







快速排序是对冒泡排序的一种改进,是由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快排的主要步骤(升序排列):
第一步:先确立一个基准,也就是说,第一趟排序下来,左边的元素都比基准元素小,右边的都比基准元素大(当然这是在升序排列的情况下,降序反之)。一般都选取最后一个或者第一个元素,即temp=a[0]或者temp=a[N-1]。
i=left(左边第一个元素的下标),j=right(最后一个元素的下标。)
第二步:先从右往左(j--),遇到第一个比temp还要小的元素(即a[j]<=temp),就停止查找,把两个元素值交换。a[i]=a[j]
第三步:从左往右(i++),遇到第一个比temp大的元素(即a[i]>=temp),就停止查找,把两个元素值交换.a[j]=a[i]。
第四步:分成了两个区,继续使用这个方法,直到分出来的去只有一个元素为止。
快速排序动图
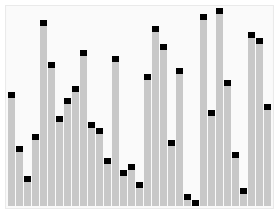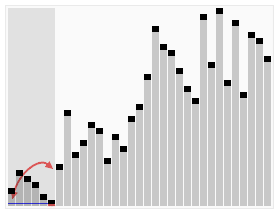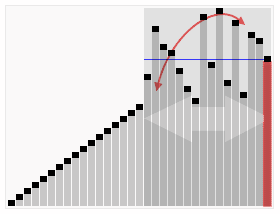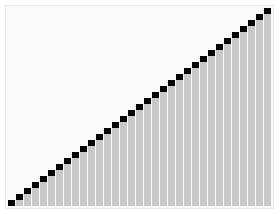
就拿a[]={5,2,7,1,8,4,9,3,6,10}这组数来举例。
第一步:temp=a[0]=5;i=0,j=9;
第二步:j--查找,当j=7时,a[j]<=temp,则a[i]=a[j],a[j]=temp,数组变为{3,2,7,1,8,4,9,5,6,10}。
然后i++查找,i=2时,a[i]>=temp,则a[j]=a[i],a[i]=temp。数组变为{3,2,5,1,8,4,9,7,6,10}。
然后在开始重复第二步的动作,直到i=j时停止。
第三步:这时的数组为:1 2 3 4 5 8 9 7 6 10。这时i=4,分为两个区间【0~3】和【5~9】重复第一步和第二步。就可以了。
最后输出结果:1 2 3 4 5 6 7 8 9 10。
源码:
//Quicksort
#include<stdio.h>
#include<string.h>
void display(int a[],int len)
{
int i=0;
for(i=0;i<len;i++)
printf("%d ",a[i]);
printf("\n");
}
void sort(int a[],int left,int right)
{
int i=left,j=right;
int temp=a[i];
if(left>=right)//如果左右下标不对,直接返回 。
return;
while(i!=j)
{
/*先从右往左,当遇到第一个小于temp的值得时候
跳出循环。a[i]赋值为a[j],这里的a[i]=temp=a[left];*/
while(i<j&&a[j]>=temp)
j--;
if(i<j)
a[i]=a[j];
/*在从左往右,当遇到第一个大于temp的时候,跳出循环
a[j]赋值为a[i]*/
while(i<j&&a[i]<=temp)
i++;
if(i<j)
a[j]=a[i];
}
a[i]=temp;//然后把中间的值换为temp.然后放区,再次循环。
sort(a,left,i-1);
sort(a,i+1,right);
}
int main()
{
int a[]={5,2,7,1,8,4,9,3,6,10},len;
len=sizeof(a)/sizeof(int);
sort(a,0,len-1);
display(a,len);
return 0;
}















 3102
3102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









