







这篇博文将记录博主在慢慢秋招求职路中遇到的一些笔试或面试的有价值的知识点,汇总下来,帮组大家查漏补缺,也帮助我自己进行知识的回顾和错误总结。范围比较广,可能包括java,前端,以及数据库,linux系统等等。
我会为每个知识点建立目录,方便大家查阅,并随着博主的招聘持续更新,大家可以关注或收藏一下博主,方便后续查看。
一、javaSE基础
1.static 关键字的用法和使用场景
- static关键字可以修饰变量
-
被static修饰的变量称为静态变量,它与类直接进行关联,生命周期等同于类的生命周期,在类加载器的加载阶段便被转化为方法区的运行时数据结构
-
静态变量可以直接通过类名进行访问,也可以通过对象进行访问,多个对象共享同一个静态变量
- static关键字可以修饰方法
-
静态方法,先于对象建立,先于非静态方法进行创建
-
静态方法不可以被子类重写,所有看起来被“重写”的情况,加上@Override注解都会报错,是因为底层实际并不是重写,也不是多态的一种应用,只是一种静态隐藏,两个方法互相没有关系,只与各自的类有关系,始终需谨记静态紧跟类的特性
class Test{ public static void main(String[] args) { Animal.staticSay(); //输出:(Static)this is animal Dog.staticSay(); //输出:(static)this is a dog Animal animal = new Dog(); animal.staticSay(); //输出:(Static)this is animal } } class Animal{ static public void staticSay(){ System.out.println("(Static)this is animal"); } } class Dog extends Animal{ //报错:@Override static public void staticSay(){ System.out.println("(static)this is a dog"); } }
-
static关键字可以修饰内部类
表示此内部类直接可以用过外层类类名进行调用,不需要通过外层类的对象
public class Test { public static void main(String[] args) { Outter.Inner inner = new Outter.Inner(); } } class Outter { public Outter() { } static class Inner { public Inner() { } } } -
static关键字可以修饰构造代码块
静态构造代码块只在类建立时执行一遍,存放一些初始化内容,此后不再执行
class Example { static{ //静态代码块 //存放类中的初始化内容 //执行时间级别:顶级1,类建立时 } { //构造代码块 //存放对象的统一初始化内容 //(因为构造方法的重载,每个构造方法不一定会被执行,对于统一的初始化内容,不需要在每个构造方法中写一遍,只需要放在构造代码块中) //执行时间级别:次顶级2,对象建立时 } Example() { //构造方法 //执行时间级别:正常3,对象建立时并且构造代码块后 }
2.创建一个实例对象的方式有什么?
-
使用new关键字
-
使用反射创建
Class aClass = Class.forName("com.southwindow.Demo"); Object o = aClass.getConstructor().newInstance(); -
使用反序列化技术创建
序列化:将整个对象看做一个容器,整个存储到文件中
反序列化:将序列化文件中的对象取出FileInputStream fis = new FileInputStream("D:\\ci.txt"); ObjectInputStream ois = new ObjectInputStream(fis); Object o = ois.readObject(); -
使用clone()创建
使用clone()方法之前,需要先实现Cloneable接口并重写clone()方法,然后该类对象才可以使用clone()
使用clone()方法不会通过构造方法,而是直接通过JVM将内容整体复制到另一个地址
public class Test_otherProject implements Cloneable{ @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } @Test public void test() throws CloneNotSupportedException { Test_otherProject test_otherProject = new Test_otherProject(); System.out.println(test_otherProject);//Test_otherProject@ed9d034 Object clone = test_otherProject.clone(); System.out.println(clone);//Test_otherProject@6121c9d6 } }
3.==和equals()方法的区别
==运算符:
- 基本类型:比较的就是值是否相同
- 引用类型:比较的就是堆内存地址值是否相同
equals()的源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
所以,默认情况,对于引用数据类型来说,equals()比较的是堆内存地址
但大多数常用类都会重写equals(),比如在String类中,equals()比较的字符串的内容
4.父类句柄子类构造方法创建的对象的特点
通过父类句柄子类构造方法创建的对象的特点:只可以使用父类方法和子类中的重写的父类方法
class Test{
public static void main(String[] args) {
Dog dog = new Dog();
dog.say();
//输出:this is a dog
Animal animal = new Dog();
animal.staticSay();
//输出:(Static)this is animal
animal.say();
//输出:this is a dog
animal.animalRun();
//输出:animal run!
//报错:animal.dogRun();
}
}
class Animal{
static public void staticSay(){
System.out.println("(Static)this is animal");
}
public void say(){
System.out.println("this is animal");
}
public void animalRun(){
System.out.println("animal run!");
}
}
class Dog extends Animal{
static public void staticSay(){
System.out.println("(static)this is a dog");
}
@Override
public void say(){
System.out.println("this is a dog");
}
public void dogRun(){
System.out.println("dog run!");
}
}
为方便理解,对于不同方法针对此种对象的情况如下:
| 特点 | 调用的方法 | 举例 |
|---|---|---|
| 静态隐藏方法 | 原父类的方法 | staticSay() |
| 非静态、重写方法 | 子类的方法 | say() |
| 非静态、非重写方法 | 不能调用,编译报错 | dogRun() |
5.多线程访问同一资源
public class Demo {
public static void main(String[] args) {
Thread_Demo task = new Thread_Demo();
new Thread(task,"thread1").start();
new Thread(task,"thread2").start();
}
}
class Thread_Demo implements Runnable{
int count=10;
@Override
public void run() {
while (true){
if(!task()){
break;
}
}
}
synchronized public boolean task() {
if(count < 0){
return false;
}else {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"操作,此时count值为:" + count);
count--;
}
return true;
}
}
/*输出:
thread1操作,此时count值为:10
thread1操作,此时count值为:9
thread2操作,此时count值为:8
thread2操作,此时count值为:7
thread2操作,此时count值为:6
thread2操作,此时count值为:5
thread2操作,此时count值为:4
thread2操作,此时count值为:3
thread1操作,此时count值为:2
thread1操作,此时count值为:1
thread1操作,此时count值为:0
Process finished with exit code 0
*/
6.JDBC原生加载过程
1.引入对应数据库jar包
2.加载数据库驱动类
Class.forName("com.mysql.jdbc.Driver");
3.获取连接对象Connectioon
Connection conn = DriverManager.getConnection("数据库连接地址","帐号","密码");
mysql的连接地址: jdbc:mysql://localhost:3306/数据库名
4.创建SQL执行环境对象Statement或预编译Preparedstatment
5.调用execute()执行SQL语句
6.释放连接
7.讲一下生产者消费者模型
生产者消费者模型:通过数据容器降低生产者与消费者的耦合度,彼此之间不直接进行通讯
具体的流程为:
1.消费者线程先休眠,生产者线程进行生产;
2.生产完毕后,将数据传输给数据仓库;
3.消费者线程被唤醒(notify()),生产者线程休眠(wait());
4.消费者对数据仓库中的数据进行消费,消费完毕后,消费者再次休眠,生产者线程被唤醒进行生产。。。
8.equals()和hashcode()的区别与联系
equals()默认比较的是对象的堆内存地址
hashcode()比较的是对象的哈希值
在底层equals()执行时会调用hashcode()先对两个对象的哈希值比较,哈希值相同后才会调用equals()比较,这样设计可以显著提高效率,大多数情况只需要比较哈希值就可以了
因为:
1.equal()相等的两个对象他们的hashCode()肯定相等,也就是用equal()对比是绝对可靠的。
2.hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的
所以,我们在书写Bean类时,通常会同时重写equals()和hashcode()
9.ConcurrentHashMap集合讲一下
由于HashMap是线程不安全的,所以为了解决这个问题,java官方推出了HashTable和ConcurrentHashMap,HashTable虽然安全,但由于上锁的是整个集合,所以效率很低,所以,在需要多线程的HashMap存储时,使用的都是ConcurrentHashMap。
ConcurrentHashMap的特点就是分段锁机制,内部存在一个segments数组,存放若干个segment,每次上锁按照segment为单位进行上锁,将未操作的segment解锁。每个segment可以理解为包含有一个HashMap的结构,如图:

Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中哈希桶的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中哈希桶的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
10.反射讲一下
反射:指在程序运行时,可以不受权限限制,动态获取某个类的对象、方法、属性等
原理:是类经过类加载器的双亲委派机制加载成字节码文件后,每个类生成一个对应的Class类对象,通过该对象可以获取到该类的对象、方法、属性等信息
二、前端
1.网页样式的导入方式有什么?讲一下他们的优先级
-
外部样式
写在<head>标签中的第一个样式,导入已经写好的CSS文件,作用于本页面,是最常使用的CSS样式方式,书写位置:<head>标签内<link href="引入的CSS文件" type="text/css" rel="stylesheet"/> 或者 <style type="text/css"> @import "style.css"; </style> -
内部样式
写在<head>标签内的第二个样式,只能使用<style>定义,不能引入外部css文件<style> /*内部样式表*/ li{ color: red; } </style> <!-- 特点:作⽤用于当前整个⻚页⾯面 --> -
内联样式
只能书写在标签的内部,控制单个HTML元素格式:
<html标签 style=“属性:值;属性:值;…”>被修饰的内容</html标签>
<li style="color: green;">内联样式表设置颜色绿色</li>
2.什么是跨域,AJAX是否可以跨域?如何实现跨域?
跨域:当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同
AJAX无法进行跨域,主要是因为浏览器的同源策略所限制
实现跨域可以通过JSONP的方式,
1.添加一个Script标签指定src跳转的跨域链接,请求JSON数据,将数据放回指定的回调函数来接收
2.通过JQuery封装好的ajax请求中的jsonpCallback属性自定义回调函数名接收数据
三、数据库
1.讲一下多表查询的内连接、左连接、右连接
内连接: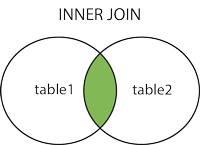 左连接:
左连接: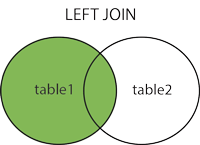 右连接:
右连接: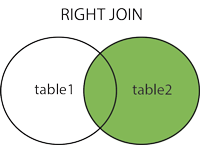
内连接:满足on条件的数据作为from表
select 表名1.字段名1,表名2.字段名2
from 表名1
inner join 表名2
on 表名1.字段名3 = 表名2.字段名3;
左连接:以左侧表为基准,去关联右侧的表进行联结,如果有未关联的数据,那么结果为null
左联结语法:
select 表名1.字段名1,表名2.字段名2
from 表名1
left join 表名2
on 表名1.字段名3 = 表名2.字段名3
右连接:以右侧表为基准,去关联左侧的表进行联结,如果有未关联的数据,那么结果为null
右联结语法:
select 表名1.字段名1,表名2.字段名2
from 表名1
right join 表名2
on 表名1.字段名3 = 表名2.字段名3
2.讲一下数据库的事务及隔离级别
事务:指一系列SQL语句组成的一个程序执行逻辑单元,要不全部执行成功,要不全部执行失败
事务的常见问题:
脏读:读取到了未提交存入数据库的数据
不可重复读:多次读取数据期间,数据发生了改变
幻读:多次读取数据期间,数据的数量发生了改变
事务的隔离级别:
1.read_uncommite(读未提交)
前一个事务还未提交数据时,下一个事务便进入操作
2.read_commited(读已提交)
前一个事务提交数据后,数据才可以被下一个事务访问
3.repeatable_read(可重复读)
前一个事务对同一数据的值的多次操作都完成后,才允许下一个事务进入
4.serializiable(顺序读)
不允许事务并发,必须依次排序执行
3.为什么阿里巴巴Java开发手册里要求禁止使用存储过程?
存储过程:可以理解为SQL函数,是SQL语句的集合,可以实现某个特定的功能,需要时调用
但存储过程相比Java等语言,难以调试和扩展且没有移植性,因此Dao建议只写简易的SQL语句,对数据的整合和筛查建议放到后端java语言中进行
4.聚簇索引与非聚簇索引
聚簇索引:索引即数据,找到索引便找到了数据,支持聚簇索引的引擎:innodb
非聚簇索引:索引是一个文件,数据在另一个文件,根据索引文件找到数据的key值,然后到数据文件中根据key值找到数据,非聚簇索引引擎:MyISAm
5.为什么MySQL底层使用B+树而不是B树、二叉树?
首先,相比于二叉树,B树及B+树在存储同样多的数据时,结构会更加的平衡、紧致,在进行磁盘寻址加载时,需要加载更少的磁盘页,缩短加载时间
而相较于B树,B+数的数据只存储于底部的叶子节点,查找数据时,不需要像B树一样进行中序遍历,而只需要遍历底部以链表结构相连的叶子结点,查找时间也更为均衡
6.SQL索引失效,联合索引失效的实际场景
防止索引失效:
不要在查询的索引列上使用函数
不要在查询的索引列上进行运算
避免查询条件左右类型不匹配发生隐式转换
使用like模糊查询时通配符%在第一位
使用联合查询时谨记最左前缀原则(从最左字段开始使用索引)
查看索引是否失效·explain 查询语句 \G:查询语句经过MySQL优化器后会生成一个记录,里面展示了该语句要使用的索引等等
四、linux系统
在一个linux日志中查询关键字
1.cat 路径/文件名 | grep 关键词
2.grep -i 关键词 路径/文件名
五、 计算机网络
在浏览器地址栏键入URL,会经历什么流程?
1.浏览器向DNS服务器请求解析该URL中的域名所对应的IP地址
2.根据ip地址和默认端口号80,和服务器建立TCP连接
3.浏览器发出读取文件的HTTP请求,该请求报文作为三次握手的第三次报文的数据发送给服务器
4.服务器对浏览器作出响应,把对应的HTML文本发送给浏览器
5.浏览器解析HTML文本并显示内容
六、常用工具
1.Git如何切分支
-
查看分支:
git branch$ git branch * dev master有星号*标志的表示当前操作的分支
-
创建分支:
git branch 分支名 -
切换分支:
git checkout 分支名,创建并切换分支:git checkout -b 分支名 -
合并分支:
git merge 分支名 -
删除分支:
git branch -d 分支名
七、做错的算法题汇总
1.整型数组按个位值排序
给定一个非空数组(列表),其元素数据类型为整型,请按照数组元素十进制最低位从小到大进行排序,十进制最低位相同的元素,相对位置保持不变。
当数组元素为负值时,十进制最低位等同于去除符号位后对应十进制值最低位。
- 输入描述: 给定一个非空数组,其元素数据类型为32位有符号整数,数组长度[1, 1000]
- 输出描述:输出排序后的数组
- 示例1:
- 输入 1,2,5,-21,22,11,55,-101,42,8,7,32
- 输出 1,-21,11,-101,2,22,42,32,5,55,7,8
public List<Integer> method(List<Integer> list){
//用于存放 <原始下标,最低位>
Map<Integer,Integer> map = new TreeMap<>();
List<Integer> result = new LinkedList<>();
list.stream().forEach(i -> {
//取最低位
int low = Math.abs(i) % 10;
map.put(list.indexOf(i),low);
});
//对Map值进行升序,即最低位进行升序
List<Map.Entry<Integer, Integer>> entries = new LinkedList<>(map.entrySet());
Collections.sort(entries, new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
//得到根据最低位排序后原始下标顺序,根据原始下标找到原始数即可
entries.forEach(entry -> result.add(list.get(entry.getKey())));
return result;
}
博主能力有限,此篇博客中有不对的地方欢迎指正!(可以通过评论或私信)
















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











