







 本文介绍了Python的四种组合数据类型:集合、元组、列表和字典。集合是无序且不重复的元素集合,可用于成员关系测试和去重。元组是不可变序列,常用于保存数据。列表是可变序列,支持多种操作,如插入、删除和排序。字典是键值对的集合,通过键来访问值。文章详细讲解了每种类型的特点、创建方法、操作符和操作函数,以及它们在实际编程中的应用。
本文介绍了Python的四种组合数据类型:集合、元组、列表和字典。集合是无序且不重复的元素集合,可用于成员关系测试和去重。元组是不可变序列,常用于保存数据。列表是可变序列,支持多种操作,如插入、删除和排序。字典是键值对的集合,通过键来访问值。文章详细讲解了每种类型的特点、创建方法、操作符和操作函数,以及它们在实际编程中的应用。
06-07 组合数据类型_集合类型&序列类型&映射类型
【集合、元组、列表、字典】

组合类型的基本概念
- 组合数据类型:能够表示多个数据的类型。
- 常用的组合数据类型:
① 集合类型:集合类型是一个元素的集合,元素之间无序,相同的元素在集合中唯一存在。【集合set】
② 序列类型:序列类型是一个元素的向量,元素之间存在先后顺序,通过序号访问,元素之间不排他。【不可变序列:字符串string,元组tuple;可变序列:列表list】
③ 映射类型:映射类型是“键-值”数据项的组合,每一个元素是一个键值对,表示为(key,value)。【字典dict】
一、集合类型
集合类型的定义和特点
• 集合类型:(等同于数学概念的“集合”)包含0个或多个数据项的无序组合(不能比较,不能排序)。用大括号{}表示,没有索引和位置的概念,集合中的元素可以动态增加或删除。
• 特点:①集合是无序的。②集合中的元素不可重复,元素类型只能是不可变数据类型。(∴ 列表、字典和集合类型本身都是可变的数据类型,不能作为集合的元素出现。)
• 注意:
①由于集合的元素是无序的,集合的输出顺序与定义顺序可以不一致。
②由于集合元素不可重复,使用集合类型能够过滤掉重复元素。【集合元素,输入时不受限制,输入后自动去重】
集合的创建
- 创建空集合
set()函数可以生产空集合变量
>>> s = set()
>>> s
set() # set()表示空集合
注意:
直接使用大括号{},生成的是字典类型,而不是集合类型。
>>> s = {}
>>> print(type(s))
<class 'dict'>
- 创建非空集合
>>> s = {1, "123",1.1}
>>> s
{1, 1.1, '123'}
>>> s=set("123")
>>> s
{'1', '2', '3'}
- set()函数:将其他组合数据类型变成集合类型,返回结果是一个无重复且排序任意的集合。
注意:
set()函数可以创建一个无序不重复的元素集,这个函数至多可以传一个参数。
如下,则传了3个参数,所以报错“TypeError: set expected at most 1 argument, got 3”。
>>> s = set(1, "123", 1.1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: set expected at most 1 argument, got 3
同理:
>>> s = set([1,2],3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: set expected at most 1 argument, got 2
解决方法:用set()函数直接传一个字符串,或列表。
>>> s=set("123")
>>> s
{'1', '2', '3'}
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}
集合类型的用途:
①成员关系测试
S={1,2,3,'omg','ok','yes'}
T='omg' in S
print(T)
②元素去重
集合类型主要用于元素去重,适用于任何组合数据类型
S={1,2,3,'omg','ok','yes',2,'omg'}
T=set(S)
print(T)
③去重同时,删除数据项
#去重同时删除数据项
S={1,2,3,'omg','ok','yes',2,'omg'}
T=set(S)
P=tuple(T-{'ok'})
print(P)
集合类型操作符
集合类型操作符:交集(S&T)、并集(S|T)、差集(S-T)、补集(S^T)。操作逻辑与数学定义相同。
*拓展-数学名词:

差集(相对补集):
符号表示:B-A
图形表示:(韦恩图/Venn图)
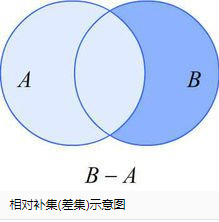
意义:{x∣x∈A,且x∉B}
集合类型常用的操作函数或方法
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s中。 |
| S.remove() | 如果数据项x在集合S中,移除该元素;如果x不在集合S中,产生KeyError异常。 |
| S.clear(x) | 移除S中的所有数据项。 |
| len.(S) | 返回集合S的元素个数。 |
| x in S | 如果x是集合S的元素,返回True,否则返回False。 |
| x not in S | 如果x不是集合S的元素,返回True,否则返回False。 |
*拓展:
| 函数或方法 | 描述 |
|---|---|
| S.copy() | 返回集合S的一个副本。 |
| S.pop() | 随机返回集合中S的一个元素,如果S为空,产生KeyError异常。 |
| S.discard(x) | 如果数据项x在集合S中,移除该元素;如果x不在集合S中,不报错。 |
| S.isdisjoint(T) | 如果集合S与集合T没有相同元素,返回True,否则返回False。 |
补充理解:【python中不可变数据类型和可变数据类型】
*见03基本数据类型:

以下知识点摘抄于:https://www.cnblogs.com/shangping/p/11368236.html
以下所有的内容都是基于内存地址来说的。
不可变数据类型: 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,对于这种数据类型,就称不可变数据类型。
可变数据类型:当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,对于这种数据类型,就称可变数据类型。
总结:不可变数据类型更改后地址发生改变,可变数据类型更改地址不发生改变。可变与不可变数据类型,就是说元素能不能动态增加或删除。
举一个不可变数据类型的栗子——整型:
a = 1
print(id(a),type(a))
a = 2
print(id(a),type(a))
result:
1912499232 <class 'int'>
1912499264 <class 'int'>
我们可以发现,当数据发生改变后,变量的内存地址发生了改变,那么整型就是不可变数据类型。
再举一个可变数据类型的栗子——列表:
list = [1,'q','qwer',True]
print(list,type(list),id(list))
list.append('djx')
print(list,type(list),id(list))
result:
[1, 'q', 'qwer', True] <class 'list'> 808140621128
[1, 'q', 'qwer', True, 'djx'] <class 'list'> 808140621128
我们可以发现,虽然集合数据发生改变,但是内存地址没有发生了改变,那么集合就是可变数据类型。
- id([object]):用于获取对象的内存地址。
“python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。”
二、序列类型
序列类型的定义和特点
- 序列类型:序列类型是一维元素向量,元素之间存在先后关系,通过序号访问。
*拓展-数学名词:
向量:在数学中,向量指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量相对应,只有大小,没有方向的量叫做数量(物理学中称标量)。
*【python中,向量即一维数组,矩阵即二维数组】【序列类型的一维向量】
- 序列类型特点:①有序(各个元素有序号)②元素可重复(数值相同,序号不同)
序列类型的索引体系:
序列各具体类型使用相同的索引体系,即正向递增序号和反向递减序号。
*(同字符串的索引)见03Python基础数据类型(数字类型,字符串类型):

可变/不可变序列类
序列类型可分为可变序列(序列中的元素可以改变)和不可变序列(序列中的元素不能改变):
| 序列类型 | 代表 |
|---|---|
| 可变序列 | 列表(list) |
| 不可变序列 | 字符串(str),元组(tuple) |
序列类型的通用操作符和函数(⭐)
| 操作符 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True;否则返回False |
| x not in s | 如果x不是s的元素,返回True;否则返回False |
| s + t | 连接s和t【拼接】 |
| s * n 或 n * s | 将序列s复制n次 |
| s[i] | 返回序列的第 i 个元素【索引】 |
| s[i:j:k] | 步骤切片,返回包含序列 s 第 i 到 j 个元素以 k 为步数的子序列(k默认为1)【切片】 |
| len(s) | 序列s的元素个数(长度) |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x) | 序列s中第一次出现元素x的位置【查下标】 |
| s.count(x) | 序列s中出现x的总次数 |
1. 元组(tuple)
元组的定义
- 元组属于不可变序列类型,即元组中的元素不能修改。
- 注意:(不希望数据发生变化,则用元组;反之,用列表。)
如果需要自定义变量,通常使用列表代替元组。
如果确认编程中不需要修改数据,可以使用元组。
元组的创建
- 创建空元组
方法一:()
>>> t = ()
>>> t
()
方法二:tuple()
>>> t=tuple()
>>> t
()
- 创建非空元组
>>> tup = (1, "2", 1.1)
>>> tup
(1, '2', 1.1)

注意:如果元组不是一个空元组,那么它必须得有一个逗号。
tuple1=10, → 加上逗号会变成元组。
tuple2=(10) → int类型(整型)
tuple3=10 → int类型(整型)
tuple4 =(10,)→元组
元组拆包
元组拆包,指将元组当中的每一个元素都赋值给一个变量。
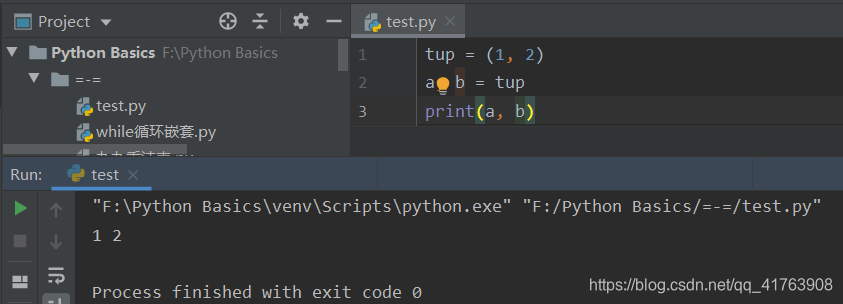
当变量的数量与元组内元素的数量不一致时,会报错。
如下:ValueError: not enough values to unpack (expected 3, got 2)
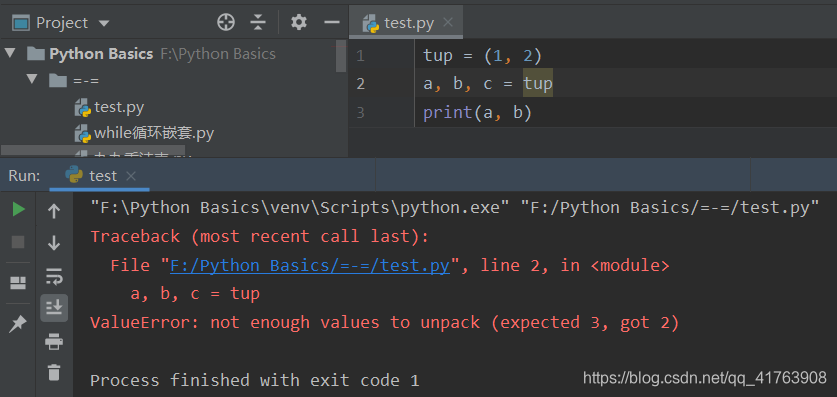
解决办法:
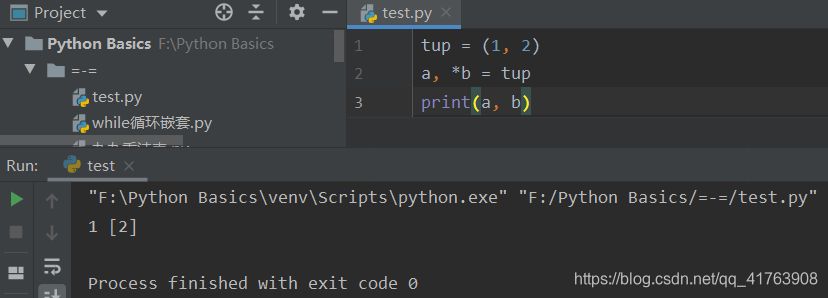
如上:“*b”接收后面所有的数据。
注意:星号表示有多个。拆包时,有且只能有一个星号。
星号接受参数之后,结果是用一个列表来存储。
- 字符串、列表也可以拆包。

(3)关于元组元素的不可变性
- (1)tuple元素不可变有一种特殊情况:当元素是可变对象时。对象内部属性是可以修改的!
tuple的不可变限制只是在一个纬度上:元素的类型。tuple的元素所保存的内容(数值或内存地址)是不允许修改的,但地址映射的对象自身是可以修改的。
举个栗子:
# 对列表[3,2]的一个元素重新赋值,变成列表[1,2]
>>> a = (1,[3,2])
>>> a[1][0] = 1
>>> a
(1, [1, 2])
# 增加一个元素到列表[1,2],变成列表[1,2,3]
>>> a[1].append(3)
>>> a
(1, [1, 2, 3])
# 删掉列表[1,2,3]中的一个元素,变成列表[1,2]
>>> del a[1][2]
>>> a
(1, [1, 2])
# 删掉元组中的元素,会报错
# TypeError: 'tuple' object doesn't support item deletion
>>> a = (1,[3,2])
>>> del a[1]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object doesn't support item deletion
- (2)不可变的tuple有什么意义?
因为tuple不可变,所以代码更安全。
2. 列表(list)
(1)列表的定义和作用
- 列表:列表是包含个或多个元素的有序序列。
- 列表属于可变序列类型,即列表中的元素可以修改。
- 列表的作用:
列表中可以保存多个有序的数据
列表是用来存储对象的对象
###(2) 列表的创建 - 创建空列表
方法一:[]
>>> t = []
>>> t
[]
方法二:list()
>>> t=list()
>>> t
[]
list()函数可以将集合或字符串类型转换成列表类型。
列表的索引
-
列表的索引:见序列类型的索引体系,即正向递增序号或反向递减序号。
正向递增序号:
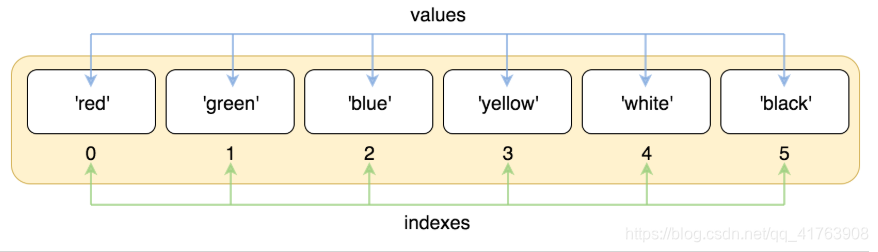
反向递减序号:
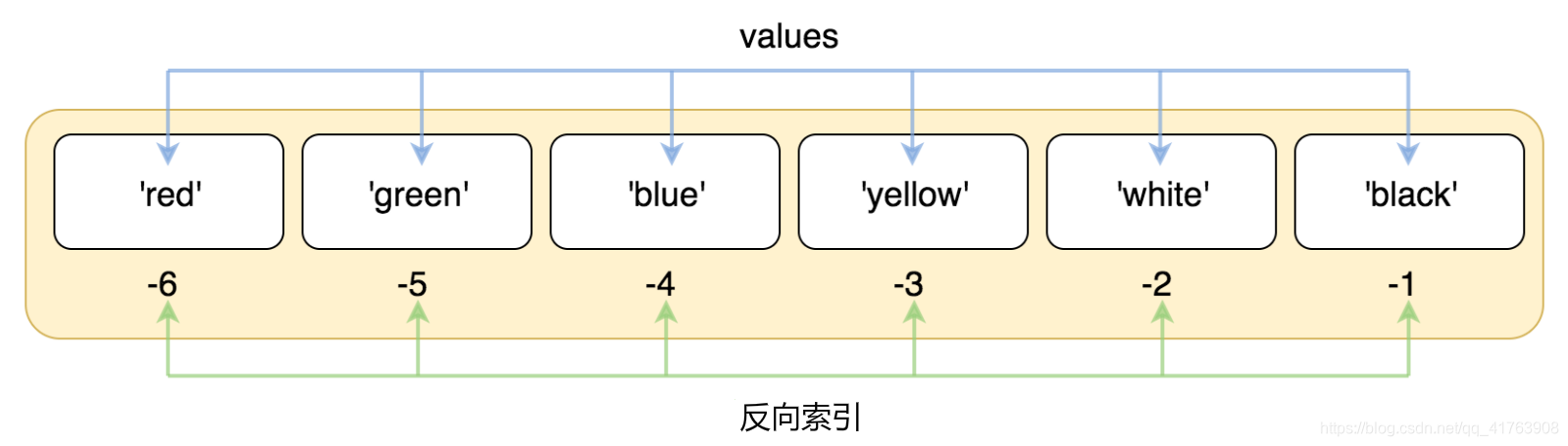
-
索引序号不能超过列表的元素范围,否则会产生IndexError错误。
-
可以使用for循环对列表类型的元素进行遍历操作:
for <循环变量> in <列表变量>:
<语句块>
举个栗子:
ls = [1, "2", [3], 4.0, (2,3)]
for i in ls:
print(i*2)
result:
2
22
[3, 3]
8.0
(2, 3, 2, 3)
说明:
①"2"是字符串类型,打印两次;
②星号表示将列表复制指定的次数 (注意2个列表不能够做乘法,要和整数做乘法运算) 如上,[3]*2=[3, 3],(2, 3)*2=(2, 3, 2, 3)
举个列表乘列表报错的栗子:
# 错误用法:列表乘列表,不用这样使用
a = [1, 2, 3] * [4, 5, 6]
# TypeError: can't multiply sequence by non-int of type 'list'
- 拓展补充:列表是一个可迭代对象(Iterable)
我们可以对list、tuple、dict、set、str等类型的数据使用for…in…的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代。
把可以通过for…in…这类语句迭代读取一条数据供我们使用的对象称之为可迭代对象(Iterable)。
(相关名词:迭代器,生成器;iter,next)(((φ(◎ロ◎;)φ)))
列表的切片
-
列表的切片是指,从现有列表中获得一个子列表。

-
语法:list[N:M:K]
*列表[起始 : 结束 : 步长]
*左闭右开区间;左取右不取,左右空取到头
*步长默认是1。步长不能是0,但可以是是负数
列表类型的操作
列表的操作函数
列表类型继承了序列类型的通用操作函数。
| 操作符 | 描述 |
|---|---|
| len(ls) | 序列s的元素个数(长度) |
| min(ls) | 序列s中的最小元素 |
| max(ls) | 序列s中的最大元素 |
| list(x) | 将x转变成列表类型 |
注意:
min(ls)和max(ls)函数的使用前提是,列表中的各元素类型可以进行比较,否则会报错。
- 举个栗子:
>>> ls = ["10", "11", "Python"]
>>> max(ls)
'Python'
见03基本数据类型-字符串类型-字符串的其他操作。

- 再举个栗子:
>>> ls = [1010, 10.10, 0x1010]
>>> min(ls)
10.1
*0x或0X是十六进制整数的引导符号。【(〃>目<)记得补充:基本数据类型-数字类型-整数类型的4种进制表示】
*程序无论采用何种进制表达数据,计算机内部都以相同数值储存数值,因此,进制之间的运算默认以十进制方式显示。
其他:
• + 和 *
• + 可以将两个列表拼接成一个列表
• * 可以将列表重复指定的次数 (注意2个列表不能够做乘法,要和整数做乘法运算)
• in 和 not in
• in用来检查指定元素是否在列表当中
• not in 用来检查指定元素是否不在列表当中
• list.index(x, start, end)
第一个参数 获取指定元素在列表中的位置
第二个参数 表示查找的起始位置
第三个参数 表示查找的结束位置
>>> ls = ['a', 'b', 'c', 'd', 'e']
>>> ls.index('a', 0, 2)
0
x不在范围内,会报错。ValueError: ‘a’ is not in list
>>> ls = ['a', 'b', 'c', 'd', 'e']
>>> ls.index('a', 1, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'a' is not in list
• list.count(x) 统计指定元素在列表中出现的个数
列表的操作方法(增删改查)
语法:<列表变量>.<方法名称>(<方法参数>)
| 方法 | 描述 |
|---|---|
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.insert(i, x) | 在列表ls原来第i位置前增加元素x |
| ls.clear() | 删除ls中所有元素 |
| ls.pop(i) | 将列表ls中第i项元素取出并从ls中删除该元素 |
| ls.remove(x) | 将列表中出现的第一个元素x删除 |
| ls.reverse() | 将列表ls中的元素反转【逆序】 |
| ls.copy() | 生成一个新的列表,复制ls中所有的元素 |
【增:ls.sppend(x),list.insert(i, x),ls.extend(seq)】
① ls.append(x)在列表中增加多个元素,可以用加号,将两个列表合并。
>>> m = ["P","Y","T"]
>>> n = ["H", "O", "N"]
>>> print(m + n)
['P', 'Y', 'T', 'H', 'O', 'N']
②ls.insert(i, x):在列表ls原来第i位置前增加元素x。
>>> ls = ['1', '2', '3', '4']
>>> ls.insert(2, '2.5')
>>> print(ls)
['1', '2', '2.5', '3', '4']
③ls.extend(seq):在列表末尾一次性追加另一个序列中的多个值(eg. 用新列表扩展原来的列表)
*参数:seq – 元素列表,可以是列表、元组、集合、字典,若为字典,则仅会将键(key)作为元素依次添加至原列表的末尾。
举个栗子:(加字符串)
ls = ['how', 'are', 'you']
ls.extend('fine')
print(s)
result:
['how', 'are', 'you', 'f', 'i', 'n', 'e']
再举个栗子:(加列表)
ls = ['how', 'are', 'you']
ls.extend(["I'm", "fine"])
print(s)
result:
['how', 'are', 'you', "I'm", 'fine']
【删:ls.remove(x),ls.pop(i); clear(); del ls[N:M:K]】
① ls.pop(i)将返回列表ls中序号为i的元素,并将该元素从列表中删除。注意区分ls.pop(i)和ls.remove(x)
>>> ls = ['P', 'Y', 'T', 'H', 'O', 'N']
>>> print(ls.pop(2))
T
>>> print(ls)
['P', 'Y', 'H', 'O', 'N']
② ls.remove(x)将删除列表ls中第一次出现的x元素。
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> ls.remove('P')
>>> print(ls)
['H', 'A', 'P', 'Y', '!']
③ ls.clear()将列表ls的所有元素删除,清空列表。
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> ls.clear()
>>> print(ls)
[]
④del ls[N:M:K]7,即del <列表变量>[<索引起始>:<索引结束>:<步长>]
i. del <列表变量>[<索引序号>]
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> del ls[5]
>>> print(ls)
['H', 'A', 'P', 'P', 'Y']
ii. del <列表变量>[<索引起始>:<索引结束>:<步长>](步长默认为1)
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> del ls[1:5:2]
>>> print(ls)
['H', 'P', 'Y', '!']
【改:ls[i]=’ '/[ ],ls[N:M:K] = ’ ‘/[ ] #重新赋值,K默认为1】
ls[index]=’ ’
>>> ls = [1,2,3,5,'cat',2,3,4,5,'bye']
>>> ls[3] = 'monkey'
>>> print(li)
[1, 2, 3, 'monkey', 'cat', 2, 3, 4, 5, 'bye']
ls[N:M:K] =’ ’
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> ls[1:] = 'i'
>>> print(ls)
['H', 'i']
【查:(查询列表中的数据)ls.index(x), ls.sort(), ls.count(x)】
①ls.index(x)方法:获取指定元素的下标
>>> li3 = [11, 22, 33, 44, 55, 'aaa',11]
>>> res = li3.index(33) //用一个变量接收结果
>>> print(res)
2
②ls.sort(key=None,reverse=False) 用来对列表中的元素进行排序,默认正向排序。∵reverse表示反转。∴ reverse=True --> 逆序;reverse=False --> 正序
正序:
>>> ls = [1, 3, 2, 5, 4]
>>> ls.sort()
>>> print(ls)
[1, 2, 3, 4, 5]
逆序:
>>> ls = ['a', 'b', 'c', 'd']
>>> ls.sort(reverse=True)
>>> print(ls)
['d', 'c', 'b', 'a']
③s.count(x):序列s中出现x的总次数
>>> ls = ['H', 'A', 'P', 'P', 'Y', '!']
>>> ls.count('P')
2
三、映射类型
映射类型的概述
- 映射类型是“键-值”数据项的组合,每个元素是一个键值对,即元素是(key, value),元素之间是无序的。
- 映射类型是由用户来定义序号,即键,用其去索引具体的值。
字典类型
字典的定义和特点
- 字典(dict):{key:value}每一个key都是唯一的,且与唯一的value相对应。没有索引的概念。key-value,键值对,也可以称为一项(item)
- (python出于设计考虑,由于大括号{}可以表示集合,)字典类型也具有和集合类似的性质,即键值对之间没有顺序且不能重复。
字典的创建
- 创建空字典
方法一:大括号{}可以创建一个空字典。
>>> d = {}
>>> print(d,type(d))
{} <class 'dict'>
方法二:dict()函数可生成一个空字典,作用和{}相同。
>>> d = dict()
>>> print(d)
{}
- 创建非空字典
方法一:{}创建字典
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> print(dict1, type(dict1))
{'name': '郭靖', 'age': 18, 'sex': '男'} <class 'dict'>
方法二:dict()函数创建字典
>>> dict1 = dict(name='郭靖', age=18, sex='男')
>>> print(dict1, type(dict1))
{'name': '郭靖', 'age': 18, 'sex': '男'} <class 'dict'>
注意:
①当字典中的key重复时,后面的键值对会替换掉前面的。(每一个key都是唯一的。)
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男', 'name': '欧阳锋'}
>>> print(dict1,type(dict1))
{'name': '欧阳锋', 'age': 18, 'sex': '男'} <class 'dict'>
②dict()双值子序列创建字典
说明:
i. Python2里,分有序和无序(无序,即不一定按添加元素的顺序打印)字典,列表里嵌套元组;Python3里只有有序的字典。
ii. 什么是双值序列?如列表[1, 2]就是双值序列;
什么是子序列?字符串’a’就可以作为一个子序列;
什么是双值子序列?字典里的双值子序列,就是序列之间的嵌套,例如[(1, 2), (3, 4)],是列表与元组嵌套。
>>> dict1 = dict([('name', '郭靖'), ('age', 18), ('sex', '男')])
>>> print(dict1, type(dict1))
{'name': '郭靖', 'age': 18, 'sex': '男'} <class 'dict'>
字典的索引
- 索引是按照一定顺序检索内容的体系。列表类型采用元素顺序的位置进行索引。字典元素“键值对”中键是值得索引。
- 字典中获取值(value)的方法:
①dict[key]
<值>=<字典变量>[<键>]
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> print(dict1['name'])
郭靖
>>> dict1 = dict(name='郭靖', age=18, sex='男')
>>> print(dict1['name'])
郭靖
*<键>是’name’,写成name(不加引号)会报错。NameError: name ‘name’ is not defined
>>> dict1 = dict(name='郭靖', age=18, sex='男')
>>> print(dict[name])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'name' is not defined
*key不存在会报错。KeyError: ‘skill’
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> print(dict1['skill'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'skill'
②dict.get(key)
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> print(dict1.get('name'))
郭靖
*获取值有两种方式:dict[key],key不存在会报错。dict.get(key),key不存在不会报错,会返回default默认值None。
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> print(dict1.get('skill'))
None
字典类型的操作
字典类型的操作函数
| 操作函数 | 描述 |
|---|---|
| len(d) | 字典d的元素个数(长度) |
| min(d) | 字典d中键的最小索引值 |
| max(d) | 字典d中键的最大索引值 |
注意,min(d)和max(d)返回的是索引值,而不是键值对中的“值”。另外,使用这两个函数的前提是字典中各索引元素可以进行比较。
>>> dict1 = {1: '清清', 2: '楚楚', 3: '明明', 4: '白白'}
>>> print(max(dict1))
4
*str 和 int 不能进行比较。
>>> dict1 = {1: '清清', 'a': '楚楚', 3: '明明', 'b': '白白'}
>>> print(max(dict1))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '>' not supported between instances of 'str' and 'int'
字典的操作方法
| 操作方法 | 描述 |
|---|---|
| d.keys() | 返回所有的键信息(dict_keys) |
| d.values() | 返回所有的值信息(dict_values) |
| d.items() | 返回所有的键值对 |
| d.get(key, default) | 键存在则返回相应值,否则返回默认值default(None) |
| d.pop(key, default) | 键存在则返回相应值,同时删除键值对,否则返回默认值default |
| d.popitem() | 随机从字典中去除一个键值对,以元组(key,value)形式返回,同时将该键值对从字典中删除 |
| d.clear() | 删除所有的键值对,清空字典 |
①d.keys()的返回结果是Python的一种内部数据类型dict_keys
>>> dict1 = {1: '清清', 2: '楚楚', 3: '明明', 4: '白白'}
>>> print(dict1.keys(), type(dict1.keys()))
dict_keys([1, 2, 3, 4]) <class 'dict_keys'>
为了更好的使用返回结果,可以把dict_keys转换为列表类型
>>> dict1 = {1: '清清', 2: '楚楚', 3: '明明', 4: '白白'}
>>> dict1.keys()
dict_keys([1, 2, 3, 4])
>>> list(dict1.keys())
[1, 2, 3, 4]
②d.values()的返回结果是Python的一种内部数据类型dict_values
同理:
>>> dict1 = {1: '清清', 2: '楚楚', 3: '明明', 4: '白白'}
>>> dict1.values()
dict_values(['清清', '楚楚', '明明', '白白'])
>>> list(dict1.values())
['清清', '楚楚', '明明', '白白']
③d.items()的返回结果是Python的一种内部数据类型dict_items
同理:
>>> dict1 = {1: '清清', 2: '楚楚', 3: '明明', 4: '白白'}
>>> dict1.items()
dict_items([(1, '清清'), (2, '楚楚'), (3, '明明'), (4, '白白')])
>>> list(dict1.items())
[(1, '清清'), (2, '楚楚'), (3, '明明'), (4, '白白')]
*列表内,键值对以元组类型表示。【双值子序列,如[(1,‘a’)]】
其他:
判断一个键是否在字典中,in/not in。(检测的是键,不是值!)
>>> dict1 = {'name': '郭靖', 'age': 18, 'sex': '男'}
>>> 'name' in dict1
True
>>> 18 in dict1
False
字典的增删改查
【增:dic.[key] = value,dict.setdefault(key, value)】
①
>>> dict1 = {'name': '明明', 'age': 18, 'sex': '男'}
>>> dict1['score'] = 110
>>> print(dict1)
{'name': '明明', 'age': 18, 'sex': '男', 'score': 110}
②dic.setdefault(key,[default])向字典中添加key-value
如果这个key已经存在于字典中,则返回value,不会对字典有影响;如果不存在,则向字典中添加这个key,并设置value。
>>> dict1 = {'name': '明明', 'age': 18, 'sex': '男'}
>>> result = dict1.setdefault('height','1.8m')
>>> print(result)
1.8m
>>> print(dict1)
{'name': '明明', 'age': 18, 'sex': '男', 'height': '1.8m'}
【更新:dict1.update(dict2)】
①dict1.update(dict2)将其他字典的key:value更新到当前字典中
>>> dict1 = {'a':1}
>>> dict2 = {'b':2}
>>> dict1.update(dict2)
>>> print(dict1)
{'a': 1, 'b': 2}
【删:del dic[‘value’],dic.pop(key, default),dic.popitem();清空:dic.clear()】
①del dic[‘value’]关键字指定删除
>>> dict1 = {'a': 1, 'b': 2}
>>> del dict1['b']
>>> print(dict1)
{'a': 1}
# value注意加引号
>>> del dict1[a]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
②dic.pop(key, default)根据key来删除键值对,返回的值就是你删除的key对应的value(相当于取出那个key对应的value)
>>> d = {'1':'白白', '2':'涵涵', '3':'萌萌'}
>>> d.pop('2')
'涵涵'
>>> print(d)
{'1': '白白', '3': '萌萌'}
>>> d.pop('4','达达')
'达达'
>>> print(d)
{'1': '白白', '3': '萌萌'}
③dic.popitem()随机删除一个键值对,一般都会删除最后一个,有一个返回值,就是你删除的对象,结果是一个元组
>>> d = {'1':'白白', '2':'涵涵', '3':'萌萌'}
>>> d.popitem()
('3', '萌萌')
>>> print(d)
{'1': '白白', '2': '涵涵'}
④dic.clear()清空字典
>>> d = {'1':'白白', '2':'涵涵', '3':'萌萌'}
>>> d.clear()
>>> print(d)
{}
【查:】
①d.key()返回键;d.value()返回值;d.items()返回键值对
②in/not in 检测的是key
>>> d = {'1':'白白', '2':'涵涵', '3':'萌萌'}
>>> '1' in d
True
>>> '涵涵' in d
False
③d.get(key, default)检测的是key,返回对应的值。(可以和d.pop(key, default)比较)default可省略
>>> d = {'1':'白白', '2':'涵涵', '3':'萌萌'}
>>> d.get('1')
'白白'
>>> d.get('1', '白白')
'白白'
>>> d.get('1','涵涵')
'白白'
>>> d.get('4')
>>>
字典的遍历
通过key遍历:dict.keys()
补充:浅拷贝和深拷贝
PS: 做拷贝对象的必须是可变类型
浅拷贝:copy() 方法用来对字典进行潜复制。“直接引用”。
列表的id地址不改变(字典中的字典同理,不进行复制,id地址不变)
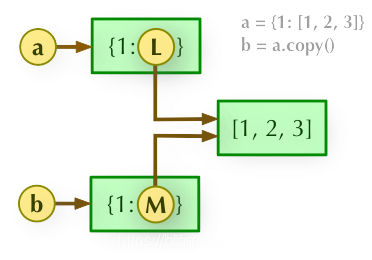
【 a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。】
深拷贝:deepcopy(),深拷贝将字典中的所有元素进行复制,形成新的id。“新建后再引用”。
两个字典中的列表的id地址改变(字典中的字典同理)
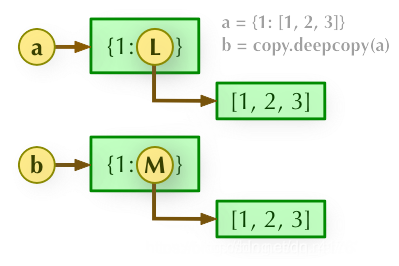
【a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。】
区别:浅拷贝只能对第一层的数据进行拷贝。如果第一层的数据也是可变数据类型,那么浅拷贝无法将其重新拷贝,形成新的id。
深拷贝则可以对所用类型的数据进行拷贝,形成一个新的id
import copy
d = {'1': [1, 2, 3]}
print(id(d['1']))
print(id(copy.copy(d['1'])))
print(id(copy.deepcopy(d['1'])))
输出:
2658061210624
2658060537408
2658060537408
字典的遍历
-
通过key来遍历
-
通过value来遍历
-
通过item(一项)来遍历
d = {'1': '白白', '2': '涵涵', '3': '萌萌'}
for k in d.keys():
print(d[k])
for v in d.values():
print(v)
for k, v in d.items():
print(k, ':', v)
输出:
白白
涵涵
萌萌
白白
涵涵
萌萌
1 : 白白
2 : 涵涵
3 : 萌萌
作业
6.1题
现在有 a = [1,2,3,4,5,6] 用多种方式实现列表的反转([6,5,4,3,2,1]) 并写出推导过程
# list.reverse()方法
>>> a = [1, 2, 3, 4, 5, 6]
>>> a.reverse()
>>> print(a)
[6, 5, 4, 3, 2, 1]
#切片
>>> a = [1, 2, 3, 4, 5, 6]
>>> a = a[::-1]
>>> print(a)
[6, 5, 4, 3, 2, 1]
#其他
#for循环
a = [1,2,3,4,5,6]
b = []
for i in a:
b.append(a[6-i])
print(b)
#排序
#sort()方法语法:
#list.sort(cmp=None, key=None, reverse=False)
#cmp -- 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
#key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
#reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
a = [1,2,3,4,5,6]
a.sort(reverse=True)
print(a)
6.2题
给用户9次机会 猜1 - 10 个数字随机来猜数字。
#我的做法
import random
num = random.randint(1, 10)
print("有个数字在1-10之间,你有9次机会,来猜猜看吧!")
i = 0
while i < 9:
i += 1
guess = eval(input(print("请输入你要猜的数字:")))
if guess > num:
print("你猜大了,你还有{}次机会,再猜猜看。".format(9-i))
elif guess < num:
print("你猜小了,你还有{}次机会,再猜猜看。".format(9-i))
else:
print("恭喜你在规定次数内猜对了!一共猜了{}次。".format(i))
break
else:
print("运气不好哦,你没有猜出来。我给的数字是{}。".format(num))
6.3题
有两个列表 lst1 = [11, 22, 33] lst2 = [22, 33, 44]获取内容相同的元素
#我的做法
lst1 = [11, 22, 33]
lst2 = [22, 33, 44]
for m in lst1:
if m in lst1:
print(m, end=' ')
#同学的好的做法:
li1 = [11, 22, 33]
li2 = [22, 33, 44]
for i in range(3):
if li1[i] in li2:
print(li1[i], end=' ')
6.4题
现在有8位老师,3个办公室,要求将8位老师随机的分配到三个办公室中
# 我第一次做的
import random
num1 = random.randint(1, 4)
num2 = random.randint(1, 8-num1)
num3 = 8-num1-num2
print("有{}位老师被分进第一间办公室,有{}位老师被分进第二间办公室,有{}位老师被分进第三间办公室。".format(num1, num2, num3))
# 我第二次做的(我想知道每一位老师都被分进了哪一间办公室)
import random
m = 0
while m < 8:
n = random.randint(1, 3)
if n == 1:
m += 1
print("第{}位老师被分入了第{}个办公室".format(m, n))
elif n == 2:
m += 1
print("第{}位老师被分入了第{}个办公室".format(m, n))
else:
m += 1
print("第{}位老师被分入了第{}个办公室".format(m, n))
# 我第三次做的(我想准确的知道哪位老师,进了哪间办公室)
import random
office = ["1-1", "1-2", "1-3"]
teacher = ["王老师", "李老师", "白老师", "高老师", "赵老师", "孙老师", "周老师", "孟老师"]
for m in range(0, 7):
n = random.randint(0, 2)
print("{}被分入了{}办公室".format(teacher[m], office[n]))
现在有8位老师,3个办公室,要求将8位老师随机的分配到三个办公室中
新增条件:为了使得空间得到充分利用,要求一个办公室至少分给2或3个人。
# 新条件下,只有三种模式[3,2,3],[2,3,3],[3,3,2]
import random
# office = ["1-1", "1-2", "1-3"]
teacher = ["王老师", "李老师", "白老师", "高老师", "赵老师", "孙老师", "周老师", "孟老师"]
module = random.randint(1, 3)
for t in range(0, 7):
# 模式[3,2,3]
if module == 1:
i = random.randint(0, 1)
if i == 0:
print("{}被分入了1-2办公室".format(teacher[t]))
else:
j = random.randint(0, 1)
if j == 0:
print("{}被分入了1-1办公室".format(teacher[t]))
else:
print("{}被分入了1-3办公室".format(teacher[t]))
# 模式[2,3,3]
elif module == 2:
i = random.randint(0, 1)
if i == 0:
print("{}被分入了1-1办公室".format(teacher[t]))
else:
j = random.randint(0, 1)
if j == 0:
print("{}被分入了1-2办公室".format(teacher[t]))
else:
print("{}被分入了1-3办公室".format(teacher[t]))
# 模式[3,3,2]
else:
i = random.randint(0, 1)
if i == 0:
print("{}被分入了1-3办公室".format(teacher[t]))
else:
j = random.randint(0, 1)
if j == 0:
print("{}被分入了1-1办公室".format(teacher[t]))
else:
print("{}被分入了1-2办公室".format(teacher[t]))
7.1题
a = {“name”:“123”,“data”:{“result”:[{“src”:“python1”},{“src”:“python2”},{“src”:“python3”}]}} 找到python1/python2/python3
a = {"name": "123", "data": {"result": [{"src": "python1"}, {"src": "python2"}, {"src": "python3"}]}}
for i in range(0, 3):
print(a["data"]["result"][i]['src'])
7.2题
有如下值列表[11,22,33,44,55,66,77,88,99,90], 将所有大于66的值保存至字典的第一个key的值中,将小于66值保存至第二个key的值中。
w
lst = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
k1 = []
k2 = []
dic = {'key1': k1, 'key2': k2}
i = 0
while i < 9:
i += 1
if lst[i] > 66:
k1.append(lst[i])
elif lst[i] < 66:
k2.append(lst[i])
print(dic)
#同学的做法
lst = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
k1 = []
k2 = []
dic = {}
for i in lst:
if i > 66:
k1.append(i)
elif i < 66:
k2.append(i)
else:
continue
dic.setdefault('key1', k1)
dic.setdefault('key2', k2)
print(dic)

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









