







写在前面
在很久之前就已经学过了爬虫。那时还是懵懵懂懂的小白,学了一点基础,就买来一本书,然后就开干。代码倒是写了不少,但是没有什么拿的出手的。之后,便又匆匆忙忙的转战 web ,学起了 Django 。这一入坑,不知不觉差不多快一年了。最后发现自己知道的依旧凤毛麟角。没有基础的计算机网络知识,没有良好的代码编写规范……
意识到问题后,开始试着阅读官方文档,去看协议,看源码。这些天看了 http 协议,计算机网络基础,python 文档,以及 Scrapy 文档。不得不说,看完后虽然记住的不多,但是大致是怎么一回事,多多少少还是了解了。比如,当初的爬虫程序,为什么要设置 header 、cookie 、session 什么的。还有 request 和 response 的含义。
这些天看了一下 Scrapy 的 官方文档,对这个框架有了一些了解。正如文档中所提到的,scrapy 框架很大程度上借鉴了 Django ,这也是为什么现在的我重新来看待它时,比之前要轻松太多了。
关于 Scrapy
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
学习一个框架,得明白,它是什么?怎么做?更深入为什么要这样做?
是什么?
简而言之,就是一个支持分布式的,可扩展的,用于批量爬取网站并提取结构化数据的异步应用程序框架。值得一提的是,Scrapy 是用 Twisted 编写的,Twisted 是一种流行的 Python 事件驱动的网络框架。因此,它是使用非阻塞(又称为异步)代码并发实现的。
Scrapy 有着丰富的命令行工具,交互式控制台,内置支持以多种格式(json、xml、csv)等。
怎么做?
要使用 Scrapy ,我们不得不先安装它。文档为我们提供的良好的 安装指南 。
我们只需要这样做:
pip install Scrapy
不过我们不得不知道下面文档中提到的:
Scrapy is written in pure Python and depends on a few key Python packages (among others)
Scrapy 需要一些依赖包:
- lxml,高效的XML和HTML解析器
- parsel,是在lxml之上编写的HTML / XML数据提取库
- w3lib,用于处理URL和网页编码的多功能帮助器
- twisted,异步网络框架
- cryptography 和 pyOpenSSL ,以处理各种网络级安全需求
其中还有一些版本要求:
- Twisted 14.0
- lxml 3.4
- pyOpenSSL 0.14
如果你没有这些依赖包,那你不得不考虑先安装依赖。在此建议使用清华源下载,这样可以避免不必要的 Time out 。如下:
pip install [example_modul] -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完成后,就可以开始按接下来的教程 学习了。
像这样创建一个项目:
> scrapy startproject tutorial
编写自己的爬虫类:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
运行项目:
> scrapy crawl quotes
至此,一个基本可以运行的 Scrapy 项目就成型了。
框架概述
在依葫芦画瓢的完成一个 Scrapy 项目的编写后,要想明白为什么要这样编写我们的爬虫程序,就不得不了解这个框架的一些细节。
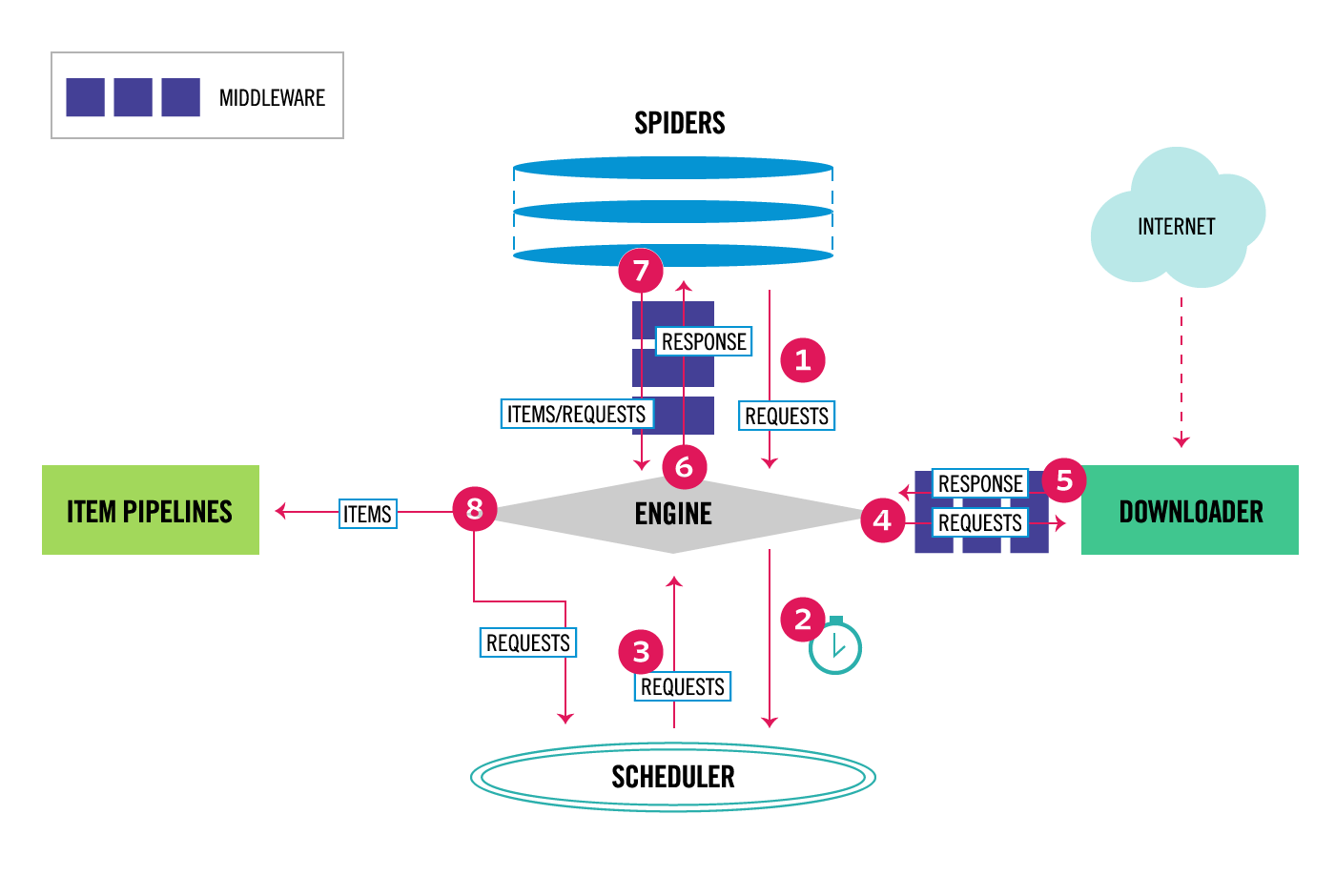
Scrapy的体系结构及组件如下图所示:
对照着 Scrapy 的项目结构:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
quotes_spider.py # a spider written by yourself
学过 Django 就会发现,这个框架简直就是套着它的设计模式来的。全局设置的 settings.py 、项目的管道 pipelines.py 、强大可扩展的中间件 middlewares.py 、以及类似模型的 items.py 。从图中我们不难发现,spiders可以对 requests 和 response 进行处理。而中间件 middlewares还可以对 items 进行处理。 管道 pipelines 对输出的 items 进行最后的清洗。所以,在我们明白要对数据做怎样处理时,只需要在对应的地方按要求编写我们的代码来达到我们的目的即可。
一个例子:如果我们需要对最后清洗的数据保存到一个文件(如:json文件)中,那么你可能就要在管道 pipelines.py 中编写合适代码来实现。像这样子:
import json
class JsonWriterPipeline(object):
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def open_spider(self, spider):
self.file = open('items.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
-
process_item (self, item, spider)
每个项目管道组件均调用此方法,返回一个 item 对象,返回 Twisted Deferred 或引发 DropItem 异常。
如果要使用自己的管道,那么就不得不实现此方法。
除此之外,还可以实现下面几种方法:
-
open_spider(self, spider)
This method is called when the spider is opened.
-
close_spider(self, spider)
This method is called when the spider is closed.
-
from_crawler(cls, crawler)
If present, this classmethod is called to create a pipeline instance from a Crawler. It must return a new instance of the pipeline. Crawler object provides access to all Scrapy core components like settings and signals; it is a way for pipeline to access them and hook its functionality into Scrapy.
编写完自己的 Item Pipeline后,我们还需要在
settings.py中激活才能使用。像这样:ITEM_PIPELINES = { 'myproject.pipelines.JsonWriterPipeline': 800, }需要注意的是,管道组件以字典的形式配置,并分配一整数值(0 ~ 1000),项目将按升序方式依次执行。
补一篇关于 Scrapy 的笔记算是对很久之前的一个总结吧!
路漫漫其修远兮吾将上下而求索。
I know nothing but my ignorance.















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









