 Netty线程模型解析
Netty线程模型解析






 本文深入剖析Netty的线程模型,包括线程组、NioEventLoopGroup的初始化及运作过程,揭示Netty如何高效处理I/O事件,特别聚焦于Reactor模式下服务端与客户端的事件处理机制。
本文深入剖析Netty的线程模型,包括线程组、NioEventLoopGroup的初始化及运作过程,揭示Netty如何高效处理I/O事件,特别聚焦于Reactor模式下服务端与客户端的事件处理机制。
文章目录
前言
个人认为,Netty中最核心的就是它的线程模型了,可以之为Netty的引擎、发动机,它负责了Netty整个正常运作流程,此篇文章将揭开Netty线程模型的面纱,并且介绍一般的线程组NioEventLoopGroup的初始化与运作的过程。在最后,我们紧接着上一篇文章 服务端启动 ,来聊一聊当一个客户端连接进来后,Netty会做怎样的操作
线程组的初始化
在我们服务端启动的代码中,绑定端口之前,我们new了两个NioEventLoopGroup
EventLoopGroup是一个存放NioEventLoop的线程组,在Netty中,一个线程组可以存放多个NioEventLoop,而一个NioEventLoop对应一个线程
EventLoopGroup bossEventLoop = new NioEventLoopGroup(1);
EventLoopGroup workerEventLoop = new NioEventLoopGroup();
那么首先来看看其构造函数做了什么
public NioEventLoopGroup() {
this(0);
}
public NioEventLoopGroup(int nThreads) {
this(nThreads, (Executor) null);
}
public NioEventLoopGroup(int nThreads, Executor executor) {
// SelectorProvider为jdk底层创建selector的类
this(nThreads, executor, SelectorProvider.provider());
}
// ...
// 总之这里会调用很多层构造函数,这里只看关键地方,跳过中间若干个构造函数
protected MultithreadEventLoopGroup(int nThreads, Executor executor, Object... args) {
// 当我们没设置线程数量,这里使用了默认的线程数量
super(nThreads == 0 ? DEFAULT_EVENT_LOOP_THREADS : nThreads, executor, args);
}
这个默认的线程数量是多少呢
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt(
"io.netty.eventLoopThreads", Runtime.getRuntime().availableProcessors() * 2));
这里会拿到系统配置,如果没有配置io.netty.eventLoopThreads这个系统配置,默认会取到两倍处理器数量的线程,最小为1,所以这里nThreads值如果没设置的话默认为两倍的处理器数量。继续往下走
protected MultithreadEventExecutorGroup(int nThreads, Executor executor,
EventExecutorChooserFactory chooserFactory, Object... args) {
if (executor == null) {
// 这个executor主要的作用是为了包装一个任务类,给他取名然后创建线程
executor = new ThreadPerTaskExecutor(newDefaultThreadFactory());
}
// 初始化一个线程组,数量为处理器的两倍
children = new EventExecutor[nThreads];
// 为这个线程池数组各个赋值
for (int i = 0; i < nThreads; i ++) {
boolean success = false;
try {
// 创建NioEventLoop放入数组
children[i] = newChild(executor, args);
success = true;
}
...
}
// 创建一个线程选择器
chooser = chooserFactory.newChooser(children);
...
}
这里我们就可以看出来了,在NioEventLoopGroup中,保存了一个NioEventLoop类型的数组对象,也就是说,一个线程组是对应多个NioEventLoop的,对应多少取决于你的配置,默认为处理器两倍。在newChild方法中创建
NioEventLoop(真正执行任务的发动机),这个方法是个多态方法,这里进入NioEventLoopGroup
protected EventLoop newChild(Executor executor, Object... args) throws Exception {
return new NioEventLoop(this, executor, (SelectorProvider) args[0],
((SelectStrategyFactory) args[1]).newSelectStrategy(), (RejectedExecutionHandler) args[2]);
}
这里调用NioEventLoop的构造函数实例化了一个NioEventLoop,然后放到上面的数组中,对于其构造函数的分析我们放到下面一节来介绍
让我们回到上面,在为数组中每个位置赋值之后,会创建一个线程选择器EventExecutorChooser,这是做什么用的呢?我们知道,在线程组中对应多个发动机线程NioEventLoop,那么一个channel进来之后就会借助这个选择器来选择一个NioEventLoop,将其分配给channel,可以做到大量channel进来之后可以均匀分配到这些NioEventLoop上
// 在向线程组提交一个任务时,他调用了next方法选择了一个NioEventLoop去执行该任务
public void execute(Runnable command) {
next().execute(command);
}
// 在注册channel时也是调用next方法选择一个NioEventLoop去注册
public ChannelFuture register(Channel channel) {
return next().register(channel);
}
那么这个next方法做了什么呢
public EventExecutor next() {
return chooser.next();
}
可以看到,这里委派给了之前的选择器来做了选择的逻辑,那么这里chooser对象是哪个选择器实例呢?在EventLoopGroup的层层构造函数中可以找到,默认是以下实现
public static final DefaultEventExecutorChooserFactory INSTANCE = new DefaultEventExecutorChooserFactory();
他的newChooser方法如下
public EventExecutorChooser newChooser(EventExecutor[] executors) {
// 如果是2的幂,意味着可以使用位运算计算
if (isPowerOfTwo(executors.length)) {
return new PowerOfTowEventExecutorChooser(executors);
} else {
// 若不是,采用普通的运算
return new GenericEventExecutorChooser(executors);
}
}
那么这两个运算有什么区别呢?先来看看普通的选择器是如何计算的
private final AtomicInteger idx = new AtomicInteger();
public EventExecutor next() {
// 使用计数器,与线程数量取余数
return executors[Math.abs(idx.getAndIncrement() % executors.length)];
}
再来看看位运算是如何计算的
private final AtomicInteger idx = new AtomicInteger();
public EventExecutor next() {
// 直接与上线程数量-1
return executors[idx.getAndIncrement() & executors.length - 1];
}
若线程数量为2,则这里将把计数器与上2-1=1,也就是说二进制第一位为1的数(奇数)会分配给下标为1(第二个线程),二进制第一位为0的数(偶数)会分配给下标为0(第一个线程),这样就能做到均匀分配。
明显使用位运算性能更好,所以由此可见,如果是我们自己设置线程数量的话,最好设置数量为2的幂
到这里线程组的初始化就完成了,主要做了以下两件事
- 在其内部成员变量保存一个NioEventLoop数组,并且一个个将其实例化出来放入数组
- 根据设置的线程数量决定选择器的实现,可以有位运算、取余运算的实现,并保存到成员变量中,在之后执行任务的时候都会从上面的数组中取出一个线程来执行任务
发动机线程的初始化
这里剧透一下,一个发动机(EventLoop)对应一个线程,所以这里线程组的线程模型已经初具端倪,其结构为一个线程池对应多个发动机线程,在每个Channel来到之后都会向线程组发起注册,而线程组会从众多线程中取出一个线程与channel唯一绑定,接下来这个channel的操作都会在这个线程中进行,达到无锁串行化的目的
从上面可以知道,线程组将每个发动机(EventLoop)都实例化放入数组中,所以这里我们把重点放到发动机的构造函数中去
NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider selectorProvider,
SelectStrategy strategy, RejectedExecutionHandler rejectedExecutionHandler) {
// 调用了父类的构造函数
super(parent, executor, false, DEFAULT_MAX_PENDING_TASKS, rejectedExecutionHandler);
// JDK底层开启selector的类
provider = selectorProvider;
// 其调用了上面的类的openSelector方法,开启一个selector实例保存下来
selector = openSelector();
selectStrategy = strategy;
}
到这里我们可以知道,一个发动机线程是对应一个selector的。接着进入父类构造函数
protected SingleThreadEventLoop(EventLoopGroup parent, Executor executor,
boolean addTaskWakesUp, int maxPendingTasks,
RejectedExecutionHandler rejectedExecutionHandler) {
super(parent, executor, addTaskWakesUp, maxPendingTasks, rejectedExecutionHandler);
// 这里创建了一个队列,用于存放待执行的任务的,后面会介绍到
tailTasks = newTaskQueue(maxPendingTasks);
}
值得一提的是这里创建了一个LinkedBlockingQueue阻塞队列保存下来,这个阻塞队列在后面会介绍到其作用,这里只需要知道它保存了任务,定期取出执行。这里继续进入父类构造函数
protected SingleThreadEventExecutor(EventExecutorGroup parent, Executor executor,
boolean addTaskWakesUp, int maxPendingTasks,
RejectedExecutionHandler rejectedHandler) {
super(parent);
this.addTaskWakesUp = addTaskWakesUp;
this.maxPendingTasks = Math.max(16, maxPendingTasks);
// 如果忘记这个值,可以往上看线程组构造函数
// 这个executor主要是用来创建一个特殊名字的线程,并且包装任务类
this.executor = ObjectUtil.checkNotNull(executor, "executor");
// 这个也是存放待执行的任务的阻塞队列
taskQueue = newTaskQueue(this.maxPendingTasks);
rejectedExecutionHandler = ObjectUtil.checkNotNull(rejectedHandler, "rejectedHandler");
}
到这里初始化工作就做完了,其实很简单,值得关注的有以下几点:
- 一个发动机线程开启了一个selector
- 一个发动机线程创建了两个存放任务的阻塞队列
- 存放了一个executor,其内部是一个线程工厂,专门用来创建线程用
发动机启动
上面都是做一系列初始化的工作,此时的线程还都没被创建,发动机都还未启动,那么在什么时候会启动呢?就拿上一篇文章为例,在服务端引导类启动过程中,会调用initAndRegister这个方法去初始化和注册Channel,相信看过上一篇文章的读者都会记得这个方法,其在初始化完服务端Channel之后,会调用如下方法注册Channel
config().group().register(channel);
这里config().group()方法返回的即为我们开头说的名为bossEventLoop这个线程组,由上面的线程组初始化的逻辑来看,此时线程组内有一个线程数组,里面存放一个线程(因为我们初始化bossEventLoop的时候传入参数为1),那么调用线程组的register方法会做什么
public ChannelFuture register(Channel channel) {
// 选择一个线程执行register方法
return next().register(channel);
}
@Override
public ChannelFuture register(Channel channel) {
return register(new DefaultChannelPromise(channel, this));
}
@Override
public ChannelFuture register(final ChannelPromise promise) {
ObjectUtil.checkNotNull(promise, "promise");
// 调用unsafe的register方法
promise.channel().unsafe().register(this, promise);
return promise;
}
不多说,继续往下看
public final void register(EventLoop eventLoop, final ChannelPromise promise) {
// 将上面next选择到的线程唯一绑定一个channel
// 保存在channel的成员变量中
AbstractChannel.this.eventLoop = eventLoop;
// 判断本线程是否是发动机线程
if (eventLoop.inEventLoop()) {
register0(promise);
} else {
try {
// 如果不是,需要让发动机线程执行以下逻辑
eventLoop.execute(new Runnable() {
@Override
public void run() {
register0(promise);
}
});
}
}
}
这里调用了eventLoop的inEventLoop方法来判断本线程是否是发动机线程
public boolean inEventLoop() {
return inEventLoop(Thread.currentThread());
}
public boolean inEventLoop(Thread thread) {
return thread == this.thread;
}
一个发动机只有唯一一个线程与之对应,所以这里直接调用Thread.currentThread()取出当前线程与发动机线程进行比对,但此时发动机还未启动,发动机线程是为null的,所以这里会执行下面的execute逻辑
public void execute(Runnable task) {
// 这里thread = null,所以为false
boolean inEventLoop = inEventLoop();
if (inEventLoop) {
addTask(task);
} else {
// 执行此段逻辑,启动发动机
startThread();
...
}
...
}
到这里,才真正开始启动发动机,进入startThread方法
private void startThread() {
if (STATE_UPDATER.get(this) == ST_NOT_STARTED) {
if (STATE_UPDATER.compareAndSet(this, ST_NOT_STARTED, ST_STARTED)) {
doStartThread();
}
}
}
这里使用了CAS并发技巧(在JUC包中大量使用这种乐观锁的方式来协调各个线程),保证了只会有一个线程执行该方法成功,其他竞争失败线程都会放弃执行该方法,保证了该方法只会执行一次
// 原子域更新类,用于标示发动机的线程启动状态
private static final AtomicIntegerFieldUpdater<SingleThreadEventExecutor> STATE_UPDATER;
若一条线程启动成功,将会更新状态为ST_STARTED,标示已经启动了,别的线程是不会再启动,而启动逻辑则是创建一个线程,所以由此可以看出,一个发动机是对应一个线程的。
这里回到doStartThread方法中
private void doStartThread() {
assert thread == null;
// 这里executor的execute是一个线程工厂,用来包装线程的
// 如果忘记此变量是什么的读者,可以看看前面线程组的构造函数
// 调用此方法,包装线程并调用start()启动线程
executor.execute(new Runnable() {
@Override
public void run() {
// 将当前线程保存下来,标示发动机唯一对应的那个线程
thread = Thread.currentThread();
boolean success = false;
updateLastExecutionTime();
try {
// 主要驱动方法,此方法不断进行循环操作
SingleThreadEventExecutor.this.run();
success = true;
}
...
}
});
}
这里SingleThreadEventExecutor.this.run()方法最为关键,此方法是一个多态方法,主要做了发动机的逻辑,循环做一系列任务。进入NioEventLoop类看看
protected void run() {
// 不断循环执行
for (;;) {
try {
// 首先调用默认策略,策略实例在构造函数赋值的
// 此策略检查阻塞队列中是否有任务,若有,则调用selectNow方法select一次
// 若没有,则进入下面的SELECT分支,进行select阻塞轮询channel事件
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.SELECT:
// 阻塞轮询channel事件,并将wakeUp状态位更新微false,将旧值作为参数传入方法
select(wakenUp.getAndSet(false));
// 如果wakenUp标志位为true
if (wakenUp.get()) {
// 唤醒正在阻塞的selector
selector.wakeup();
}
default:
// fallthrough
}
cancelledKeys = 0;
needsToSelectAgain = false;
// IO操作与执行任务的比例
final int ioRatio = this.ioRatio;
// 如果比例100%,表示执行任务就没有超时的时间
if (ioRatio == 100) {
try {
// 处理selector轮询到的channel事件
processSelectedKeys();
} finally {
// Ensure we always run tasks.
// 最后运行注册到线程的任务
runAllTasks();
}
} else {
// 到此分支,证明比例不是100%,默认为50
// 这里记录IO的时间
final long ioStartTime = System.nanoTime();
try {
// 处理轮询到的channel事件
processSelectedKeys();
} finally {
// Ensure we always run tasks.
// 这里即为io的时间
final long ioTime = System.nanoTime() - ioStartTime;
// ioTime * (100 - ioRatio) / ioRatio这个表达式可以看成
// 默认:50% * IO时间,如果IO时间为10s,那么就规定执行taskQueue队列
// 的任务最多执行5s时间
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
}
}
...
}
}
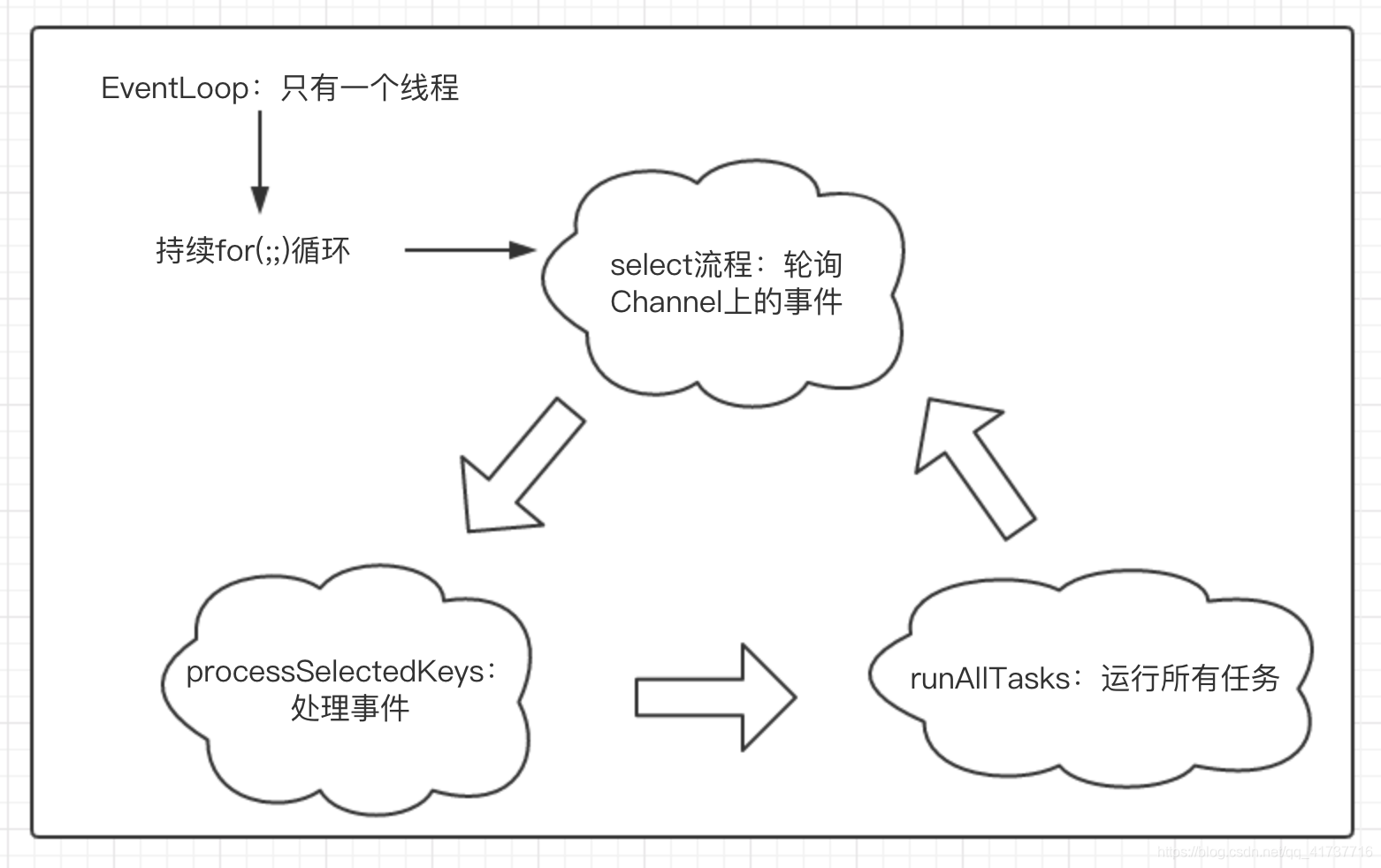
这里即为整个发动机的流程,可以看成是一个循环,做了三件事:
- select:阻塞在select方法限定一个时间,看看是否有channel产生了事件
- processSelectedKeys:处理轮询到的channel事件
- runAllTasks:执行阻塞队列中的任务
下面就这三件事做一个介绍
select流程:轮询Channel上的事件
首先,根据默认的策略,查看阻塞队列中是否有任务,若有任务,则非阻塞的select一下就返回
protected boolean hasTasks() {
return !taskQueue.isEmpty() || !tailTasks.isEmpty();
}
public int calculateStrategy(IntSupplier selectSupplier, boolean hasTasks) throws Exception {
return hasTasks ? selectSupplier.get() : SelectStrategy.SELECT;
}
private final IntSupplier selectNowSupplier = new IntSupplier() {
@Override
public int get() throws Exception {
return selectNow();
}
};
以上代码说明了我刚刚的那句话,这里不作赘述,下面就进入了switch分支,因为这一节着重介绍select方法,所以这里假设阻塞队列中没有任务,进入SelectStrategy.SELECT分支
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false));
这里将wakenUp的状态位置为false,并将旧的wakenUp状态作为方法参数传入select方法
private void select(boolean oldWakenUp) throws IOException {
// JDK的selector
Selector selector = this.selector;
try {
int selectCnt = 0;
long currentTimeNanos = System.nanoTime();
// 查看scheduledTaskQueue定时执行队列是否有到期的任务
// 若有,delayNanos方法返回0,若没有,越久的定时返回值越大
long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos);
for (;;) {
// delayNanos为定时任务还有多久到期
// 这里的意思就是,若delayNanos超过500000,则就不会进入下面的那个if分支
// 而1000000000Nanos为1s,读者可以认为这里意思就是判断是否有到期的任务即可
long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L;
// 若进入这里,表示有到期的定时任务需要执行
if (timeoutMillis <= 0) {
// selectCnt表示select次数
// 这里表示至少需要select一次
if (selectCnt == 0) {
// 非阻塞的查看是否有channel事件
selector.selectNow();
selectCnt = 1;
}
// 退出循环,结束select流程
break;
}
// 如果阻塞队列有任务,则尝试将wakenUp设为ture,若成功
// 则退出循环,结束select流程
if (hasTasks() && wakenUp.compareAndSet(false, true)) {
selector.selectNow();
selectCnt = 1;
break;
}
// 这里阻塞一定时间轮询channel是否有事件,这个时间取决于定时任务的到期时间
// 到期时间越快,阻塞的时间越短
int selectedKeys = selector.select(timeoutMillis);
// select一次就自增值
selectCnt ++;
// selectedKeys != 0 表示有事件产生了
// oldWakenUp 表示之前有线程设置了wakenUp标志位为true
// wakenUp.get() 表示现在就有线程设置了wakenUp标志位为true
// hasTasks() 表示有任务在阻塞队列
// hasScheduledTasks() 表示有定时任务到期了,需要被执行
// 以上满足一项即退出循环,结束select流程
if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) {
break;
}
if (Thread.interrupted()) {
// 线程被中断,也会退出循环,结束select流程
selectCnt = 1;
break;
}
long time = System.nanoTime();
// currentTimeNanos 表示开始select循环的时间
// time 表示现在的时间
// 这里表达式可以转换来看 time - currentTimeNanos >= timeoutMillis
// 表示上次select到现在过的时间,是否确实阻塞了timeoutMillis这段时间
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
// timeoutMillis elapsed without anything selected.
// 这里表示select确实阻塞了一段时间,而不是空轮询立即返回
// 这里是为了解决NIO的selector空轮询BUG,下面会介绍到
selectCnt = 1;
}
// SELECTOR_AUTO_REBUILD_THRESHOLD 默认为512
// 也就是说,selectCnt若大于512,视为发了了空轮询BUG
else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
// The code exists in an extra method to ensure the method is not too big to inline as this
// branch is not very likely to get hit very frequently.
// 重新创建一个selector,规避BUG
selector = selectRebuildSelector(selectCnt);
selectCnt = 1;
break;
}
currentTimeNanos = time;
}
...
}
}
这里总结一下,一共有以下情况会退出select流程:
- 在开头的switch判断中,若阻塞队列中有任务,则select一下马上返回,结束select流程
- 若有定时任务到期需要被执行,select一下马上返回,结束select流程
- 再判断一次阻塞队列中是否有任务,若有,CAS操作将wakenUp值设置为true,select一下马上返回,结束select流程
- 上述情况都没发生,则会select阻塞一段时间,然后返回之后检查是否有轮询到什么事件
- 若轮询到事件
- 若wakenUp被设置为true
- 若阻塞队列中有任务
- 若有定时任务到期需要被执行
- 以上情况均会退出select流程
- 线程被中断
- 发生了空轮询BUG,主要表现在过短的轮询时间超过了默认值512次,将重新开启一个新的selector,并退出select流程
可以看到,以上流程在很多时间点上都会检查是否阻塞队列或者定时任务队列是否有任务,若有就会先去执行对应的任务,或是wakenUp标志位也会中断select的流程。
selector空轮询BUG
JDK声称已经解决了selector的空轮询bug,但还是有部分人声称此bug依然存在,这里我也不做论断,只是介绍一下Netty是如何解决了selector空轮询BUG
什么是空轮询bug?在调用jdk的selector.selector()方法时有几率会产生空轮询,并CPU飙升100%。
其实Netty并没有解决此BUG,Netty只是用了一个方法去探测是否出现了此BUG,若探测到BUG出现,则开启一个新的selector,从而规避了此BUG,也算一个解决之道吧。
那么如果探测出现了此BUG呢?在上面的代码注释也可以看到,Netty记录了一个变量,用来表示一个select流程做了几次select调用,每调用一次增加1。由于select会阻塞一段时间,若确实阻塞了这么多时间,以上记录的变量会归一。若重复执行了select方法512次(默认值,可配置),且实际上都没有阻塞规定的时间,则判断出现了空轮询BUG,则会调用selectRebuildSelector方法重新构造一个selector
private Selector selectRebuildSelector(int selectCnt) throws IOException {
// 重新构造一个selector
rebuildSelector();
// 拿到新的selector
Selector selector = this.selector;
// Select again to populate selectedKeys.
// 至少select一次,看看期间是否有事件了
selector.selectNow();
return selector;
}
这里看看rebuildSelector做了什么
public void rebuildSelector() {
...
rebuildSelector0();
}
private void rebuildSelector0() {
// 拿到旧的selector
final Selector oldSelector = selector;
final SelectorTuple newSelectorTuple;
try {
// 开启一个新的selector
newSelectorTuple = openSelector();
}
...
// Register all channels to the new Selector.
// 这里就是将所有channel注册到新的selector上
int nChannels = 0;
// 遍历旧selector上的SelectionKey
for (SelectionKey key: oldSelector.keys()) {
// attachment就是channel
Object a = key.attachment();
try {
// 原先感兴趣的事件
int interestOps = key.interestOps();
// 旧的key取消掉
key.cancel();
// 将原先到事件注册到新的selector上
SelectionKey newKey = key.channel().register(newSelectorTuple.unwrappedSelector, interestOps, a);
if (a instanceof AbstractNioChannel) {
// Update SelectionKey
// 重新赋值channel上的selectionKey为新的key
((AbstractNioChannel) a).selectionKey = newKey;
}
nChannels ++;
}
...
}
selector = newSelectorTuple.selector;
unwrappedSelector = newSelectorTuple.unwrappedSelector;
try {
// time to close the old selector as everything else is registered to the new one
// 将旧的selector关闭
oldSelector.close();
}
...
}
这里主要就是开启了一个新的selector,并将旧的selector上的注册的事件都转移到新的selector上去,并且更新所有channel上的SelectionKey变量。通过规避BUG,绕道走的方式,就解决了空轮询的BUG
processSelectedKeys:处理事件
当结束了上面的selector流程,这里就来到了第二个工作,处理事件
private void processSelectedKeys() {
if (selectedKeys != null) {
// 走优化的处理
processSelectedKeysOptimized();
} else {
// 走没有优化的处理
processSelectedKeysPlain(selector.selectedKeys());
}
}
这里Netty优化了一下JDK的Selector实现类中的一个数据结构。首先看上面的代码,当selectedKeys变量不为空时,表示现在是优化的方案,那么这个变量是什么时候被赋值的呢?在NioEventLoop的构造函数中,调用了openSelector这个方法,这个方法是我们没有分析的,现在来看一下
private SelectorTuple openSelector() {
final Selector unwrappedSelector;
try {
// 开启一个selector,这个selector没有被优化过
unwrappedSelector = provider.openSelector();
}
...
// 若配置了不做优化,则直接返回原生selector即可
// 默认为false,进行优化
if (DISABLE_KEY_SET_OPTIMIZATION) {
return new SelectorTuple(unwrappedSelector);
}
// 这里尝试加载sun.nio.ch.SelectorImpl这个类
// 这个类即为包装对象,selector的实现类
Object maybeSelectorImplClass = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
try {
return Class.forName(
"sun.nio.ch.SelectorImpl",
false,
PlatformDependent.getSystemClassLoader());
} catch (Throwable cause) {
return cause;
}
}
});
// 如果加载的类不是上面开启的selector的子类,则不进行优化
if (!(maybeSelectorImplClass instanceof Class) ||
// ensure the current selector implementation is what we can instrument.
!((Class<?>) maybeSelectorImplClass).isAssignableFrom(unwrappedSelector.getClass())) {
...
return new SelectorTuple(unwrappedSelector);
}
// 准备包装的类对象
final Class<?> selectorImplClass = (Class<?>) maybeSelectorImplClass;
// Netty优化过的一个数据结构,看成一个数组即可
final SelectedSelectionKeySet selectedKeySet = new SelectedSelectionKeySet();
Object maybeException = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
try {
// 拿到selectedKeys和publicSelectedKeys这两个Field域对象
Field selectedKeysField = selectorImplClass.getDeclaredField("selectedKeys");
Field publicSelectedKeysField = selectorImplClass.getDeclaredField("publicSelectedKeys");
...
// 将上述两个域利用反射,都设置Netty优化过的数据结构进去
selectedKeysField.set(unwrappedSelector, selectedKeySet);
publicSelectedKeysField.set(unwrappedSelector, selectedKeySet);
return null;
}
...
}
});
...
}
// 将此数据结构赋值到成员变量中,证明此时可以使用优化方案
selectedKeys = selectedKeySet;
return new SelectorTuple(unwrappedSelector,
new SelectedSelectionKeySetSelector(unwrappedSelector, selectedKeySet));
}
其实就是将一个数据结构容器类设置到SelectorImpl的两个成员变量而已,那么Netty为何要这样做呢?我们先看看被替换的两个成员变量是什么
public abstract class SelectorImpl extends AbstractSelector {
protected Set<SelectionKey> selectedKeys = new HashSet();
private Set<SelectionKey> publicSelectedKeys;
...
}
这里可以看出,是两个Set,那么优化过的数据结构又是怎样的呢?
final class SelectedSelectionKeySet extends AbstractSet<SelectionKey> {
SelectionKey[] keys;
int size;
...
@Override
public boolean add(SelectionKey o) {
if (o == null) {
return false;
}
keys[size++] = o;
if (size == keys.length) {
// 扩容
increaseCapacity();
}
return true;
}
}
这里可以看出,优化过的数据结构是一个数组而已,在这之前,我一直很好奇一件事,就是这个类为什么继承了Set,又没有Set该有的方法?看到这里我就明白了,原来这个类存在的意义是为了替换JDK底层的Set实现,转为数组实现,Netty认为在这里不需要用到Set(在后面的操作中可以看出来),只需要一个数组操作即可,数组的操作一定是比Set快的,其添加元素只需要在数组下标中插入元素即可,并且自带扩容数组的实现。
我们回到processSelectedKeys方法中去,这里我们就来看看优化之后的处理事件方法
private void processSelectedKeysOptimized() {
// selectedKeys为数组
for (int i = 0; i < selectedKeys.size; ++i) {
// 直接使用下标访问元素
final SelectionKey k = selectedKeys.keys[i];
// null out entry in the array to allow to have it GC'ed once the Channel close
// See https://github.com/netty/netty/issues/2363
// 置为空,方便GC
selectedKeys.keys[i] = null;
// 这里一般为channel
final Object a = k.attachment();
if (a instanceof AbstractNioChannel) {
// 处理事件
processSelectedKey(k, (AbstractNioChannel) a);
} else {
@SuppressWarnings("unchecked")
NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a;
processSelectedKey(k, task);
}
...
}
}
这里优化过后,只需要下标一次就可以取出数组中的元素,肯定是比Set的数据结构快的。这里关注processSelectedKey方法,具体处理事件
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
// unsafe是操作底层channel的类
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
...
try {
// 事件,位表示
int readyOps = k.readyOps();
...
// Process OP_WRITE first as we may be able to write some queued buffers and so free memory.
// 表示有OP_WRITE事件,需要将channel中的缓存数据写出到客户端
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
// Call forceFlush which will also take care of clear the OP_WRITE once there is nothing left to write
// 写出数据
ch.unsafe().forceFlush();
}
// Also check for readOps of 0 to workaround possible JDK bug which may otherwise lead
// to a spin loop
// 表示有OP_READ 或 OP_ACCEPT事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
// 服务端、客户端channel的read方法做的事情是不同的
unsafe.read();
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
这里最为关键的就是OP_READ或OP_ACCEPT的产生,若有这两个事件中的一种,则处理,但客户端和服务端的Channel处理事件的方式是不一样的
服务端Channel处理事件
服务端Channel的unsafe实现的父类是NioMessageUnsafe,所以进入此类的read方法
public void read() {
...
try {
try {
do {
// 接受新连接
int localRead = doReadMessages(readBuf);
if (localRead == 0) {
break;
}
if (localRead < 0) {
closed = true;
break;
}
allocHandle.incMessagesRead(localRead);
// 这里的意思就是,只要doReadMessages方法返回的值不是0
// 就一直循环到一定的次数
} while (allocHandle.continueReading());
} catch (Throwable t) {
exception = t;
}
int size = readBuf.size();
for (int i = 0; i < size; i ++) {
readPending = false;
// 将List中的元素一个个传播read事件,
pipeline.fireChannelRead(readBuf.get(i));
}
// 清空List
readBuf.clear();
allocHandle.readComplete();
// 传播readComplete事件
pipeline.fireChannelReadComplete();
}
}
}
这里关键是执行doReadMessages这个方法
protected int doReadMessages(List<Object> buf) throws Exception {
// 使用JDK的channel类accept一个新连接
SocketChannel ch = SocketUtils.accept(javaChannel());
try {
if (ch != null) {
// 将新连接封装为Netty的channel类,也是装饰
// 并将其保存在List中,以便后续一个个将其传播给pipeline
buf.add(new NioSocketChannel(this, ch));
// 返回1,证明有接受到一个新连接
return 1;
}
}
...
// 证明没有接受到新连接
return 0;
}
这里就是熟悉的accept了,由此我们可以看出,对于服务端Channel关注的事件,所作出的行为只是在accept接受新连接,并将其传播下去,并不负责读数据。这里我们关注一下,在接受到新连接之后,将新连接包装成Netty的Channel实现类之后,将其传播给pipeline时做了什么事情
pipeline.fireChannelRead(readBuf.get(i));
我们回忆一下上一篇,关于服务端Channel的初始化,其在pipeline中添加了一个关键的Handler叫做ServerBootstrapAcceptor,在fireChannelRead传播事件的过程中,最终会调用到ServerBootstrapAcceptor的channelRead方法,回忆一下,在服务端启动时,初始化服务端channel的时候将childHandler和childGroup等等配置对象都保存到了ServerBootstrapAcceptor中,在其fireChannelRead方法中用到了这些配置
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 这里的channel就是刚刚accept的新连接的包装的Netty Channel
final Channel child = (Channel) msg;
// 为子Channel的pipeline加入子Handler
child.pipeline().addLast(childHandler);
...
try {
// 调用子线程组,调用注册方法,注册子channel
childGroup.register(child)...
}
...
}
这里调用了子线程组的注册方法
public ChannelFuture register(Channel channel) {
return next().register(channel);
}
可以看到,和父线程组一样,从线程组中选择一个发动机线程去注册channel
这里就不往下看了,其逻辑和上一篇我们分析的一样,简要的用语言概括一下:
- 首先将选择出来的发动机线程唯一绑定一个channel(一个channel对应一个EventLoop)
- 将channel注册到selector上,此时关心的事件位还是0
- 向pipeline传播register事件
- 调用beginRead方法,将channel事件修改为自己关心的事件,这里客户端channel将注册OP_READ事件到selector上
一个新连接到服务端之后会发生什么事?
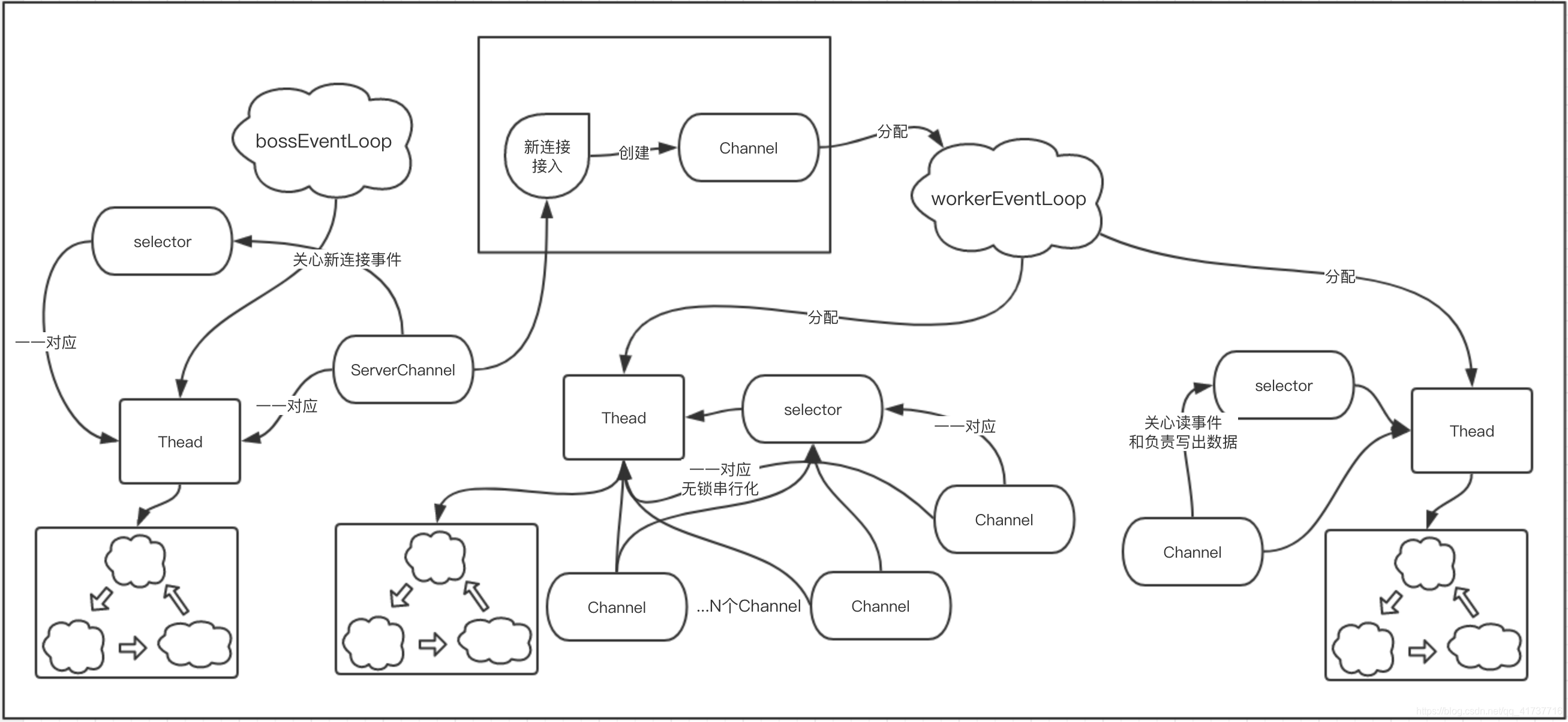
到这里就已经解答了这个问题,Netty服务端中有一个服务端Channel在持续关注新连接事件,当有新连接事件,调用底层的channel.accept方法接收一个新连接,并把它分配给一个子线程组,让它对应一个线程,然后此channel就会去selector上注册OP_READ事件,表示自己关心读事件,这样,客户端的读事件到来之后就可以处理了。
分析到这里,读者应该要有一个画面,就是reactor的主从线程模型,一个主reactor相当于一个服务端Channel,负责接受连接,别的啥都不管,接受到连接之后交给从reactor去处理,该Channel只关心读事件,所以这里可以看出,主reactor负责接受连接,从reactor负责读事件,写数据出去
客户端Channel处理事件
这里客户端Channel处理事件的方式就是从ByteBuf中读取数据,其是一个数据结构,在channel读数据时,并不是从TCP连接中直接读取数据,这样会阻塞等待数据,在Nio中,数据是会读到一个缓冲区的,全部读完才会有读事件产生,所以这里channel读取事件是不会阻塞的,直接读取返回。
runAllTasks:运行所有任务
到这里,就来到最后一个环节,在前面一直说的执行阻塞队列的任务或定时任务,首先解答一个疑问,为什么这里会有任务要执行呢?要执行什么任务呢?
首先,NioEventLoop其实也是一个定时线程池的实现
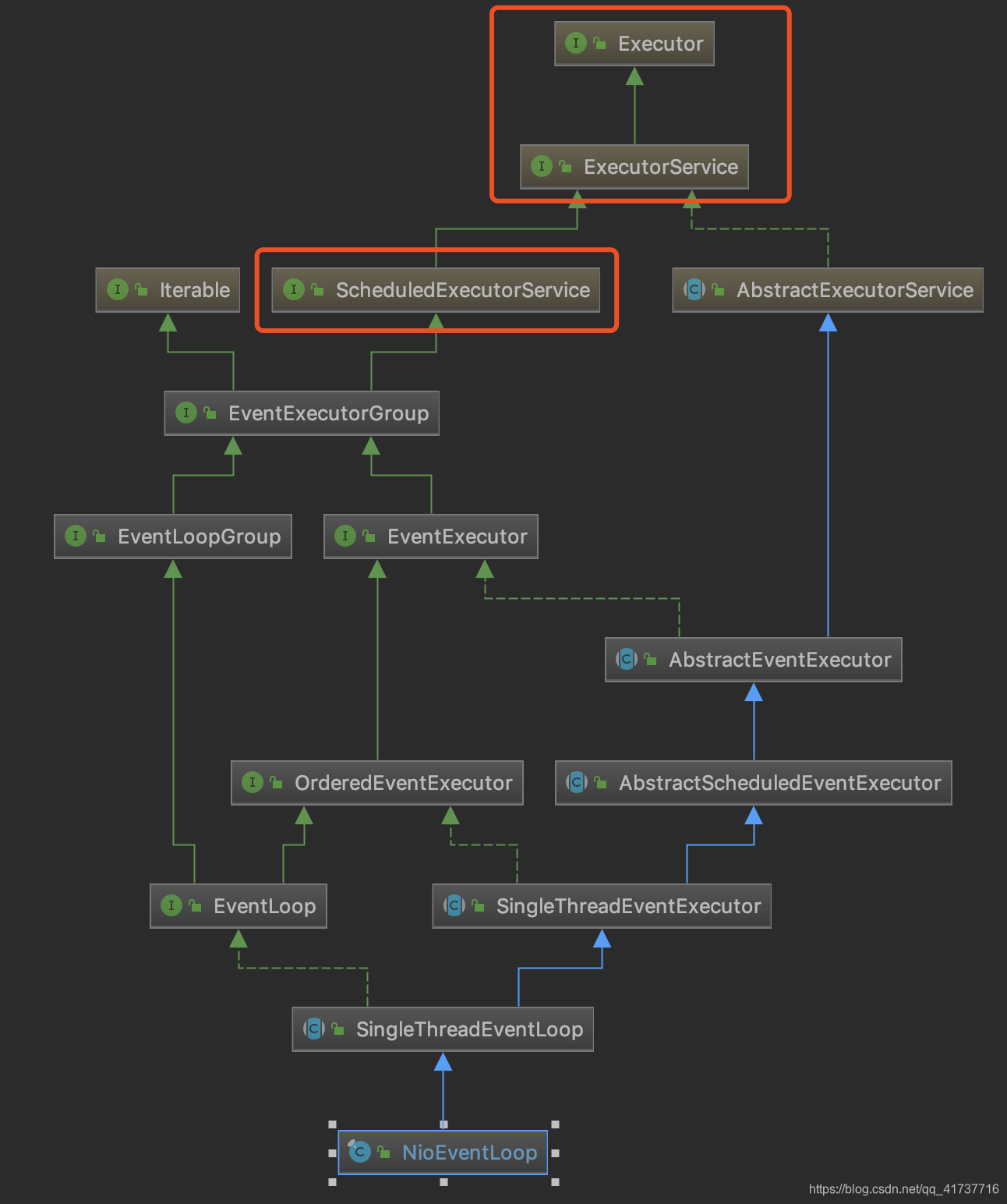
其实现的这些接口,都可以看出它其实也具有一个定时执行任务的功能,当我们想要定时执行某个任务,即可调用API,像使用ScheduledExecutorService定时任务线程池那样使用它,任务就会在这个流程中被执行,其功能与ScheduledExecutorService无异。定时任务都将会存放到scheduledTaskQueue这个成员变量中
// 其为优先队列,在第一个的是最快要过期的定时任务
PriorityQueue<ScheduledFutureTask<?>> scheduledTaskQueue;
那么还有其他两个阻塞队列的任务是从哪里来呢?回忆一下我们在无锁串行化的介绍中,若对channel的操作的线程并不是其绑定的那个发动机线程,那么会交给发动机线程去execute方法封装成一个任务去执行。在哪里可以找到这些代码呢?直接搜索inEventLoop方法在哪里被用到,随便拿一个即可
if (executor.inEventLoop()) {
next.invokeChannelWritabilityChanged();
} else {
Tasks tasks = next.invokeTasks;
if (tasks == null) {
next.invokeTasks = tasks = new Tasks(next);
}
executor.execute(tasks.invokeChannelWritableStateChangedTask);
}
这里主要看第二个分支,若不是发动机线程,封装成一个Tasks,然后调用其execute执行任务
public void execute(Runnable task) {
...
addTask(task);
...
}
这里略过无关的代码,直接看addTask做了什么
protected void addTask(Runnable task) {
// 向阻塞队列添加一个任务
if (!offerTask(task)) {
reject(task);
}
}
final boolean offerTask(Runnable task) {
if (isShutdown()) {
reject();
}
return taskQueue.offer(task);
}
其实这里做的只是向阻塞队列添加一个元素而已。至于另一个tailTasks阻塞队列,一般不会有任务被添加到那边,一般此队列做一些收尾的动作
这里回到runAllTasks的逻辑中去
protected boolean runAllTasks() {
assert inEventLoop();
boolean fetchedAll;
boolean ranAtLeastOne = false;
do {
// 去拿定时线程池中的任务
fetchedAll = fetchFromScheduledTaskQueue();
// 执行taskQueue中的任务
if (runAllTasksFrom(taskQueue)) {
ranAtLeastOne = true;
}
// 直到我们拿到所有要执行的定时任务
} while (!fetchedAll); // keep on processing until we fetched all scheduled tasks.
if (ranAtLeastOne) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
}
// 执行tailTasks队列中的所有任务
afterRunningAllTasks();
return ranAtLeastOne;
}
这里主要有两个分支,一个是fetchFromScheduledTaskQueue拿到定时的任务,一个是runAllTasksFrom开始执行任务
拿到定时任务
这里进入fetchFromScheduledTaskQueue方法
private boolean fetchFromScheduledTaskQueue() {
long nanoTime = AbstractScheduledEventExecutor.nanoTime();
// 拿出线程池中,定时任务到期的任务
Runnable scheduledTask = pollScheduledTask(nanoTime);
// 若没有需要执行的定时任务,这里为null,直接返回
while (scheduledTask != null) {
// 到这里,说明有定时任务需要被执行,将其放入taskQueue队列中
if (!taskQueue.offer(scheduledTask)) {
// No space left in the task queue add it back to the scheduledTaskQueue so we pick it up again.
// 若到这里,说明队列满了,这里我们将任务放回去,等等再拿出来加入队列
scheduledTaskQueue().add((ScheduledFutureTask<?>) scheduledTask);
return false;
}
// 就这么一直while循环,拿出定时任务直到没有定时任务为止
scheduledTask = pollScheduledTask(nanoTime);
}
return true;
}
这里主要做的就是拿出所有需要被执行的定时任务,并放入taskQueue这个队列中,直到没有定时任务为止
执行任务
这里就进入了runAllTasksFrom(taskQueue)方法,执行所有taskQueue队列中的任务,从上面我们可以知道,在这个队列中,现在不止是需要同步执行的任务,还存在一些需要被执行的定时任务
protected final boolean runAllTasksFrom(Queue<Runnable> taskQueue) {
// 从队列中取出一个Runnable任务
Runnable task = pollTaskFrom(taskQueue);
if (task == null) {
return false;
}
// 一直循环
for (;;) {
// 这里就是执行了task.run方法执行
safeExecute(task);
// 继续从队列中取任务
task = pollTaskFrom(taskQueue);
// 直到没有任务,才退出流程
if (task == null) {
return true;
}
}
}
这里的逻辑就是一直执行队列中的所有任务,直到没有任务,才会退出这个流程
一般来说,执行任务是会有限定时间的,也就是我们之前说的IO的比例时间,一般只会允许执行IO一半的时间来执行队列中的任务
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
在限定时间的方法版本中有如下逻辑
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
// 限定一个deadline,即为timeoutNanos这个指定时间
// 这里ScheduledFutureTask.nanoTime()可以看作为当前时间
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
safeExecute(task);
runTasks ++;
// Check timeout every 64 tasks because nanoTime() is relatively expensive.
// XXX: Hard-coded value - will make it configurable if it is really a problem.
// 每次在执行一次任务之后都会检查一次时间
if ((runTasks & 0x3F) == 0) {
// 这里可以看作又取了一次当前时间
lastExecutionTime = ScheduledFutureTask.nanoTime();
// 判断当前是否超过了deadline的时间,也就是上面所说的IO的一半时间
if (lastExecutionTime >= deadline) {
// 若超过,退出流程
break;
}
}
// 继续拿出任务来执行
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
...
}
可以看到,在默认情况下是会限定一个时间来执行任务的,这个时间默认为processSelectedKeys方法执行的时间的50%
Reactor线程模型
到这里,Netty发动机做的事情大概都已经介绍完了,这里简单画一张图来表示这些发动机都在做什么
而一般我们是使用了主从的Reactor线程模型,所以我们可以将整体的Netty服务端看成是在做下面这幅图的操作
希望读者看到这里,可以理解到Netty的大致脉络了。

















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









