







 本文介绍如何在R中利用sf、tidyverse、janitor、tmap等包对地理空间数据进行读取、清洗、筛选和合并,并进行地图可视化。通过示例展示了如何筛选以'E09'开头的行政区划,并将结果与伦敦数据集合并,最后绘制了带有特定指标的地图。
本文介绍如何在R中利用sf、tidyverse、janitor、tmap等包对地理空间数据进行读取、清洗、筛选和合并,并进行地图可视化。通过示例展示了如何筛选以'E09'开头的行政区划,并将结果与伦敦数据集合并,最后绘制了带有特定指标的地图。
本节将会学习如何利用地理空间数据进行连接、筛选等操作,首先我们加载软件环境和数据。
-
sf:(simple features, standard way to encode spatial vector data
-
tidyverse:The tidyverse package is designed to make it easy to install and load core packages from the tidyverse in a single command
-
janitor:janitor has simple functions for examining and cleaning dirty data
-
tmap/tmaptools:tmap is an actively maintained open-source R-library for drawing thematic maps
library(pacman)
p_load(sf,tidyverse,janitor,tmap,tmaptools)
tmap_mode("plot")
#this will take a few minutes
EW <- st_read("https://opendata.arcgis.com/datasets/8edafbe3276d4b56aec60991cbddda50_2.geojson")
LondonData<-read_csv("https://files.datapress.com/london/dataset/ward-profiles-and-atlas/2015-09-24T14:21:24/ward-profiles-excel-version.csv",
locale = locale(encoding = "latin1"),
na = "n/a")
LondonData数据清洗之前

LondonData数据清洗之后,即使用janitor的clean_names函数对列名称做了一定的清洗,里面的空格将会变成下划线,而且大写字母会转化为小写字母。

筛选lad15cd中以“E09”开头的条目
#筛选lad15cd中以“E09”开头的条目
LondonMap<-EW%>%
filter(str_detect(lad15cd,"^E09"))
LondonMap
可视化LondonMap
qtm()
qtm(LondonMap,fill = "lad15nm")

不过这里,我们没有对EW表格中的列名称进行清洗。下面,我们要把地理信息表EW和信息表LondonData合并,采用连接的方法,整个表链接步骤如下:
BoroughDataMap<-EW %>%
clean_names()%>%
filter(str_detect(lad15cd,"^E09"))%>%
merge(.,
LondonData,
by.x="lad15cd",
by.y="new_code",
no.dups=TRUE)%>% #内连接
distinct(.,lad15cd,
.keep_all = TRUE) #去除重复条目
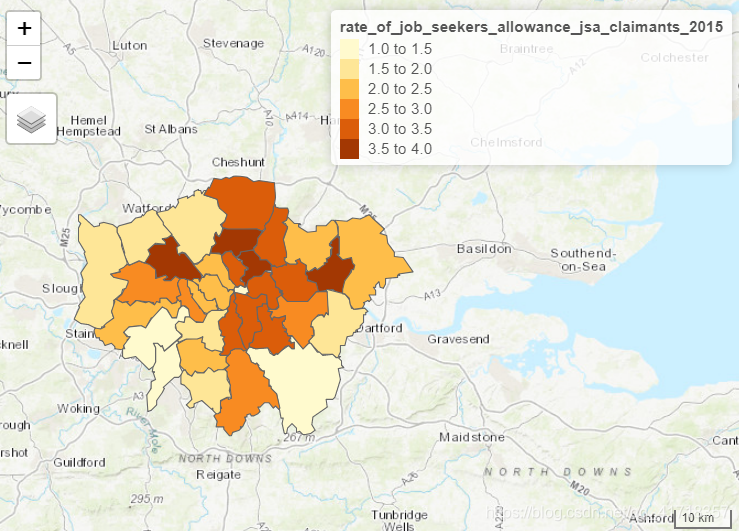
qtm(BoroughDataMap,fill = "rate_of_job_seekers_allowance_jsa_claimants_2015")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









