







WHUT第三周训练整理
写在前面的话:我的能力也有限,错误是在所难免的!因此如发现错误还请指出一同学习!
索引
(这里的难度分类只是针对新生!)
一、easy:01、02、04、06、08、09、10、11、12、13、19、20
二、medium:03、06、07、14、16、17、18
三、hard:05
四、乱入的搜索:15
本题解报告大部分使用的是C++语言,在必要的地方使用C语言解释。
一、easy
1001:将字符串中连续相同的字符子串转换成“kX”的格式
分析:按照题目的意思模拟就可以了,需要注意的是发现很多同学都没注意到“子串”的问题,就是只有连续的相同字母才可以合并!AABBAA应该转换成2A2B2A而不是4A2B!
Code:
int main()
{
int T;
cin >> T;
while (T--)
{
string str;
cin >> str;
int num = 0; // num保存连续的长度
char ch; // ch为当前连续的字母
for (int i = 0; i < str.length(); i++)
{
if (i == 0) // 确定第一个字母
num = 1, ch = str[i];
else
{
if (str[i] != ch) // 如果不相同则输出
{
if (num == 1) // 注意1的情况不需要输出
cout << ch;
else
cout << num << ch;
num = 1; // 重置长度和字母
ch = str[i];
}
else // 否则计数++
{
num++;
}
}
}
if (num == 1) // 注意结束之后末尾还有一部分没处理完
cout << ch;
else
cout << num << ch;
cout << endl;
}
return 0;
}
1002:将段落中的每个单词翻转
分析:可以选择C++调库,也可是用C语言自己手动写,我下面都放出来。
Code:
(C)
const int MAXN = 1000+10;
char str[MAXN];
void solve(int st, int ed){ // 翻转str的[st, ed]部分
int len = ed-st+1;
for(int i = 0; i < len/2; i++){
char ch = str[st+i];
str[st+i] = str[ed-i];
str[ed-i] = ch;
}
}
int main()
{
int T;
scanf("%d", &T);
getchar(); // 在使用gets或者getline时注意在外面getchar
while (T--)
{
gets(str);
int st = 0;
for(int i = 0; i <= strlen(str); i++){ // 注意这里利用了字符串以'\0'结尾的特征,位于i==strlen(str)的位置
if(str[i] == ' ' || str[i] == '\0'){
solve(st, i-1);
st = i+1;
}
}
printf("%s\n", str);
}
return 0;
}
(C++)
int main()
{
int T;
cin >> T;
getchar();
while (T--)
{
string str;
getline(cin, str);
stringstream ss(str); // 利用stringstram将一整行字符串拆分成一个个的单词
int first = 1;
while(ss >> str){
if(first) first = 0;
else cout << " ";
reverse(str.begin(), str.end()); // 调库翻转
cout << str;
}
cout << endl;
}
return 0;
}
1004:蛇形字符串还原
分析:我的做法可能比较直接比较笨,直接还原出这个矩阵,然后一列一列地输出即可。
Code:
char g[MAXN][MAXN];
int main()
{
while(cin >> n, n){
string str;
cin >> str;
for(int i = 0; i < str.length()/n; i++){
if(i%2 == 0){ // 偶数正向存
for(int j = 0; j < n; j++){
g[i][j] = str[i*n+j];
}
}
else{ // 奇数反向存
for(int j = 0; j < n; j++){
g[i][n-j-1] = str[i*n+j];
}
}
}
for(int i = 0; i < n; i++){ // 一列一列输出
for(int j = 0; j < str.length()/n; j++){
cout << g[j][i];
}
}
cout << endl;
}
return 0;
}
1008:统计字符串中数字字符出现的次数
分析:很简单,大家都会做,不多说了,上代码。
Code:
int main()
{
int n;
cin >> n;
for(int i = 0; i < n; i++){
string str;
cin >> str;
int cnt = 0;
for(int j = 0; j < str.length(); j++){
if(str[j] >= '0' && str[j] <= '9') cnt++;
}
cout << cnt << endl;
}
return 0;
}
1009:判断字符串是否是C的合法标识符
分析:合法的C标识符满足:
1.以下划线或者字母开头
2.只能包含数字、字母以及下划线
Code:
int main()
{
int n;
cin >> n;
getchar(); // 依旧在getline和gets之前要getchar
while(n--){
string str;
getline(cin, str);
// 开头只能是下划线或者字母,isalpha函数判断是否是字母
if(str[0] != '_' && !isalpha(str[0])){
cout << "no" << endl;
continue;
}
int ans = 1;
// 内容只能包括下划线、字母以及数字,isalnum函数判断是否是字母或者数字
for(int i = 0; i < str.length(); i++){
if(str[i] == '_' || isalnum(str[i])) continue;
ans = 0;
break;
}
if(ans) cout << "yes" << endl;
else cout << "no" << endl;
}
return 0;
}
1010:在字符串中找到最大字母往后插入字符串"(max)"
分析:先找到最大元素,再遍历一遍用一个新的字符数组或者字符串保存插入"(max)"后的字符串。
Code:
int main()
{
string str;
while (cin >> str)
{
char ch; // 保存最大字符
for (int i = 0; i < str.length(); i++)
{
if (i == 0)
ch = str[i]; // 给定第一个值
else
{
if (str[i] > ch) // 更新
ch = str[i];
}
}
string ans = ""; // 新串用来保存结果
for(int i = 0; i < str.length(); i++){
ans += str[i];
if(str[i] == ch) ans += "(max)"; // 如果是最大字符,则插入
}
cout << ans << endl;
}
return 0;
}
1011:将英文句子中每个单词的首字母改成大写
分析:一行一行的读入字符串,拆分出每个单词,将第一个字母改成大写,即减去32,在acsii码中大写字母的值 = 小写字母的值-32。
下面给出C++调库的代码以及C语言的常规写法代码。
Code:
(C)
const int MAXN = 100+10;
char str[MAXN];
int main()
{
while(gets(str)){
for(int i = 0; i < strlen(str); i++){
if(i == 0 || str[i-1] == ' '){ // 确定当前字符是否为首字母
if(str[i] >= 'a' && str[i] <= 'z'){ // 判断是否为小写字母
str[i] -= 32; // 转换成大写字母
}
}
}
printf("%s\n", str);
}
return 0;
}
(C++)
int main()
{
string str;
while(getline(cin, str)){
stringstream ss(str);
int first = 1;
while(ss >> str){ // 一整行拆分成单词
str[0] = toupper(str[0]); // 调库转成大写字母
if(first) first = 0; // 控制空格
else cout << " ";
cout << str;
}
cout << endl;
}
return 0;
}
1012:统计每个元音字母在字符串中出现的次数"
分析:也很简单,大家都做,上代码。
Code:
int main()
{
int T;
cin >> T;
getchar(); // getline和gets之前要getcahr
while (T--)
{
string str;
getline(cin, str);
int cntA = 0, cntE = 0, cntI = 0, cntO = 0, cntU = 0;
for (int i = 0; i < str.length(); i++)
{
// 保险起见,我先把字母转换成小写了
if (tolower(str[i]) == 'a')
cntA++;
else if (tolower(str[i]) == 'e')
cntE++;
else if (tolower(str[i]) == 'i')
cntI++;
else if (tolower(str[i]) == 'o')
cntO++;
else if (tolower(str[i]) == 'u')
cntU++;
}
cout << "a:" << cntA << endl;
cout << "e:" << cntE << endl;
cout << "i:" << cntI << endl;
cout << "o:" << cntO << endl;
cout << "u:" << cntU << endl;
if(T) cout << endl; // 控制输出块之间的空行
}
return 0;
}
1013:判断一个密码是否是安全密码
分析:还是很简单,按照题目的意思来检查就可以了,看代码。
Code:
int main()
{
int T;
cin >> T;
while (T--)
{
string str;
cin >> str;
int flag1 = 0, flag2 = 0, flag3 = 0, flag4 = 0, cnt = 0; // 分别表示四种要求是否被满足,以及满足的组数
for (int i = 0; i < str.length(); i++)
{
if (str[i] >= 'a' && str[i] <= 'z') // 小写字母
{
if (!flag1)
{
flag1 = 1;
cnt++;
}
}
if (str[i] >= 'A' && str[i] <= 'Z') // 大写字母
{
if (!flag2)
{
flag2 = 1;
cnt++;
}
}
if (str[i] >= '0' && str[i] <= '9') // 数字
{
if (!flag3)
{
flag3 = 1;
cnt++;
}
}
if (str[i] == '~' || str[i] == '!' || str[i] == '@' || str[i] == '#' || str[i] == '$' || str[i] == '%' || str[i] == '^') // 特殊符号
{
if (!flag4)
{
flag4 = 1;
cnt++;
}
}
}
if (str.length() >= 8 && str.length() <= 16 && cnt >= 3) // 长度需求
{
cout << "YES" << endl;
}
else
{
cout << "NO" << endl;
}
}
return 0;
}
1019:将字符串所有字母转换成小写
分析:莫得难度,调库或者手写都可以,看代码。
Code:
int main()
{
string str;
while(getline(cin, str)){
for(int i = 0; i < str.length(); i++){
if(isupper(str[i])) str[i] = tolower(str[i]); // 如果是大写就转换成小写
}
cout << str << endl;
}
return 0;
}
1020:输出空心三角形
分析:分三部分输出,第一行,中间部分,以及最后一行。
可以发现第一行只需要输出 n-1 个空格和 1 个字符;
中间部分需要输出 n-1-i 个空格然后输出 1 个字符再输出 2i-1 个空格最后输出 1 个字符;
最后一行输出 2n-1 个字符。
需要注意特判1的情况!详见代码。
Code:
int main()
{
char ch;
int first = 1; // 用于控制输出块之间的空行,第一个输出块前面不输出空行,其余都要
while (cin >> ch, ch != '@')
{
int n;
cin >> n;
if (first)
first = 0;
else
cout << endl;
if (n == 1) // 特判1的情况
{
cout << ch << endl;
continue;
}
for (int i = 0; i < n - 1; i++) // 输出第一行
cout << " ";
cout << ch << endl;
for (int i = 1; i < n - 1; i++) // 输出中间部分
{
for (int j = 0; j < n - 1 - i; j++)
cout << " ";
cout << ch;
if (i == 1) // 特判1的情况
cout << " " << ch << endl;
else
{
for(int j = 0; j < 1+(i-1)*2; j++) cout << " ";
cout << ch << endl;
}
}
for(int i = 0; i < 2*n-1; i++) cout << ch; // 输出最后一行
cout << endl;
}
return 0;
}
二、medium
1003:模拟OJ判题
分析:只需要判断AC、WA和PE,AC和WA有本质的区别,而AC和PE只是格式的区别。因此将两者的多余部分全部去掉,如果相同则是PE,否则是WA,当然,如果一开始就相同则是AC。
Code:
int main()
{
int T;
string s;
cin >> T;
getchar();
while (T--)
{
string ans[4];
for (int i = 0; i < 2; i++)
{
getline(cin, s); //读取START
while(true)
{
getline(cin, s);
if (s != "END")
ans[i] += s + '\n';
else
break;
}
for (int j = 0; j < ans[i].size(); j++)//计算出去掉换行、制表和空格之后的数据
if (ans[i][j] != '\n' && ans[i][j] != '\t' && ans[i][j] != ' ')
ans[i + 2] += ans[i][j];
}
if (ans[2] != ans[3])
cout << "Wrong Answer" << endl;
else if (ans[0] != ans[1])
cout << "Presentation Error" << endl;
else
cout << "Accepted" << endl;
}
return 0;
}
1006:画8
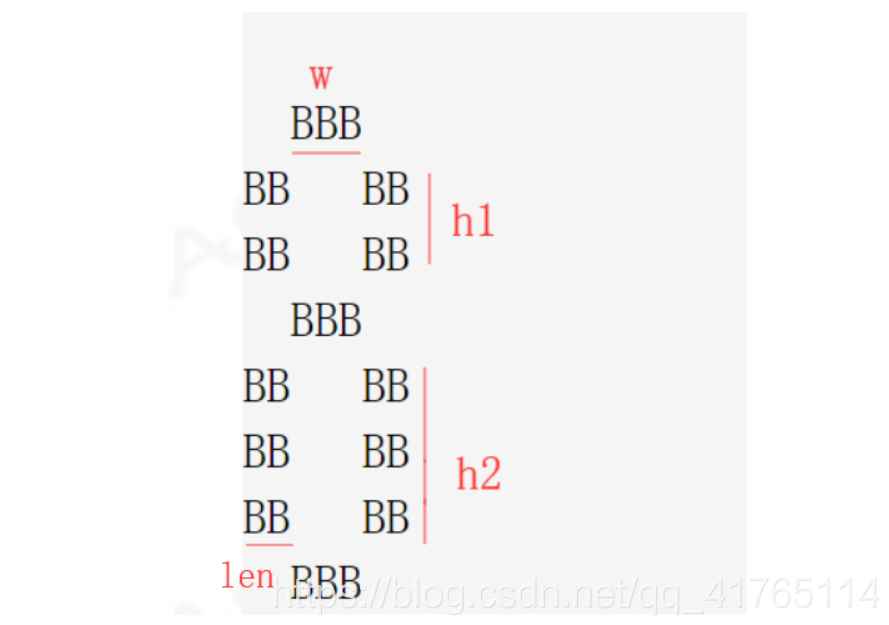
分析:题目的意思是横着的三行高度都是1,宽度可变,竖着的两列高宽度都可以改变,下面的圈和上面的圈的高度相近,即两者的插值最多为1,而且下面的圈不少于上面的圈,并且是一个正方形。
因此我们需要计算的是横着的三行的宽度w,上面一个圈的高度h1,下面一个圈的高度h2,还有两列的宽度len,而w与h2的值相等,故只需要求h1、h2和len。
根据题目描述,len = n/6+1。
若n为奇数,去掉三行后n-3为偶数,上下两个圈的高度均分,(n-3)/2;
若n为偶数,去掉三行后n-3位奇数,下面的圈大一点,(n-3)/2和(n-3)/2+1。
Code:
int main()
{
int T;
cin >> T;
while(T--){
int n, h1, h2, w, len;
char ch;
cin >> ch >> n;
h1 = h2 = (n-3)/2; // 先均分
if(n%2 == 0) h2 = h1+1; // n为偶数,下圈高度+1
w = h2; // 下圈为矩形,w==h2
len = n/6+1; // 列的宽度
for(int i = 0; i < len; i++) cout << " ";
for(int i = 0; i < w; i++) cout << ch;
cout << endl;
for(int i = 0; i < h1; i++){
for(int j = 0; j < len; j++) cout << ch;
for(int j = 0; j < w; j++) cout << " ";
for(int j = 0; j < len; j++) cout << ch;
cout << endl;
}
for(int i = 0; i < len; i++) cout << " ";
for(int i = 0; i < w; i++) cout << ch;
cout << endl;
for(int i = 0; i < h2; i++){
for(int j = 0; j < len; j++) cout << ch;
for(int j = 0; j < w; j++) cout << " ";
for(int j = 0; j < len; j++) cout << ch;
cout << endl;
}
for(int i = 0; i < len; i++) cout << " ";
for(int i = 0; i < w; i++) cout << ch;
cout << endl;
if(T) cout << endl; // 控制输出块之间的空行
}
return 0;
}
1007:按照DNA的逆序数排序
分析:数据范围很小,双重循环枚举两个元素判断是否为逆序对,统计答案,根据统计的结果从小到大排序,需要注意如果逆序数相同的话按照出现的顺序排序,因此还需要引入变量id,给每个DNA给个出现顺序。
在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序。一个排列中逆序的总数就称为这个排列的逆序数。
– 《逆序数》百度百科
Code:
const int MAXN = 200 + 10;
// 典型利用结构体重载运算符进行自定义排序规则,在acm比赛中非常常用,当然也可以使用cmp
struct Node
{
string str; // DNA串
int id, cnt; // 出现顺序以及逆序数
bool operator < (Node other) const // 自定义排序规则
{
if (cnt != other.cnt) // 如果逆序数不同,则按照逆序数从小到大排序
return cnt < other.cnt;
else // 如果逆序数相同,则按照出现顺序从小到大排序
return id < other.id;
}
} nodes[MAXN];
int main()
{
int T;
cin >> T;
while (T--)
{
int n, m;
cin >> n >> m;
for (int i = 0; i < m; i++)
{
cin >> nodes[i].str;
nodes[i].id = i; // 给每个DNA串一个唯一的出现顺序表示
int cnt = 0;
// 双重循环枚举统计逆序数
for (int j = 0; j < nodes[i].str.length(); j++)
{
for (int k = j + 1; k < nodes[i].str.length(); k++)
{
if (nodes[i].str[j] > nodes[i].str[k])
cnt++;
}
}
nodes[i].cnt = cnt;
}
sort(nodes, nodes + m);
for (int i = 0; i < m; i++)
{
cout << nodes[i].str << endl;
}
if (T) cout << endl; // 控制输出块之间的空行
}
return 0;
}
1014:字符串检测
分析:这道题其实并不难,但是做的人并不多,而且题目中的output出问题了,所以还是放在medium里面。
样例中的<其实就是小于号 <!
样例中的<其实就是小于号 <!
样例中的<其实就是小于号 <!
这个符号就是小于号的转义符号,这是需要了解的。
然后其实这道题就只要按照题面说的做就可以了:
- 字符串中必须有元音字母
- 字符串中不能有连续的三个元音字母或者连续的三个辅音字母
- 字符串中不能连续出现两个相同的字母,除了 ‘e’ 和 ‘o’
满足这些条件的字母串是 acceptable,否则是 not acceptable。
Code:
int isVowel(char ch) // 判断这个字母是否是元音字母
{
if (ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u')
return 1;
else
return 0;
}
int main()
{
string str;
while (cin >> str)
{
if (str == "end") // 以 end 字符串作为结尾
break;
// cnt用来保存元音字母个数,flag保存答案,last表示前面已经连续的元音字母或非元音字母的长度
int cnt = 0, flag = 1, last = 1;
for (int i = 0; i < str.length(); i++)
{
if (isVowel(str[i])) // 条件1
cnt++;
if (i && str[i - 1] == str[i] && str[i] != 'e' && str[i] != 'o') // 条件3
{
flag = 0;
break;
}
if (i && isVowel(str[i - 1]) == isVowel(str[i])) // 条件2
{
if (last >= 2)
{
flag = 0;
break;
}
else
{
last++;
}
}
else{
last = 1;
}
}
if(!cnt) flag = 0;
if(flag){
cout << "<" << str << "> is acceptable." << endl;
}
else{
cout << "<" << str << "> is not acceptable." << endl;
}
}
return 0;
}
1016:火星语翻译
分析:给出一张对照的表,英文单词与火星文单词对应,接下来给出一段文字,将其中有英文单词对应的火星语转换成英文单词。很明显就是C++中map的使用,在火星语和英文单词之间建立一个映射,如果不用C++的话可能需要保存下这张表然后对于每个词暴力遍历这张表查看是否要替换,效率比较低。
Code:
map<string, string> mp; // string到string的映射
char ch[3005];
int main()
{
string a, b;
cin >> a;
while (cin >> a && a != "END")
{
cin >> b;
mp[b] = a; // 建立b和a之间的映射
}
cin >> a;
getchar(); // 在使用gets和getline之前需要getchar
while (1)
{
gets(ch);
int i, len;
if (strcmp(ch, "END") == 0)
break;
len = strlen(ch);
b = "";
for (i = 0; i < len; ++i)
{
if (ch[i] < 'a' || ch[i] > 'z') // 遇到非字母字符时输出
{
if (mp[b] != "") // 如果这个单词有映射,输出映射的字符串
cout << mp[b];
else // 否则直接输出单词
cout << b;
b = "";
cout << ch[i];
}
else // 否则进行字符串连接
b += ch[i];
}
cout << endl;
}
return 0;
}
1017:网页重现
分析:处理文本中的标签 <br> 以及 <hr>,前者表示回车,后者表示在新行输出一行分割线后回车,后者如果已经在新的一行中那么就需要另起一行。除此以外,还需要处理一行最多只能显示80个字符,要保证单词是完整的,如果这行加入这个单词这行的字符就超过80字符的限制,那么这个单词整个都要放到下一行去。比较好的一点是题目说了,标签是独立出来的,前后都有空格,所以我们只需要一个字符串一个字符串地读入来判断就可以了,详见代码。
Code:
int main()
{
string str;
int cnt = 0; // cnt保存当前行的字符个数
while(cin >> str){ // 一个个字符串地读
if(str == "<br>"){ // 如果是<br>则另起一行,清空cnt
cout << endl;
cnt = 0;
continue;
}
if(str == "<hr>"){ // 如果是<hr>则根据cnt判断是否另起一行然后输出分割线
if(cnt) cout << endl, cnt = 0;
cout << "--------------------------------------------------------------------------------" << endl;
continue;
}
int limit = 80;
if(cnt) limit--; // 这里要注意,否则会PE
if(cnt+str.length() <= limit){ // 如果没有超出了80个字符的限制
if(cnt) cout << " ", cnt++;
cnt += str.length();
cout << str;
}
else{ // 否则另起一行
cout << endl;
cout << str;
cnt = str.length();
}
}
cout << endl;
return 0;
}
1018:查找重新排序后相同的字符串
分析:使用小技巧,对每个字符串都先进行一次 sort 以实现“标准化”,这样就免去了后面对两个字符串检查是否重新排序后相同的麻烦。这里我使用了C++的map映射以及vector容器,使用map实现string->int的映射,又因为每类重新排序后相同字符串的个数不确定,因此使用vector,详见代码。
Code:
const int MAXN = 200 + 10;
map<string, int> id; // 对每类标准化后的字符串分配一个唯一的vector下标
vector<string> vec[MAXN]; // vector数组,每类字符串都拥有一个vector
int main()
{
string dict;
int index = 0;
while(cin >> dict){
if(dict == "XXXXXX") break;
string s = dict;
sort(s.begin(), s.end()); // 对字符串排序
if(id.count(s) == 0) id[s] = index++; // 如果没有映射,建立一个
vec[id[s]].push_back(dict); // 将这个词放到对应的vector中
}
string words;
while(cin >> words){
if(words == "XXXXXX") break;
sort(words.begin(), words.end()); // 对字符串排序
if(id.count(words) == 0){ // 如果没有对应的vector,说明无效
cout << "NOT A VALID WORD" << endl;
}
else{ // 否则对对应vector中的所有字符串进行排序后输出
sort(vec[id[words]].begin(), vec[id[words]].end());
for(int i = 0; i < vec[id[words]].size(); i++){
cout << vec[id[words]][i] << endl;
}
}
cout << "******" << endl;
}
return 0;
}
三、hard
1005:给出大量单词,求以某字符串为前缀的单词个数
分析:看题目就联系到了经典的Trie字典树,稍加改写就可以通过此题,就是需要学习一下字典树,有兴趣的可以自行搜索,这里就简单说下。
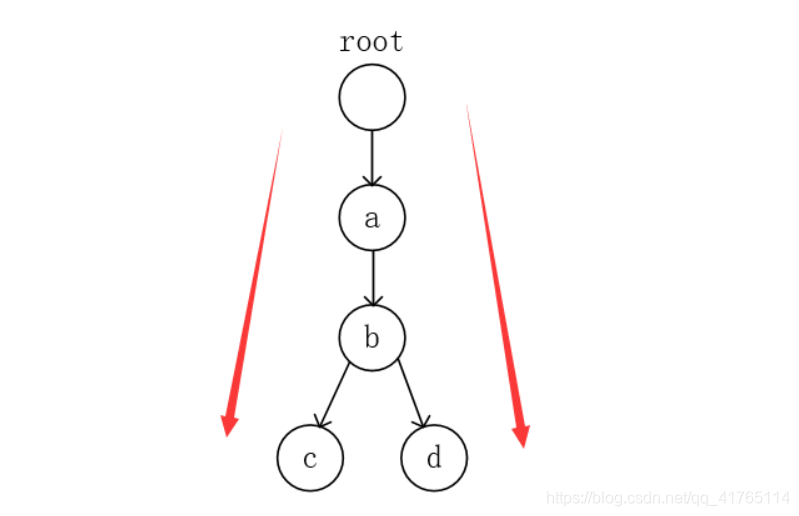
字典树是一颗树,每层有26个结点,分别代表26个字母,任意一条从根节点开始的路径可以代表一个字符串,正因为这样的树形结构,使得具有相同前缀的字符串占用的多余空间被省下来了,进而使效率提高。
例如利用Trie保存字符串 “abc” 和 “abd”。
回到这道题目,需要我们求的时候以某个字符串为前缀的单词个数,那么我们需要在字典树上的每个点计数,表示在利用原始单词构造这颗字典树时这个节点被经过的次数,即以这个字符串为前缀的单词个数。
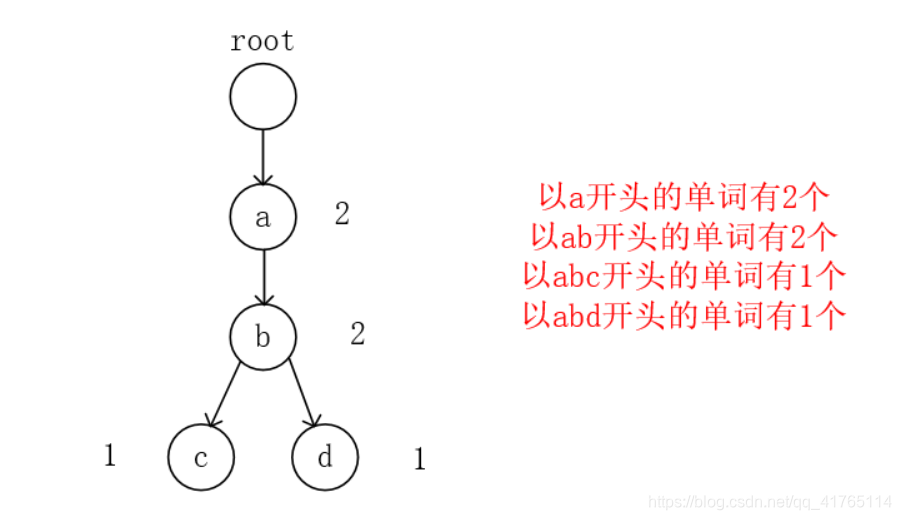
因此我们求以字符串str开头的单词个数时,顺着字典树最后走到的节点其上的权值就是答案。
注意:这题需要用数组字典树,用链表实现的会被卡掉!
Code:
int trie[1000010][26]; //数组形式定义字典树,值存储的是下一个字符的位置
int num[1000010]={0}; //附加值,以某一字符串为前缀的单词的数量
int pos = 1;
void Insert(char word[]) //在字典树中插入某个单词
{
int i;
int c = 0;
for(i=0;word[i];i++){
int n = word[i]-'a';
if(trie[c][n]==0) //如果对应字符还没有值
trie[c][n] = pos++;
c = trie[c][n];
num[c]++;
}
}
int Find(char word[]) //返回以某个字符串为前缀的单词的数量
{
int i;
int c = 0;
for(i=0;word[i];i++){
int n = word[i]-'a';
if(trie[c][n]==0)
return 0;
c = trie[c][n];
}
return num[c];
}
int main()
{
char word[11];
while(gets(word)){
if(word[0]==NULL) //空行。gets读入的回车符会自动转换为NULL。
break;
Insert(word);
}
while(gets(word))
printf("%d\n",Find(word));
return 0;
}
四、乱入的搜索
1015:经典的八字码问题
分析:可能是选题的时候出现了问题,这道题目跟字符串没什么关系,主要是要使用进阶的搜索算法, A* 算法或者 IDA* 算法以及其他的有效搜索方法都可以通过这道题目。由于跟本次训练的主题无关,我就不多说了,我使用的是IDA*算法,也就是迭代加深搜索,有兴趣的同学可以去学习一下。
简单的说IDA*就是DFS搜索的进阶版,它通过迭代加深与估价函数来进行优化,迭代加深就是用从0开始限制了搜索的最大层数maxn,估价函数是用来计算从当前状态到达最终状态至少还需要多少步,如果当前的层数+估价函数的结果 > maxn,那么就可以直接放弃这个状态返回就可以了,如果在这样的maxn限制下到了最终状态,那么maxn就是最优解。
IDA*适用于目标状态比较明确的背景下,这样会比较好设计估价函数。
对于这道题目来说,dfs搜索的部分已经迭代加深部分都没什么难度,往上套就可以了,问题就是怎么设计估价函数。如下图中,我们的最终状态就是最右边的样子,那么对于最左边的状态至少还需要多少步才能到达最终状态?假设我们可以随意移动每个数字,我们检查每个数字的当前位置与目标位置之间的“距离”,1 2 3 4 5 6 7 8 9 12 13 14 已经到了目标位置,而10还需要往左移动一次,11往上移动一次,15往左移动一次,即至少需要3次操作才能到达最终状态。(事实上3次可能并不能还原,不过步骤肯定不会低于这个次数,我们设计估价函数的时候可以保守一点)

Code:
const int size = 3;
char path[4] = {'u', 'l', 'r', 'd'};
char ans[10000];
int arr[size*size];
int target[size*size] = {1,2,3,4,5,6,7,8,0};
int direct[4][2] = {{-1, 0}, {0, -1}, {0, 1}, {1, 0}};
int targetPlace[9][2] = {2, 2, 0, 0, 0, 1, 0, 2, 1, 0, 1, 1, 1, 2, 2, 0, 2, 1};
int flag; // 答案是否存在
int zero; // 0的位置
int maxn; // 最大层数
int distance(){ // 估价函数,计算“距离”
int cnt = 0;
for(int i = 0; i < size*size; i++){
if(arr[i] != 0){
int t = arr[i];
int x = i/size;
int y = i%size;
cnt += abs(targetPlace[t][0]-x)+abs(targetPlace[t][1]-y);
}
}
return cnt;
}
int judge(){ // 检查是否有解
int cnt = 0;
int k = 0;
for(int i = 0; i < 9; i++){
for(int j = i+1; j < 9; j++){
if(arr[i] > arr[j] && arr[j]){
cnt++;
}
}
}
return !((k+cnt)%2);
}
int dfs(int zero, int way, int depth){
if(flag) return 1;
if(depth == maxn){
if(distance() == 0){
flag = 1;
return 1;
}
return 0;
}
for(int i = 0; i < 4; i++){
int newx = zero/3+direct[i][0];
int newy = zero%3+direct[i][1];
int newz = newx*3+newy;
if(newx < 0 || newx >= 3 || newy < 0 || newy >= 3) continue;
if(i+way == 3) continue;
swap(arr[newz], arr[zero]);
if(depth+distance() <= maxn && !flag){
ans[depth] = path[i];
if(dfs(newz, i, depth+1)){
flag = 1;
return 1;
}
}
swap(arr[newz], arr[zero]);
}
return 0;
}
int main(){
string str;
while(cin >> str){
// 将输入转换成数字串arr,x的地方用0代替
if(str[0] == 'x'){
zero = 0;
arr[0] = 0;
}
else{
arr[0] = str[0]-'0';
}
int j = 1;
for(int i = 1; i < size*size; i++){
cin >> str;
if(str[0] != ' '){
if(str[0] == 'x'){
zero = j;
arr[j++] = 0;
}
else
arr[j++] = str[0]-'0';
}
}
flag = 0;
// 开始迭代加深搜索
if(judge()){
maxn = distance();
for( ; ; maxn++){
if(dfs(zero, -1, 0)){
flag = 1;
break;
}
}
}
if(flag){
for(int i = 0; i < maxn; i++){
cout << ans[i];
}
cout << endl;
}
else{
cout << "unsolvable" << endl;
}
}
return 0;
}
【END】感谢观看!














 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









