






第三步解析数据
完了呢,一个一个分析我们的products就行了
这里需要注意,我们爬下来productes数据是一个
- 标签,一个空白循环的
所以for循环间隔2(如果对数据比较严格的话建议用selenium 模拟浏览器爬会比较慢,因为部分商品是异步加载的)
让后呢,在 - 里定位自己想要的就行了

因为我们已经得到这个 - 标签里的所有东西了,比如我要获取价格
直接products[i].find(‘div’,{‘class’,‘p-price’}).text

第四步写到csv里呗
主要csv只认可gbk的编码格式,不定义也可以,我没有报错
还有就是按照list的格式写,我第一次不是,结果一个字一个逗号

中间是咱们爬虫的代码哦
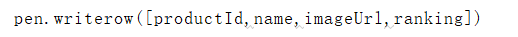
终于写完了,爬取评论的下次写吧!(三)见
源码还在审核,完了搜索shangping.py吧!要一个积分哦,你自己敲更好。学的扎实,额!那评论的源码免费好了,至少小赚一点















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









