







 本文介绍了一种使用Python pandas库分析北京2018年天气数据的方法,包括读取CSV文件,数据预处理,转换温度单位,解析日期格式,以及通过分组聚合函数计算每月最高温度、最低温度、风向列表和空气质量列表。
本文介绍了一种使用Python pandas库分析北京2018年天气数据的方法,包括读取CSV文件,数据预处理,转换温度单位,解析日期格式,以及通过分组聚合函数计算每月最高温度、最低温度、风向列表和空气质量列表。
需求:
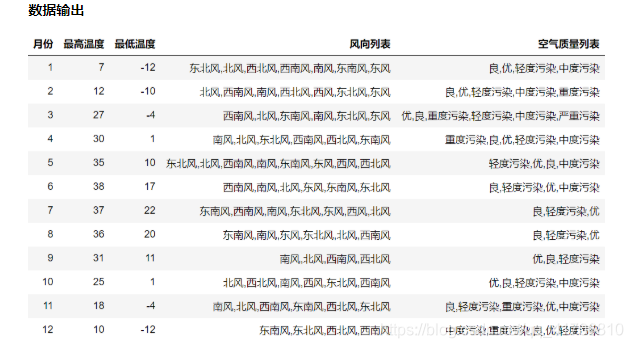
计算每个月的最高温度、最低温度、出现的风向列表、出现的空气质量列表

1、读取数据
import pandas as pd
fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
df.head(3)
知识:使用df.info()可以查看每列的类型
df.info()

知识:series怎样从str类型变成int
df["bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df["yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')
df.head(3)
知识:进行日期列解析,可以方便提取月份
df["ymd"] = pd.to_datetime(df["ymd"])
df["ymd"].dt.month
知识:series可以用Series.unique去重
df["fengxiang"].unique()
知识:可以用",".join(series)实现数组合并成大字符串
",".join(df["fengxiang"].unique())
2、方法1
result = (
df.groupby(df["ymd"].dt.month)
.agg(
# 新列名 = (原列名,函数)
最高温度=("bWendu", "max"),
最低温度=("yWendu", "min"),
风向列表=("fengxiang", lambda x : ",".join(x.unique())),
空气质量列表=("aqiInfo", lambda x : ",".join(x.unique()))
)
.reset_index()
.rename(columns={"ymd":"月份"})
)
3、方法2
def agg_func(x):
"""注意,这个x是每个分组的dataframe"""
return pd.Series({
"最高温度": x["bWendu"].max(),
"最低温度": x["yWendu"].min(),
"风向列表": ",".join(x["fengxiang"].unique()),
"空气质量列表": ",".join(x["aqiInfo"].unique())
})
result = df \
.groupby(df["ymd"].dt.month) \
.apply(agg_func) \
.reset_index() \
.rename(columns={"ymd":"月份"})


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









