








arXiv 2021
Jingjing Ren, Xiaowei Hu, Lei Zhu, Xuemiao Xu, Yangyang Xu, Weiming Wang, Zijun Deng, Pheng-Ann Heng
https://arxiv.org/abs/2102.02996
一、简介
伪装物体检测是一项具有挑战性的任务,其目的是识别与周围环境具有相似纹理的物体。

本质上伪装后的物体和背景在纹理上有细微的差别,如上图(a)所示,鱼的纹理包括密集的白色小颗粒和棕色区域。
基于这一观察,我们提出了通过构造多个纹理感知细化模块,在深度卷积神经网络中学习纹理感知特征,放大伪装目标和背景之间细微的纹理差异,从而提高伪装对象检测的性能。
为了实现这一点,我们设计了texture-aware refinnement module(TARM)模块,以放大伪装对象和背景之间的纹理差异,从而显著提高伪装对象的识别率。
此外,我们设计了一个边界一致性损失来增强边界的细节信息,而没有额外的测试计算开销。
二、模型
2.1 整体框架
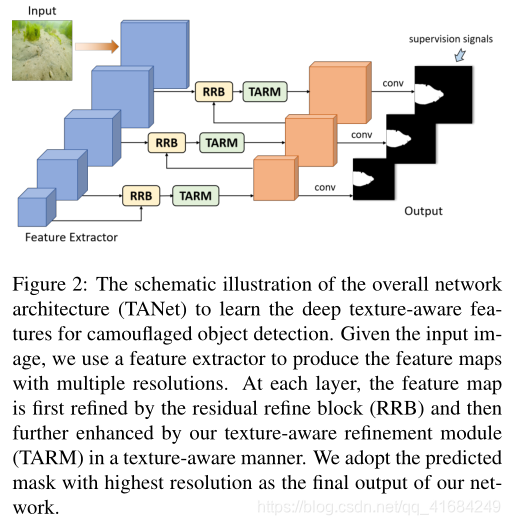
上图展示了带有TARM的整体网络架构(TANet),用于有阴影的对象检测。
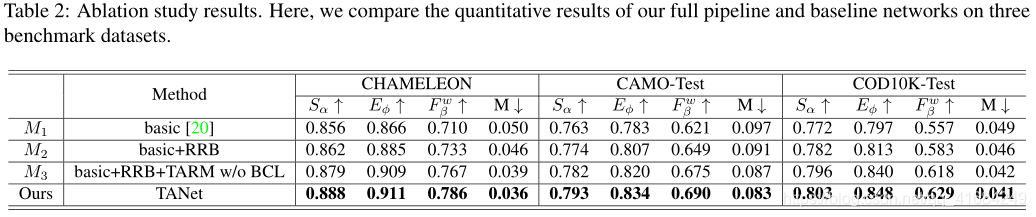
给定输入图像,采用特征提取器提取多种分辨率的特征图,然后利用residual refine blocks(RRB)细化不同层次的特征图,以增强细节和去除背景噪声。
由于内存占用较大,我们忽略了在第一层细化特征图。接下来,我们提出了纹理细化模块(TARM)来学习纹理特征,这有助于提高伪装对象的可见性。
最后,我们预测二进制掩码,通过在多层添加监督信号来指示每层伪装的对象。
2.2 Texture-Aware Refinement Module(TARM)
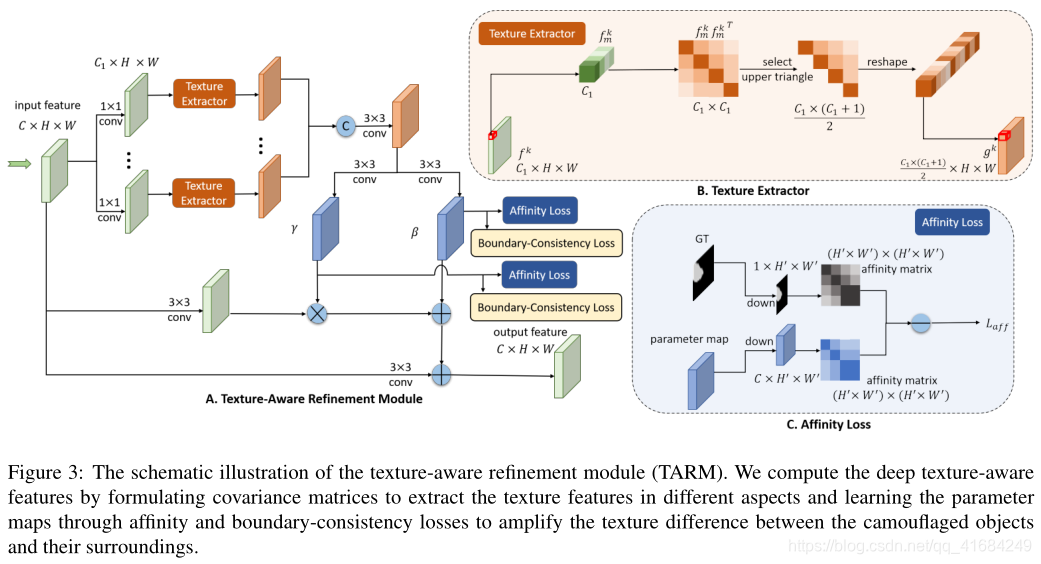
首先,输入图像(C×H×W)使用1×1的卷积运算获得多个特征图(C1×H×W)。为了计算效率,这里的C1小于C。
接下来,计算协方差矩阵,以获得卷积特征上不同响应之间的相关性,描述特征的组合,并用于表示纹理信息。具体操作如上图(B),计算特征图每个像素(C1×1)与自身的转置(1×C1)的内积,得到协方差矩阵(C1×C1)。然后采用该矩阵的上三角形式来表示纹理特征,并将结果整形为特征向量。对每一个像素都执行相同操作,最后得到协方差特征图(C1×(C1+1))/2×H×W。
然后将这些协方差特征图拼接,经过一个3×3的卷积融合这些协方差特征图。
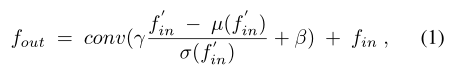
最后,如公式(1)操作。
fin是输入图像,µ和σ是其均值和方差,fin’是经过3×3卷积提取的特征图,conv是一个3×3卷积。
γ和β是上述协方差特征图分别经过3×3卷积得到的,用于通过调整输入特征的纹理来放大伪装对象及其周围的环境纹理差异。
三、损失函数
3.1 Affinity Loss
为了使特征图γ和β捕捉伪装对象和背景之间的纹理差异,我们采用Affinity Loss来放大纹理特征之间的差异。
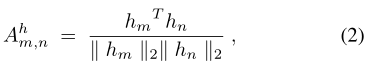
如上图C所示。首先受用合并操作对特征图进行下采样,然后计算affinity矩阵,该矩阵是得到成对纹理相似性结果矩阵。
公式(2)表示m和n位置之间的相似性结果。
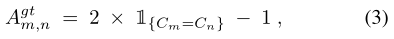
然后计算ground truth(GT)的affinity矩阵,如果m和n位置的标签相同就等于1,不同等于0。

在自然图像中,伪装物体通常占据较小的区域,因此存在类不平衡问题。为解决该问题,将affinity loss表示为公式(4)所示。
3.2 Boundary-Consistency Loss
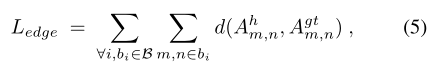
卷积特征包含高度语义特征,但是由于参数图的小分辨率,容易导致在伪装对象和背景之间产生模糊的边界。为了解决这个问题,我们提出了一种边界一致性损失,通过重新检查跨边界区域的预测结果来提高边界质量。
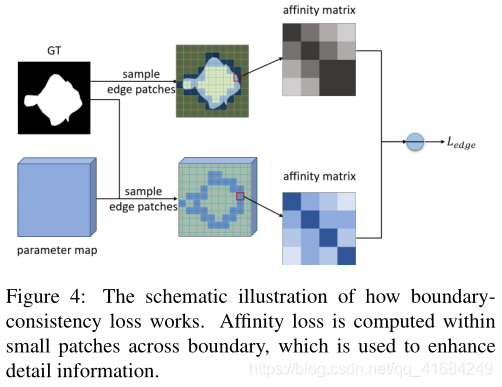
没有使用下采样操作,使其具有更高分辨率的参数映射,有助于为边界预测提供更详细的信息,并且只考虑边界的像素块。
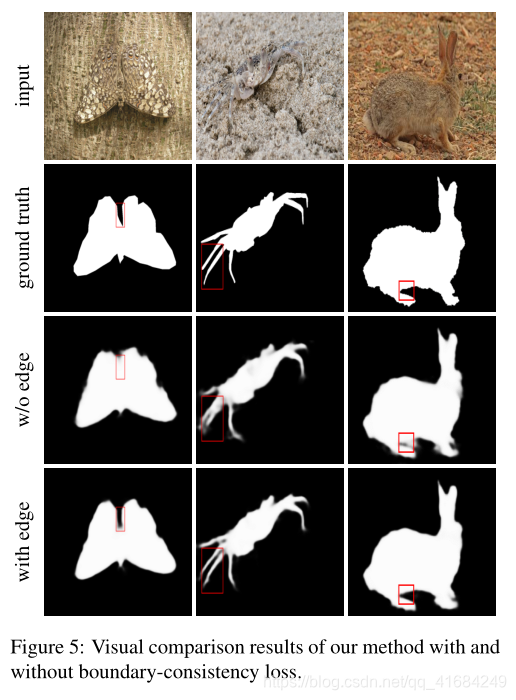
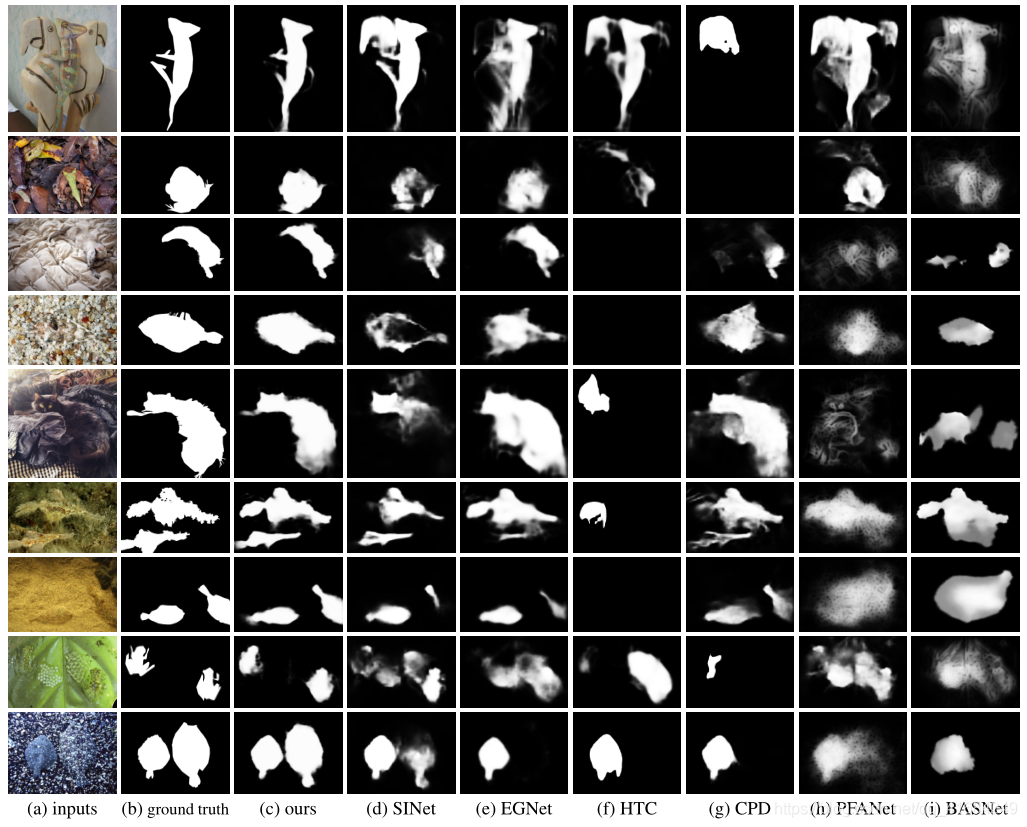
上图是边界损失的效果。
3.3 训练和测试策略
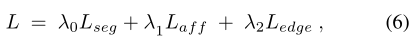
Lseg是二进制交叉熵损失。λ0=1,λ1=1,λ2=10。
使用ResNeXt50作为backbone,其在ImageNet上进行了预训练。使用SGD和poly learning策略来优化网络。初始学习率为0.001,decay power为0.9。输入图像大小为384×384,一共训练30个epoch。
3.4 可视化

通过学习解码器来进行可视化。
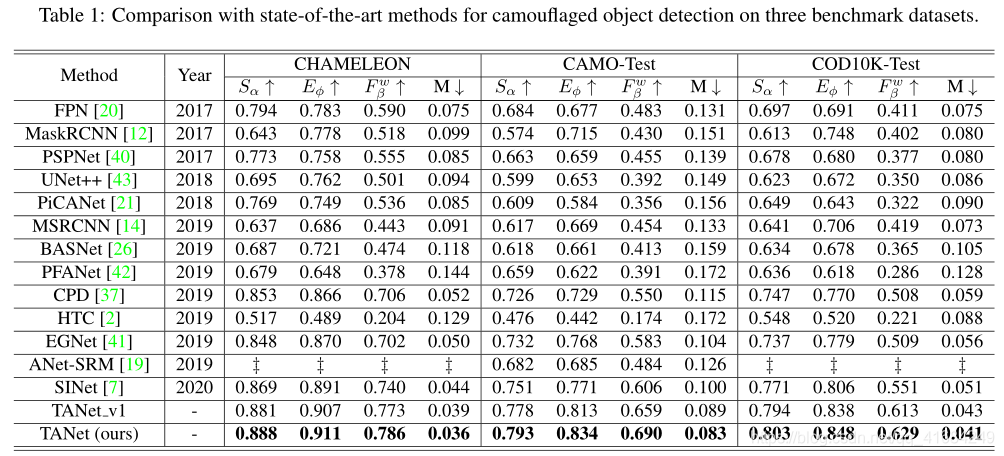
四、实验
训练集使用COD10K的3040张训练图像、CPD1K的600张训练图像和CAMO的1000张训练图像。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











