执行脚本前需要做的操作
- 需要具备 python 的环境
具体安装这里不做赘述 - 判断是否安装 requests 包
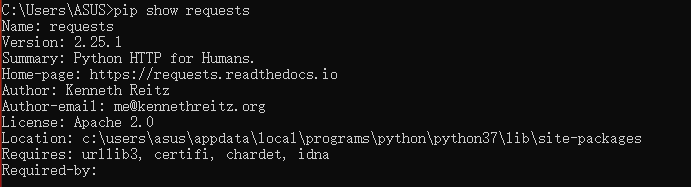
win+R 输入 cmd 打开命令提示符,输入 pip show requests, 如下则表示已具备 requests 包
- 若未安装 requests
未安装 requests 使用 pip 工具进行安装 pip install requests
 安装完成后开始写代码
安装完成后开始写代码
import requests
import os
def get(link):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(link, headers=headers)
return response
def get_json(link):
response = requests.get(link)
return response.json()
def save_data(data, filePath, wType='wb'):
path = filePath[: filePath.rfind('/') + 1]
if not os.path.exists(path):
os.makedirs(path)
if wType.find('b') == 1:
with open(filePath, wType)as f:
f.write(data)
f.flush()
else:
with open(filePath, wType, encoding='utf-8')as f:
f.write(data)
f.flush()
if __name__ == '__main__':
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/%s.js'
hero_head_url = 'https://game.gtimg.cn/images/lol/act/img/champion/%s.png'
heroLists = get_json(url).get('hero')
print('正在下载')
for hero in heroLists:
heroId = hero.get('heroId')
name = hero.get("name")
title = hero.get("title")
alias = hero.get('alias')
print(f'英雄:{hero.get("name")}-{hero.get("title")}')
print(f'\t头像:{hero.get("title")}.png')
file = './头像/%s.png' % title
headData = get(hero_head_url % alias).content
save_data(headData, file)
AudioUrls = {
'禁用时': hero['banAudio'],
'选取时': hero['selectAudio']
}
print(f'\t语音:')
for t, url in AudioUrls.items():
print(f'\t\t{t}.mp3')
file = './语音/%s/%s.mp3' % (title, t)
audioData = get(url).content
save_data(audioData, file)
hero_info = get_json(hero_info_url % heroId)
hero_skins_info = hero_info.get('skins')
hero_spells_info = hero_info.get('spells')
print(f'\t皮肤:')
for v in hero_skins_info:
hero_skin_name = v.get('name')
hero_skin_png_url = v.get('loadingImg')
print(f'\t\t{hero_skin_name}.png')
file = './皮肤/%s/%s.png' % (title, hero_skin_name)
try:
hero_skin_data = get(hero_skin_png_url).content
except requests.exceptions.MissingSchema:
hero_skin_data = get(v.get('chromaImg')).content
save_data(hero_skin_data, file)
print(f'\t技能:')
sort = ['passive', 'q', 'w', 'e', 'r']
count = 0
i = 0
while i < len(hero_spells_info):
info = hero_spells_info[count]
if info.get('spellKey') == sort[i]:
i += 1
name = info.get('name')
spellKey = info.get('spellKey').upper()
spellKey = (len(spellKey) > 1) and '被动' or spellKey
pngUrl = info.get('abilityIconPath')
txt = f"{((len(spellKey) > 1) and '属性' or '按键')}:{spellKey}\n\n技能名称:{name}\n\n{info.get('description')}"
print(f'\t\t[{spellKey}]{name}.png')
pngFile = './技能/%s/[%s]%s.png' % (title, spellKey, name)
txtFile = './技能/%s/技能描述.txt' % title
headSkill = get(pngUrl).content
save_data(headSkill, pngFile)
save_data(f"{'*' * 30}\n{txt}\n", txtFile, 'a')
else:
count += 1
if count == 5:
count = 0
print('\t\t技能描述.txt')





















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









