







文章目录
面向对象 v.s. 面向过程
面向过程目前最熟知的就是c
其他的主流语言都是面向对象的
面向对象编程
三大基本特征:封装多态继承;
继承指子类是父类的实例,子类继承复用父类属性行为,也具有子类特有属性行为;
多态指的是一类事物有多种形态,一个抽象类有多个子类(因而多态的概念依赖于继承),不同的子类对象调用相同的方法,实现不同的行为,产生不同的执行结果,多态可以增加代码的灵活度。
.py可作为一个模块 from xxx import xxx
类的构建
class node(object):
def __init__(self, val=0):
self.val = val
self.next = none
head = node() #init
head.next = node(num_list.pop()) #赋值val
Python 语言中,以下划线开头的标识符有特殊含义,例如:
以单下划线开头的标识符(如 _width),表示不能直接访问的类属性,其无法通过 from...import* 的方式导入;
以双下划线开头的标识符(如__add)表示类的私有成员;
以双下划线作为开头和结尾的标识符(如 __init__),是专用标识符。
因此,除非特定场景需要,应避免使用以下划线开头的标识符。
__name__系统定义
_name保护类型
__name私有类型(前面是两个下划线)
@property将方法转化成属性,只读
__name__是python的一个内置类属性,它天生就存在于一个 python 程序中。
直接运行python程序时,__name__的值为“__main__”
导入.py外部文件运行时,__name__的值为文件名,即模块名
只要在测试代码前面加上:if __name__ == '__main__':
那么,编写调试过程直接运行该模块时__name__ "的值为__main__ ",即测试内容被执行。
而同事在导入该模块,__name__ ""的值为py文件名,测试内容则不会被执行。完美的解决了这个问题。
派生类调用基类__init__()方法,需要加super().__init__()
派生是面向对象编程的基本概念,它赋予了我们基于某个基础类来轻松创建新类的能力。使用派生类的方法,我们可以复用他人的代码,不必从 0 开始创建自己的轮子。
定义一个基于某个现有类的新类的方法如下:
def 新类(现有的类):
pass
现有的类,有时也称为基类、父类;新类也称为派生类、子类。派生类继承了基类的所有属性。
下面的例子中,车辆是基类,汽车和自行车是派生类,它们都继承了车辆的全部成员。
一、self参数
self指的是实例Instance本身,在Python类中规定,函数的第一个参数是实例对象本身,并且约定俗成,把其名字写为self,也就是说,类中的方法的第一个参数一定要是self,而且不能省略。
我觉得关于self有三点是很重要的:
self指的是**实例本身**,而不是类
类的方法中的self不可以省略,pycharm自动提示需要参数self。
二、__ init__ ()方法:传递的参数由__ init__ ()接受,如person(“xiaoming”)
在python中创建类后,通常会创建一个\ __ init__ ()方法,这个方法会在创建类的实例的时候自动执行。 \ __ init__ ()方法必须包含一个self参数,而且要是第一个参数。
比如下面例子中的代码,我们在实例化Bob这个对象的时候,\ __ init__ ()方法就已经自动执行了,但是如果不是\ __ init__ ()方法,比如说eat()方法,那肯定就只有调用才执行。
如果 \ __ init__ ()方法中还需要传入另一个参数name,但是我们在创建Bob的实例的时候没有传入name,那么程序就会报错, 说我们少了一个\ __ init__ ()方法的参数,因为\ __ init__ ()方法是会在创建实例的过程中自动执行的,这个时候发现没有name参数,肯定就报错了!
栗子:传入了name之后就不会报错,而且eat方法也可以使用name这个参数。
class Person():
def __init__(self,name):
print("是一个人")
self.name=name
def eat(self):
print("%s要吃饭" %self.name)
Bob=Person('Bob')
Bob.eat()
三、super(Net, self).init()
Python中的super(Net, self).init()是指首先找到Net的父类(比如是类NNet),然后把类Net的对象self转换为类NNet的对象,然后“被转换”的类NNet对象调用自己的init函数,其实简单理解就是子类把父类的__init__()放到自己的__init__()当中,这样子类就有了父类的__init__()的那些东西。
回过头来下面的代码,Net类继承nn.Module,super(Net, self).init()就是对继承自父类nn.Module的属性进行初始化。而且是用nn.Module的初始化方法来初始化继承的属性。
当然,如果初始化的逻辑与父类的不同,不使用父类的方法,自己重新初始化也是可以的。

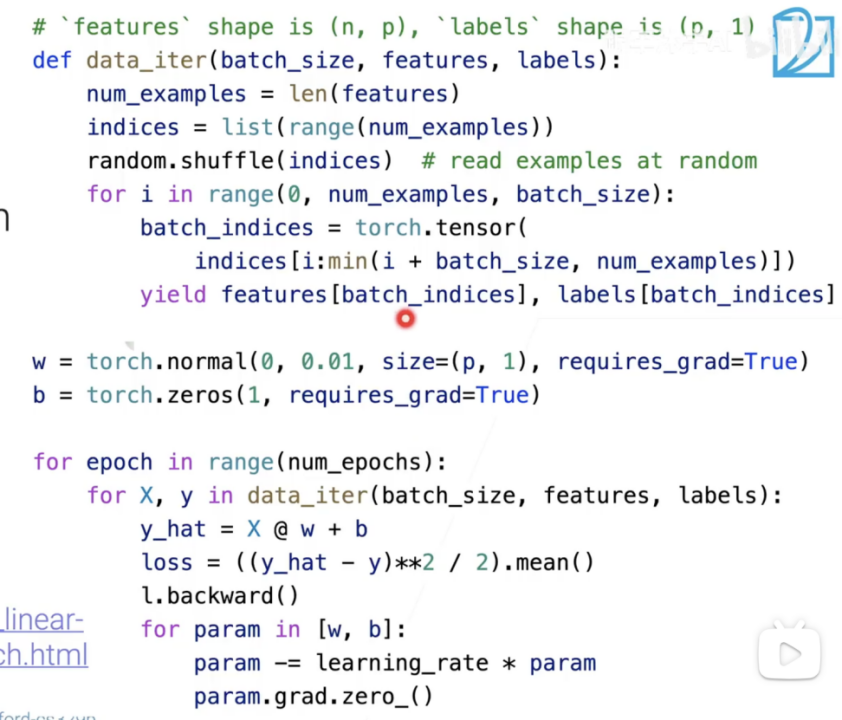
yield相比return可以批量返回罗列。
@指矩阵乘法,这里是矩阵乘向量。
L.backward()即loss.backword()
Param-=…*param.grad 少写了,应该是梯度
最后一行把梯度清零进入下一循环。
排序
list = sorted(iterable, key=none, reverse=false)
print(sorted(chars,key=lambda x:len(x)))
#连带⼀起排序
test_data_1=sorted(dict_data.items(),key=lambda x:x[0]) #lambda
#先按照成绩降序排序,相同成绩的按照名字升序排序:
d1 = [{‘name’:‘alice’, ‘score’:38}, {‘name’:‘bob’, ‘score’:18}, {‘name’:‘darl’, ‘score’:28}, {‘name’:
l = sorted(d1, key=lambda x:(-x[‘score’], x[‘name’]))
#指定第⼆个元素排序
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
def takesecond(elem): # 获取列表的第⼆个元素
return elem[1]
random.sort(key=takesecond)
注释
单行#
多行 三引号
命名规则
命名注意不可以数字开头且不可与保留字重名
根据下标获取
不仅限于字符串
1.单个字符
“abcd”[0]
Abc[-1]#最后一个元素
2.切片:
“abcd”[1:3]
Abc[0:-1] #第一个元素到倒数第二个元素的切片 左闭右开
list_[1:] #去掉列表中第一个元素(下标为0)
a[:-1] #除了最后一个取全部
[::-1] #反转
输出相关
python格式化输出(已导出pdf防止网页失效)
这个博主总结的很全 推荐
print("双引号存在的意义在于可以在双引号包裹中输出单引号'")
print可以包含多个参数。每对参数由逗号分隔,并在显示时在它们之间插入空格。
三引号可以用来包裹多行文本。我们只需要在文本的开头和结尾加上三引号,再调用 print() 函数就能将多行文本原样打印出来。
使用三引号不仅方便,还能最大程度地保留原始文本结构,让我们”所见即所得“。
print('''
跨行输出
''')
print('跨行输出\n也可以用转义字符\n')
print(name + '的夫人是' + wife)
print(type('hi'))# 输出:<class 'str'>
print(type(666))# 输出:<class 'int'>
print(type(3.14))# 输出:class 'float'>
#不能将字符串和整数相联结(相加),需要类型转换
num = 100
print('杖责黄盖' + str(num) + '军棍')
#浮点形式的字符串是无法使用 int()进行数据转换的,但是浮点数是可以使用 int()函数来转换的。类型转换 str() float()
print(a.lstrip())##去除左边的空格
print(a.rstrip())##去除右边的空格
time
import time #需要导入 time 才能使用 time.sleep() ->注释
time.sleep(1) #含义是:暂停 1 秒再执行下一行代码。
数组矩阵
b=np.array(a) #list to nparray
key[0][:len(m[0])]
r[i][k] += a[i][j] * b[j][k]
matrix_list[ord(y)-65][0]
数组作为函数实参,只传递地址,无需引用&
列表
多个数据组成的有序序列
['python','website']
#应用:判断是否在列表中
Abc[-1] in [‘c’,’C’] #返回true/false
a, b = b, a #交换
s.reverse()
#合并列表:直接使⽤"+"号合并列表
#注意a.append(b)将b看成list⼀个元素和a合并成⼀个新的list [1, 2, 3, ['www', 'jb51.net']]
for i in a:#循环查找
if i not in list:
#注意list的查找索引是list.index(x) x为值,返回其下标,若不存在抛出异常
str.join(x) #⽤于将序列中的元素以指定的字符连接生成一个新的字符串
list.insert(index, obj)
v2.extend(v1) #[v2,v1]
del v[-1]
v.remove(x)
v.count(x)
v.index(x)#首次出现的下标
排序
.sort() 与sorted()区别:前者改变原元素顺序,后者对副本排序
字典
{'name':'python','number':1}
del tinydict['name'] # 删除键是'name'的条⽬
tinydict.clear() # 清空字典所有条⽬
dict(zip(list1,list2))打包
cmp(dict1, dict2)⽐较
dict.keys()
dict.values()
dict.update(dict2)把字典dict2的键/值对更新到dict⾥,添加元素或如果后⾯的键有重复的会覆盖前⾯的
dict.pop
popitem()返回并删除字典中的最后⼀对键和值。
key,value/item in chengji.items()返回键值对
两层for循环 in/not in替代标记数组
dict.fromkeys(list)创建以list为键的值为空的字典
dict={key:value}
字符串
若字符串中想打出引号需要转义字符
转义序列\ '表示第二个引号只是一个引号,而不是字符串的结尾:
另一种方法是使用双引号字符串包括其中要输出的单引号。
⼦串:必须连续,⼦序列:可以不连续
ord()函数主要用来返回对应字符的ascii码,chr()主要用来表示ascii码对应的字符
根据ascii码输出字⺟ chr(ascii)
ascii码以及⼤⼩写字⺟关系+数字起始:
48~57是0~9
65~90为26个⼤写英⽂字⺟,a~z
97~122号为26个⼩写英⽂字⺟,a~z
⼤写+32=⼩写
i.isspace()检测字符串是否只由空格组成
i.isalnum()检测字符串是否由字⺟和数字组成。
s.swapcase() ⽅法⽤于对字符串的⼤⼩写字⺟进⾏转换
filename.endswith(’.log’)/startswith 以…收尾/开头
#单引号、双引号、三引号依然适用
#使用单引号和双引号来表示字符串。
#第三种字符串格式使用三引号和三引号字符串可跨越多行。
#字符串之间用+拼接
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
>>> eval('2 + 2')
4
#对⻬+填充字符
ljust(width[, fillchar])返回⼀个原字符串左对⻬,并使⽤fillchar(默认空格)填充⾄⻓度width的新字符串。
rjust(width[, fillchar])返回⼀个原字符串右对⻬,
Str.join(list) #[list[0]+str+list[1]+str+....]
Str.count(x)
Str.find(x)#find找到⼦串并返回最⼩的索引
Str.index(x)
Lower()/upper()
格式化字符串 str.format(x)用x替换str的某个符合的字符 还涉及到正则表达式regex或RE
元组
(‘python’,‘website’)
元组和列表的区别在于元组不能改变,可以hash,列表可以改变,故不可hash
集合_唯一性
set() 函数创建⼀个⽆序不重复元素集,可进⾏关系测试,删除重复数据,还可以计算交集、差集、并集等。
交集 & : x&y,返回⼀个新的集合,包括同时在集合 x 和y中的共同元素。
并集 | : x|y,返回⼀个新的集合,包括集合 x 和 y 中所有元素。
差集 - : x-y,返回⼀个新的集合,包括在集合 x 中但不在集合 y 中的元素。
补集 ^ : x^y,返回⼀个新的集合,包括集合 x 和 y 的⾮共同元素。
if else
没有缩进会导致if else无法运行,报错
if skill==‘跑’: #注意冒号!!
print(‘逃跑成功!’)
elif skill==‘走’: # if 2<=num<=4: 是正确的
print(‘逃跑失败’)
else:
print(‘逃跑失败’)
输入相关
input() 函数来说,不管用户输入的回答是什么,比如整数 33、小数 3.14 或者火星文,Python 都会统一把它转换为字符串类型。
变量=input(“提示信息字符串”)
运算
Pow(x,y) :x的y次方
Round(x,d) 对x四舍五入 d是小数截取位数

range(start,end,step步长)
//整除
**幂
round( x [, n] )⽅法返回浮点数x的四舍五⼊值。n – 数值表达式,表示从⼩数点位数。
a//b,应该是对除以b的结果向负⽆穷⽅向取整后的数
import math
math.ceil(n)
math.floor(n)
进制转换:int()类可将数字或字符串转换为整型,以及把各进制转为⼗进制,调⽤⽅法为:
int(x, base=10)
>>> int('55') #字符串转换为⼗进制整型数
>>> int(0b11) #⼆进制转换为⼗进制
>>> int(0o11) #⼋进制转换为⼗进制
>>> int(0x11) #⼗六进制转换为⼗进制
int(x, 0)适⽤于带0x标示的各种进制数转⼗进制,
若不带0x的各种进制数要在后⾯的base中写明这是⼏进制,如x = int("deadbeef", 16)表明是16进制转⼗进制
使⽤bin(x) ,oct(x) 或hex(x) 转换:
传⼊的参数可以是2,8,16进制的,输出是字符串形式
保留⼏位⼩数:
⽅法⼀:format函数
print(format(1.23456, ‘.2f’))
⽅法⼆:’%.xf’⽅法
print(‘%.2f’ % 1.23456)
gcd:b == 0?a:gcd(b, a % b)
*&a 即取a所在地址的值,即变量a的值
*p p++指p按其所指向数据类型直接长度进行增减
斐波那契数列变换问题:即第三项等于前两项之和
年⽉⽇问题:闰年判断(四年一闰,百年不闰,四百年再闰)+⼤⼩⽉(左⼿握拳从右往左数,数完再从右往左数循环)
能被400整除或者能被4整除但不能被100整除为闰年,⼆⽉为29天。⼀般为28天。
dfs搜索
本质就是递归回溯,⼤神做法如下:
def dfs(i,j):
dx = [0,0,-1,1]
dy = [-1,1,0,0]
if i == m-1 and j == n-1:
for pos in route:
print('('+str(pos[0])+','+str(pos[1])+')')
return
for k in range(4):
x = i+dx[k]
y = j+dy[k]
if x>=0 and x<m and y>=0 and y<n and map1[x][y]==0:
map1[x][y]=1
route.append((x,y))
dfs(x,y)#递归
map1[x][y]=0#还原回来⾛下⼀趟循环
route.pop()#回溯
else:
return
return fun(str1[:m-1], str2) or fun(str1, str2[:n-1])#打印路径
最⻓连续⼦序列
dp = [1] * n #dp根据实际⽐对的是⾃⼰还是对⽅来做⼀维/⼆维矩阵
for i in range(n):
for j in range(i):
if nums[j] < nums[i]:
dp[i] = max(dp[i], dp[j] + 1)
函数
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
# 异常处理
except value error:
pass
# Python_web框架篇
Django耦合度高,难替换内置功能
Flask 轻量级,易扩展使用
网页开发流程:系统功能结构图(前,后台)->系统业务流程图->数据表关系
fuctional structure chart->business flow chart->data table relation















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









