






根据DGL 来做的,按照DGL 实现来讲述
1. GCN Cora 训练代码:
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(GCN, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats)
self.conv2 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feat):
h = self.conv1(g, in_feat)
h = F.relu(h)
h = self.conv2(g, h)
return h
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
features = g.ndata["feat"]
labels = g.ndata["label"]
train_mask = g.ndata["train_mask"]
val_mask = g.ndata["val_mask"]
test_mask = g.ndata["test_mask"]
for e in range(100):
# Forward
logits = model(g, features)
# Compute prediction
pred = logits.argmax(1)
# Compute loss
# Note that you should only compute the losses of the nodes in the training set.
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print(
f"In epoch {e}, loss: {loss:.3f}, val acc: {val_acc:.3f} (best {best_val_acc:.3f}), test acc: {test_acc:.3f} (best {best_test_acc:.3f})"
)
if __name__ == "__main__" :
dataset = dgl.data.CoraGraphDataset()
# print(f"Number of categories: {dataset.num_classes}")
g = dataset[0]
g = g.to('cuda')
model = GCN(g.ndata["feat"].shape[1], 16, dataset.num_classes).to('cuda')
train(g, model)
2. 其中的GraphConv 类的DGL源码分析:
先粘贴出DGL(DGL 是0.9.1的CUDA 版本实现)对 GCN论文中提出的图卷积类的实现吧:
源码为只大致在:(看得出我这个是有个conda 名字是 pytorch36GPU,你改成自己的就行)![]()
我就贴点重要的,不重要的不贴了
class GraphConv(nn.Module):
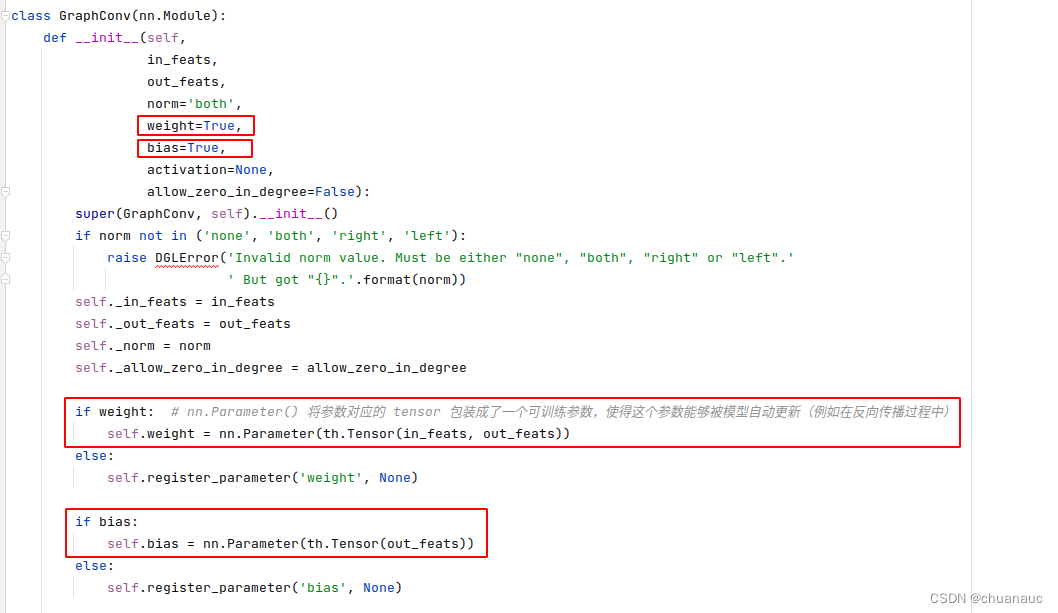
再一开始的初始化中就确定了,根据 GraphConv 的参数确定了要训练的参数 tensor W 和 tensor bais :
这些参数被包装成 nn.Parameters 的类型,方便反向传播的时候更新
(1) DGL 实现消息传递时的NodeBatch 和 EdgeBatch :
给出这张图:
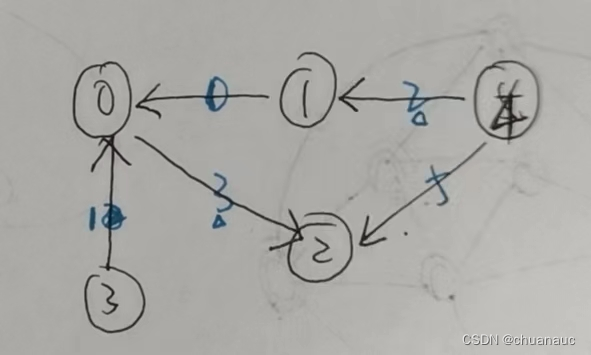
当面对的是一个有向图(DGL默认是有向图):
有入边的点有:节点0,1,2
在消息传递的时候,DGL会找出有入边的节点,并将他们划分到不同的NodeBatch中去
例如上图,就可以把 节点1 分给 NodeBatch1 , 把节点0,2 分给 NodeBatch2
然后根据这些点的入边,把边也根据NodeBatch划分为对应的 EdgeBatch,
例如,按照上述的划分方法,那么 NodeBatch1 对应的 EdgeBatch1 的边为 [节点4 -> 节点1 ]
NodeBatch2 对应的 EdgeBatch2 的边为 [节点1 -> 节点0 ] , [节点3 -> 节点0 ] , [节点0 -> 节点2 ], [节点4 -> 节点2 ]
给出样例代码,配合输出来解释:
import dgl
import torch
import dgl.function as fn
def copyer(edges) :
print("==" * 10, "copyer()")
print("edges.edges():", edges.edges()) # 表明该batchEdge的节点都有哪些个
return {'m': edges.data['efeat']}
def reducer(nodes):
print("==" * 10, "reducer()")
print("mailbox:", nodes.mailbox)
print("nodes.data :", nodes.data)
print("nodes.nodes :", nodes.nodes()) # 表明该batchNode的节点都有哪些个
return {'n': nodes.mailbox['m'].sum(1)}
if __name__ == "__main__" :
g = dgl.graph(([1, 3, 4, 0, 4], [0, 0, 1, 2, 2]))
g.ndata['x'] = torch.randn(g.num_nodes(),2)
print(g.ndata['x'])
g.ndata['nfeat'] = torch.tensor([11,22,33,44,55])
g.edata['efeat'] = torch.tensor([666,222,333,444,555])
g.update_all(copyer, reducer)
print(g.ndata['n'])
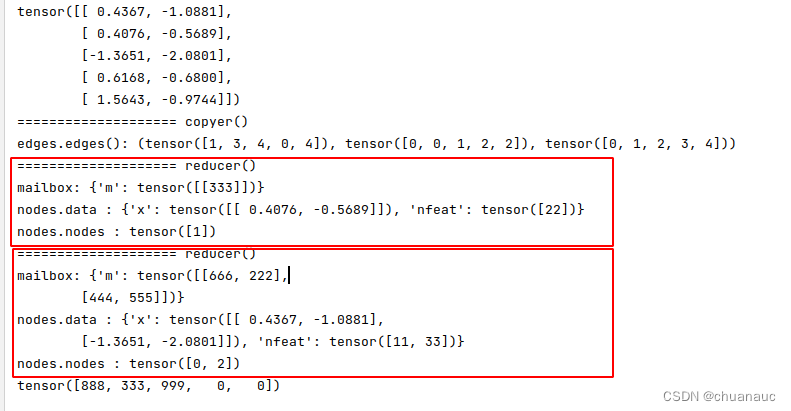
这是输出的内容: 可以看到,总共有3个入边节点,就划分成了2个nodeBatch (划分方式就是位上面举出的例子) :因此gather_all()函数就会执行两遍 reducer()函数
最后输出的g.ndata['n'] 的内容赋和理解:
即:对于节点 0 , 获得 [节点1 -> 节点0 ] :666 , [节点3 -> 节点0 ] :222 两条边上的信息(特征数值)加和:因此 666+222=888
同样的,节点 1 ,获得 [节点4 -> 节点1 ] :333 这条边上的信息(特征数值),因此值为 333
同样的,节点 2 ,获得 [节点0 -> 节点2 ], [节点4 -> 节点2 ] 两条边上的信息(特征数值)加和:因此 444+555=999
而,节点3,节点4 由于没有入边,因此,无法获得边的信息(特征数值)加和:因此,值为 0
解释一下 update_all() 函数:
之所以要解释 update_all() 函数,是因为,这个函数表示了DGL 关于聚合拓扑图上消息的实现方法:
它位于:![]()
update_all()函数 将两个重要的 边上消息聚合函数message_function() 和 节点上消息聚合函数 reduction_function() 作为自己函数的参数,将两个操作以DGL自己实现的优化方式加以顺序执行
我直接粘贴了DGL对于update_all()函数的注释,如下:

这个update_all()函数的Note也很重要:

之所以只解释 update_all()函数的注释,是因为,他的函数实现我没看(懂),麻了,之后再说吧,期待有一天对于这种工程代码也能顺利拿下
分别进一步解释一下 message_function() 和 reduce_function() :
如下图所示,DGL定义了两种消息传递的方法,在边上进行汇聚处理的函数 叫 “message_function()” ,在节点上进行汇聚处理的函数 叫 "reduce_function()" 。

DGL自己实现了一些常用的 message_function() 和 reduce_function() ,但是,如果想要理解DGL上的消息聚合(或是理解GCN上的节点特征如何经由边聚合,点聚合 最后更新得到新的节点特征的)[我们使用的样例代码 Cora 数据集的边上没有特征,因此,整个数据集都是在对节点上的特征经由边来传递,在节点上聚合]
接下来的内容来源于下图所示的文档,我大致翻译了一下,并加入了我的理解和对应的代码介绍:

(1)message_function():
在DGL中,message_function() 只接受 有且只有一个参数 `edges` (实现自定义message_fuction()时就,你也可以将参数写为 nodes ,但是没用,你其实只是将edges 在这个函数里面重名为了 nodes,其实调用的还只能是 edges 的属性 ),这是一个 EdgeBatch 的实例。由于message_function()一般就是定义好并且在update_all()函数中作为参数使用,因此,DGL在实现消息传递框架时,就会提供给 message_function() 这样的一个参数: edges ,edges 表示在所指定的拓扑图上执行消息传递所涉及的全部边。 【 { 这个疑问之后会再出一个minibatch的文章训练方法,来向西指出来}这里会有 minibatch训来那所以不一定edges值的是整张图的全部边,或 这是一个异构图因此会有不同种类的边,这些情况都存在,但现在面对的是整图处理的GCNfullbatch训练,所以都先缓缓】 edges 有 src、 dst 和 data 共3个成员属性, 分别用于访问源节点、目标节点和边的特征。因此,当我们想自己设计自己的UDF_message_function()的时候,就可以使用到这个参数edges实例的一些内容啦
因此,message_function() 的函数格式是这样的:
def UDF_message_fuction(edges) :
# 具体的函数内容
return {'dst_mailbox_attr' : XXXXXXX }
## 最后生成的这个字典类型时,存储到 涉及的所有边 对应的 **src节点** 的mailbox属性中了举个例子,我们以 copy_u() 这个message_function这个DGL 已经实现好的(Built_In Function)来举例: dgl.function.copy_u — DGL 1.1.3 documentation
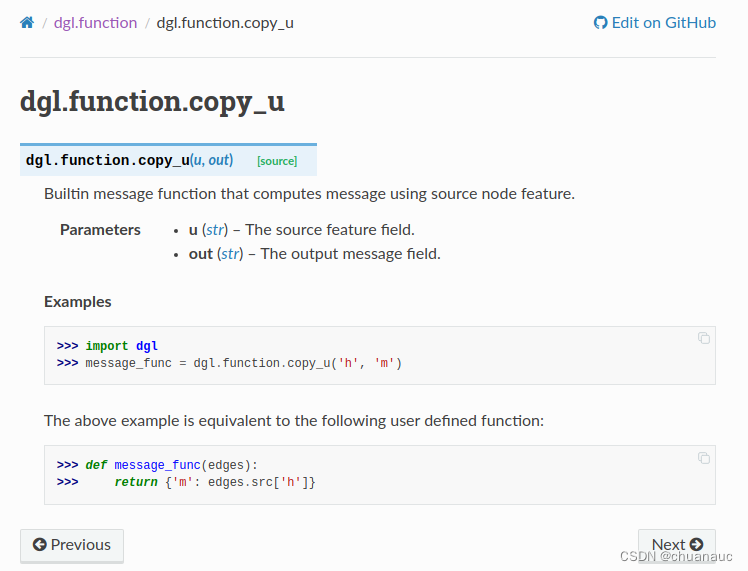
可以看出,如果我们想自己实现这个copy_u() 函数,需要使用到 edges.src['h'] 这个东西,这是因为,这个copy_u的函数含义是 :通过源节点src的特征来计算消息(message) 。
因此,它会返回一个字典,字典的键是 ‘m’ (字典的键的名字你自己随意取,你取名字为 :`{ 'kkkk' : edges.src['nfeat'] }` 也没关系的),之所以取名字为 'm' 是因为这个 字典返回值 会被加入到 graph.ndata.mailbox 这个实例中 (graph.ndata.mailbox 也是一个字典类型的实例)。
我们使用代码:`print("edges.src['nfeat']:",edges.src['nfeat'])`输出一下edges.src['nfeat']
输出的内容是:edges.src['nfeat']: tensor([22, 44, 55, 11, 55])
解释一下,首先这是一个len为5的tensor,代表着图g中的5条边对应的节点的src的特征,即,若更直观的来看,其实是[节点1的特征,节点3的特征,节点4的特征,节点0的特征,节点4的特征] 组成的tensor :为什么是以这样的顺序去组织图g上的节点特征呢?因为,这些节点分别作为src指向对应的dst,换句话说,GCN的聚合图上邻居信息,不就是dst聚合指向该dst节点的src节点的特征嘛,因此,现在列出这些要被reduce_function()聚合的节点特征,方便下一步reduce_function()来处理。
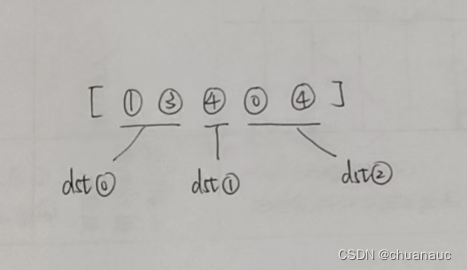
但是,我们在输出 reduce_function()这个函数的nodes.mailbox['m'] 内容时,发现,相较于message_function() 中的 edges.src['nfeat'] 的内容,nodes.mailbox['m'] 内容发生了改变。我的猜测是:update_all()函数 对 reduce_function()函数的 返回字典内容 nodes.mailbox['m'] 进行了一些处理,将原本的一维tensor进行划分,划分依据是:根据dst节点的入度不同,将dst节点进行划分,并分配给不同度数组dst节点其用于执行aggragate操作所需的src节点特征的tensor
由于我没有详细读update_all()函数的具体实现,因此下述内容时为根据输出的合理猜测(有时间我会读下并且补充上去的)
我们根据测试代码和输出来验证下我们的说法,并配合我们的例子 图g 进行举例:
我们在reduce_function()中利用参数nodes进行输出,发现nodes.mailbox 中的内容已经被 update_all()修改为入下图所示:

将图上的dst根据入度不同划分为两个组(入度为1的组有一个dst节点:节点1 ;入度为2的节点组有2个节点:节点0,节点2)

而最后,将src的节点分组并将其特征对应的tensor划分好维度后,update_all()函数会将新的图上src节点的特征加入到 nodes 实例的 mailbox属性中了
顺理成章的,我们继续介绍 reduce_function() 这个函数:
(2)reduce_function() :
reduce_function() 只接受有且只有一个参数 nodes (实现自定义reduce_fuction()时就,你也可以将参数写为 edges ,但是没用,你其实只是将 nodes 在这个函数里面重名为了 edges,其实调用的还是 nodes 的属性,与 message_function() 同理,不信可以自己改来试试 ),这是一个 NodeBatch 的实例, 在消息传递时,它被DGL在内部生成以表示一批节点。 nodes 的成员属性 mailbox 可以用来访问节点收到的消息。可以使用DGL的Build_In Function,例如 sum、max、min 等 来处理这些 mailbox 中的消息。
我们根据一个DGL 中的 Build_In reduce_function() 的实现 sum() 函数为例来解释:
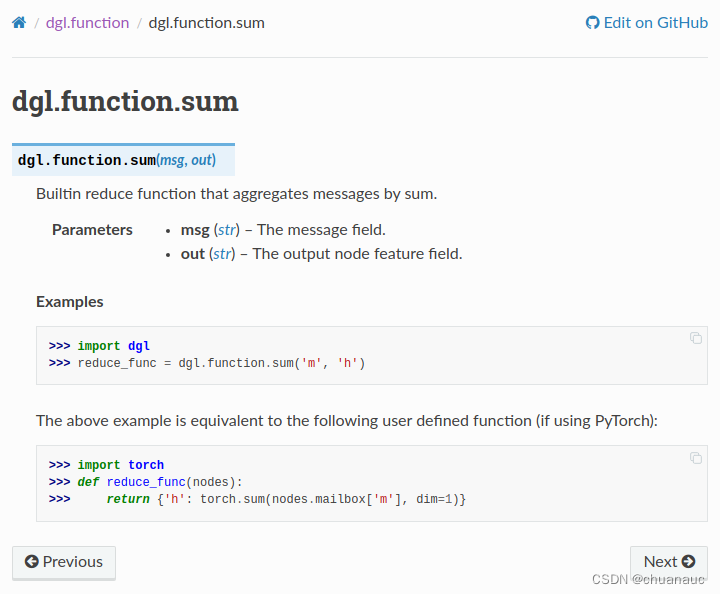
可以看出,sum() 的目的是将消息累加 :承接刚才的 经由 update_all() 处理过后的nodes中的mailbox['m']的内容:(如例子中的图g所示,会掉用两次reducer()函数,输出每次调用reduce()中的mailbox[‘m’]的内容)

可以看出, nodes.mailbox['m'].sum(1) 语句就是将 dst节点对应的src节点的特征值加和并以dst节点为一个维度地返回
而后,这个 键为 'h' ,值为 聚合各个src节点特征的dst节点的tensor 会作为字典返回,这个字典被update_function() 接收,用于实现最后的更新操作 。
(3)update_function() :
update_function() 函数用于 接受 reduce_function() 处理后生成的nodes,执行消息传递的最后一步,将当前节点的特征相结合,并将输出作为节点的新特征。
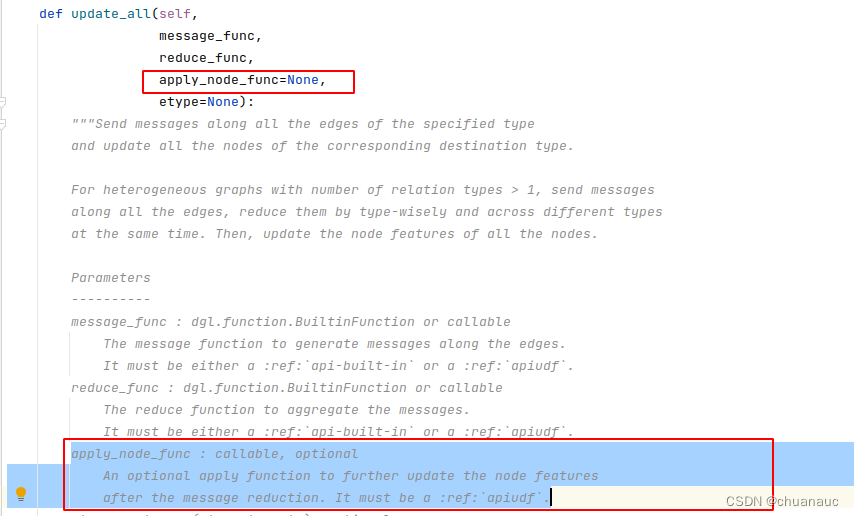
更新函数是一个可选择的参数,用户也可以不使用它,而是在 update_all 执行完后直接对节点特征进行操作。 由于更新函数通常可以用纯张量操作实现,所以DGL不推荐在 update_all 中指定更新函数,在update_all函数中,update_function() 也是赋值为了 None

在DGL的update_all() 函数的注释里面也有体现:(apply_node_func 就是 update_function() 函数)
最后,update_all() 将最终处理完的字典内容 返回给了图g的ndata中,作为属性 'h' 可以被 `g.ndata['h']` 访问到
于是,我们可以总结一下:
update_all() 函数中,处理消息由message_function()实现,将处理后的消息存放 nodes.mailbox中
reduce_function() 则是 聚合 nodes.mailbox 中的消息
最后,处理后的各个节点中的内容 会存放到 图g 的 ndata这个属性中
验证代码如下:
import dgl
import torch
import dgl.function as fn
from dgl.utils.internal import expand_as_pair
def copyer(edges) :
# 与 : `aggregate_fn = fn.copy_src('h', 'm')` 等价 ; 与 aggregate_fn = fn.copy_u('h', 'm') 也等价
print("==" * 10, "copyer()")
print("edges.edges():", edges.edges()) ## 输出edges实例中包含的所有边
print("@@edges.src['nfeat']:",edges.src['nfeat'])
return {'m': edges.src['nfeat']}
def reducer(nodes):
print("==" * 10, "reducer()")
print("mailbox:", nodes.mailbox)
print("nodes.data :", nodes.data)
print("nodes.nodes :", nodes.nodes()) # 表明该batchNode的节点都有哪些个
print("type of mailbox:", type(nodes.mailbox) ) # graph.ndata.mailbox 也是一个字典类型的实例
print("nodes.mailbox['m'] 中的内容是什么?:", nodes.mailbox['m'] )
return {'h': nodes.mailbox['m'].sum(1)} # 若这里的属性设置为'kkk',即:return {'kkk': nodes.mailbox['m'].sum(1)}
# 那就该输出:print("g.ndata['kkk'] :", g.ndata['kkk'])
if __name__ == "__main__" :
g = dgl.graph(([1, 3, 4, 0, 4], [0, 0, 1, 2, 2]))
g.ndata['x'] = torch.randn(g.num_nodes(),2)
print(g.ndata['x'])
g.ndata['nfeat'] = torch.tensor([11,22,33,44,55])
g.edata['efeat'] = torch.tensor([111,222,333,444,555])
feat_src, feat_dst = expand_as_pair(g.ndata['x'], g)
print("feat_src: ", feat_src.size(),"")
print(feat_src)
print("feat_dst: ", feat_dst.size())
print(feat_dst)
g.update_all(copyer, reducer)
print("g.ndata['h'] :", g.ndata['h'])
# print("g.ndata['m'] :", g.ndata['m']) # 会报错,因为mailbox的属性不存在于ndata中,与g.ndata['h']是两个东西,不能直接输出
GraphConv层的DGL 实现 :
我们能理解为:
GCN 就是将原图加了自环,然后将所有的指向dst的节点的特征加和(由于图上加了自环,因此也加入了自己本节点的特征),这个新生成的节点的特征乘以W再加上bais 就是 一层GraphConv的输出结果
那么,全图的GCN 到底在训练什么呢?
训练 相乘的参数W 和 bais
全图训练 是什么意思呢 ?
因为全图中有些点是label 点,有些不是,label点中又分为 train 点 val点 test 点,虽然所有节点都参与计算,所有节点的feat都与W相乘 (每一次训练都是全图的所有节点 与 W 相乘 后加 bais ),但是,只有train的节点计算出的结果predict_y 才会与真实的 y 值相比较计算出loss用于更新 W 和 bais ,val 节点和test节点计算出的loss只用于展示,不用于更新 W 和 bais
全图(使用所有的节点和边的特征)上的训练只需要使用上面定义的模型进行前向传播计算,并通过在训练节点上比较预测和真实标签来计算损失,从而完成后向传播。

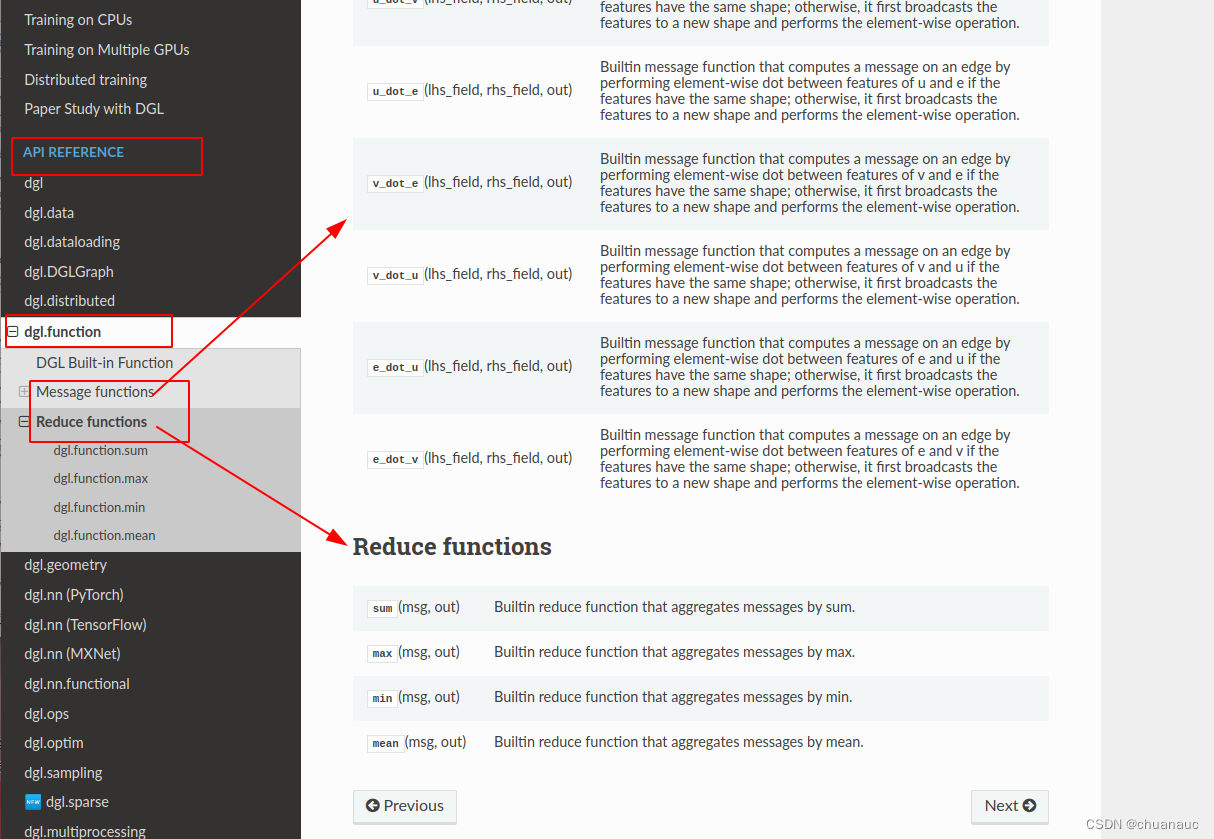
由于DGL经常改版文档且不具有连贯性,,,,我把一些常用的助于理解的内容直接截图,需要就自己找一下吧:
(1)在哪里找到 message_function() 和 reduce_function() 的API 位置截了个图 :
一些DGL 的基础使用也补充在这里吧:
import dgl
import dgl.function as fn
import torch
g = dgl.graph(([0, 0, 1, 5], [1, 2, 2, 0])) # 6个节点,4条边
g.ndata['x'] = th.ones(g.num_nodes(), 3) # 长度为3的节点特征
g.edata['x'] = th.ones(g.num_edges(), dtype=th.int32) # 标量整型特征
print(g)
''' 输出内容:
Graph(num_nodes=6, num_edges=4,
ndata_schemes={'x' : Scheme(shape=(3,), dtype=torch.float32)}
edata_schemes={'x' : Scheme(shape=(,), dtype=torch.int32)})
'''
# 不同名称的特征可以具有不同形状
g.ndata['y'] = th.randn(g.num_nodes(), 5)
g.ndata['x'][1] # 获取节点1的特征
g.edata['x'][th.tensor([0, 3])] # 获取边0和3的特征一些基础python torch.tensor语法概述:
1.
if __name__ == "__main__" :
XXXXXXX
XXXXXXX当我们直接执行这个脚本时,__name__属性被设置为__main__,因此满足if条件,语句块中的代码被调用。
但如果我们将该脚本作为模块导入到另一个脚本中,则__name__属性会被设置为模块的名称(例如"example"),语句块中的代码不会被执行。
2.
# Compute prediction
pred = logits.argmax(1) # 返回沿着第一个维度(即维度索引为1)的最大值的索引。
# 即,加入有5个样本,每个样本有3个维度的评分,那么就会给出没个样本3中维度评分最高的哪个维度的索引序号
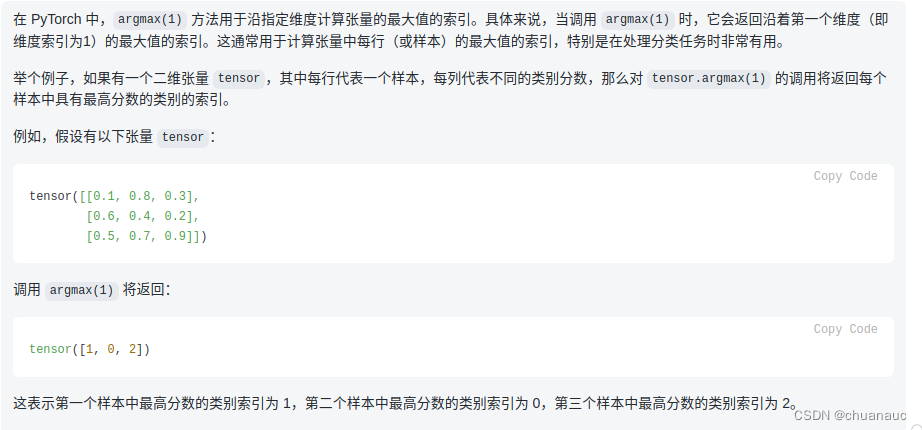
3. numpy 关于 tensor 的一个用法:
在DGL 中使用一串 True 或 False 组成的 一维tensor 来标识 这个节点到底是属于 train test val 哪一类
train_mask = g.ndata["train_mask"]
val_mask = g.ndata["val_mask"]
test_mask = g.ndata["test_mask"]而后,由于对于torch中的tensor来说:
就可以:select_label_tensor = labels[train_mask] 了
import torch
# 定义一个Tensor
tensor = torch.tensor([1, 2, 3, 4, 5])
# 定义一个布尔数组,选择索引为1和4的元素
mask = torch.tensor([False, True, False, False, True])
# 通过布尔索引选择元素
selected_tensor = tensor[mask]
print(selected_tensor) # tensor([2, 5])顺便,查看一个变量到底是什么类型可以使用 type() 函数:
train_mask = g.ndata["train_mask"]
print(type(train_mask))
# 输出为:
# <class 'torch.Tensor'>4. 关于定义的模型 GCN 的 .parameters() 这个属性 :
由于 GCN 类继承了 nn.Module 类 ,如下代码示:
class GCN(nn.Module):
def XXXXXXnn.Module类是所有神经网络模型的基类,它提供了一些默认的功能,包括 parameters() 方法,在 nn.Module 类内部,parameters() 方法被实现为递归地遍历模型中的所有子模块,获取子模块的参数并返回。
在这个的代码中,GCN 类的父类是 nn.Module,所以 model.parameters() 会返回 GCN 类中定义的所有参数
我们可以通过下述两种办法来查看一个模型的情况:
print(model) # 用于输出模型
# 输出内容为:
# GCN(
# (conv1): GraphConv(in=1433, out=16, normalization=both, activation=None)
# (conv2): GraphConv(in=16, out=7, normalization=both, activation=None)
# )
或者更细致一点描述出在模型中被训练的参数有哪些:
在 PyTorch 中,可以通过 parameters() 方法来获取模型中所有需要优化的参数。这个方法会返回一个包含所有参数的生成器(generator),可以通过遍历这个生成器来查看所有的参数。
for name, param in model.named_parameters():
print(name, param.shape)
# 输出内容:
# conv1.weight torch.Size([1433, 16])
# conv1.bias torch.Size([16])
# conv2.weight torch.Size([16, 7])
# conv2.bias torch.Size([7])5. 代码中什么是实例?
loss_fn = torch.nn.MSELoss()
loss = loss_fn(y_pred, y_true) 是否可以合并为一个代码,如下所示?
loss = torch.nn.MSELoss(y_pred, y_true)回答是:不可以。因为之所以要来这一步是因为如下图所是 MSELoss是一个类,类必须实例花才能调用它的函数

那就引申出一个问题,这个 loss = loss_fn(y_pred, y_true) 到底是再调用MSELoss类中的什么函数呢?
答案是:MSELoss类中的forward() 函数,=
但是为什么代码不显示为 loss = loss_fn.forward (y_pred, y_true) ?
【回答】:在PyTorch中,loss_fn(y_pred, y_true) 这个语句调用了 MSELoss 类的父类 torch.nn.Module 中的 __call__ 方法。__call__ 方法是 Module 类的一个魔法函数,用于将实例化后的对象作为函数直接调用。调用了 Module 类的 __call__ 方法,该方法内部会调用 forward() 方法,其中包含了计算均方误差损失的逻辑。
因此,loss_fn(y_pred, y_true) 语句的作用等同于 loss_fn.forward(y_pred, y_true)。
给出一个伪代码,大致就是关于 nn.Module 这个弗雷中实现了 __call__方法,由 MSELoss 子类继承,在将 子类MSELoss实例话后可以直接通过调用 __call__ 方法来使用魔法函数的特性(将实例化的对象作为函数直接调用)
class Module_Simple:
def __init__(self):
pass
def __call__(self, *input, **kwargs):
output = self.forward(*input, **kwargs)
return output
def forward(self, *input):
raise NotImplementedError
class MSELoss_Simple(Module_Simple):
def __init__(self, input_dim, output_dim):
super(MSELoss_Simple, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
x = self.linear(x)
return x
input_dim = 10
output_dim = 5
input_data = torch.randn(3, input_dim)
model = MyModel(input_dim, output_dim)
output = model(input_data) # 调用 model.forward(input_data) 方法
6. 差一个 梯度 是怎么求出来的?
7. 子类继承父类,并显示使用父类的构造函数,语法是: super(ThisClassName).__init__()
在 Python 中,子类在继承父类的同时可以添加自己的属性和方法。
当子类继承父类时,在子类的构造函数中需要显式地调用父类的构造函数以初始化父类的属性,这可以通过 super() 函数来实现。
super() 函数的作用是返回一个临时对象,该临时对象是当前类继承链上的下一个类。通过这个临时对象,可以调用任何在继承链上的父类中定义的方法。具体来说,super(GraphConv, self) 会返回 GraphConv 类的父类 nn.Module 的实例 ,使得 GraphConv 类可以使用父类中定义的一些方法、属性等,如自动求导和优化器。
8. 函数赋值语法:
这个语法在python中很常见,但是对于我这个C++ 选手来说太痛了,不过没关系,接受一下:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









