









FLink读取kafka数据写入postgres
一、前言
记录一次使用FLink流式读取kafka数据并用jdbcsink写入postgres时,遇到的问题:即:程序正常运行,但写入没有反应,数据库中无记录。
二、问题解决关键
网上资料中,多数写法是如下所示的:
package com.antiy.wc;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class SinkToPostgres {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 2. 从配置文件中加载配置参数
ParameterTool parameters = ParameterTool.fromArgs(args);
String propertiesPath = parameters.get("path",System.getProperty("user.dir")+"/src/main/resources/application.properties");
ParameterTool parameterTool = ParameterTool.fromPropertiesFile(propertiesPath);
env.getConfig().setGlobalJobParameters(parameterTool);
String PGUrl = parameterTool.get("PGUrl");
String PGUserName = parameterTool.get("PGUserName");
String PGPassWord = parameterTool.get("PGPassWord");
// 3. 建立数据源
DataStreamSource<EventPOJO> dataStream = env.fromElements(
new EventPOJO("Bob","./home",1000L),
new EventPOJO("Ley","./abc?id=1",2000L),
new EventPOJO("Alice","./abc?id=2",3000L),
new EventPOJO("Tom","./abc?id=3",4000L),
new EventPOJO("Jerry","./abc?id=4",5000L)
);
dataStream.print();
// 5. 将数据写入postgres
dataStream.addSink(JdbcSink.sink(
"INSERT INTO flink_event_test(user_name,url) VALUES (?,?)",
((preparedStatement,event) -> {
preparedStatement.setString(1,event.name);
preparedStatement.setString(2,event.url);
}),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(PGUrl)
.withDriverName("org.postgresql.Driver")
.withUsername(PGUserName)
.withPassword(PGPassWord)
.build()
));
// 6.执行程序
env.execute();
}
}
其中缺少JdbcExecutionOptions.builder()参数配置,并且数据来源是有界流,并不是从kafka中读取的流式数据。所以程序会在将读取到的所有数据(有界流)写入postgres,程序运行完毕,写入数据库成功。
但将数据源改为kafka无界流后,会出现消费成功,但是数据库中一直“无记录”的情况。
分析原因:
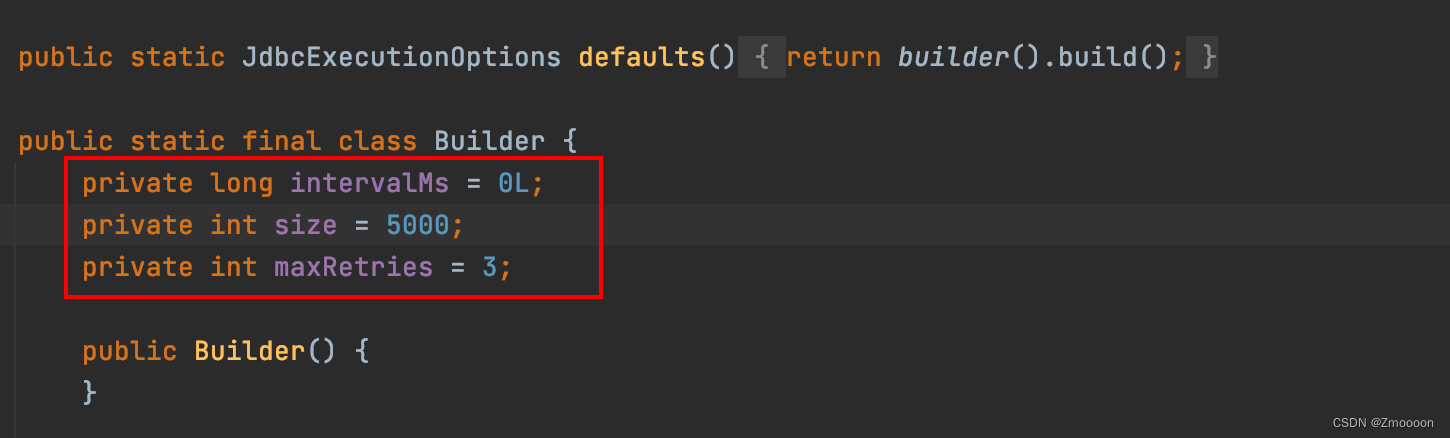
JdbcSink中还有一个JdbcExecutionOptions对象需要实现,它的功能是用于设置批量提交的策略(两次提交最小时间间隔,一次批量提交的数据量,重试次数等)。那之前引起问题的原因显而易见,是因为没有kafka中传入的数据没有到达默认的批量提交量(5000条),这些数据一直在内存中积累并未commit到数据库,所以postgres中一直查询不到数据。

三、完整代码
package com.antiy.wc;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class KafkaToPostgres {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 2. 从配置文件中加载配置参数
ParameterTool parameters = ParameterTool.fromArgs(args);
String propertiesPath = parameters.get("path",System.getProperty("user.dir")+"/src/main/resources/application.properties");
ParameterTool parameterTool = ParameterTool.fromPropertiesFile(propertiesPath);
env.getConfig().setGlobalJobParameters(parameterTool);
String kafkaInputBootStrapServers = parameterTool.get("kafkaInputBootStrapServers");
String kafkaInputGroupId = parameterTool.get("kafkaInputGroupId");
String kafkaInputTopic = parameterTool.get("kafkaInputTopic");
String PGUrl = parameterTool.get("PGUrl");
String PGUserName = parameterTool.get("PGUserName");
String PGPassWord = parameterTool.get("PGPassWord");
// 3. 从kafka中读取数据
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaInputBootStrapServers);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,kafkaInputGroupId);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); // 设置自动提交offset
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000); //提交时间间隔
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //key的反序列化
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //value反序列化
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
DataStreamSource<String> KafkaStream = env.addSource(new FlinkKafkaConsumer<String>(kafkaInputTopic,new SimpleStringSchema(),properties));
// 4.转换为Event对象
SingleOutputStreamOperator<EventPOJO> mapStream = KafkaStream.map(new MapFunction<String, EventPOJO>() {
@Override
public EventPOJO map(String s) throws Exception {
String[] fields = s.split(",");
return new EventPOJO(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
});
mapStream.print();
// 5. 将数据写入postgres
mapStream.addSink(JdbcSink.sink(
"INSERT INTO flink_event_test(user_name,url) VALUES (?,?)",
// 标准写法:创建类实现JdbcStatementBuilder接口
// new MyJdbcStatementBuilder(),
// 简便写法:使用lambada表达式
((preparedStatement,event) -> {
preparedStatement.setString(1,event.name);
preparedStatement.setString(2,event.url);
}),
JdbcExecutionOptions.builder()
.withBatchSize(5)
.withBatchIntervalMs(5000)
.withMaxRetries(3)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(PGUrl)
.withDriverName("org.postgresql.Driver")
.withUsername(PGUserName)
.withPassword(PGPassWord)
.build()
));
// 6.执行程序
env.execute();
}
// public static class MyJdbcStatementBuilder implements JdbcStatementBuilder<EventPOJO>{
// @Override
// public void accept(PreparedStatement preparedStatement, EventPOJO eventPOJO) throws SQLException {
// preparedStatement.setString(1, eventPOJO.name);
// preparedStatement.setString(2, eventPOJO.url);
// }
// }
}
















 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









