






自我介绍!!!!
说一下你对分布式理解是什么样的?
springcloud里面的几个组件?
Eureka:服务注册中心
Ribbon:客户端负载均衡
Hystrix:熔断器
Fegin:声明式的Http客户端
Zuul:服务网关
权限是怎么设计的? 用户-->角色-->权限(菜单按钮等资源)
项目用的权限框架是什么?spring security认证和授权流程;认证验证账号密码,授权:登录token
jwt和token区别?
jwt(JSON Web Token)无状态,安全性,可避免CSRF攻击
分布式事务是怎么处理的?MQ事务消息 seata分布式事务
tcc (seata)二阶段提交 有没有基于tcc的一些其他解决方案 比如说最大努力通知(基于消息队列来说)?
rocket mq用过吗,网络波动?
更新数据库 redis缓存数据怎么去更新(双写一致性)?
redis除了做缓存你们还做其他东西吗?
redis有没有用它做分布式锁?
zookeeper是怎么去实现分布式锁?
redis缓存和我们框架项目去做缓存,有什么其他区别(比如用map做缓存)?
数据库优化?
有没有用过相关命令去查看sql执行?
分表!分好以后怎么去确认数据在那张表?
分表策略?
分表以后查询一个范围但跨表了?怎么办?
union和unionall区别?
索引有去了解他的底层吗
B+tree能做到什么优化? 它和二叉树有什么不同?
myisam和Innodb区别引擎?
有没有遇到锁表的情况?
目录
7.k8s
k8s详细教程/Kubernetes详细教程.md · java668/LearningNotes - Gitee.com
1.Java基础
1.1 线程池
线程池创建:

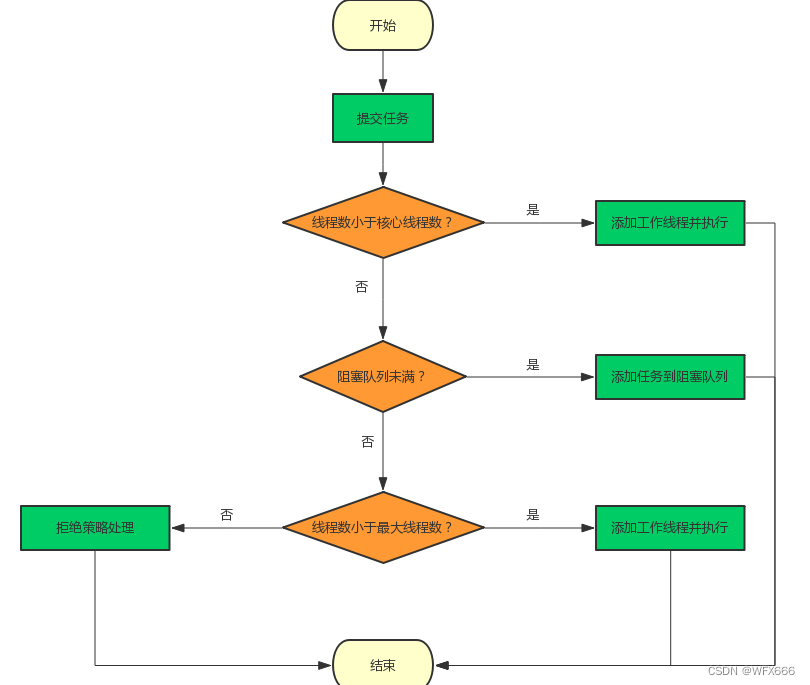
1. 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
2. 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要
创建非核心线程立刻运行这个任务;
d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池
会抛出异常 RejectExecutionException。
3. 当一个线程完成任务时,它会从队列中取下一个任务来执行。
4. 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它
最终会收缩到 corePoolSize 的大小。
@1.具体执行过程
@2.线程池参数两个都相等的时候会怎样
1.Executors.newFixedThreadPool(10);创建10个线程的线程池
2.ExecutorService executorService2 = Executors.newCachedThreadPool();创建缓存的线程池,这种方式可以控制内存不会被占满
3.创建拥有定时任务的固定线程个数的线程池,可以定时执行ScheduledExecutorService scheduledExecutorService =Executors.newScheduledThreadPool(10);
4.创建单线程ExecutorService executorService = Executors.newSingleThreadExecutor();
参数1:corePoolSize:线程池的基本大小
参数2. maximumPoolSize:线程池中允许的最大线程数
参数3:poolSize:线程池中当前线程的数量,当该值为0的时候,意味着没有任何线程,线程池会终止;同一时刻,poolSize不会超过maximumPoolSize
拒绝策列:第31个任务被拒绝

提交优先级
执行优先级


@3.sleep,wait 方法区别
--sleep()方法是Thread类里面的,
主要的意义:就是让当前线程停止执行,让出cpu给其他的线程,但是不会释放对象锁资源以及监控的状态,当指定的时间到了之后又会自动恢复运行状态。
加参数:sleep()方法必须传入参数,参数就是休眠时间,时间到了就会自动醒来。
--wait()方法是Object类里面的,
主要的意义:就是让线程放弃当前的对象的锁,进入等待此对象的等待锁定池,只有针对此对象调动notify,notifyAll方法后本线程才能够进入对象锁定池准备获取对象锁进入运行状态
加参数:wait()方法可以传入参数也可以不传入参数,传入参数就是在参数结束的时间后开始等待,不穿如参数就是直接等待
--join 等待目标线程执行完成之后再继续执行
--yield 线程礼让。目标线程由运行状态转换为就绪状态,也就是让出执行权限,让其他线程得以优先执行,但其他线程能否优先执行是未知数
注意:wait()、notify()、notifyAll()必须放在synchronized block中,否则会抛出异常
1.2 Synchronized和Volatitl原理
Synchronized原理:代码反编译(字节码)monitorenter和monitorexit
Volatitl:同步关键字,字节码中是lock(线程与线程之间没法直接通信)
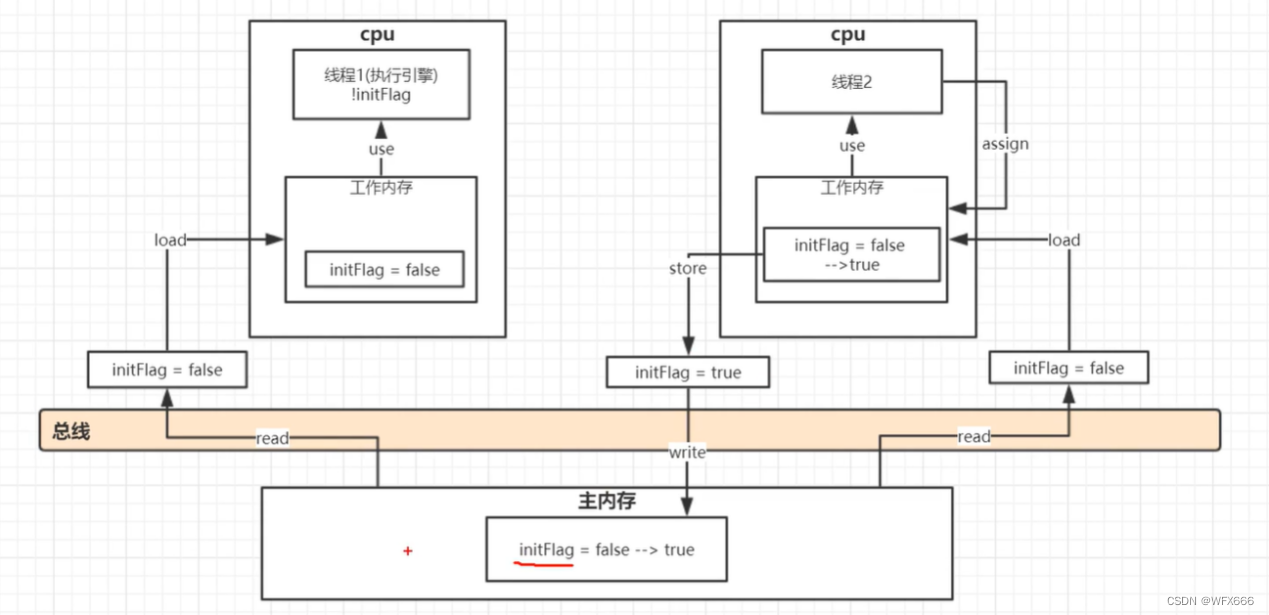
volatile关键字:简单理解:线程修改值后,马上将值存放到主内存,所有子线程都可见
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
底层原理:assign,load,read,store,write


1.3.jdk用到单例模式的有哪些?
@1.Runtime
第一种:懒汉式:
public static synchronized UserModel getInstance() {
if (userModel == null) {
userModel = new UserModel();
}
return userModel;
第二种:饿汉式
public static UserModel getInstance(){
return new userModel();
第三种:双重检索式:双重检索的方式,可以说是在性能和安全两个角度找了一个平衡点,可以理解为懒汉式单例模式的加强版,既考虑性能又考虑安全性的问题。
public static UserModel getInstance() {
if (userModel == null) {
synchronized (DoubleCheckSingletonPattern.class) {
if (userModel == null) {
userModel = new UserModel();
}
}
}
return userModel;
问题点:隐患补充:这里隐藏着一个问题,当两个线程进来后,先获取锁的线程开始创建线程的同时,第二个线程进入判断,因为构造对象的过程可能会比较长,
这时第一个线程还未完成对象的完整创建,但第二个线程会拿到一个不是null的值,从而认为已经构造完成,导致返回的类并非是一个完整的对象。解决方案可以通过volatile来解决这个问题,完美的解决了这个问题的还是推荐使用内部类的创建方式
第四种:注册登记式:Spring框架中IOC容器就采用的这种方式来管理我们系统中的Bean对象
private final static Map<String, Object> objectsMap = new ConcurrentHashMap<>();
public static synchronized Object getInstance() {
String key = "&userModel";
if (!objectsMap.containsKey(key)) {
objectsMap.put(key, new UserModel());
}
return objectsMap.get(key);
}
第五种:内部类形式:程序启动后并不会初始化内部类,而当外部类调用内部类的方法时,才会初始化内部类的UserModel实例,保证在不浪费资源的情况下达到的单例模式的应用
public class InnerClassSingletonPattern {
static {
System.out.println("父类加载了");
}
public static UserModel getInstance() {
return UserModelSingleton.userModel;
}
static class UserModelSingleton {
static final UserModel userModel = new UserModel();
static {
System.out.println("子类加载了");
}
1.4 jdk1.8hashmap集合底层原理
@1.hashMap底层原理:有序? Hash
.hashMap:
1.7:数组+链表
1.8:数组+链表+红黑树
ConcurrentHashMap实现线程安全的原理?ReentrantLock 是基于AQS实现的。分为公平锁和非公平锁。
初始容量:16 (2的指数次幂)
负载因子:0.75

1.5 类加载过程
类加载主要分为:加载,连接,初始化,使用,卸载5个阶段;
其中连接分为:验证,准备,解析;
1.6 为什么堆的常量和栈的常量要设置成一样
1.7 Jvm垃圾回收
JVM调优总结 -Xms -Xmx -Xmn -Xss - unixboy - ITeye博客
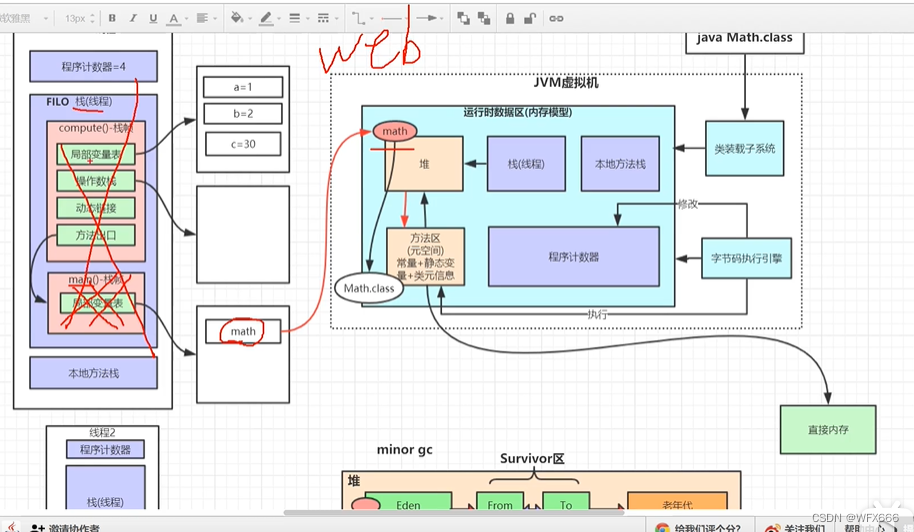
堆:
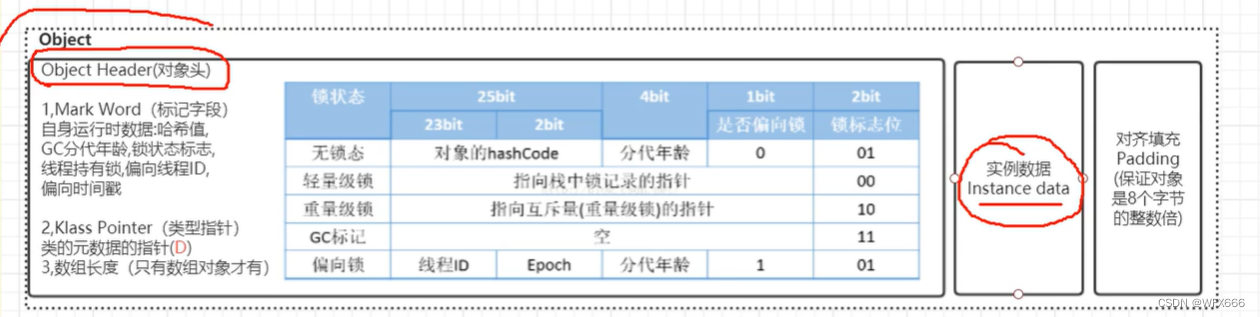
方法区:(1.8之前叫永久代)存放常量,静态变量,类元信息(对象头每个类唯一,比如同步锁,,,)
本地方法区:native方法。。
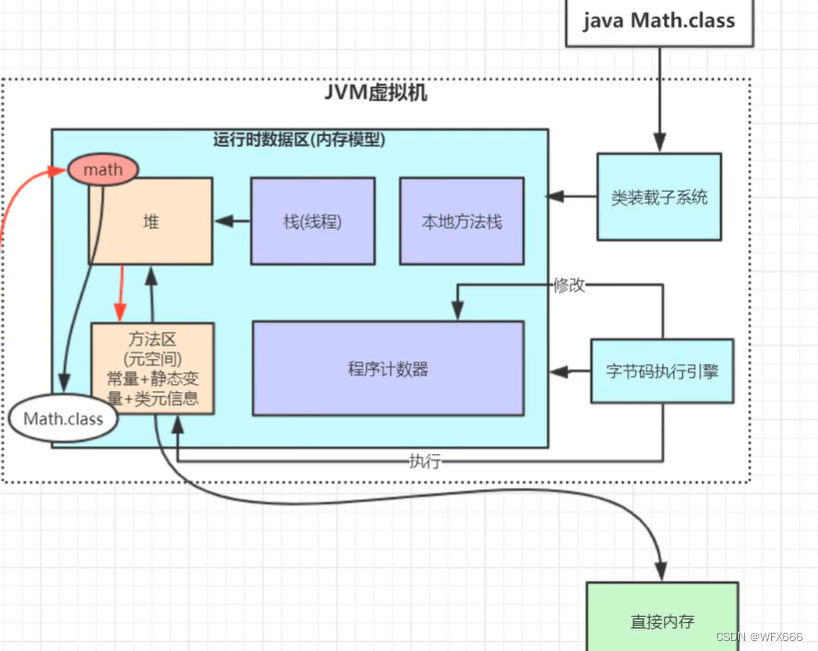
栈内存:先进后出,(栈中的局部变量引用堆中的地址)
操作数栈:代码执行加减乘除
堆:GC
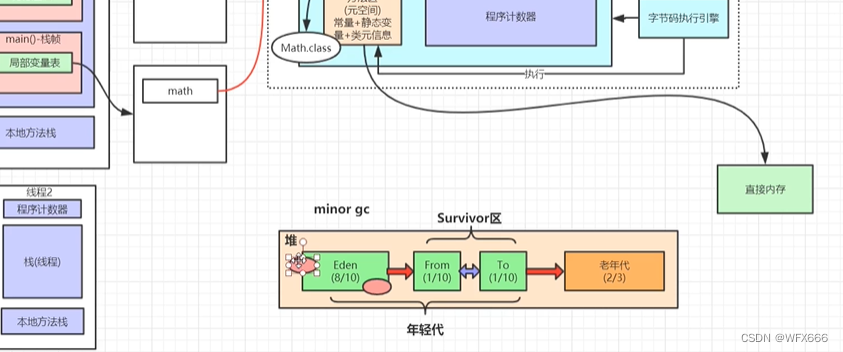
分为年轻代(占1/3),老年代(占2/3),
年轻代:分为Eden区,From区,To区
对象分代年龄:对象头上的一个4bt标识,每移动一次区域就会+1,当达到15(好像可设置),就会将对象移到老年代(存在老年代的一般是线程池,静态对象,spring bean)
Eden区:new的对象一般放在Eden区,当此内存区放满时会触发字节码执行引擎minor GC(不被引用的对象)
Eden区和From区到To区是复制算法
当老年代放满时会触发full Gc 如果还是清理不掉对象,则会OOM
GC用到的算法
标记清除算法:
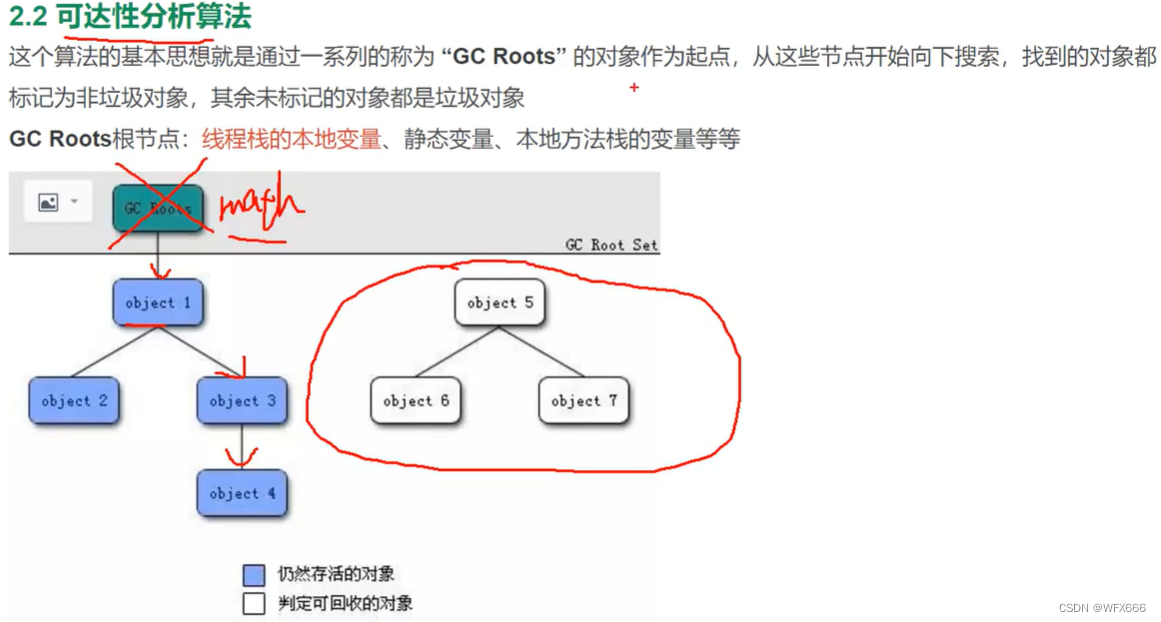
对象存活判断:
可达性分析
垃圾收集算法:(标记 -清除算法)
复制算法:它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。---内存缩小为原来的一半,持续复制长生存期的对象则导致效率降低
标记-压缩算法:
分代收集算法:


程序计数器:简单理解线程代码执行步数,执行到的位置
对象:
GC
1.8 顺序遍历和逆序遍历的区别?
1.9 为什么hashcode和equals方法需要重写?
1、重写equals()是为了实现自己的区分逻辑。
2、重写hashCode()是为了提高hash tables的使用效率,以及和equals()保持一致(看下面hashcode的第三点)。
举例:
1、String重写Object的equals方法
2、HashSet是如何保证存储的元素不同的?
举例:
1、String重写Object的equals方法
2、HashSet是如何保证存储的元素不同的?
原文链接:https://blog.csdn.net/river66/article/details/87803663
2.0 栅栏:CyclicBarrier
2.Spring
@Autowired 与@Resource的区别:
1、@Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
2、@Autowired默认按类型装配(这个注解是属业spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
spring不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resource、@PostConstruct以及@PreDestroy。
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了。@Resource有两个属性是比较重要的,分是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序
1. 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
2. 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
3. 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
4. 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
@Autowired 与@Resource的区别:
1、 @Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
2、 @Autowired默认按类型装配(这个注解是属业spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
https://blog.csdn.net/weixin_40423597/article/details/80643990
2.1.AOP原理
Ioc:控制反转,是一种思想,主要是用来解耦,核心做法是增加ioc容器(将特定包下的代码扫描注册实例话在一个bean容器中),使用时通过注入的方式即可。
Spring AOP:分为静态代理和动态代理
静态代理:
动态代理
JDK 动态代理:是通过 JDK 中的 java.lang.reflect.Proxy 类实现的。它也有一定的局限性,这是因为 JDK 动态代理必须要实现一个或多个接口。
CGLIB:
| 名称 | 说明 |
| JoinpointJoinpoint(连接点) | 指那些被拦截到的点,在 Spring 中,可以被动态代理拦截目标类的方法。 |
| Pointcut(Pointcut切入点) | 指要对哪些 Joinpoint 进行拦截,即被拦截的连接点。 |
| Advice( Advice通知) | 指拦截到 Joinpoint 之后要做的事情,即对切入点增强的内容。 |
| Target( Target目标) | 指代理的目标对象。 |
| Weaving(Weaving植入) | 指把增强代码应用到目标上,生成代理对象的过程。 |
| Proxy( Proxy代理) | 指生成的代理对象。 |
| Aspect Aspect( 切面) | 切入点和通知的结合。 |
2.2 依赖注入原理
2.3.springBoot
运行机制:
从启动类注解:
springbootApplication
涉及注解:
@SpringBootConfiguration
@EnableAutoConfiguration—
@AutoConfigurationPackage
@Import
@ComponentScan
Springboot根据配置文件自动装配所属依赖的类再用动态代理的方式注入到spring容器里面
1.特有的配置文件?
2.特有的注解?
@SpringBootApplication
@ ServletComponentScan
3.生命周期
https://www.it610.com/article/1288250549858250752.htm
首先说一下Servlet的生命周期:实例化,初始init,接收请求service,销毁destroy;
Spring上下文中的Bean生命周期也类似,如下:
(1)实例化Bean:
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
(2)设置对象属性(依赖注入):
实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完成依赖注入。
(3)处理Aware接口:
接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
①如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的就是Spring配置文件中Bean的id值;
②如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor:
如果想对Bean进行一些自定义的处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。
(5)InitializingBean 与 init-method:
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(6)如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(7)DisposableBean:
当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(8)destroy-method:
最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
2.4.springCloud
@1.组件有哪些
K8S:
服务发现——Netflix Eureka
客服端负载均衡——Netflix Ribbon
断路器——Netflix Hystrix
服务网关——Netflix Zuul
分布式配置——Spring Cloud Config
2.4.1 微服务各种注解的使用
@Mapper: 注解写在你的Mapper映射接口上面
@SpringBootApplication: 写在主程序上面
@Configuration: 写在配置类上面
@Bean: 写在配置类中的返回新的对象的方法上面
@EnableEurekaServer: 把当前微服务标记为Eureka注册中心 接收其他微服务的注册
@EnableEurekaClient: 注册该微服务到Eureka中
@LoadBalanced: 该注解写在配置RestTemplate的配置类方法上来启动ribbon负载均衡
@EnableFeignClients: 写在主程序上来支持feign
@HystrixCommand(fallbackMethod=“你的方法”)
@EnableCircuitBreaker : 启用对Hystrix熔断机制的支持
@FeignClient(value="服务名",fallbackFactory=实现FallbackFactory的类.class): 实现服务降级
@EnableHystrixDashboard: 加在主程序上启动服务监控
@FeignClient(value=“服务名”): 写在接口上 来调用远程服务
@EnableZuulProxy: 写在主程序上启动zuul路由访问功能
2.5 springMvc
SpringMVC框架是以请求为驱动,围绕Servlet设计,将请求发给控制器,然后通过模型对象,分派器来展示请求结果视图。其中核心类是DispatcherServlet,它是一个Servlet,顶层是实现的Servlet接口。

SpringMVC运行原理
需要在web.xml中配置DispatcherServlet。并且需要配置spring监听器ContextLoaderListener

(1)客户端(浏览器)发送请求,直接请求到DispatcherServlet。
(2)DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
(3)解析到对应的Handler后,开始由HandlerAdapter适配器处理。
(4)HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。
(5)处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。
(6)ViewResolver会根据逻辑View查找实际的View。
(7)DispaterServlet把返回的Model传给View。
(8)通过View返回给请求者(浏览器)
2.6 spring事务
事务传播行为是指方法之间事务的传播. 比如, 在方法A中调用了方法B:
PROPAGATION_REQUIRED:默认传播
如果A有事务就使用当前事务, 如果A没有事务, 就创建一个新事务.
PROPAGATION_SUPPORTS :支持
如果A有事务就使用当前事务, 如果A没有事务, 就以非事务执行.
PROPAGATION_MANDATORY :强制性
如果A有事务就使用当前事务, 如果A没有事务, 就抛异常,用来检验上下逻辑有没有加事务
PROPAGATION_REQUIRES_NEW
不管A有没有事务都创建一个新事务.
PROPAGATION_NOT_SUPPORTED
不管A有没有事务都以非事务执行.
PROPAGATION_NEVER :不能有事务
如果A有事务就抛异常, 如果A没有事务, 就以非事务执行.
PROPAGATION_NESTED:
如果A没有事务就创建一个事务, 如果A有事务, 就在当前事务中嵌套其他事务.
2.7 bean的生命周期
3.中间件
3.1Redis
@1.了解多少
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。string 类型的值最大能存储 512MB
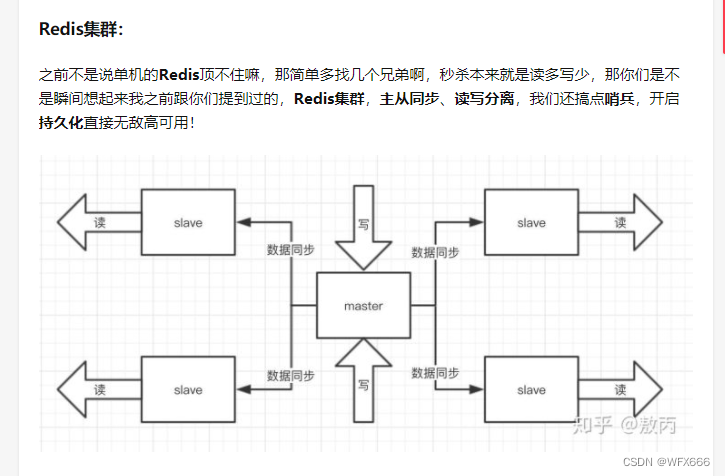
Redis问题点:
https://blog.csdn.net/womenyiqilalala/article/details/105205532
1.缓存穿透
缓存穿透是指查询一个根本不存在的数据
解决:设置null值返回/设置返回null的key过期时间/布隆过滤器
2.缓存雪崩
Key失效,大量请求直接到达存储层,存储层压力过大导致系统雪崩
三方面:1.redis系统宕机(多个节点高可用)。2.不让key同时失效,随机失效时间。3.做多级缓存,本地进程一级缓存,redis二级缓存
3.缓存击穿
系统中存在以下两个问题时需要引起注意:
- 当前key是一个热点key(例如一个秒杀活动),并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
解决方案:分布式锁,ression-》lock。布隆过滤器
4.持久化:
AOF
RDB
5.如何保证Redis与数据库的数据一致性?双写一致
6.分布式锁
Jedis
Lettuce
RedisTemplate
Redisson
3.2RocketMQ
@1.了解多少
异步处理,应用解耦,流量削锋和消息通讯四个场景
https://www.cnblogs.com/linjiqin/p/5720865.html
rocketMq如何保证消息不丢失?
Producer发送消息阶段
手段一:提供SYNC的发送消息方式,等待broker处理结果。
手段二:发送消息如果失败或者超时,则重新发送。
手段三:broker提供多master模式
Broker处理消息阶段
手段四:提供同步刷盘的策略【等待刷盘成功才会返回producer成功】
手段五:提供主从模式,同时主从支持同步双写
Consumer消费消息阶段
手段六:consumer默认提供的是At least Once机制
手段七:消费消息重试机制
4.数据库
4.1数据库优化
数据库会问有没有调优经验?
4.2 Mysql
MySQL 索引和事务、并发访问处理、脏读、不可重复读、幻读、丢失更新(C/C++)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1cv411P7Wb/?spm_id_from=333.337.search-card.all.click&vd_source=4f507e36c1556aa9a2cf62fa04b94c6f
两种引擎:(引擎是来形容表的)
MYISAM(my sam):不支持外键,表锁,插入数据时,锁定整个表,查表总行数时,不需要全表扫描。

INNODB:支持外键,行锁,查表总行数时,全表扫描。
为什么innodb必须有主键,并且推荐使用整型的自增主键?
数据库B+树决定的,自增是用于判断子节点
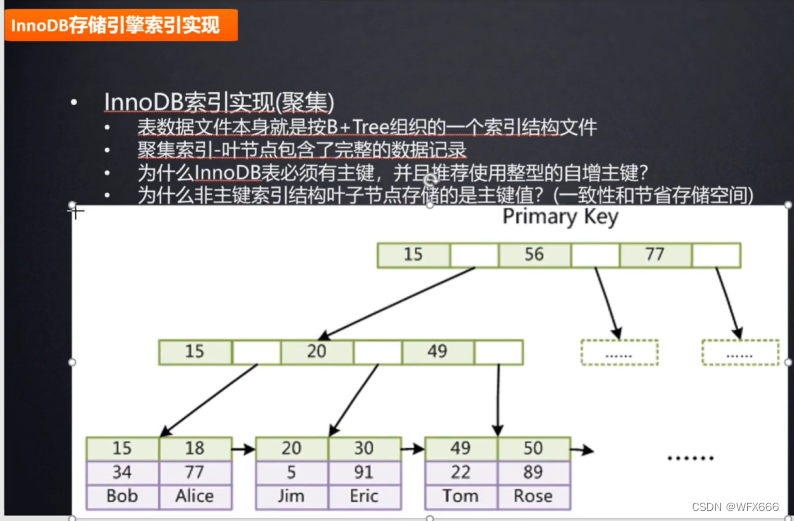
索引分为:有B+索引和hash索引
Hash :hash索引,等值查询效率高,不能排序,不能进行范围查询
B树:数据有序,范围查询
聚集索引:
索引和数据在一个文件,只需要查询一次
非聚集索引:
索引和数据在两个文件,需要查询两次
联合索引:
5.数据结构
5.1 算法
雪花算法:
- 时间位:可以根据时间进行排序,有助于提高查询速度。
- 机器id位:适用于分布式环境下对多节点的各个节点进行标识,可以具体根据节点数和部署情况设计划分机器位10位长度,如划分5位表示进程位等。
- 序列号位:是一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号
Redis也能生成自增主键
Uuid和雪花算法
UUID (Universally Unique Identifier),通用唯一识别码。UUID是基于当前时间、计数器(counter)和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。
格式 & 版本
UUID由以下几部分的组合:
当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
时钟序列。
全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
优点
- 简单,代码方便。
- 生成ID性能非常好,基本不会有性能问题。本地生成,没有网络消耗。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点
- 采用无意义字符串,没有排序,无法保证趋势递增。
- UUID使用字符串形式存储,数据量大时查询效率比较低
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
5.2 数据结构
索引(有顺序)
1.二叉树
(根节点左边子节点小于根节点,右边子节点大于根节点)
缺点:查询慢,最坏情况当查6节点时基本遍历整张表,

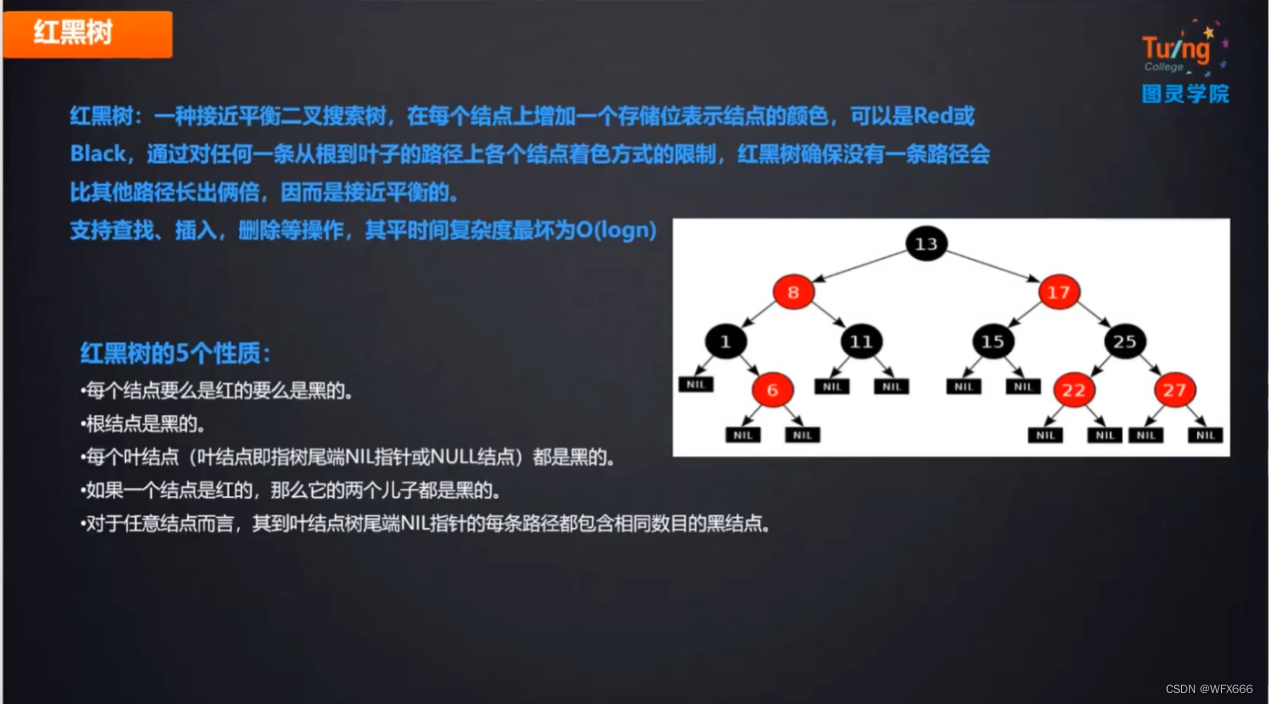
2.红黑树(平衡树)
红黑树:当单边存储过大时旋转平衡
缺点:数据量太大时深度太高,查找慢

3.B树
每一个叶子节点默认大小16K
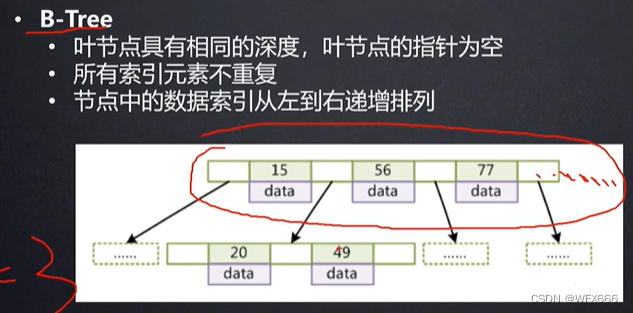
4.B+树

6.网络通信
6.1 IO/NIO
6.2.TCP/IP
三次握手:
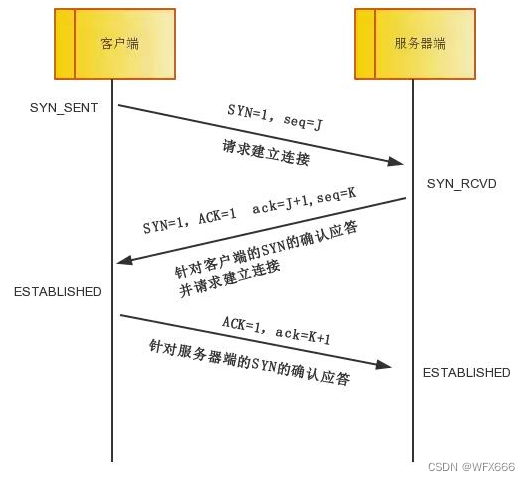
- 第一次握手:客户端将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给服务器端,客户端进入SYN_SENT状态,等待服务器端确认。
- 第二次握手:服务器端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务器端将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给客户端以确认连接请求,服务器端进入SYN_RCVD状态。
- 第三次握手:客户端收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务器端,服务器端检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端和服务器端进入ESTABLISHED状态,完成三次握手,随后客户端与服务器端之间可以开始传输数据了。
四次握手:

- 中断连接端可以是客户端,也可以是服务器端。
- 第一次挥手:客户端发送一个FIN=M,用来关闭客户端到服务器端的数据传送,客户端进入FIN_WAIT_1状态。意思是说"我客户端没有数据要发给你了",但是如果你服务器端还有数据没有发送完成,则不必急着关闭连接,可以继续发送数据。
- 第二次挥手:服务器端收到FIN后,先发送ack=M+1,告诉客户端,你的请求我收到了,但是我还没准备好,请继续你等我的消息。这个时候客户端就进入FIN_WAIT_2 状态,继续等待服务器端的FIN报文。
- 第三次挥手:当服务器端确定数据已发送完成,则向客户端发送FIN=N报文,告诉客户端,好了,我这边数据发完了,准备好关闭连接了。服务器端进入LAST_ACK状态。
- 第四次挥手:客户端收到FIN=N报文后,就知道可以关闭连接了,但是他还是不相信网络,怕服务器端不知道要关闭,所以发送ack=N+1后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。服务器端收到ACK后,就知道可以断开连接了。客户端等待了2MSL后依然没有收到回复,则证明服务器端已正常关闭,那好,我客户端也可以关闭连接了。最终完成了四次握手。















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









