







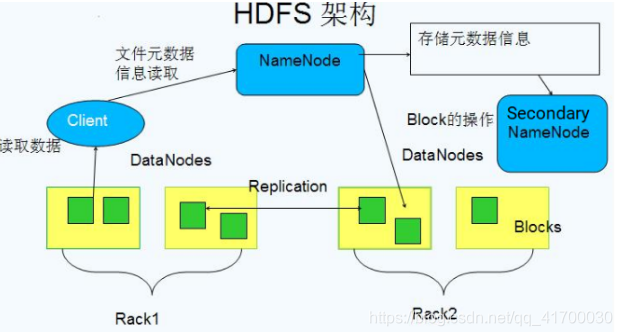
简单了解一下Hadoop的Hdfs(分布式文件存储系统)
1、Hdfs将一个很大的数据分割成很多小的数据块(Blocks)存储在数据节点(DataNode)上,由NameNode进行管理
2、提供副本进行容错及可靠性保证,每个数据默认在两个不通机架的三个节点上保存由三个副本
3、HDFS是针对MapReduce设计的,使得数据尽可能根据其本地局部性进行访问与计算。
5、提供对这些信息的快速访问,并提供可扩展的方式。能够通过简单加入更多服务器的方式就能够服务更多的
NameNode
文件信息在硬盘上保存成两个文件:命名空间镜像文件(fsimage)和修改日志文件(edit log)。此外,NameNode还保存一个文件,用来存储数据块在数据节点的分布情况。系统启动之时,这些信息会加载到内存中。
1.存储文件元数据,比如整棵树的目录结构,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
2.运行NameNode的服务器至关重要,只有1个,一旦失效则整个文件系统失效
3.只对元数据的增删做日志记录,不对block和文件流做记录。
4.DataNode故障时,负责创建更多的副本block5、数据会定时保存到本地磁盘,但不保存block的位置信息,而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









