




 本文详细介绍了HDFS的元数据管理机制,包括文件的读取和写入过程,重点解析了NameNode、Block、DataNode的角色及作用。客户端通过DistributedFileSystem与NameNode交互,进行文件创建和数据流管理。DataStreamer负责建立DataNode之间的pipeline,确保数据的可靠传输。同时,文章还阐述了元数据的存储、读取和安全性保障机制。
本文详细介绍了HDFS的元数据管理机制,包括文件的读取和写入过程,重点解析了NameNode、Block、DataNode的角色及作用。客户端通过DistributedFileSystem与NameNode交互,进行文件创建和数据流管理。DataStreamer负责建立DataNode之间的pipeline,确保数据的可靠传输。同时,文章还阐述了元数据的存储、读取和安全性保障机制。
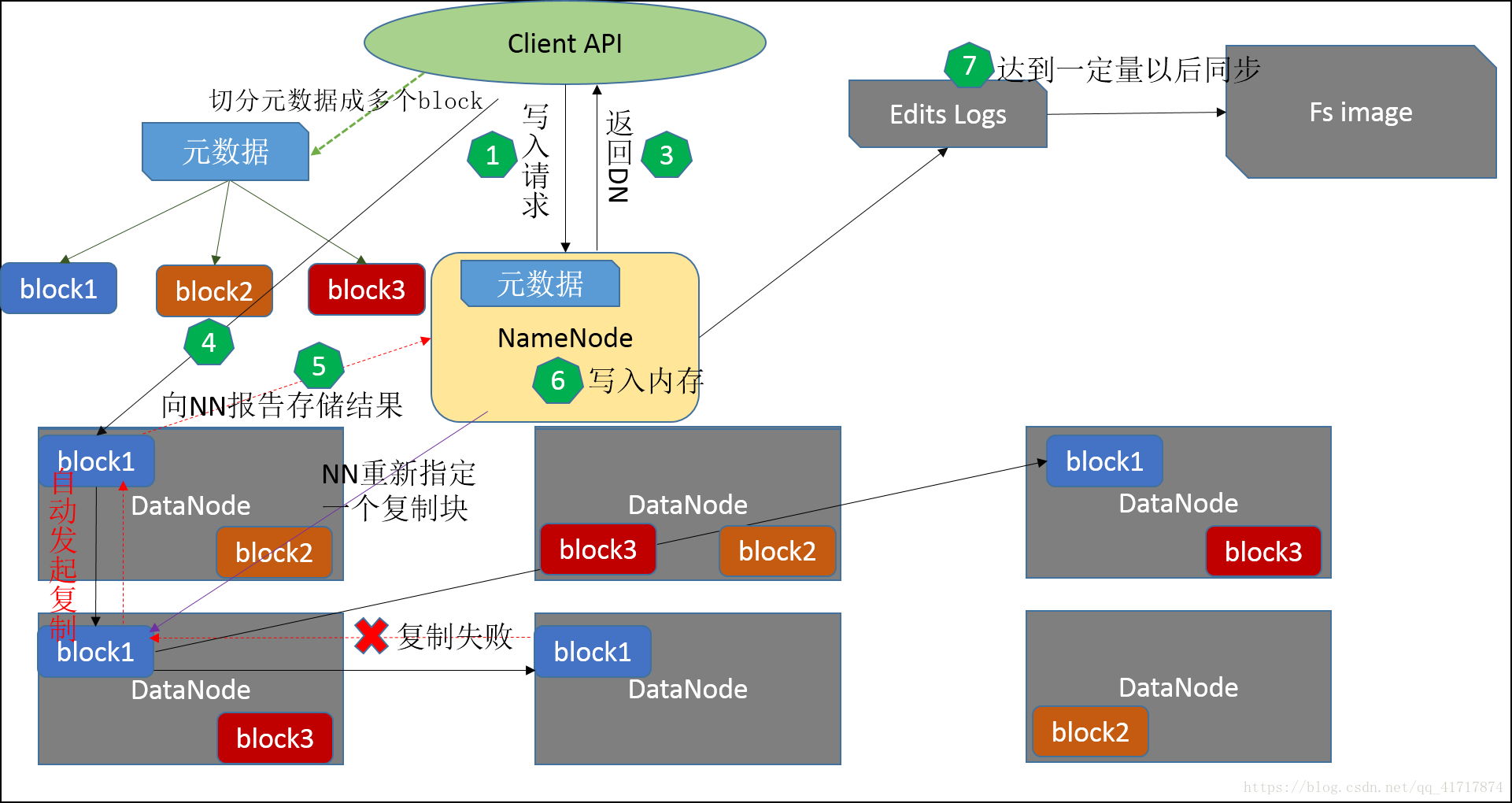
元数据管理机制
1、文件读取过程
1.客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
2.DistributedFileSystem通过RPC(远程过程调用)调用NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode就会记录下新文件,否则就会抛出IO异常。
3.前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream 可以协调 NameNode和DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
4.DataStreamer会去处理接受dataqueue,它先问询NameNode这个新的block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把它们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
5.DFSOutputStream 还有一个队列叫ack ueue,也是由packet组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
6.客户端完成写数据后,调用close方法关闭写入流。
7.DataStreamer 把剩余的包都刷到 pipeline 里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









