




什么是OpenCL?
1.概述
- OpenCL(Open Computing Language 开放计算语言)是一种开放的、免版税的标准,用于超级计算机、云服务器、个人计算机、移动设备和嵌入式平台中各种加速器的跨平台并行编程。OpenCL是由Khronos Group创建和管理的。OpenCL使应用程序能够使用系统或设备中的并行处理能力,从而使应用程序运行得更快、更流畅。
2.OpenCL是如何工作的?
- OpenCL是一种编程框架和运行时,它使程序员能够创建称为内核程序(或内核)的小程序,这些程序可以在系统中的任何处理器上并行编译和执行。处理器可以是不同类型的任意组合,包括cpu、gpu、dsp、fpga或张量处理器——这就是为什么OpenCL经常被称为异构并行编程的解决方案。
- OpenCL框架包含两个api。platform layer API在主机CPU上运行,首先用于使程序能够发现系统中可用的并行处理器或计算设备。通过查询哪些计算设备可用,应用程序可以在不同的系统上便携地运行—适应加速器硬件的不同组合。一旦发现了计算设备,platform layer API就允许应用程序选择并初始化它想要使用的设备。
- 第二个API是Runtime API,它使应用程序的内核程序能够为它们将要运行的计算设备编译,并行加载到这些处理器上并执行。一旦内核程序完成执行,将使用Runtime API收集结果。
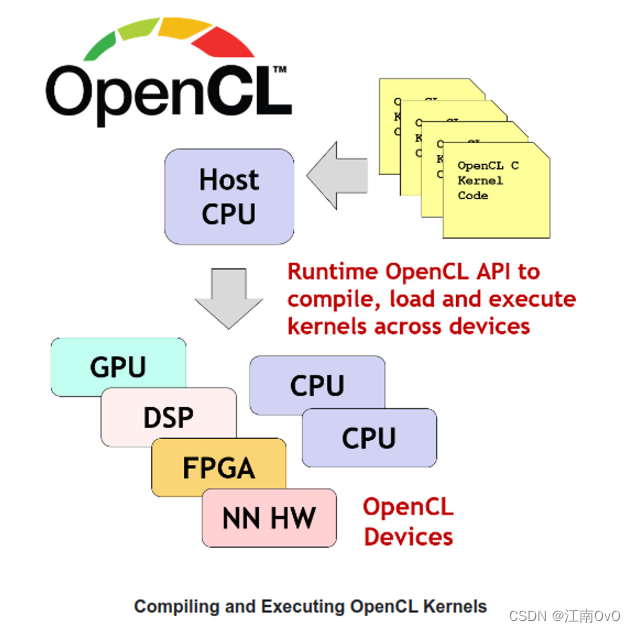
- 为了更好使用与不同的处理器,OpenCL抽象出来了四大模型:
- 平台模型:描述了OpenCL如何理解拓扑连接系统中的计算资源,对不同硬件及软件实现抽象,方便应用于不同设备
- 存储模型:对硬件的各种存储器进行了抽象
- 执行模型:程序是如何在硬件上执行的
- 编程模型:数据并行和任务并行
3.平台模型
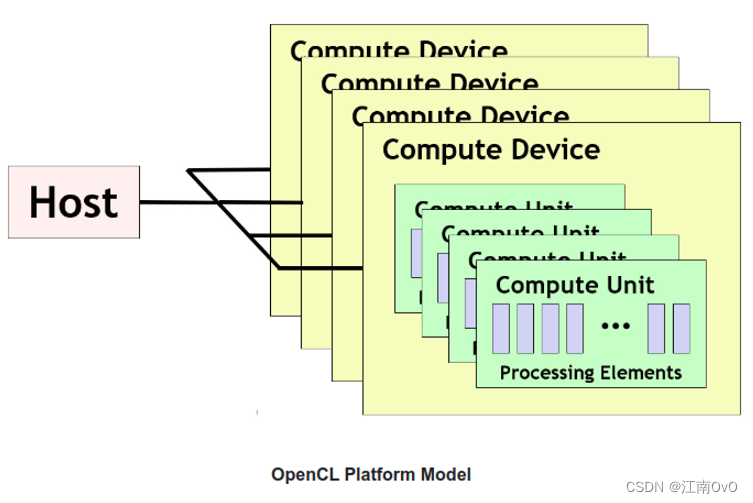
- OpenCL中,需要一个主机处理器(Host),一般为CPU。而其他的硬件处理器(多核CPU/GPU/DSP等)被抽象成Compute Device。每个Compute Device 包含多个 Compute Unit,每个Compute Unit 又包含多个Processing Elements(处理单元)
- 举例说明:计算设备可以是GPU,计算单元对应于GPU内部的流多处理器(streaming multiprocessors(SMs)),处理单元对应于每个SM内部的单个流处理器。处理器通常通过共享指令调度和内存资源,以及增加本地处理器间通信,将处理单元分组为计算单元,以提高实现效率。
4.存储模型
-
OpenCL中定义了不同类型的存储区域
-
Host memory:主机CPU可用,可以通过直接传输/共享内存的方式与设备端进行数据传输;
-
Global/Constant memory:对计算设备上的所有计算单元可用
-
Local memory:对计算单元中所有处理单元可用的
-
Private memory:对单个处理单元可用,在硬件实现上通常映射为寄存器

-
在 OpenCL 中,全局存储器中的数据内容通过存储对象来表示(Memory Object),在 OpenCL 中较为常用的两个存储对象为:Buffer Objects 和 Image Objects

5.执行模型
- 主机应用程序使用OpenCL命令队列将内核和数据传输函数发送到设备以执行。通过将命令入队到命令队列中,内核和数据传输函数可以与应用程序主机代码并行异步执行。
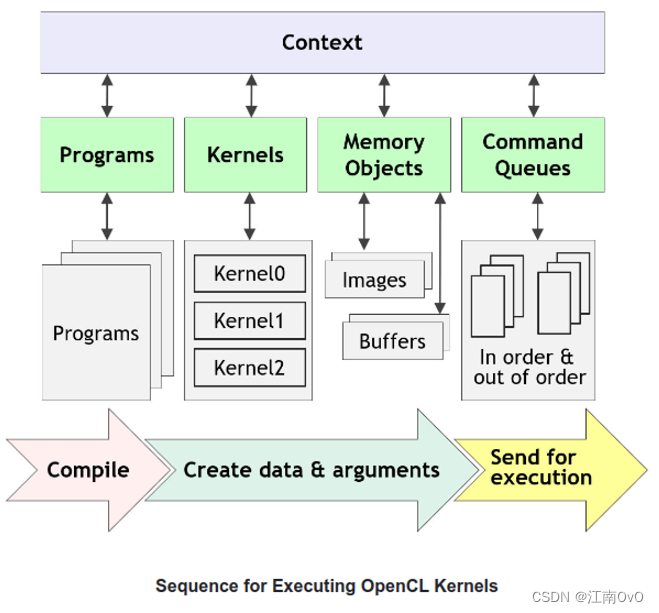
重要概念:
- Context:每个Context支持多个Device,Host端通过Context与Device端进行交互和管理
- Commend Queue:Host端发送命令到队列中让Device端去执行(顺序乱序执行都行),一个命令队列只能管理一个设备。
- Kernel Objects:OpenCL核心计算部分,类似C语言的代码。在需要设备执行计算任务时,数据会被推送到Device端,然后Device端的计算单元会并发执行内核程序
- Program Objects:Kernel Object的集合,OpenCL中可以使用cl_program表示
执行流程:
- 查询可用的OpenCL平台和设备
- 在平台上为OpenCL设备创建一个context
- 在context上为OpenCL设备创建并编译程序
- 选择kernel去执行程序
- 为内核创建为其操作的内存对象
- 在一个OpenCL Device上创建一个命令队列去执行命令
- 如果需要,将数据传输命令排队到内存对象中
- 将内核排队到命令队列中去执行
- 如果需要,将命令入队,以便将数据传输回主机
高效并行计算:
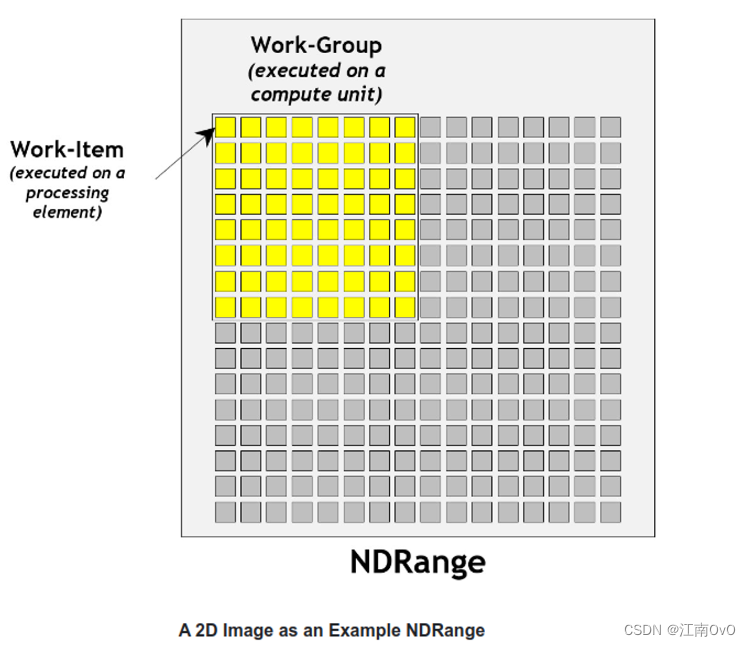
- 为了提高执行效率,处理器通常会将处理元素分组为计算单元。因此,当使用clEnqueueNDRangeKernel命令时,程序指定了一个工作组大小,该工作组大小表示可以在计算单元上容纳的nrange中的单个工作项组。相同工作组中的工作项能够共享本地内存,使用工作组屏障更容易地同步,并使用工作组函数(如async_work_group_copy)更有效地合作,这些在单独工作组中的工作项之间是不可用的。
6.编程模型
OpenCL 定义了两种不同的编程模型:任务并行和数据并行。
- 数据并行:划分计算数据,分配给不同的计算单元进行同时计算,适用于数据相互独立的计算任务。
- 任务并行:计算步骤的每一个步骤有前后依赖,这使得我们无法将计算任务并行执行。于是,我们只能对每一个步骤的数据进行并行,之后将整个流程进行异步/同步串行执行,为了协调整个流程的先后关系,OpenCL 提供了Event 机制用来进行流程同步控制。


















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











