







Python的外交官——IO流操作目录
一、学IO操作目的是啥?
我们在编程时一般不可能只是打打代码,而没有将数据存到电脑上,比如想把一篇文章写在电脑里,或者想从电脑中查看一篇文章,那就需要IO流操作,将文章永久存到电脑上。可能很多读者都不明白,不是就简单的复制粘贴嘛,哪有那么高级。这里牛顿就会冒出来说那是你站在巨人的肩膀上,没错!我们一般用到的都是简单化的读写,你想想我们的复制粘贴哪里来?就是我们在软件内部写了IO流操作,把事情简单化了,使得我们不用考虑到这么多知识,而是简单的复制粘贴。哪有的人又问,Print函数和Input函数表示就是输入输出吗?是的,但是我们不可能让用户去编写一段代码吧,肯定需要让用户操作的越简单越好啦!再加上电脑已关机,输入的文字就会随之消失!
那什么是IO流操作呢?
首先我们需要清楚IO流操作中的读写操作不是我们平时所说读写看,而是将数据加载到硬盘中,我们叫IO流的写操作,即输入流,将硬盘加载出来,叫做IO流的读操作,即输出流。
那问题来了,什么是流?
流是个比较抽象的概念,可以这么理解,假设硬盘是大海,那么数据流就可以是水流,水要进入大海就是输入流,水要流出来就是输出流。字节流就是一滴一滴地流,字符流就是一大块一大块地流,区别嘛,就是字节流变得更加简单和纯净,而字符流,什么垃圾啊,鱼啊,一起加进去流动。
流操作分类
1.按照数据流方向可以分为输入流和输出流。
2.按照处理数据类型的单位不同可以分为字节流和字符流。
所以IO流操作就是一种抽象的概念,即Input Output Stream,输入输出流,以流的方式进行输入输出。
一个完整的IO操作,一般为以下步骤:
打开文件 ==> 读取数据 ==> 数据运算 ==> 数据的持久化 ==> 关闭资源
读取数据是将数据从一个持久化设备(比如硬盘,U盘)中读取到内存(这东西比硬盘快)中。
(以上是个人理解)
二、open函数
那很多人就感觉IO流应该是一只非常难搞的鸭子!说实话,确实有点,在其他编程语言中,IO流操作一直都是一大难点之一,但是在Python中,它就是一个函数,一个内置函数,Python团队将它简单化了!
格式
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file:必选参数,传入的文件名路径,可以是相对路径也可以是绝对路径。
mode:可选参数,用于指定文件的打开方式,默认为r。
buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(可以理解为为内存),为0则表示在打开指定文件时不使用缓冲区,为大于0的整数用于指定缓冲区的大小(单位是字节),为小于0则代表使用默认的区大小。建议为默认值,因为快啊!
encoding:设定打开文件时所使用的编码格式。
errors:可选参数,指定编码错误如何处理,不在二进制模式下使用。
newline:可选参数,就是用来换行的。
closefd:可选参数,一般用不到
opener:可选参数,一般用不到
三、open函数使用
1.输入流与输出流
输入流输出流其实是和字符字节流一起套用的,就相当于一个改变的是水流方向,一个是水的容量,我们先演示的是字符流,一般情况下,字符流是不需要使用关键传参的。
注意:默认为mode="rt"
下面是mode值的参数表:
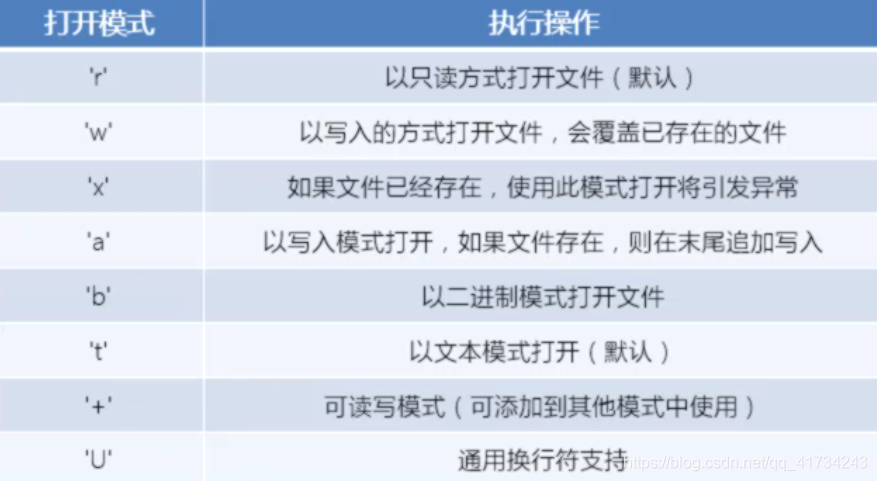
a.输出流就是mode=“r”
代码
#假设文件名为China.txt 内容为:我爱中国!也爱Python!
#由于Win系统编码不能显示汉字所以使用utf-8
#read函数是只读模式下使用的用来读出数据,只读模式下不可以使用write函数
#close函数是关闭文件,防止内存占用,虽然Python默认有内存回收机制,但是以防万一嘛!
op = open("H:\\China.txt", encoding="utf-8")
print(op.read())
op.close()
显示结果
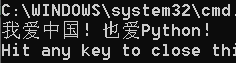
b.输入流就是mode=“w"或者"a”
会发现怎么输入流是两个呢?因为"w"表示的是将原来的覆盖,重新写,而"a"是在原来的基础上添加!
代码
#假设文件名为China.txt 内容:我爱中国!也爱Python!
#weite函数接收字符后,返回字符个数,只写模式下不可以使用read函数
op_1 = open("H:\\China.txt", "a", encoding="utf-8")
op_2 = open("H:\\Python.txt", "w", encoding="utf-8")
print(op_1.write("我爱中国!也爱Python!"))
print(op_2.write("我爱中国!爱Python!"))
op_1.close()
op_2.close()
显示结果
2.字节操作
接下来就是字节流操作,字节流操作的读操作是输出一堆字节,所以没有编码,必须将字符转换成字节才能传输,就相当于小吸管不能塞进大鱼一样。
在Python中在字符引号前面加b就是将其改变成字节。
注意:字节流操作不支持编码参数传参,即encoding为默认值
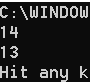
字节的输出流操作
就是mode="rb"
代码
#假设文件名为China.txt 内容为:我爱中国!也爱Python!
#由于Win系统编码不能显示汉字所以使用utf-8
#read函数是只读模式下使用的用来读出数据,只读模式下不可以使用write函数
#close函数是关闭文件,防止内存占用,虽然Python默认有内存回收机制,但是以防万一嘛!
#注意字节流操作不支持编码
op = open("H:\\China.txt", "rb")
print(op.read())
op.close()
显示结果

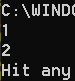
字节的输入流操作
就是mode="ab"或者mode="wb"
代码
#假设文件名为China.txt 内容:字节1和13
#b在Python中表示字节,所以在字节流中只能传字节
#weite函数接收字符后,返回字符个数,只写模式下不可以使用read函数
op_1 = open("H:\\China.txt", "ab")
op_2 = open("H:\\Python.txt", "wb")
print(op_1.write(b'1'))
print(op_2.write(b'13'))
op_1.close()
op_2.close()
显示结果
下面是mode参数的组合:
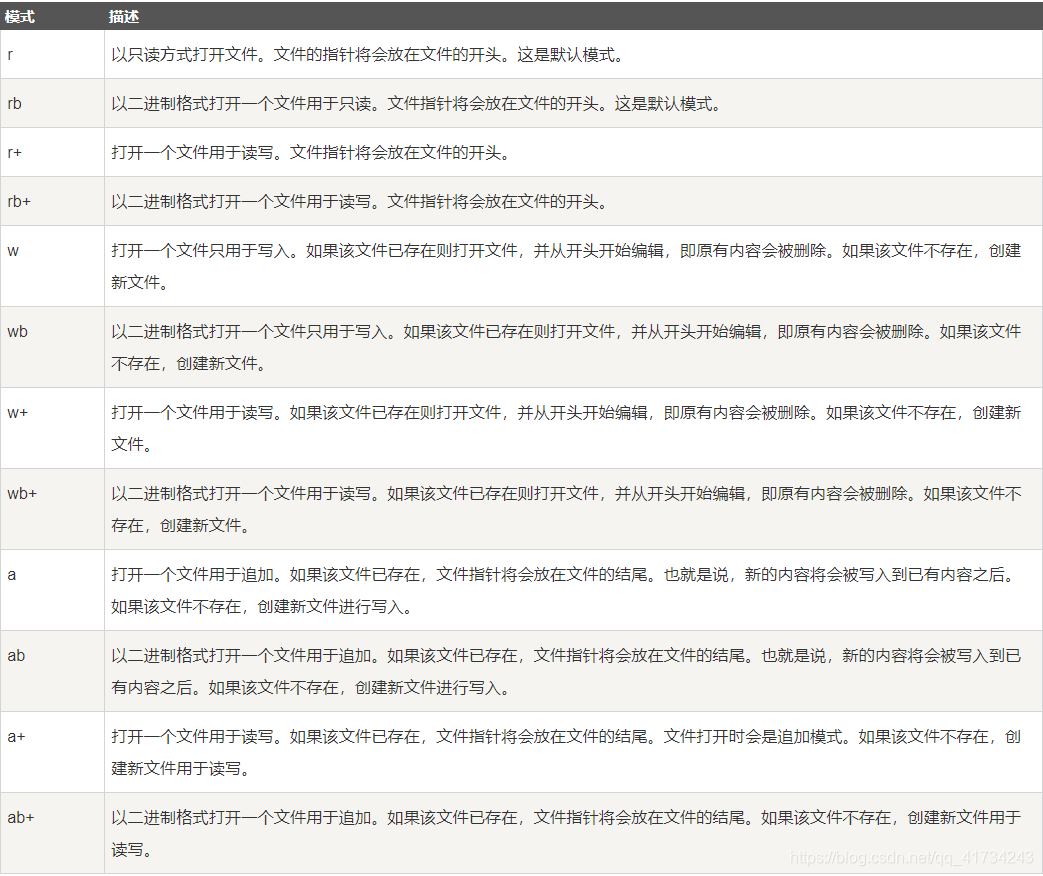
下面是文件对象内置方法:

四、with语句块
with语句块是一种从Python2.5引入的一个新的语法,它是一种上下文管理协议,目的在于从流程图中把 try,except 和finally 关键字和资源分配释放相关代码统统去掉,简化try…except…finlally(后面会讲的异常处理)的处理流程。说白了就是对没有关掉文件对象,默认使用close函数,避免程序员忘记关闭。(说实话,一个字,周到!)
格式:
with expression [as target]:
…语句块
expression:一个需要执行的表达式
target:一个变量或者元组,存储的是expression表达式执行返回的结果,可选参数。
代码
file_1 = open("H:\\China.txt", "r", encoding="utf-8")
with file_1 as f:
print(f.read())
显示结果

五、对象的序列化和反序列化
对象概念是一个逻辑单位,它是比较抽象的一个概念。后面会详细讲解,目前暂时理解为,一种黑盒子或者一种思维。
对象的序列化和反序列化也是一种抽象的概念,我们可以理解为,一种思维实体化,就是说,一个虚无的东西变成一种可以摸得到看的到的东西,比如开心这个感觉,它是虚无,看不到也摸不着的,但是我们通过文字开心就能明白这个东西是什么,从开心这个感觉到文字的展现的这个过程叫序列化,而反序列化,就是我们通过读懂文字知道开心这个感觉的这个过程。简而言之就是思维实体化。
对象序列化就是将对象这个概念变成字节数据,反之,就是反序列化。我们可以通过导入pickle模块的dump/dumps方法进行序列化,load/loads方法进行反序列化。还有json模块也是,但是一般用来序列化字典类型的数据。
关于json/pickle模块的序列化函数使用:链接在此
1.序列化
代码
import pickle
list_1 = [19,2,4,69,77,8,9]
list_2 = [8,2,84,67,7,8,9]
file_1 = open("H:\\list_1.txt", "wb")
file_2 = open("H:\\list_2.txt", "wb")
data_1 = pickle.dump(list_1, file_1)
print(data_1) #返回None
file_1.close()
data_2 = pickle.dumps(list_2)
with file_2 as f:
print(f.write(data_2))
显示结果
2.反序列化
代码
import pickle
file_1 = open("H:\\list_1.txt", "rb")
file_2 = open("H:\\list_2.txt", "rb")
list_1 = pickle.load(file_1)
file_1.close()
with file_2 as f:
data_2 = f.read()
list_2 = pickle.loads(data_2)
print(list_1)
print(list_2)
显示结果















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









