







全分布式集群搭建
前提: 一台主机,一台或以上的副机
将虚拟机改为桥接模式
在VMWare侧边栏右键虚拟机名字->选择"设置"->选择"桥接模式"
获取IP
连接上主机的网络,使虚副机与主机处在同一网络下。
输入ifconfig获取虚拟机ip
配置文件
-
修改hostname:
在终端输入
sudo vim /etc/hostname 将默认的名称删除,输入自己要设置的hostname,保存退出。
-
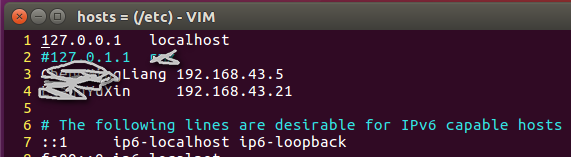
修改hosts文件:
输入
sudo vim /etc/hosts 注释掉第二行127.0.1.1,将主机和其它成员的ip与hostname写入
重启,使修改生效。
-
切换用户(如果已是要配置的用户下则不用切换)
-
转到用户家目录
cd ~, 查看是否有BigData文件夹, 有则删去。 -
输入
cd /opt/hadoop/etc/hadoop/输入
sudo vim workers, 将各副机的hostname写入
修改xml文件
-
在
/opt/hadoop/etc/hadoop/目录下修改core-site.xml,hdfs-site.xml,yarn-site.xml -
core-site.xml内容:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <!--修改value--> <value>hdfs://主机的hostname:9000</value> </property> </configuration> -
hdfs-site.xml内容:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.nameservices</name> <value>hdfs01</value> <!--此处的value集群机器间要保持一致--> </property> <property> <name>dfs.namenode.secondary.http-address</name> <!--修改value--> <value>主机的hostname:50090</value> </property> <property> <name>dfs.blocksize</name> <value>32m</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hdfs/Bigdata/data/hadoop/hdfs/nn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:/home/hdfs/Bigdata/data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:/home/hdfs/Bigdata/data/hadoop/hdfs/snn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hdfs/Bigdata/data/hadoop/hdfs/dn</value> </property> </configuration> -
yarn-site.xml内容:<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <!--修改value--> <value>主机的hostname</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/hdfs/Bigdata/hadoop/data/hadoop/yarn/nm</value> </property> </configuration> -
附
mapred-site.xml的内容:<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
启动服务
- 主机格式化文件系统,副机可以不格式化
- 主机启动namenode:
hadoop-daemon.sh start namenode或 hdfs --daemon start namenode(推荐)- 副机启动datanode:
hdfs --daemon start datanode - 主机启动resourcemanager:
yarn --daemon start resourcemanager - 副机启动nodemanager:
yarn --daemon start nodemanager
结果
在浏览器输入https://主机hostname或主机ip:9870,可以看到各副机的信息。主机位启动datanode,所以没有它的信息.

零散知识点
-
启动服务后,可以用jps查看是否已启动服务。
副机包含
NodeManager,DataNode,Jps -
杀掉进程:kill -9 进程号
-
如果正确启动,转到~/Bigdata/data/hadoop/hdfs
输入ls可以看到只有一个dn(针对副机)。
如果有nn则会导致连接主机失败
-
查看集群ID与数据节点ID:进入dn目录,输入cat current, cat VERSION
-
查看日志:输入 cd /opt/hadoop/logs, cd hadoop-hdfs-datanode-你的hostname.log。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









