创建学生表
CREATE TABLE student(
sid INT,
sname VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
);
*/
# 创建学生表
CREATE TABLE student(
sid INT,
sname VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
);
2.向学生表中添加数据,3种方式
- 方式1:插入全部字段,将所有字段名都写出来
INSERT INTO student (sid,sname,age,sex,address) VALUES(1,‘孙悟空’,20,‘男’,‘花果山’);
- 方式2:插入全部字段,不写字段名
INSERT INTO student VALUES(2,‘孙悟饭’,10,‘男’,‘地球’);
- 方式3:插入指定字段的值
INSERT INTO category (cname) VALUES(‘白骨精’);
注意:
-
值与字段必须要对应,个数相同&数据类型相同
-
值的数据大小,必须在字段指定的长度范围内
-
varchar char date类型的值必须使用单引号,或者双引号 包裹。
4.如果要插入空值,可以忽略不写,或者插入null
- 如果插入指定字段的值,必须要上写列名
3.6.2 更改数据
- 语法格式1:不带条件的修改
update 表名 set 列名 = 值
- 语法格式2: 带条件的修改
update 表名 set 列名 = 值 [where 条件表达式: 字段名 = 值 ]
3.6.3 删除数据
- 语法格式1:删除所有数据
delete from 表名
- 语法格式2:指定条件 删除数据
delete from 表名 [where 字段名 = 值]
3.7 DQL 查询表中数据
3.7.1 准备数据
/*
#创建员工表
表名 emp
表中字段:
eid 员工id,int
ename 姓名,varchar
sex 性别,char
salary 薪资,double
hire_date 入职时间,date
dept_name 部门名称,varchar
*/
#创建员工表
CREATE TABLE emp(
eid INT,
ename VARCHAR(20),
sex CHAR(1),
salary DOUBLE,
hire_date DATE,
dept_name VARCHAR(20)
);
#添加数据
INSERT INTO emp VALUES(1,'孙悟空','男',7200,'2013-02-04','教学部');
INSERT INTO emp VALUES(2,'猪八戒','男',3600,'2010-12-02','教学部');
INSERT INTO emp VALUES(3,'唐僧','男',9000,'2008-08-08','教学部');
INSERT INTO emp VALUES(4, '白骨精', '女', 5000, '2015-10-07', '市场部');
INSERT INTO emp VALUES(5,'蜘蛛精','女',5000,'2011-03-14','市场部');
INSERT INTO emp VALUES(6,'玉兔精','女',200,'2000-03-14','市场部');
INSERT INTO emp VALUES(7,'林黛玉','女',10000,'2019-10-07','财务部');
INSERT INTO emp VALUES(8, '黄蓉', '女', 3500, '2011-09-14', '财务部');
INSERT INTO emp VALUES(9,'吴承恩','男',20000,'2000-03-14',NULL);
INSERT INTO emp VALUES(10,'孙悟饭','男', 10,'2020-03-14',财务部);
INSERT INTO emp VALUES(11, '兔八哥', '女', 300, 2010-03-14', 财务部);
3.7.2 简单查询
- 查询不会对数据库中的数据进行修改. 只是一种显示数据的方式 SELECT
语法格式: select 列名 from 表名
-- 需求1:查询emp中的所有数据
-- 使用 * 表示所有列
SELECT * FROM emp;
-- 需求2: 查询emp表中的所有记录,仅显示id和name字段
SELECT eid,ename FROM emp;
-- 需求3: 将所有的员工信息查询出来,并将列名改为中文(别名查询,使用关键字 as)
# 使用 AS关键字, 为列起别名
SELECT
eid AS '编号',
ename AS '姓名' ,
sex AS '性别',
salary AS '薪资',
hire_date '入职时间', -- AS 可以省略
dept_name '部门名称'
FROM emp;
-- 需求4:查询一共有几个部门(使用去重关键字 distinct)
-- 使用distinct 关键字,去掉重复部门信息
SELECT DISTINCT dept_name FROM emp;
-- 需求5: 将所有员工的工资 +1000 元进行显示
-- 运算查询 (查询结果参与运算)
SELECT ename , salary + 1000 FROM emp;
3.7.3 条件查询
如果查询语句中没有设置条件,就会查询所有的行信息,在实际应用中,一定要指定查询条件,对记录进行过滤
- 语法格式: select 列名 from 表名 where 条件表达式
- 先取出表中的每条数据, 满足条件的数据就返回, 不满足的就过滤掉
运算符
1.比较运算符
| 运算符 | 说明 |
|---|---|
| y < <= y= = => != | 大于、小于、大于(小于)等于、不等于 |
| BETWEEN ...AND... | 显示在某一区间的值 例如: 2000-10000之间: Between 2000 and 10000 |
| IN(集合) | 集合表示多个值,使用逗号分隔,例如: name in (悟空,八戒) in中的每个数据都会作为一次条件,只要满足条件就会显示 |
| LIKE '%张%' | 模糊查询 |
| IS NULL | 查询某一列为NULL的值, 注: 不能写 = NULL |
2.逻辑运算符
| 运算符 | 说明 |
|---|---|
| And && | 多个条件同时成立 |
| Or || | 多个条件任一成立 |
| Not | 不成立,取反。 |
需求:
# 查询员工姓名为黄蓉的员工信息
SELECT * FROM emp WHERE ename = '黃蓉';
# 查询薪水价格为5000的员工信息
SELECT * FROM emp WHERE salary = 5000;
# 查询薪水价格不是5000的所有员工信息
SELECT * FROM emp WHERE salary != 5000;
SELECT * FROM emp WHERE salary <> 5000;
# 查询薪水价格大于6000元的所有员工信息
SELECT * FROM emp WHERE salary > 6000;
# 查询薪水价格在5000到10000之间所有员工信息
SELECT * FROM emp WHERE salary BETWEEN 5000 AND 10000;
# 查询薪水价格是3600或7200或者20000的所有员工信息
-- 方式1:or
SELECT * FROM emp WHERE salary = 3600 OR salary = 7200 OR salary = 20000;
-- 方式2: in() 匹配括号中指定的参数
SELECT * FROM emp WHERE salary IN(3600,7200,20000);
3.模糊查询 通配符
| 通配符 | 说明 |
|---|---|
| % | 表示匹配任意多个字符串 |
| \( = \) | 表示匹配 一个字符 |
# 查询含有'精'字的所有员工信息
SELECT * FROM emp WHERE ename LIKE '%精%';
# 查询以'孙'开头的所有员工信息
SELECT * FROM emp WHERE ename LIKE '孙%';
# 查询第二个字为 '兔'的所有员工信息
SELECT * FROM emp WHERE ename LIKE '_兔%';
# 查询没有部门的员工信息
SELECT * FROM emp WHERE dept_name IS NULL;
-- SELECT * FROM emp WHERE dept_name = NULL;
# 查询有部门的员工信息
SELECT * FROM emp WHERE dept_name IS NOT NULL;
四、单表&约束
4 .1 DQL操作单表
4.1.1 创建数据库,复制表
- 创建一个新的数据库 db2
CREATE DATABASE db2 CHARACTER SET utf8;
- 将db1数据库中的 emp表 复制到当前 db2数据库
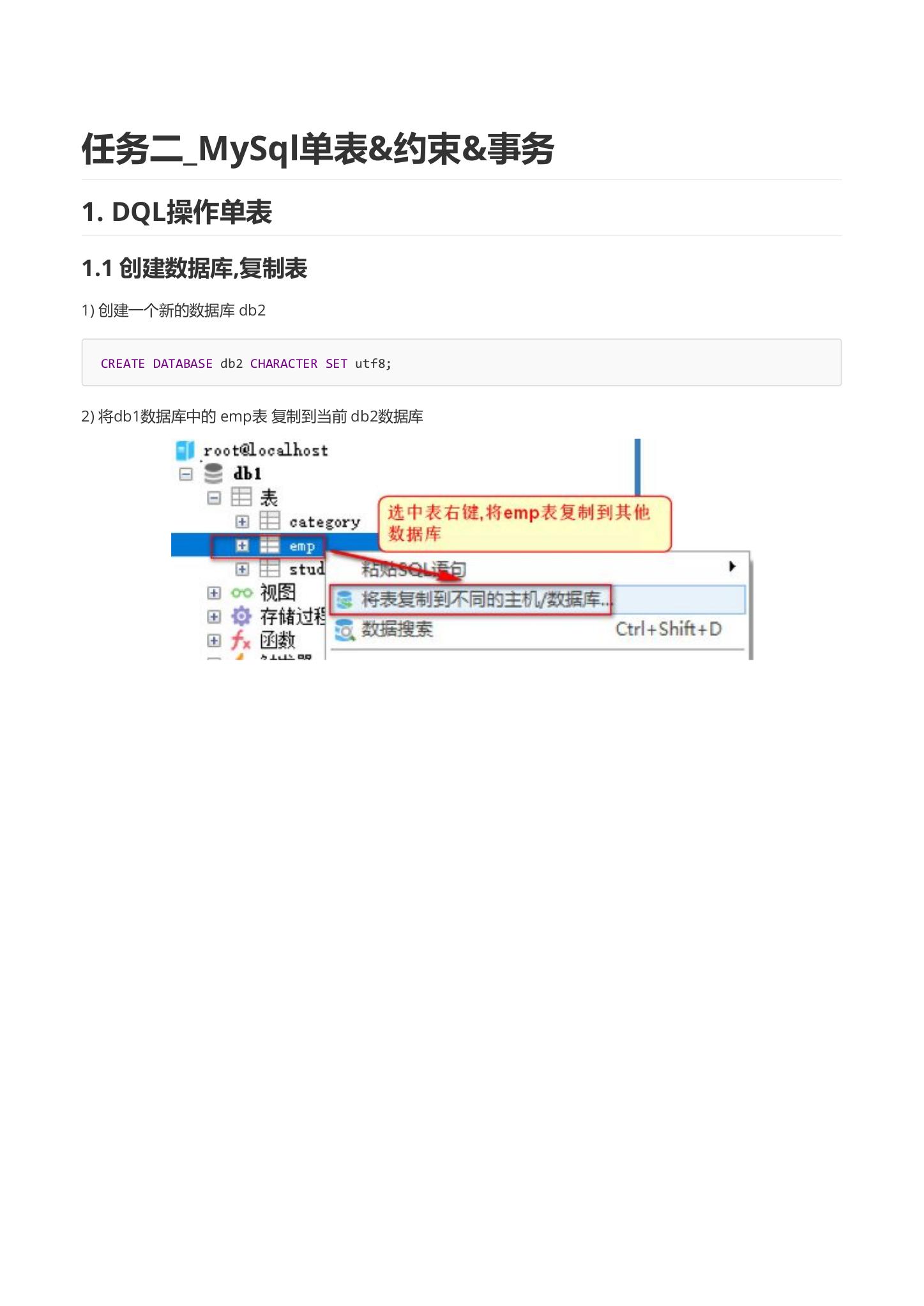
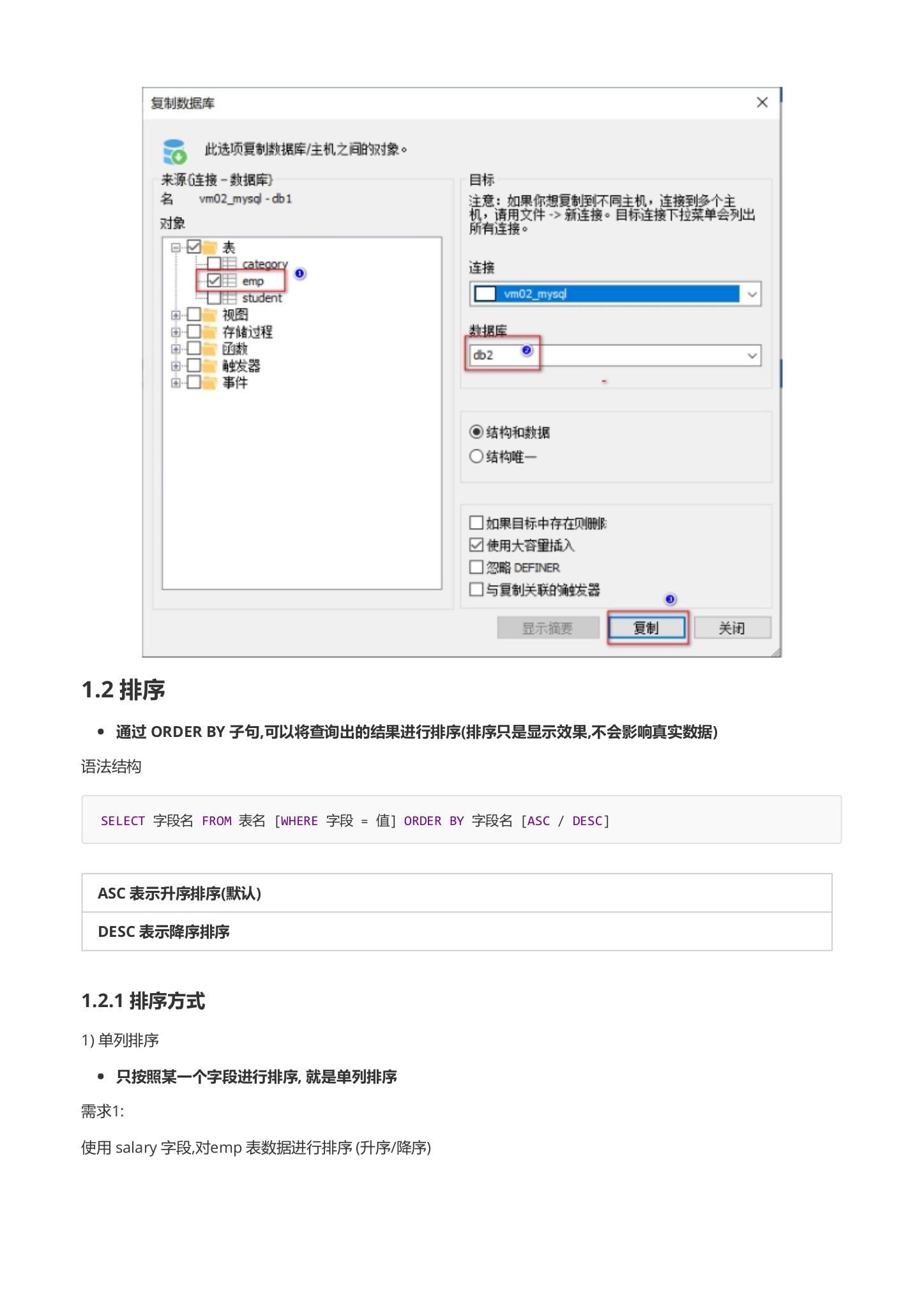
4.1.2 排序
- 通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据) 语法结构
- SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
- ASC 表示升序排序(默认)
- DESC 表示降序排序
4.1.2.1单列排序
- 只按照某一个字段进行排序, 就是单列排序
# 需求1:使用 salary 字段,对emp 表数据进行排序 (升序/降序)
-- 默认升序排序 ASC
SELECT * FROM emp ORDER BY salary;
-- 降序排序
SELECT * FROM emp ORDER BY salary DESC;
4.1.2.2组合排序
- 同时对多个字段进行排序, 如果第一个字段相同 就按照第二个字段进行排序, 以此类推
# 需求2:
-- 在薪水排序的基础上,再使用id进行排序, 如果薪水相同就以id 做降序排序
-- 组合排序
SELECT * FROM emp ORDER BY salary DESC, eid DESC;
4.1.3 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空值。
- 语法结构
SELECT 聚合函数(字段名) FROM 表名;
- 5个聚合函数
| 聚合函数 | 作用 |
|---|---|
| count(字段) | 统计指定列不为NULL的记录行数 |
| sum(字段) | 计算指定列的数值和 |
| max(字段) | 计算指定列的最大值 |
| min(字段) | 计算指定列的最小值 |
| avg(字段) | 计算指定列的平均值 |
#1 查询员工的总数
-- 统计表中的记录条数 使用 count()
SELECT COUNT(eid) FROM emp; -- 使用某一个字段
SELECT COUNT(*) FROM emp; -- 使用 *
SELECT COUNT(1) FROM emp; -- 使用 1,与 * 效果一样
-- 下面这条SQL 得到的总条数不准确, 因为count函数忽略了空值
-- 所以使用时注意不要使用带有null的列进行统计
SELECT COUNT(dept_name) FROM emp;
#2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值
-- sum函数求和,max函数求最大,min函数求最小,avg函数求平均值
SELECT
SUM(salary) AS '总薪水',
MAX(salary) AS '最高薪水',
MIN(salary) AS '最低薪水',
AVG(salary) AS '平均薪水'
FROM emp;
#3 查询薪水大于4000员工的个数
SELECT COUNT(*) FROM emp WHERE salary > 4000;
#4 查询部门为 '教学部' 的所有员工的个数
SELECT COUNT(*) FROM emp WHERE dept_name = '教学部';
#5 查询部门为 '市场部' 所有员工的平均薪水
SELECT
AVG(salary) AS '市场部平均薪资'
FROM emp
WHERE dept_name = '市场部';
4.1.4 分组
- 分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
语法格式:
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
案例1
- 通过性别字段 进行分组 – 按照性别进行分组操作
SELECT * FROM emp GROUP BY sex; – 注意 这样写没有意义
GROUP BY 分组过程
- 原始数据
| \( \square \) | eid | ename | Asex | salary | hire_date | dept_name |
|---|---|---|---|---|---|---|
| \( \square \) | 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| \( \square \) | 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| \( \square \) | 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| \( \square \) | 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| \( \square \) | 8 | 黃蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| \( \square \) | 11 | 兔八哥 | 女 | 300 | 2010-03-14 | 财务部 |
| \( \square \) | 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| \( \square \) | 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| \( \square \) | 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| \( \square \) | 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | (NULL) |
| \( \square \) | 10 | 孙悟饭 | 男 | 10 | 2020-04-21 | (NULL) |
- 分组操作第一步,将性别相同的数据, 分为一组, 分了两组

- 分组的第二步,返回每组的第一条数据, 所以我们的结果是这样的
| eld | ename | sex | salary | hire_date | dept_name |
|---|---|---|---|---|---|
| 到白骨精 | 女 | 5000 | 2015-10-07 | 市场部 | |
| A 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
注意:
-
分组的目的 就是为了统计, 所以一般分组会与聚合函数一起使用, 单独进行分组 是没有意义的.
-
分组时可以查询要分组的字段, 或者使用聚合函数进行统计操作.
- 查询其他字段没有意义需求: 通过性别字段 进行分组, 求各组的平均薪资
SELECT sex, AVG(salary) FROM emp GROUP BY sex;
案例2
## 1. 查询有几个部门
SELECT dept_name AS '部门名称' FROM emp GROUP BY dept_name;
#2.查询每个部门的平均薪资
SELECT
dept_name AS '部门名称',
AVG(salary) AS '平均薪资'
FROM emp GROUP BY dept_name;
#3.查询每个部门的平均薪资,部门名称不能为null
SELECT
dept_name AS '部门名称',
AVG(salary) AS '平均薪资'
FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name;
案例3
- 查询平均薪资大于6000的部门.
分析:
-
需要在分组后,对数据进行过滤,使用关键字 hiving
-
分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
SQL实现:
# 查询平均薪资大于6000的部门
-- 需要在分组后再次进行过滤,使用 having
SELECT
dept_name ,
AVG(salary)
FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name HAVING AVG(salary) > 6000 ;
- where 与 having的区别
| 过滤方式 | 特点 |
|---|---|
| where | where 进行分组前的过滤 where 后面不能写 聚合函数 |
| having | having 是分组后的过滤 having 后面可以写 聚合函数 |
4.1.5 limit关键字
limit 关键字的作用
-
limit是限制的意思,用于限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
-
limit 语法是 MySql的方言,用来完成分页
语法结构:
SELECT 字段1,字段2... FROM 表名 LIMIT offset , length;
参数说明:
| limit offset,length;关键字可以接受一个或者两个 为0 或者正整数的参数 |
| offset 起始行数, 从0开始记数, 如果省略 则默认为 0 . |
| length 返回的行数 |
# 需求1:
# 查询emp表中的前 5条数据
-- 参数1 起始值,默认是0 , 参数2 要查询的条数
SELECT * FROM emp LIMIT 5;
SELECT * FROM emp LIMIT 0 , 5;
# 查询emp表中 从第4条开始,查询6条
-- 起始值默认是从0开始的.
SELECT * FROM emp LIMIT 3 , 6;
#需求2:
-- 分页操作 每页显示3条数据
SELECT * FROM emp LIMIT 0,3; -- 第1页
SELECT * FROM emp LIMIT 3,3; -- 第2页 2-1=1 1*3=3
SELECT * FROM emp LIMIT 6,3; -- 第三页
-- 分页公式 起始索引 = (当前页 - 1) * 每页条数
-- limit是MySql中的方言
4.2 SQL约束
- 约束的作用
对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性. 违反约束的不正确数据,将无法插入到表中
- 常见的约束
| 约束名 | 约束关键字 |
|---|---|
| 主键 | primary key |
| 唯一 | unique |
| 非空 | not null |
| 外键 | foreign key |
4.2.1 主键约束
| 特点 | 不可重复 唯一 非空 |
|---|---|
| 作用 | 用来表示数据库中的每一条记录 |
4.2.1.1 添加主键约束
语法格式
字段名 字段类型 primary key
# 方式1 创建一个带主键的表
CREATE TABLE emp2(
-- 设置主键 唯一 非空
eid INT PRIMARY KEY,
ename VARCHAR(20),
sex CHAR(1)
);
-- 删除表
DROP TABLE emp2;
-- 方式2 创建一个带主键的表
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1),
-- 指定主键为 eid字段
PRIMARY KEY(eid)
);
-- 方式3 创建一个带主键的表
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1)
)
-- 创建的时候不指定主键,然后通过 DDL语句进行设置
ALTER TABLE emp2 ADD PRIMARY KEY(eid);
- DESC 查看表结构
-- 查看表的详细信息
DESC emp2;
- 测试主键的唯一性 非空性
#正常插入一条数据
INSERTINTOemp2VALUES(1,'宋江','男');
#插入一条数据,主键为空
--Column'eid'cannotbenull主键不能为空
INSERTINTOemp2VALUES(NULL,'李逵','男');
#插入一条数据,主键为1
--Duplicateentry'1'forkey'PRIMARY'主键不能重复INSERTINTOemp2VALUES(1,'孙二娘','女');
- 哪些字段可以作为主键?
- 通常针对业务去设计主键, 每张表都设计一个主键id
- 主键是给数据库和程序使用的,跟最终的客户无关,所以主键没有意义没有关系,只要能够保证不重复就好,比如身份证就可以作为主键.
4.2.1.2 删除主键约束
- 删除表中的主键约束 (了解)
-- 使用DDL语句 删除表中的主键
ALTER TABLE emp2 DROP PRIMARY KEY;
DESC emp2;
4.2.1.3 主键的自增
注: 主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值.
关键字:
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
1) 创建主键自增的表
## -- 创建主键自增的表
CREATE TABLE emp2(
-- 关键字 AUTO_INCREMENT, 主键类型必须是整数类型
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
);
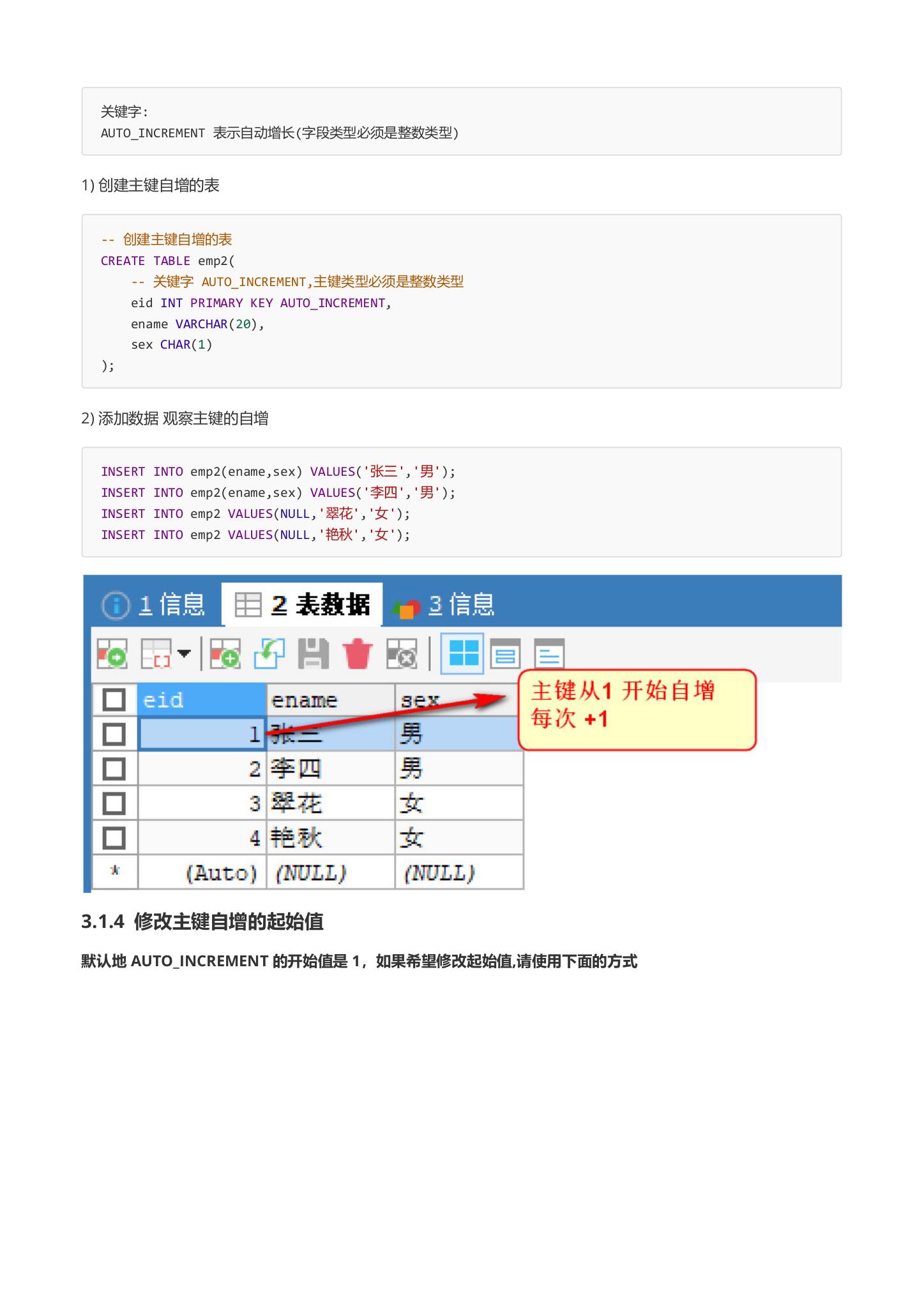
2) 添加数据 观察主键的自增
INSERT INTO emp2(ename,sex) VALUES('张三','男');
INSERT INTO emp2(ename,sex) VALUES('李四','男');
INSERT INTO emp2 VALUES(NULL,'翠花','女');
INSERT INTO emp2 VALUES(NULL,'艳秋','女');
4.2.1.4 修改主键自增的起始值
默认地 AUTO_INCREMENT 的开始值是 1 ,如果希望修改起始值, 请使用下面的方式
## -- 创建主键自增的表,自定义自增其实值
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
-- 插入数据,观察主键的起始值
INSERT INTO emp2(ename,sex) VALUES('张百万','男');
INSERT INTO emp2(ename, sex) VALUES('艳秋', '女');
4.2.1.5 DELETE和TRUNCATE对自增长的影响
- 删除表中所有数据有两种方式
| 清空表数据的方式 | 特点 |
|---|---|
| DELETE | 只是删除表中所有数据,对自增没有影响 |
| TRUNCATE | truncate 是将整个表删除掉,然后创建一个新的表 自增的主键,重新从 1 开始 |
测试1: delete 删除表中所有数据
-- 目前最后的主键值是 101
SELECT * FROM emp2;
-- delete 删除表中数据,对自增没有影响
DELETE FROM emp2;
-- 插入数据 查看主键
INSERT INTO emp2(ename,sex) VALUES('张百万','男');
INSERT INTO emp2(ename,sex) VALUES('艳秋','女');
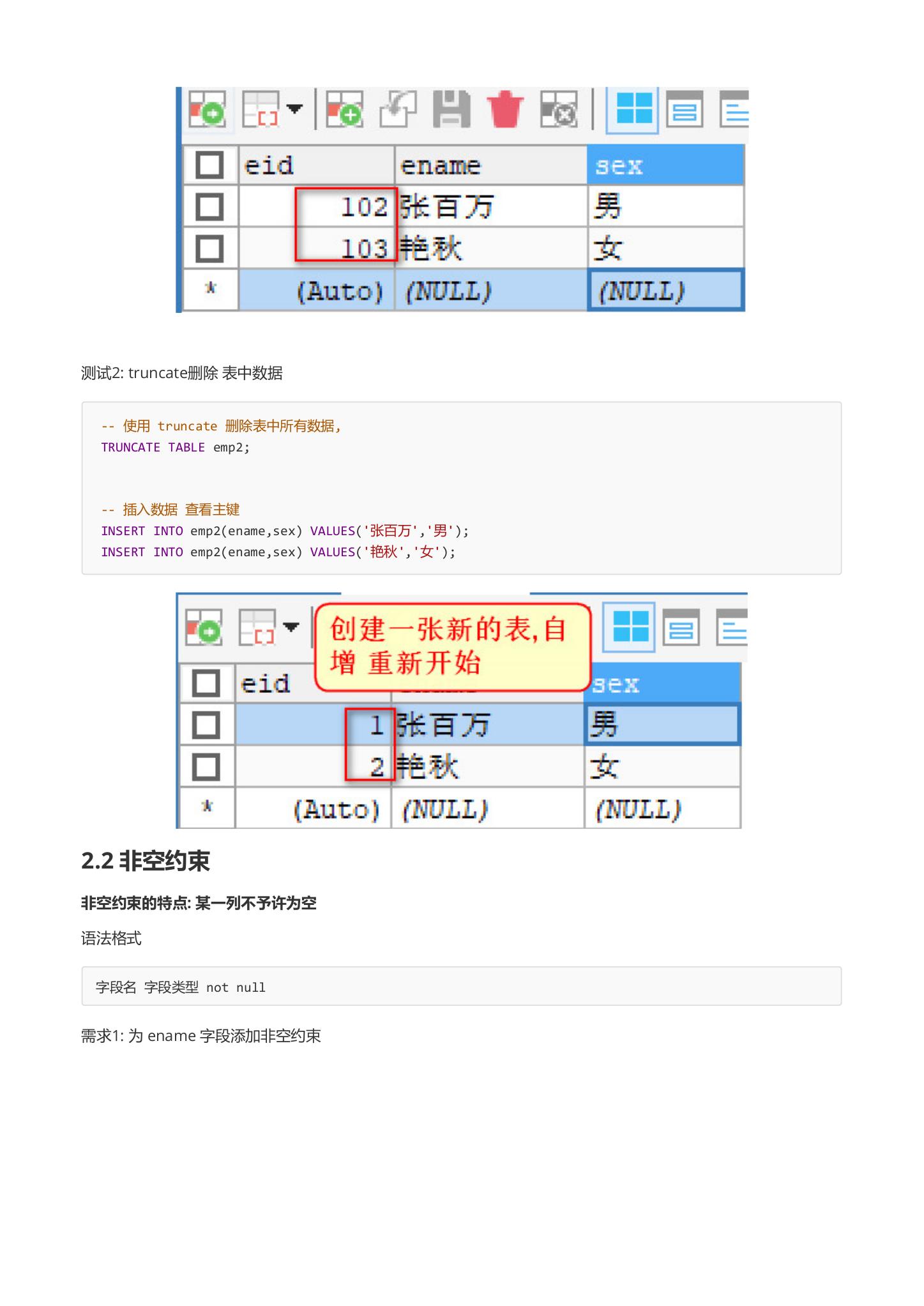
测试2: truncate删除 表中数据
-- 使用 truncate 删除表中所有数据,
TRUNCATE TABLE emp2;
-- 插入数据 查看主键
INSERT INTO emp2(ename, sex) VALUES('张百万','男');
INSERT INTO emp2(ename, sex) VALUES('艳秋','女');
4.2.2 非空约束
- 非空约束的特点: 某一列不予许为空
语法格式
字段名 字段类型 not null
需求1: 为 ename 字段添加非空约束
## # 非空约束
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- 添加非空约束,ename字段不能为空
ename VARCHAR(20) NOT NULL,
sex CHAR(1)
);
4.2.3 唯一约束
- 唯一约束的特点: 表中的某一列的值不能重复(对null不做唯一的判断)
语法格式
字段名 字段值 unique
- 添加唯一约束
#创建emp3表 为ename 字段添加唯一约束
CREATE TABLE emp3(
eidINTPRIMARYKEYAUTO_INCREMENT,
enameVARCHAR(20)UNIQUE,
sexCHAR(1)
);
主键约束与唯一约束的区别: 1. 主键约束 唯一且不能够为空 2. 唯一约束,唯一 但是可以为空 3. 一个表中只能有一个主键,但是可以有多个唯一约束
4.2.4 外键约束
- FOREIGN KEY 表示外键约束,将在多表中学习。
4.2.5 默认值
- 默认值约束 用来指定某列的默认值
语法格式
字段名 字段类型 DEFAULT 默认值
五、数据库事务
5.1 什么是事务
-
事务是一个整体,由一条或者多条SQL 语句组成,这些SQL语句要么都执行成功,要么都执行失败,只要有一条SQL出现异常,整个操作就会回滚,整个业务执行失败
- 比如: 银行的转账业务,张三给李四转账500元 , 至少要操作两次数据库, 张三 -500, 李四 + 500,这中间任何一步出现问题, 整个操作就必须全部回滚, 这样才能保证用户和银行都没有损失.
-
回滚
即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,滚回到事务开始时的状态。(在提交之前执行)
5.2 模拟转账操作
- 创建 账户表
-- 创建账户表
CREATE TABLE account(
-- 主键
id INT PRIMARY KEY AUTO_INCREMENT,
-- 姓名
NAME VARCHAR(10),
-- 余额
money DOUBLE
);
-- 添加两个用户
INSERT INTO account (NAME, money) VALUES ('tom', 1000), ('jack', 1000);
- 模拟tom 给 jack 转 500 元钱,一个转账的业务操作最少要执行下面的 2 条语句: 注:
-- tom账户 -500元
UPDATE account SET money = money - 500 WHERE NAME = 'tom';
-- jack账户 + 500元
UPDATE account SET money = money + 500 WHERE NAME = 'jack';
假设当tom 账号上 -500 元,服务器崩溃了。jack 的账号并没有+500 元,数据就出现问题了。
我们要保证整个事务执行的完整性,要么都成功, 要么都失败. 这个时候我们就要学习如何操作事务.
5.3 MySql事务操作
- MYSQL 中可以有两种方式进行事务的操作:
- 手动提交事务
- 自动提交事务
5.3.1 手动提交事务
5.3.1.1 语法格式
| 功能 | 语句 |
|---|---|
| 开启事务 | start transaction; 或者 BEGIN; |
| 提交事务 | commit; |
| 回滚事务 | rollback; |
- START TRANSACTION
。这个语句显式地标记一个事务的起始点。
- COMMIT
。 表示提交事务,即提交事务的所有操作,具体地说,就是将事务中所有对数据库的更新都写到磁盘上的物理数据库中,事务正常结束。
- ROLLBACK
。 表示撤销事务,即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态
5.3.1.2 手动提交事务流程
-
执行成功的情况: 开启事务 ( \sim ) 执行多条 ( \mathrm{{SQL}} ) 语句 ( \sim ) 成功提交事务
-
执行失败的情况: 开启事务 ( \sim ) 执行多条 SQL 语句 ( \rightarrow ) 事务的回滚

注:
如果事务中 SQL 语句没有问题,commit 提交事务,会对数据库数据的数据进行改变。 如果事务中 SQL 语句有问题,rollback 回滚事务,会回退到开启事务时的状态。
5.3.2 自动提交事务
-
MySQL 默认每一条 DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,语句执行完毕 自动提交事务,MySQL 默认开始自动提交事务
-
MySQL默认是自动提交事务
5.4 事务的四大特性 ACID
| 特性 | 含义 |
|---|---|
| 原子性 | 每个事务都是一个整体,不可再拆分,事务中所有的 SQL 语句要么都执行成功, 要么都失败。 |
| 一致性 | 事务在执行前数据库的状态与执行后数据库的状态保持一致。如:转账前2个人的 总金额是 200 转账后 2 个人总金额也是 2000. |
| 隔离性 | 事务与事务之间不应该相互影响,执行时保持隔离的状态 |
| 持久性 | 一旦事务执行成功,对数据库的修改是持久的。就算关机,数据也是要保存下来的. |
5.5 Mysql 事务隔离级别
5.5.1 数据并发访问
一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库. 数据库的相同数据可能被多个事务同时访问,如果不采取隔离措施,就会导致各种问题, 破坏数据的完整性
5.5.2 并发访问会产生的问题
事务在操作时的理想状态: 所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个 数据。可能引发并发访问的问题
| 并发访问 的问题 | 说明 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务中尚未提交的数据 |
| 不可重复 读 | 一个事务中两次读取的数据内容不一致, 要求的是在一个事务中多次读取时数据是一致的. 这 是进行 update 操作时引发的问题 |
| 幻读 | 一个事务中,某一次的 select 操作得到的结果所表征的数据状态, 无法支撑后续的业务操作. 查 询得到的数据状态不准确,导致幻读. |
5.5.3 四种隔离级别
通过设置隔离级别,可以防止上面的三种并发问题. MySQL数据库有四种隔离级别 上面的级别最低,下面的级别最高。
-
( y ) 会出现问题
-
( n ) 不会出现问题

5.5.4 隔离级别相关命令
- 设置事务隔离级别,需要退出 MySQL 再重新登录才能看到隔离级别的变化
set global transaction isolation level # 级别名称;
read uncommitted # 读未提交
read committed # 读已提交
repeatable read # 可重复读
serializable # 串行化
-- 例如: 修改隔离级别为 读未提交
set global transaction isolation level read uncommitted;
5.6 隔离性问题
5.6.1 解决脏读问题
- 脏读非常危险的,比如张三向李四购买商品,张三开启事务,向李四账号转入 500 块,然后打电话给李四说钱 已经转了。李四一查询钱到账了,发货给张三。张三收到货后回滚事务,李四的再查看钱没了。
解决:
- 将全局的隔离级别进行提升为: read committed
5.6.2 不可重复读
- 不可重复读: 同一个事务中,进行查询操作,但是每次读取的数据内容是不一样的
解决:
- 将全局的隔离级别进行提升为: repeatable read
5.6.3 幻读
- 幻读: select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入, 此时就发生了幻读。
解决:
- 将事务隔离级别设置到最高 SERIALIZABLE ,以挡住幻读的发生
如果一个事务,使用了SERIALIZABLE——可串行化隔离级别时,在这个事务没有被提交之前,其他的线程, 只能等到当前操作完成之后,才能进行操作,这样会非常耗时,而且,影响数据库的性能,数据库不会使用这种隔离级别
六、表设计
6.1. 多表关系设计
实际开发中,一个项目通常需要很多张表才能完成。例如:一个商城项目就需要分类表(category)、商品表 (products)、订单表(orders)等多张表。且这些表的数据之间存在一定的关系,接下来我们一起学习一下多表关系设计方面的知识
| 表与表之间的三种关系 |
|---|
| 一对多关系: 最常见的关系, 学生对班级,员工对部门 |
| 多对多关系: 学生与课程, 用户与角色 |
| 一对一关系:使用较少,因为一对一关系可以合成为一张表 |
6.1.1 一对多关系(常见)
-
一对多关系 (1:n)
- 例如:班级和学生,部门和员工,客户和订单,分类和商品
-
一对多建表原则
- 在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
-
一对多关系 在多的一方建立外键, 指向一的一方的主键
employee 员工表 :
| eid | ename | age | dept_id |
|---|---|---|---|
| 1 | 张百万 | 18 | 2 |
| 2 | 广坤 | 48 | 1 |
department 部门表:
| id | dept_name |
|---|---|
| 1 | 市场部 |
| 2 | 财务部 |
6.1.2 多对多关系(常见)
-
多对多 (m:n)
- 例如:老师和学生,学生和课程,用户和角色
-
n 多对多关系建表原则
- 需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的 主键。
多对多关系:
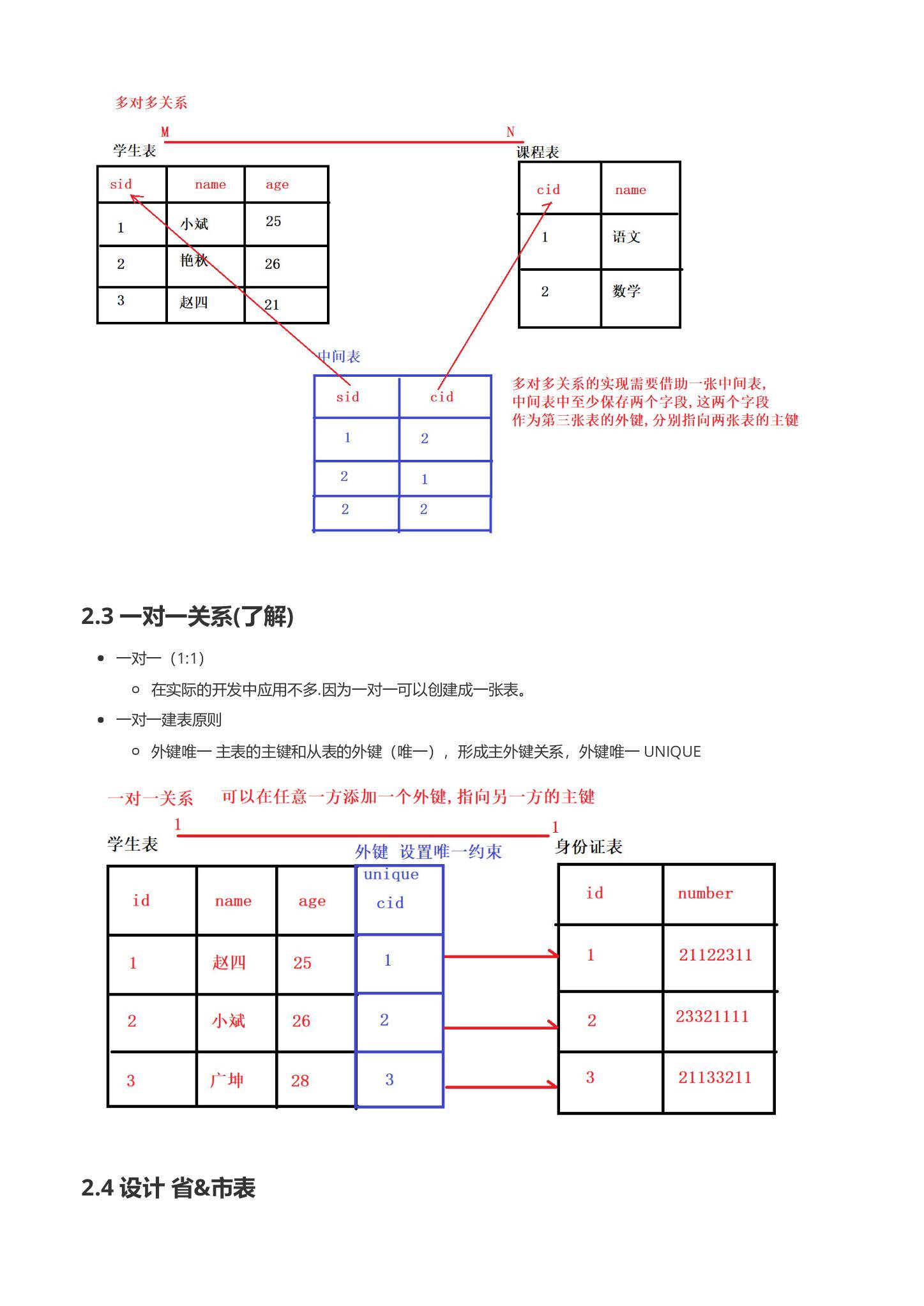
史间表:
多对多关系的实现需要借助一张中间表, 中间表中至少保存两个字段, 这两个字段作为第三张表的外键, 分别指向两张表的主键
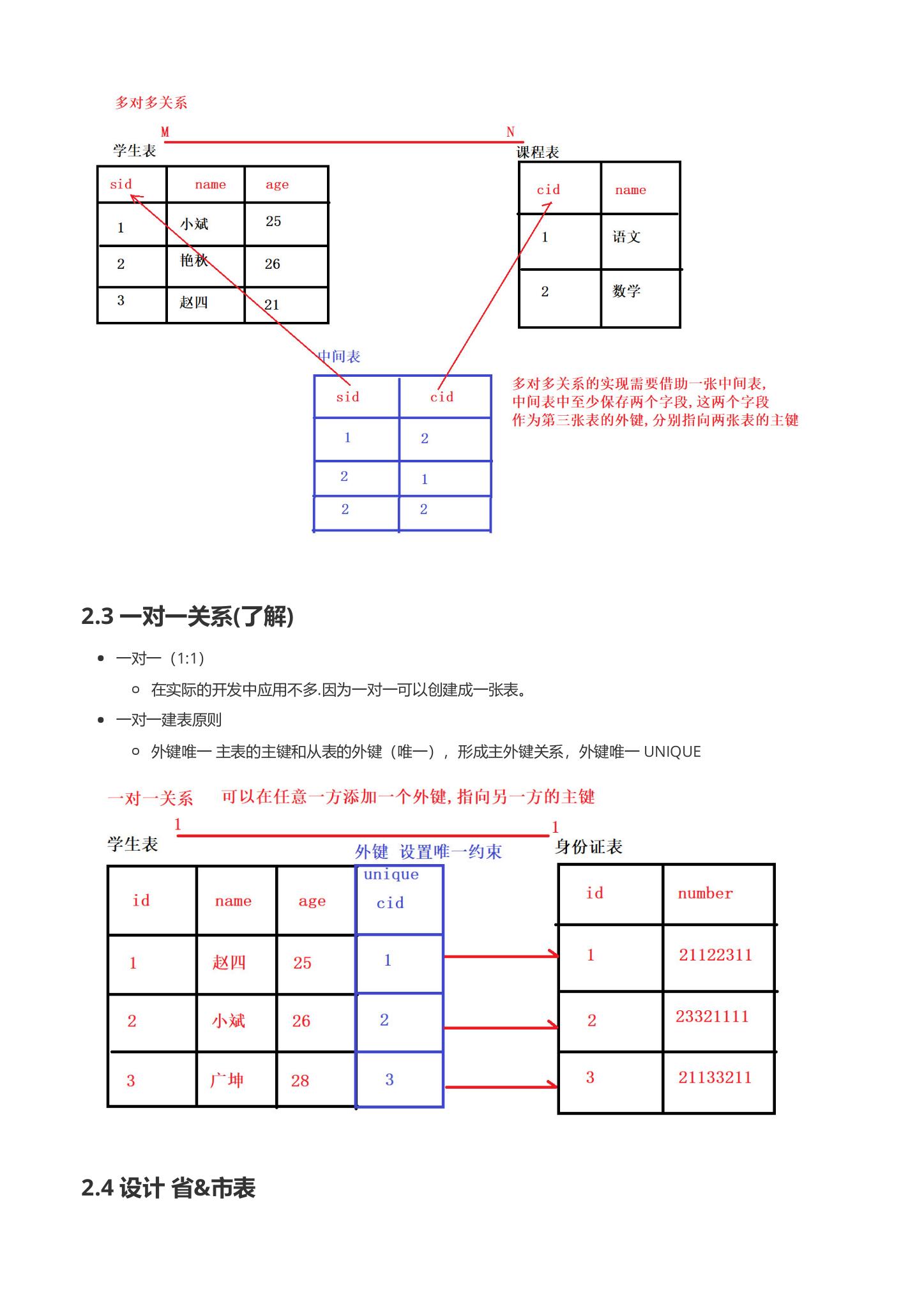
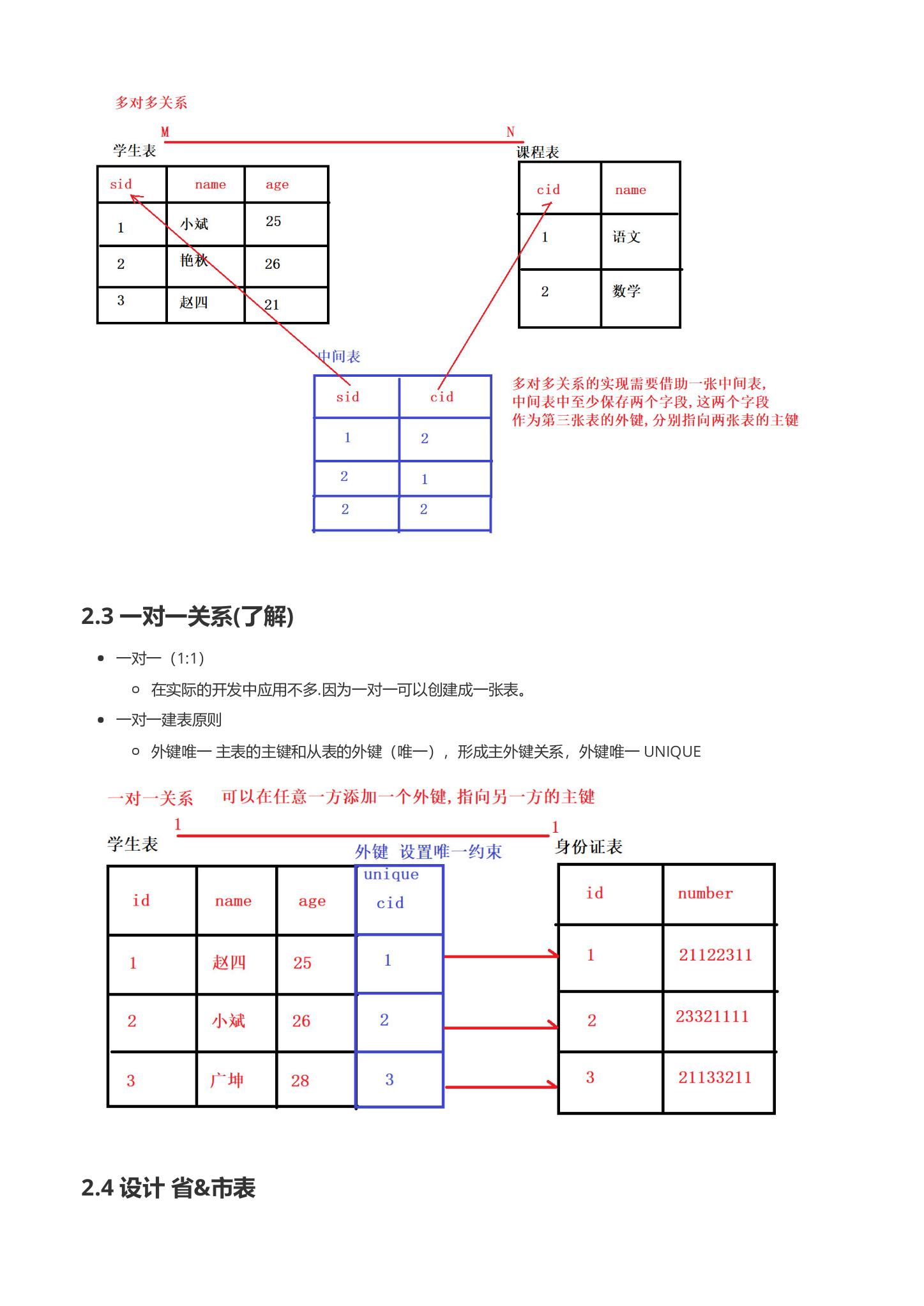
6.1.3 一对一关系(了解)
-
一对一 (1:1)
- 在实际的开发中应用不多.因为一对一可以创建成一张表。
-
一对一建表原则
- 外键唯一 主表的主键和从表的外键(唯一),形成主外键关系,外键唯一 UNIQUE
一对一关系 可以在任意一方添加一个外键, 指向另一方的主键
6.1.4 设计 省&市表
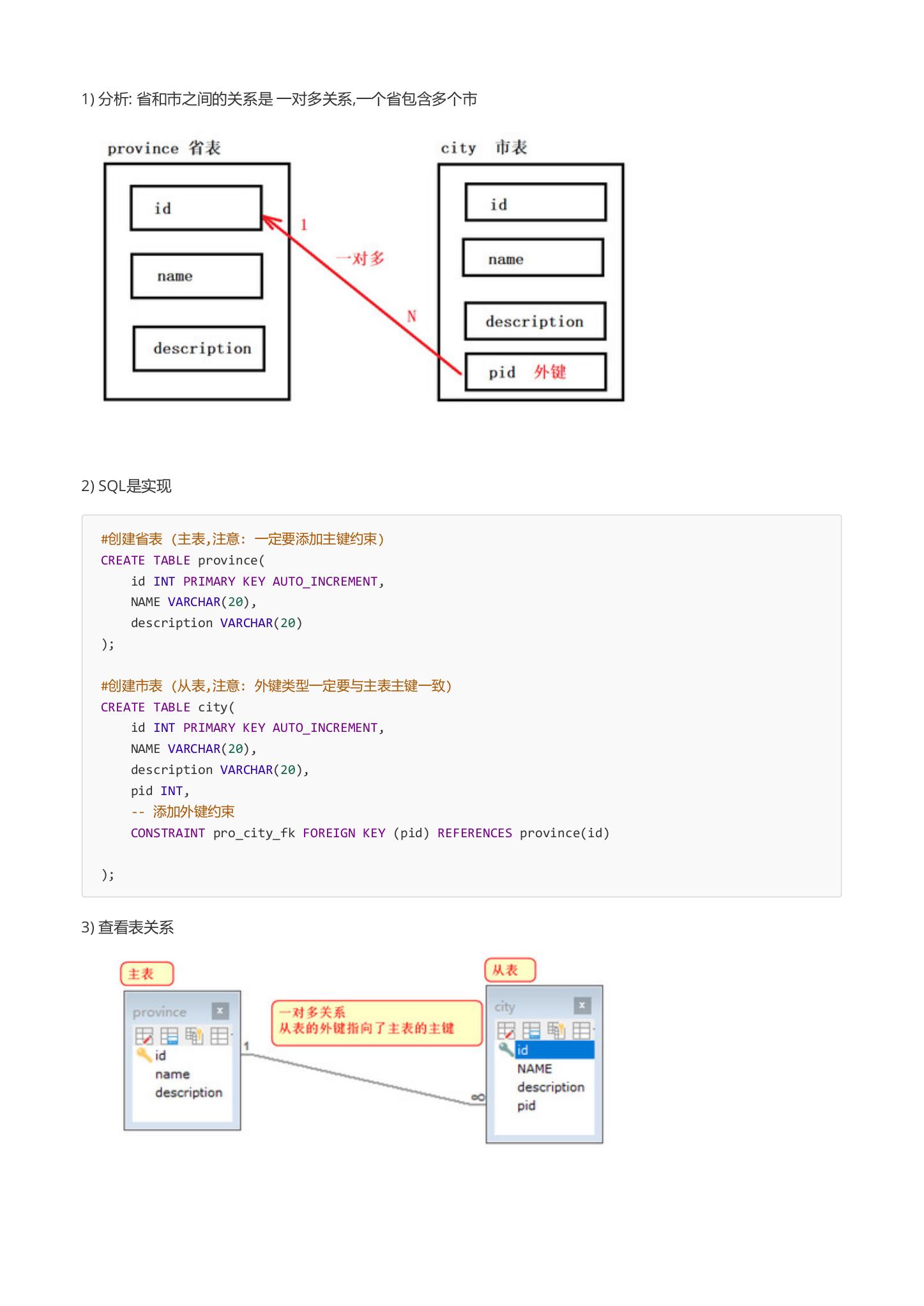
1.分析: 省和市之间的关系是 一对多关系,一个省包含多个市
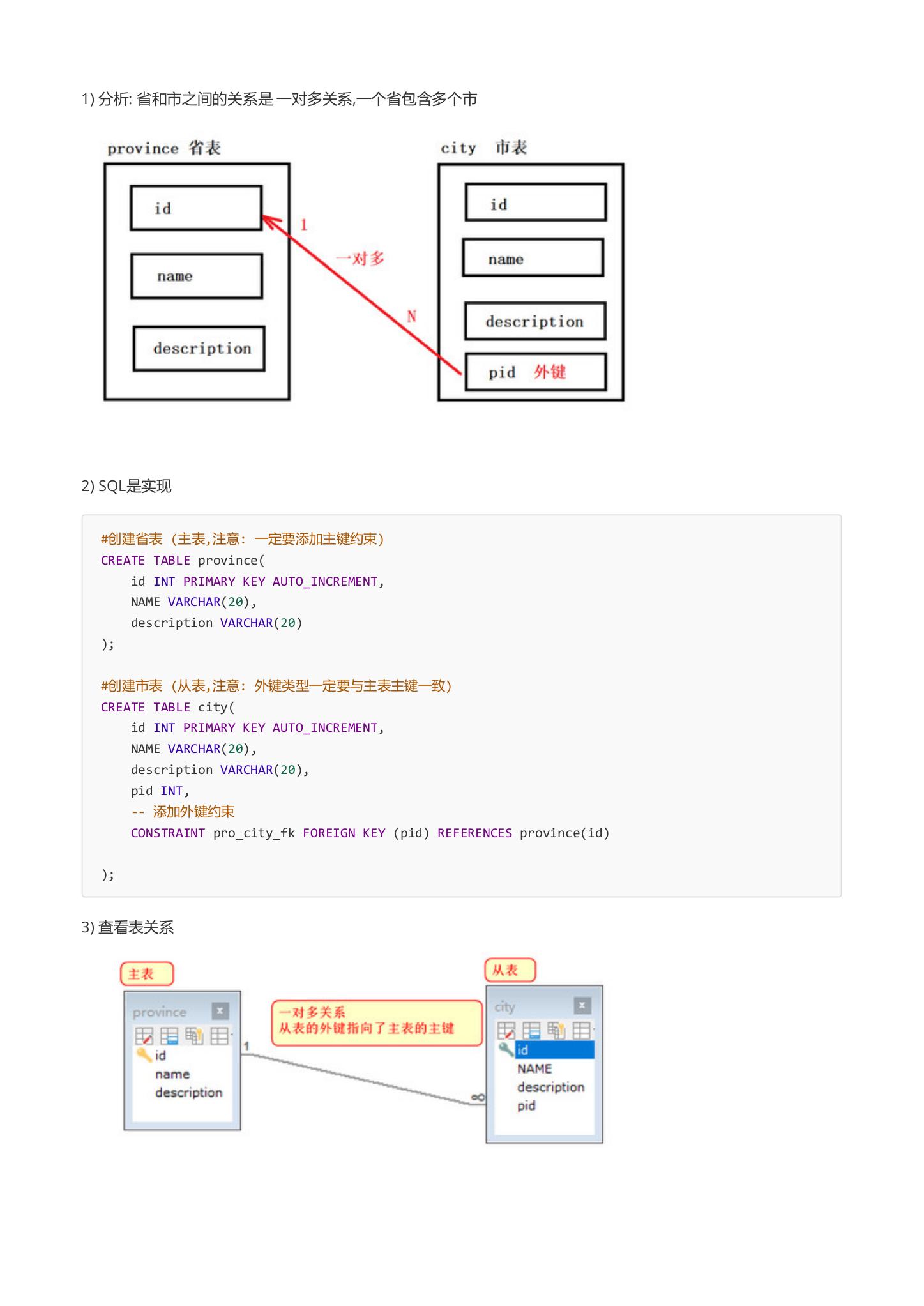
2.SQL是实现
#创建省表 (主表, 注意: 一定要添加主键约束)
CREATE TABLE province(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
description VARCHAR(20)
);
#创建市表 (从表, 注意: 外键类型一定要与主表主键一致)
CREATE TABLE city(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
description VARCHAR(20),
pid INT,
-- 添加外键约束
CONSTRAINT pro_city_fk FOREIGN KEY (pid) REFERENCES province(id)
);
3.查看表关系
6.1.5 设计 演员与角色表
- 分析: 演员与角色 是多对多关系, 一个演员可以饰演多个角色, 一个角色同样可以被不同的演员扮演
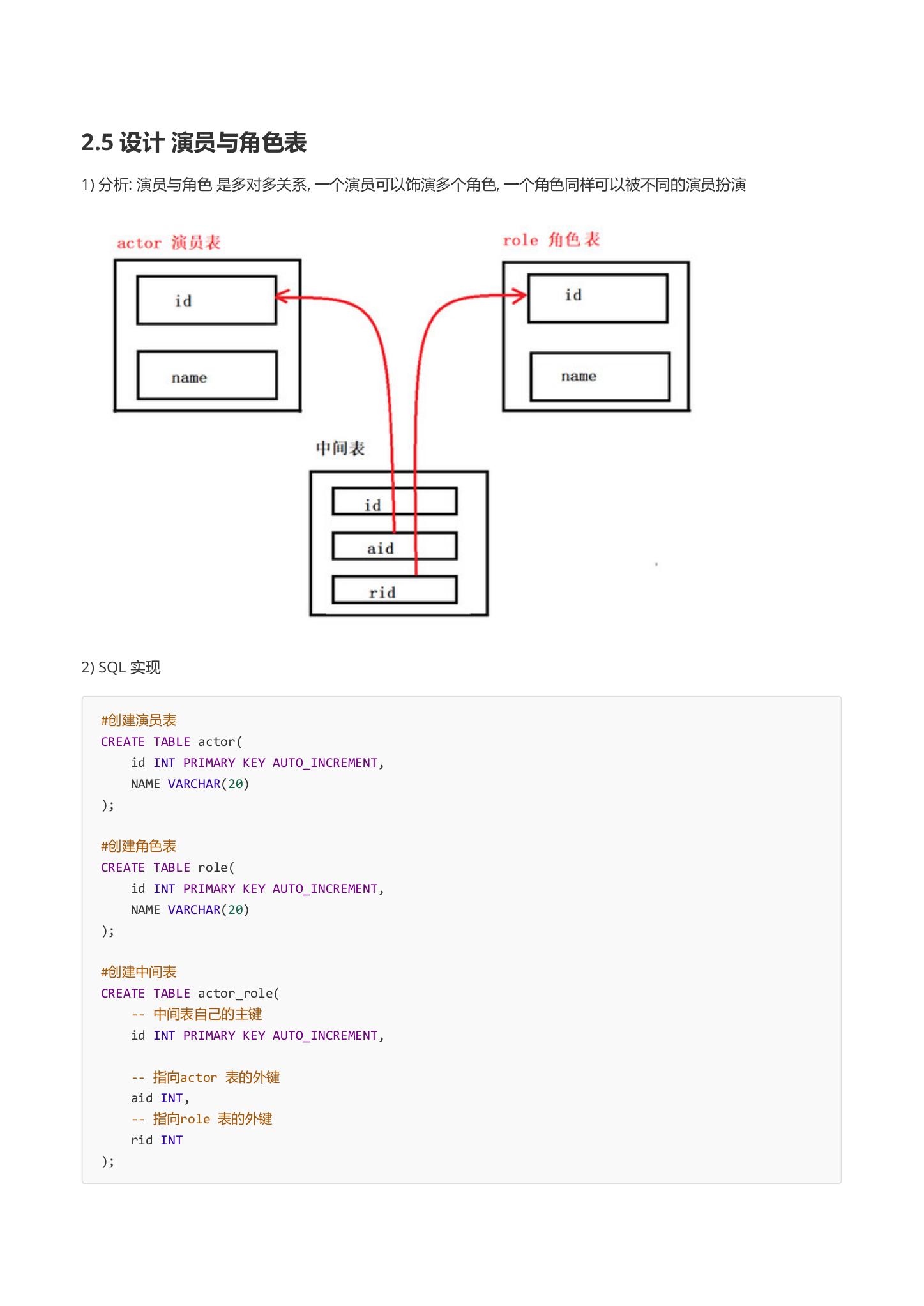
2.SQL 实现
#创建演员表
CREATE TABLE actor(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
#创建角色表
CREATE TABLE role(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
#创建中间表
CREATE TABLE actor_role(
-- 中间表自己的主键
id INT PRIMARY KEY AUTO_INCREMENT,
-- 指向actor 表的外键
aid INT,
-- 指向role 表的外键
rid INT );
3.添加外键约束
-- 为中间表的aid字段,添加外键约束 指向演员表的主键
ALTER TABLE actor_role ADD FOREIGN KEY(aid) REFERENCES actor(id);
-- 为中间表的rid字段,添加外键约束 指向角色表的主键
ALTER TABLE actor_role ADD FOREIGN KEY(rid) REFERENCES role(id);
4.查看表关系

6.2. 多表查询
6.2.1 什么是多表查询
-
DQL: 查询多张表,获取到需要的数据
-
比如 我们要查询家电分类下 都有哪些商品,那么我们就需要查询分类与商品这两张表
6.2.2 数据准备
- 创建db3_2 数据库
-- 创建 db3_2 数据库,指定编码
CREATE DATABASE db3_2 CHARACTER SET utf8;
2.创建分类表与商品表
#分类表 (一方 主表)
CREATE TABLE category (
cid VARCHAR(32) PRIMARY KEY ,
cname VARCHAR(50)
);
#商品表 (多方 从表)
CREATE TABLE products(
pid VARCHAR(32) PRIMARY KEY ,
pname VARCHAR(50),
price INT,
flag VARCHAR(2), \( \;\# \) 是否上架标记为:1表示上架、0表示下架
category_id VARCHAR(32),
-- 添加外键约束
FOREIGN KEY (category_id) REFERENCES category (cid)
);
3.插入数据
#分类数据
INSERT INTO category(cid,cname) VALUES('c001','家电');
INSERT INTO category(cid,cname) VALUES('c002','鞋服');
INSERT INTO category(cid,cname) VALUES('c003','化妆品');
INSERT INTO category(cid,cname) VALUES('c004','汽车');
#商品数据
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p001','小米电视
机',5000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p002','格力空
调',3000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p003','美的冰
箱',4500,'1','c001');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p004','篮球鞋',800,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p005','运动裤',200,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p006','T恤',300,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p007','冲锋
衣',2000,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p008','神仙水',800,'1','c003');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p009','大宝',200,'1','c003');
6.2.3 笛卡尔积
交叉连接查询,因为会产生笛卡尔积,所以 基本不会使用
-
语法格式 SELECT 字段名 FROM 表1,表2; 2) 使用交叉连接查询 商品表与分类表 SELECT * FROM category , products;
-
观察查询结果,产生了笛卡尔积 (得到的结果是无法使用的)
交叉查询会产生笛卡尔积, 得到两个表的数据的乘积
| \( \square \) | pid | prame | price | flag | category id | cid | CRAME |
|---|---|---|---|---|---|---|---|
| \( \square \) | \( \mathbf{{p001}} \) | 小米电视机 | 5000 | 1 | COOD | c001 | 家电 |
| \( \square \) | p001 | 小米电视机 | 5000 | 1 | c001 | c002 | 鞋服 |
| \( \square \) | p001 | 小米电视机 | 5000 | 1 | c001 | c003 | 化妆品 |
| \( \square \) | p001 | 小米电视机 | 5000 | 1 | c001 | c004 | 汽车 |
| \( \square \) | p002 | 格力空调 | 3000 | 1 | c001 | c001 | 家电 |
| \( \square \) | p002 | 格力空调 | 3000 | 1 | c001 | c002 | 鞋服 |
| \( \square \) | p002 | 格力空调 | 3000 | 1 | c001 | c003 | 化妆品 |
| \( \square \) | p002 | 格力空调 | 3000 | 1 | c001 | c004 | 汽车 |
- 笛卡尔积
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
6.2.4 内连接查询
- 内连接的特点:
- 通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
- 比如通过: 从表的外键 ( = ) 主表的主键方式去匹配
6.2.4.1 隐式内连接
form子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接.
使用where条件过滤无用的数据
语法格式
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
- 查询所有商品信息和对应的分类信息
# 隐式内连接
SELECT * FROM products,category WHERE category_id = cid;
- 查询商品表的商品名称 和 价格,以及商品的分类信息
SELECT
p.`pname`,
p.`price`,
c.`cname`
FROM products p , category c WHERE p.`category_id` = c.`cid`;
- 查询 格力空调是属于哪一分类下的商品
#查询 格力空调是属于哪一分类下的商品
SELECT p. `pname`, c. `cname` FROM products p , category c
WHERE p.`category_id` = c.`cid` AND p.`pid` = 'p002';
6.2.4.2 显式内连接
使用 inner join …on 这种方式, 就是显式内连接
语法格式
SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
-- inner 可以省略
- 查询所有商品信息和对应的分类信息
# 显式内连接查询
SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
- 查询鞋服分类下,价格大于500的商品名称和价格
# 查询鞋服分类下,价格大于500的商品名称和价格
-- 我们需要确定的几件事
-- 1.查询几张表 products & category
-- 2.表的连接条件 从表.外键 = 主表的主键
-- 3.查询的条件 cname = '鞋服' and price > 500
-- 4.要查询的字段 pname price
SELECT
p. pname,
p.price
FROM products p INNER JOIN category c ON p.category_id = c.cid
WHERE p.price > 500 AND cname = '鞋服';
6.2.5 外连接查询
左外连接
- 左外连接,使用 LEFT OUTER JOIN,OUTER 可以省略
- 左外连接的特点
- 以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
- 如果匹配不到, 左表中的数据正常展示, 右边的展示为null
语法格式:
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
-- 左外连接查询
SELECT * FROM category c LEFT JOIN products p ON c.`cid`= p.`category_id`
右外连接
-
右外连接,使用 RIGHT OUTER JOIN,OUTER 可以省略
-
右外连接的特点
- 以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
- 如果匹配不到,右表中的数据正常展示, 左边展示为null
语法格式:
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
-- 右外连接查询
SELECT * FROM products p RIGHT JOIN category c ON p. category_id = c. cid;
6.26 连接方式总结
-
内连接: inner join,只获取两张表中交集部分的数据.
-
左外连接: left join,以左表为基准,查询左表的所有数据, 以及与右表有交集的部分
-
右外连接: right join,以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
6.3 子查询 (SubQuery)
6.3.1 什么是子查询
-
子查询概念
- 一条select 查询语句的结果, 作为另一条 select 语句的一部分
-
子查询的特点
- 子查询必须放在小括号中
- 子查询一般作为父查询的查询条件使用
-
子查询常见分类
- where型 子查询: 将子查询的结果, 作为父查询的比较条件
- from型 子查询:将子查询的结果, 作为 一张表,提供给父层查询使用
- exists型 子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数, 包含子查询的结果
6.3.2 子查询的结果作为查询条件
语法格式:
SELECT 查询字段 FROM 表 WHERE 字段= (子查询) ;
1.通过子查询的方式,查询价格最高的商品信息
-- 1.先查询出最高价格
SELECT MAX(price) FROM products;
-- 2.将最高价格作为条件, 获取商品信息
SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
2.查询化妆品分类下的 商品名称 商品价格
## #查询化妆品分类下的 商品名称 商品价格
-- 先查出化妆品分类的 id
SELECT cid FROM category WHERE cname = '化妆品';
-- 根据分类id ,去商品表中查询对应的商品信息
SELECT
p. `pname`,
p. `price`
FROM products p
WHERE p. category_id` = (SELECT cid FROM category WHERE cname = '化妆品');
3.查询小于平均价格的商品信息
-- 1. 查询平均价格
SELECT AVG(price) FROM products; -- 1866
-- 2.查询小于平均价格的商品
SELECT * FROM products
WHERE price < (SELECT AVG(price) FROM products);
6.3.3 子查询的结果作为一张表
语法格式
SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;
- 查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称
-- 1. 先查询分类表的数据
SELECT * FROM category;
-- 2.将上面的查询语句 作为一张表使用
SELECT
p.`pname`,
p.`price`,
c.cname
FROM products p
-- 子查询作为一张表使用时 要起别名 才能访问表中字段
INNER JOIN (SELECT * FROM category) c
ON p.`category_id` = c.cid WHERE p.`price` > 500;
6.3.4 子查询结果是单列多行
- 子查询的结果类似一个数组, 父层查询使用 IN 函数,包含子查询的结果
语法格式
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
6.3.5 子查询总结
-
子查询如果查出的是一个字段(单列), 那就在where后面作为条件使用.
-
子查询如果查询出的是多个字段(多列), 就当做一张表使用(要起别名).
七、 数据库设计
7.1 数据库三范式(空间最省)
- 概念: 三范式就是设计数据库的规则.
- 为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式
- 满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以此类推。一般说来,数据库只需满足第三范式(3NF) 就行了
7.1.1 第一范式 1NF
- 概念:
- 原子性, 做到列不可拆分
- 第一范式是最基本的范式。数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个字段都是不可再分的最小数据单元,则满足第一范式。
7.1.2 第二范式 2NF
- 概念:
- 在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。
- 一张表只能描述一件事.
7.1.3 第三范式 3NF
- 概念:
- 消除传递依赖
- 表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
7.2 数据库反三范式
7.2.1 概念
-
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能
-
浪费存储空间,节省查询时间 (以空间换时间)
7.2.2 什么是冗余字段?
- 设计数据库时,某一个字段属于一张表,但它同时出现在另一个或多个表,且完全等同于它在其本来所属表的意义表示,那么这个字段就是一个冗余字段
7.2.3 反三范式示例
- 两张表,用户表、订单表,用户表中有字段name,而订单表中也存在字段name。
用户表
| id | name | sex |
|---|---|---|
| 1 | 李四 | 男 |
| 2 | 张百万 | \( \frac{1}{x} \) |
| 3 | 鵬飞 | 男 |
订单表 冗余字段
| id | number | price | name |
|---|---|---|---|
| 1 | qwer123 | 2000 | 张百万 |
| 2 | qwer234 | 3000 | 张百万 |
| 3 | qwer345 | 1500 | 鵬飞 |
使用场景:
-
当需要查询“订单表”所有数据并且只需要“用户表”的name字段时, 没有冗余字段 就需要去join 连接用户表,假设表中数据量非常的大, 那么会这次连接查询就会非常大的消耗系统的性能.
-
这时候冗余的字段就可以派上用场了, 有冗余字段我们查一张表就可以了.
7.2.4 总结
- 创建一个关系型数据库设计,我们有两种选择
- 尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅、让人心醉。
- 合理的加入冗余字段这个润滑剂,减少join,让数据库执行性能更高更快。
八、 索引
8.1 什么是索引
在数据库表中,对字段建立索引可以大大提高查询速度。通过善用这些索引,可以令MySQL的查询和运行更加高效。
如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字
8.2 常见索引分类
| 索引名称 | 说明 |
|---|---|
| 主键索引 (primary key) | 主键是一种唯一性索引,每个表只能有一个主键, 用于标识数据表中的每一 条记录 |
| 唯一索引(unique) | 唯一索引指的是 索引列的所有值都只能出现一次, 必须唯一. |
| 普通索引 (index) | 最常见的索引,作用就是 加快对数据的访问速度 |
MySql将一个表的索引都保存在同一个索引文件中, 如果对中数据进行增删改操作,MySql都会自动的更新索引.

8.2.1 主键索引 (PRIMARY KEY)
特点: 主键是一种唯一性索引,每个表只能有一个主键,用于标识数据表中的某一条记录。
一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL。
语法格式:
- 创建表的时候直接添加主键索引 (最常用)
CREATE TABLE 表名(
-- 添加主键 (主键是唯一性索引, 不能为null, 不能重复, )
字段名 类型 PRIMARY KEY,
);
8.2.2 唯一索引(UNIQUE)
特点: 索引列的所有值都只能出现一次, 必须唯一.
唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
语法格式:
- 创建表的时候直接添加主键索引
CREATE TABLE 表名(
列名 类型 (长度),
-- 添加唯一索引
UNIQUE [索引名称] (列名)
);
- 使用create语句创建: 在已有的表上创建索引
create unique index 索引名 on 表名(列名(长度))
ALTER TABLE 表名 ADD UNIQUE ( 列名 )
8.2.3 普通索引 (INDEX)
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column=)或排序条件(ORDERBY column)中的数据列创建索引。
语法格式:
使用create index 语句创建: 在已有的表上创建索引
create index 索引名 on 表名(列名[长度])
8.2.4 删除索引
- 由于索引会占用一定的磁盘空间,因此,为了避免影响数据库的性能,应该及时删除不再使用的索引
- 语法格式
ALTER TABLE table_name DROP INDEX index_name;
- 删除 demo01 表中名为 dname_indx 的普通索引。
ALTER TABLE demo01 DROP INDEX dname_indx;
8.3 索引的优缺点总结
-
添加索引首先应考虑在 where 及 order by 涉及的列上建立索引。
-
索引的优点
-
大大的提高查询速度
-
可以显著的减少查询中分组和排序的时间。
- 索引的缺点
-
创建索引和维护索引需要时间,而且数据量越大时间越长
-
当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度
九、视图
9.1 什么是视图
-
视图是一种虚拟表。
-
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
-
向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句.
-
视图向用户提供基表数据的另一种表现形式
9.2 视图的作用
-
权限控制时可以使用
- 比如,某几个列可以运行用户查询,其他列不允许,可以开通视图 查询特定的列, 起到权限控制的作用
-
简化复杂的多表查询
- 视图 本身就是一条查询SQL,我们可以将一次复杂的查询 构建成一张视图, 用户只要查询视图就可以获取想要得到的信息(不需要再编写复杂的SQL)
- 视图主要就是为了简化多表的查询
9.3 视图的使用
创建视图 语法格式:
create view 视图名 [column_list] as select语句;
view: 表示视图
column_list: 可选参数, 表示属性清单, 指定视图中各个属性的名称, 默认情况下, 与SELECT语句中查询的属性相同
as : 表示视图要执行的操作
select语句: 向视图提供数据内容
9.4 视图与表的区别
-
视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
-
通过视图不能改变表中数据(一般情况下视图中的数据都是表中的列 经过计算得到的结果,不允许更新)
-
删除视图,表不受影响,而删除表,视图不再起作用
十、 MySQL 存储过程
10.1 什么是存储过程
-
MySQL 5.0 版本开始支持存储过程。
-
存储过程 (Stored Procedure) 是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
-
简单理解: 存储过程其实就是一堆 SQL 语句的合并。中间加入了一些逻辑控制。
10.2 存储过程的优缺点
-
优点:
- 存储过程一旦调试完成后,就可以稳定运行,(前提是,业务需求要相对稳定,没有变化)
- 存储过程减少业务系统与数据库的交互,降低耦合,数据库交互更加快捷(应用服务器,与数据库服务器不在同一个地区)
-
缺点:
- 在互联网行业中,大量使用MySQL,MySQL的存储过程与Oracle的相比较弱,所以较少使用,并且互联网行业需求变化较快也是原因之一
- 尽量在简单的逻辑中使用,存储过程移植十分困难,数据库集群环境,保证各个库之间存储过程变更一致也十分困难。
- 阿里的代码规范里也提出了禁止使用存储过程,存储过程维护起来的确麻烦;
十一、MySQL触发器
11.1 什么是触发器
触发器(trigger)是MySQL提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作 (insert, delete, update) 时就会激活它执行。一一百度百科
简单理解:当我们执行一条sql语句的时候,这条sql语句的执行会自动去触发执行其他的sql语句。
11.2 触发器创建的四个要素
-
监视地点 (table)
-
监视事件 (insert/update/delete)
-
触发时间 (before/after)
-
触发事件 (insert/update/delete)
11.3 创建触发器
语法格式:
delimiter $ -- 将Mysql的结束符号从 ; 改为 $,避免执行出现错误
CREATE TRIGGER Trigger_Name -- 触发器名,在一个数据库中触发器名是唯一的
before/after(insert/update/delete) -- 触发的时机 和 监视的事件
on table_Name -- 触发器所在的表
for each row -- 固定写法 叫做行触发器, 每一行受影响,触发事件都执行
begin
-- begin和end之间写触发事件
end
$ -- 结束标记















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









