






目录
一、基于共享存储的SAN
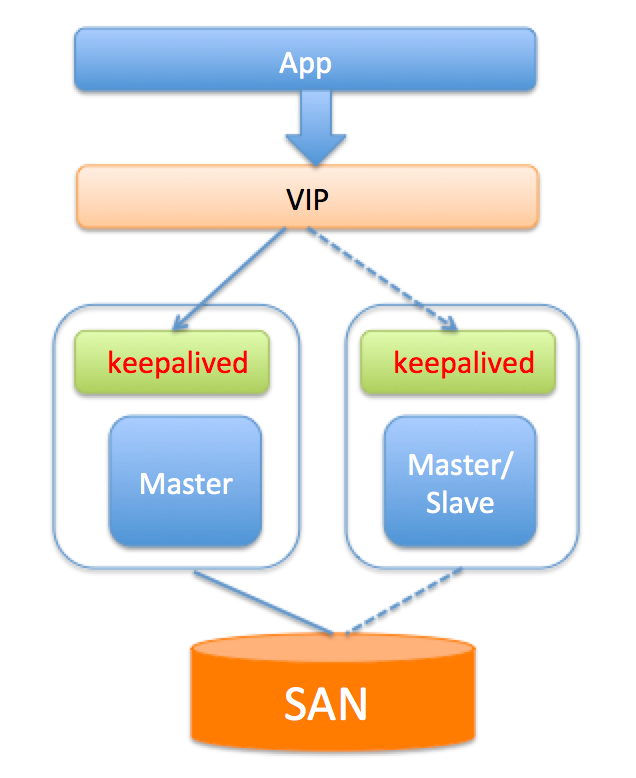
方案介绍:SAN(Storage Area Network):简单点说就是可以实现网络中不同服务器的数据共享,共享存储能够为数据库服务器和存储解耦。使用共享存储时,服务器能够正常挂载文件系统并操作,如果服务器挂了,备用服务器可以挂载相同的文件系统,执行需要的恢复操作,然后启动MySQL。
优点:
1.可以避免存储外的其它组件引起的数据丢失。
2.部署简单,切换逻辑简单,对应用透明。
3.保证主备数据的强一致。
限制或缺点:
1.共享存储是单点,若共享存储挂了,则会丢失数据。
2.价格比价昂贵。
二、基于磁盘复制的方案DRBD
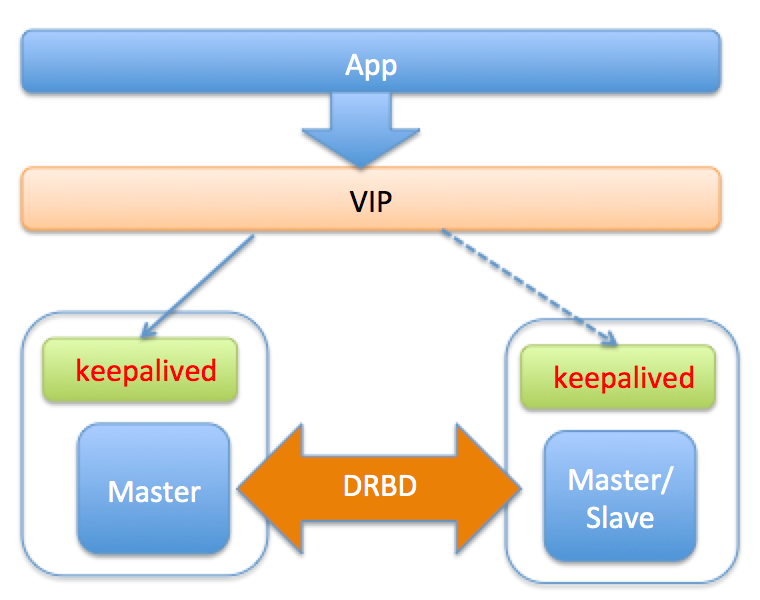
方案介绍:DRBD(Distributed Replicated Block Device)是一种磁盘复制技术,可获得和SAN类似的效果。DRBD是一个以Linux内核模块方式实现的块级别同步复制技术。它通过网卡将主服务器的每个块复制到另外一个服务器块设备上,并在主设备提交块之前记录下来。DRBD与SAN类似,也是有一个热备机器,开始提供服务时会使用和故障机相同的数据,只不过DRBD的数据是存储复制,不是共享存储。
优点:
1.切换对应用透明
2.保证主备数据的强一致。
限制或缺点:
1.影响写入性能,原因是每次写磁盘的实质都需要同步到网络服务器。
2.一般配置两节点同步,可扩展性比较差
3.备库不能提供读服务,资源浪费
三、基于MySQL复制(单点写)
第一和第二类两种方案分别依赖于底层的共享存储和磁盘复制技术,来解决MySQL服务器和磁盘单点的问题。而实际生产环境中,高可用更多的是依赖于MySQL本身的复制,通过复制为Master制作一个或多个热副本,在Master故障时,将服务切换到热副本。
(一)、KeepAlived (主从或主主半同步复制)
实现过程:使用KeepAlived组件实现的MySQL高可用,其中的MySQL(master/master)主主同步复制关系,保证了MySQL服务中数据的一致性,保证了高可用,而KeepAlived提供虚拟IP,通过KeepAlived来进行故障监控,当其中的一台MySQL服务器宕机时,虚拟IP自动漂移 到另一台主机上,从而实现MySQL故障时自动转换。
方案介绍:KeepAlived是一个HA软件,作用是检测服务器状态,检查原理是模拟网络请求检测,对于db服务器主要是IP,端口但这都可能不够,因此KeepAlived也支持自定义脚本。KeepAlived基于VRRP协议来实现高可用,每个服务器的机器都会部署一个KeepAlived服务,多个KeepAlived服务中有一个Master,Master指向其他各个Slave KeepAlived服务发送心跳包(如果接收不到就会认为主宕机,需要按照权重重新选主),所有的服务器配置指向同一个VIP,正常情况下,应用访问VIP时,即访问的是master配置指向的真实IP;而如果Master所在KeepAlived服务挂了,则基于VRRP协议会重新选一个KeepAlived Master来提供服务,在这种情况下,如果master上的DB正常,而且上面有长连接,则会造成双写。KeepAlived通过监听来确认服务器的状态,如果发现服务器故障,则将故障服务器从系统中剔除(通过关掉自身的KeepAlived服务实现),KeepAlived的高可用架构如下图,分别在主、从服务器上安装KeepAlived的软件,并配置同样的VIP,VIP层将真实IP屏蔽,应用服务器通过访问VIP来获取DB服务。当Master故障时,KeepAlived感知,并将Slave提升主,继续提供服务对应用层透明。

优点:
- 安装配置简单
- Master故障时,Slave快速切换提供服务,并且对应用透明。
限制或缺点:
1.需要主备的IP在同一个网段。
2.提供的检测机制比较弱,需要自定义脚本来确定Master是否能提供服务,比如更新心跳表等。
3.无法保证数据的一致性,原生的MySQL采用异步复制,若Master故障,Slave数据可能不是最新,导致数据丢失,因此切换时要考虑Slave延迟的因素,确定切换策略。对于强一致需求的场景,可以开启(semi-sync)半同步,来减少数据丢失。
- KeepAlived软件自身的HA无法保证。
1. KeepAlived核心
(1).健康检查
他是根据TCP/IP参考模型,在网络层传输层和应用层间,通过探测数据传送状态来判断节点状态是否正常,如果某的服务器结点出现异常,或者工作出现故障,KeepAlived将会检测到,并将出现故障的服务器节点从集群系统中提出,这个工作全部都是自动完成的,不需要人工参与,需要人工参与完成的知识修复出现故障的服务节点。
(2).故障切换
后来的KeepAlived又加入了vrrp(虚拟路由冗余协议),通过VRRP可以实现网络不间断稳定运行,因此KeepAlived一方面有服务器状态监测和故障隔离的功能,另外一方面也有HA cluster(高可用集群)功能。
2. KeepAlived工作原理
(1).虚拟路由冗余协议
VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了
(2).切换机制与心跳
Keepalived dirctors之间的故障切换转移,是通过VRRP协议来实现的。在keepalived directors正常工作时,主Directors节点会不断的向备节点广播心跳信息,用以告诉备节点自己还存活,当主节点发生故障时,备节点就无法继续检测到主节点的心跳,进而调用自身的接管程序,接管主节点的IP资源及服务。而当主节点恢复故障时,备节点会释放主节点故障时自身接管的IP资源及服务,恢复到原来的自身的备用角色
3. KeepAlived配置
(1) VRRP D配置
VRRP 的配置是 KeepAlived比较重要的配置,主要分为两个部分 VRRP 同步组和 VRRP实例,也就是想要使用 VRRP进行高可用选举,那么就一定需要配置一个VRRP实例,在实例中来定义 VIP、服务器角色等
①VRRP Sync Groups
不使用Sync Group的话,如果机器(或者说router)有两个网段,一个内网一个外网,每个网段开启一个VRRP实例,假设VRRP配置为检查内网,那么当外网出现问题时,VRRP D认为自己仍然健康,那么不会发生Master和Backup的切换,从而导致了问题。Sync group就是为了解决这个问题,可以把两个实例都放进一个Sync Group,这样的话,group里面任何一个实例出现问题都会发生切换。
vrrp_sync_group VG_1{ #监控多个网段的实例
group {
VI_1 #实例名
VI_2
......
}
notify_master /path/xx.sh #指定当切换到master时,执行的脚本
netify_backup /path/xx.sh #指定当切换到backup时,执行的脚本
notify_fault "path/xx.sh VG_1" #故障时执行的脚本
notify /path/xx.sh
smtp_alert #使用global_defs中提供的邮件地址和smtp服务器发送邮件通知
}
123456789101112
②RP实例(instance)配置
vrrp_instance VI_1 {
state MASTER #指定实例初始状态,实际的MASTER和BACKUP是选举决定的。
interface eth0 #指定实例绑定的网卡
virtual_router_id 51 #设置VRID标记,多个集群不能重复(0..255)
priority 100 #设置优先级,优先级高的会被竞选为Master,Master要高于BACKUP至
少50
advert_int 1 #检查的时间间隔,默认1s
nopreempt #不抢占模式,只在优先级高的机器上设置即可,优先级低的机器上不设置。
preempt_delay #抢占延迟,默认5分钟
debug #debug级别
authentication { #设置认证
auth_type PASS #认证方式,支持PASS和AH,官方建议使用PASS
auth_pass 1111 #认证的密码
}
virtual_ipaddress { #设置VIP,可以设置多个,用于切换时的地址绑定。格式:#
<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABE
192.168.200.16/24 dev eth0 label eth0:1
192.168.200.17/24 dev eth1 label eth1:1
192.168.200.18
}
}
(2) lvs配置(负载均衡)
虚拟服务器virtual_server定义块 ,虚拟服务器定义是KeepAlived框架最重要的项目了,是KeepAlived.conf必不可少的部分。 该部分是用来管理LVS的,是实现KeepAlived和LVS相结合的模块。ipvsadm命令可以实现的管理在这里都可以通过参数配置实现,注意:real_server是被包含在virtual_server模块中的,是子模块。
virtual_server 192.168.202.200 23 { #VIP地址,要和vrrp_instance模块中virtual_ipaddress地址一致
delay_loop 6 #健康检查时间间隔
lb_algo rr #lvs调度算法rr|wrr|lc|wlc|lblc|sh|dh
lb_kind DR #负载均衡转发规则NAT|DR|RUN
persistence_timeout 5 #会话保持时间
protocol TCP #使用的协议
persistence_granularity <NETMASK> #lvs会话保持粒度
virtualhost <string> #检查的web服务器的虚拟主机(host:头)
sorry_server<IPADDR> <port> #备用机,所有realserver失效后启用
real_server 192.168.200.5 23 { #RS的真实IP地址
weight 1 #默认为1,0为失效
inhibit_on_failure #在服务器健康检查失效时,将其设为0,而不是直接从ipvs中删除
notify_up <string> | <quoted-string> #在检测到server up后执行脚本
notify_down <string> | <quoted-string> #在检测到server down后执行脚本
TCP_CHECK { #常用检测
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 3 #重连间隔时间
connect_port 23 #健康检查的端口的端口
bindto <ip>
}
}
(二)、MHA(一主两从、一主多从或者多主多从的集群。)
方案介绍:MHA(Master High Availability)是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库的高可用,MHA通过从宕机的主服务器上保存二进制日志来进行回补,能在最大程度上减少数据丢失。MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA可以单独部署在一台独立的机器上管理多个master-slave集群,MHA Node运行在每台MySQL服务器上,主要作用是切换时处理二进制日志,确保切换尽量少丢数据。MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
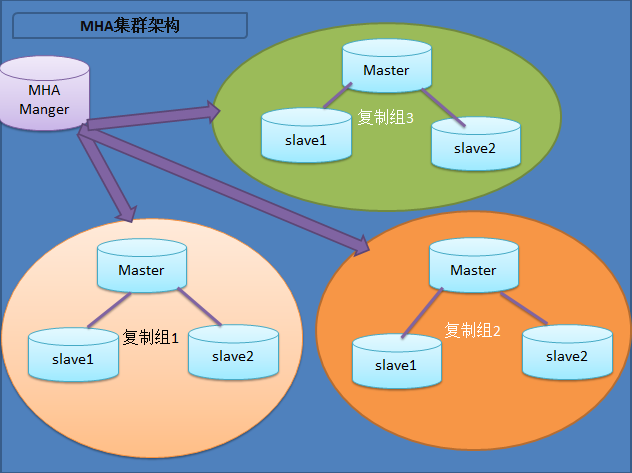
MHA failover过程:
a.检测到 Master 异常,进行一系列判断,最后确定 Master 宕掉;
b.检查配置信息,罗列出当前架构中各节点的状态;
c.根据定义的脚本处理故障的 Master,VIP漂移或者关掉mysqld服务;
d.所有 Slave 比较位点,选出位点最新的 Slave,再与 Master 比较并获得 binlog 的差异,copy 到管理节点;
e.从候选节点中选择新的 Master,新的 Master 会和位点最新的 Slave 进行比较并获得 relaylog 的差异;
f.管理节点把 binlog 的差异 copy 到新 Master,新 Master 应用 binlog 差异和 relaylog 差异,最后获得位点信息,并接受写请求(read_only=0);
g.其他 Slave 与位点最新的 Slave 进行比较,并获得 relaylog 的差异,copy 到对应的 Slave;
h.管理节点把 binlog 的差异 copy 到每个 Slave,比较 Exec_Master_Log_Pos 和 Read_Master_Log_Pos,获得差异日志;
i.每个Slave应用所有差异日志,然后 reset slave 并重新指向新 Master;
j.新 Master reset slave 来清除 Slave 信息。
优点:
- 代码开源,方便结合业务场景二次开发
- 故障切换时,可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。
- 可以灵活选择VIP方案或者全局目录数据库方案(更改Master IP映射)来进行切换。
缺点: - 无法保证强一致,因为从故障Master上保存二进制日志并不总是可行,比如Master磁盘坏了,或者SSH认证失败等。
- 只支持一主多从架构,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
- 采用全局目录数据库方案切换时,需要应用感知变化,因此对应用不透明,因此要保持切换对应用透明,依然依赖于VIP。
- 不适用于大规模集群部署,配置比较复杂。
- MHA管理节点本身的HA无法保证。
(三)、基于zookeeper的高可用
方案介绍:前面基于MySQL复制的两种方案,都存在一个不可避免的自身高可用问题,因为他们本身都是单点,而且引入多个HA软件也会带来新的分布式系统的一致性问题。而zookeeper是一个典型的发布/订阅模式的分布式数据管理和协调框架,通过zookeeper中丰富的数据节点类型进行交叉使用,配合watcher时间通知机制,可以方便地构建一系列分布式应用设计的核心功能,比如:数据发布.订阅,负载均衡,分布式协调/通知,集群管理,Master选举,分布式锁和分布式队列等。
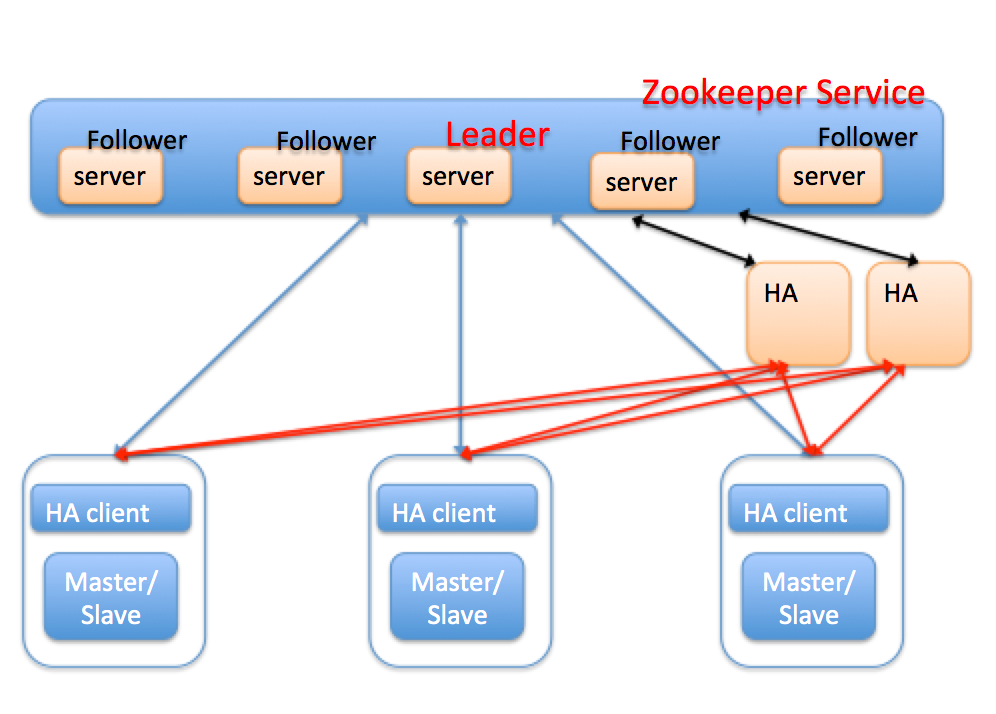
每个MySQL节点上面部署了一个HA client,用于实时向zookeeper汇报本地节点的心跳状态,比如主库crash,通过修改zookeeper(以下简称zk)上的节点信息,来通知HA。HA节点在zk上注册监听事件,当zk节点发生变化时会自动让HA感知,HA节点可以部署一个或多个,主要用于容灾。HA节点之间通过zookeeper服务来实现数据的一致性,通过分布式锁保证多个HA节点不会同时对一个主从节点进行切换。HA本身是无状态的,所有MySQL节点状态信息全部保存在zookeeper服务器上,切换时,HA会对MySQL节点进行复检,然后切换。我们看看引入zookeeper后的切换流程:
a.HA client 检测到 Master 异常,进行一系列判断,最后确定 Master 宕掉;
b.HA client 删除 Master在zk上的节点信息;
c.由于监听机制,HA会感知到有节点被删除;
d.HA对MySQL节点进行复检,比如建立连接,更新心跳表等
e.确认异常后,则进行切换。
我们再看看这种架构下,是否能保证HA自身的高可用
(1).如果HA-client本身挂了,MySQL节点正常?
HA-Client管理的MySQL节点无法与zookeeper保持心跳,zk服务将节点删除,HA会感知到这种变化,准备尝试一次切换,切换前,会进行复检,复检时发现MySQL节点是OK的,则不会切换。
(2).MySQL节点与zookeeper的网络断了,那么表现如何?
由于HA-Client与节点在同一台主机,因此HA-client无法再定时向zk汇报心跳,zk会将对应的MySQL节点信息删除,HA尝试复检,依然失败,则进行切换。
(3).HA挂了,表现如何?
由于HA无状态,并且有多个副本,因此一个HA挂了,不会对整个系统造成影响。
优点:
- 保证了整个系统的高可用
- 主从的强一致依赖于MySQL本身,比如半同步,或者外围工具的回补策略,类似MHA。
- 扩展性非常好,可以管理大规模集群。
缺点:
1.引入zookeeper,整个系统变得复杂。
四、基于分布式(多点写)方案
第三类是当前业内主流方案,该方案的特点是借助中间件进行分片,但对于同一份数据,依然只允许一个节点写,即单点写,可谓伪分布式;最后是同一个数据理论上可以再多个节点写入如,类似于oracle的RAC,以及EMC的freeplum这种分布式数据库。mysql中主要是基于Galera的PXC和NDB Cluster。MySQL Cluster实现基于NDB存储引擎,使用很多局限性,而PXC是基于innodb引擎,虽然也有局限性,但由于目前innodb使用非常广泛,所以有一定的参考价值。
(一)MySQL cluster(通过使用NDB存储引擎实时备份冗余数据)
MySQL cluster是官方集群的部署方案,通过使用NDB存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。
优点:
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
缺点:
-
国内使用的较少;
-
配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
-
至少三节点;
(二) Galera PXC
基于Galera的MySQL高可用集群, 是多主数据同步的MySQL集群解决方案,使用简单,没有单点故障,可用性高。常见架构如下
优点:
1. 多主写入,无延迟复制,能保证数据强一致性;
2. 有成熟的社区,有互联网公司在大规模的使用;
3. 自动故障转移,自动添加、剔除节点;
缺点:
1. 需要为原生MySQL节点打wsrep补丁
2. 只支持innodb储存引擎
3. 至少三节点;
选择
随着人们对数据一致性的要求不断的提高,越来越多的方法被尝试用来解决分布式数据一致性的问题,如MySQL自身的优化、MySQL集群架构的优化、Paxos、Raft、2PC算法的引入等等。
而使用分布式算法用来解决MySQL数据库数据一致性的问题的方法,也越来越被人们所接受,一系列成熟的产品如PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster等越来越多的被大规模使用。
随着官方MySQL Group Replication的GA,使用分布式协议来解决数据一致性问题已经成为了主流的方向。根据实际情况,按需求选择,MySQL高可用问题可以被更好的解决。
五、表格对比
| 方案 | 优点 | 缺点 | 适用于 | 概述 |
|---|---|---|---|---|
| 基于共享存储的SAN | 1.可以避免存储外的其它组件引起的数据丢失。 2.部署简单,切换逻辑简单,对应用透明。 3.保证主备数据的强一致。 | 1.共享存储是单点,若共享存储挂了,则会丢失数据。 2.价格比价昂贵。 | 强一致性,速度快,不差钱 | 存储设备和处理器(服务器)之间建立直接的高速网络(与LAN相比)连接,通过这种连接实现数据的集中式存储 |
| 基于磁盘复制的DRBD | 1.切换对应用透明 2.保证主备数据的强一致。 3.价格低 | 1.影响写入性能,由于每次写磁盘,实质都需要同步到网络服务器。 2.一般配置两节点同步,可扩展性比较差 3.备库不能提供读服务,资源浪费 | 对速度要求不是很高 | 以Linux内核模块方式实现的块级别同步复制技术 |
| 基于MySQL复制的KeepAlived | 1.安装配置简单 2. Master故障时,Slave快速切换提供服务,并且对应用透明。 | 1.需要主备的IP在同一个网段。 2.提供的检测机制比较弱,需要自定义脚本。 3.无法保证数据的一致性,原生的MySQL采用异步复制,对于强一致需求的,开启半同步,可以来减少数据丢失。 4. KeepAlived软件自身的HA无法保证。 | 主从或主主半同步复制 | 使用KeepAlived组件实现的MySQL高可用 |
| 基于MySQL复制的MHA | 1.代码开源,方便结合业务场景二次开发 2.故障切换时,可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。 3.可以灵活选择VIP方案或者全局目录数据库方案(更改Master IP映射)来进行切换。 | 1.无法保证强一致,因为从故障Master上保存二进制日志并不总是可行,比如Master磁盘坏了,或者SSH认证失败等。 2.只支持一主多从架构,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。 3.采用全局目录数据库方案切换时,需要应用感知变化,因此对应用不透明,因此要保持切换对应用透明,依然依赖于VIP。 4.不适用于大规模集群部署,配置比较复杂。 5.MHA管理节点本身的HA无法保证。 | 一主两从、一主多从或者多主多从的集群。(多节点) | 从宕机的主服务器上保存二进制日志来进行回补,能在最大程度上减少数据丢失 |
| 基于MySQL复制的Zookeeper | 1.保证了整个系统的高可用 2.主从的强一致依赖于MySQL本身,比如半同步,或者外围工具的回补策略,类似MHA。 3.扩展性非常好,可以管理大规模集群。 | 1.引入zookeeper,整个系统变得复杂。 | 整个系统高可用 | 使用分布式算法保证集群数据的一致性 |
| MySQL cluster | 1.全部使用官方组件,不依赖于第三方软件; 2.可以实现数据的强一致性; | 1.国内使用的较少; 2.配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异; 3.至少三节点 | 不依赖于第三方软件 | 使用NDB存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。 |
| Galera的PXC | 1.多主写入,无延迟复制,能保证数据强一致性; 2.有成熟的社区,有互联网公司在大规模的使用; 3. 自动故障转移,自动添加、剔除节点; | 1.需要为原生MySQL节点打wsrep补丁 2.只支持innodb储存引擎 至少三节点; | 是多主数据同步的MySQL集群解决方案 |















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









