






四.共享模型之内存
1、Java 内存模型(JMM)
JMM 即 Java Memory Model,它定义了主存(共享内存)、工作内存(线程私有)抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、 CPU 指令优化等。
JMM 体现在以下几个方面
原子性 - 保证指令不会受到线程上下文切换的影响
可见性 - 保证指令不会受 cpu 缓存的影响
有序性 - 保证指令不会受 cpu 指令并行优化的影响
2、可见性
1)退不出的循环


解决方法
- 使用 volatile (易变)推荐使用
它可以用来修饰成员变量和静态成员变量(放在主存中的变量),他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
2)使用synchronized

2)可见性与原子性
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见,不能保证原子性,仅用在一个写线程,多个读线程的情况:上例从字节码理解是这样的:

比较一下之前我们将线程安全时举的例子:两个线程一个 i++ 一个 i-- ,只能保证看到最新值,不能解决指令交错

注意:
1.synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是synchronized 是属于重量级操作,性能相对更低
2.如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到对 run 变量的修改了,想一想为什么? 使用了synchronized
3)模式之两阶段终止
使用volatile改进

4)模式之 Balking
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做 了,直接结束返回,有点类似单例。
1.用一个标记来判断该任务是否已经被执行过
2.需要避免线程安全问题
3.加锁的代码块要尽量的小,以保证性能

3、有序性
1)指令级并行原理
1. 名词
Clock Cycle Time
主频的概念大家接触的比较多,而 CPU 的 Clock Cycle Time(时钟周期时间),等于主频的倒数,意思是 CPU 能够识别的最小时间单位,比如说 4G 主频的 CPU 的 Clock Cycle Time 就是 0.25 ns,作为对比,我们墙上挂钟的Cycle Time 是 1s
例如,运行一条加法指令一般需要一个时钟周期时间
CPI
有的指令需要更多的时钟周期时间,所以引出了 CPI (Cycles Per Instruction)指令平均时钟周期数
IPC
IPC(Instruction Per Clock Cycle)即 CPI 的倒数,表示每个时钟周期能够运行的指令数
CPU 执行时间
程序的 CPU 执行时间,即我们前面提到的 user + system 时间,可以用下面的公式来表示
程序 CPU 执行时间 = 指令数 * CPI * Clock Cycle Time


2.指令重排序优化
事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令还可以再划分成一个个更小的阶段,例如,每条指令都可以分为:
取指令-指令译码-执行指令-内存访问-数据写回 这 5 个阶段

在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行,这一技术在 80's 中叶到 90's 中叶占据了计算架构的重要地位。
指令重排的前提是,重排指令不能影响结果(数据依赖性)例如

3.支持流水线的处理器
现代 CPU 支持多级指令流水线,例如支持同时执行取指令-指令译码-执行指令-内存访问-数据写回的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率。
4. SuperScalar 处理器
大多数处理器包含多个执行单元,并不是所有计算功能都集中在一起,可以再细分为整数运算单元、浮点数运算单元等,这样可以把多条指令也可以做到并行获取、译码等,CPU 可以在一个时钟周期内,执行多于一条指令,IPC> 1

5.多线程下指令重排序问题

在多线程环境下,以上的代码 r1 的值有三种情况:
第一种:线程 2 先执行,然后线程 1 后执行,r1 的结果为 4
第二种:线程 1 先执行,然后线程 2 后执行,r1 的结果为 1
第三种:线程 2 先执行,但是发生了指令重排,num = 2 与 ready = true 这两行代码语序发生交换
1.ready = true; // 前
2.num = 2; // 后
然后执行 ready = true 后,发生了时间片切换,线程 1 运行,那么 r1 的结果是为 0。
解决方案:
volatile 修饰的变量,可以禁用指令重排,禁止的是加 volatile 关键字变量之前的代码重排序
3)Volatile原理
1.保证可见性
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
对 volatile 变量的写指令后会加入写屏障
对 volatile 变量的读指令前会加入读屏障
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中

‘’而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据


2.保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
还是那句话,不能解决指令交错:
1.写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
2.而有序性的保证也只是保证了本线程内相关代码不被重排序

3. double-checked locking 问题
以著名的 double-checked locking 单例模式为例

以上的实现特点是:
1.懒惰实例化
2.首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
3.有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外

其中
17 表示创建对象,将对象引用入栈 // new Singleton
20 表示复制一份对象引用 // 引用地址
21 表示利用一个对象引用,调用构造方法
24 表示利用一个对象引用,赋值给 static INSTANCE
也许 jvm 会优化为:先执行 24,再执行 21。如果两个线程 t1,t2 按如下时间序列执行:

关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取INSTANCE 变量的值这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初始化完毕的单例对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
解决

如上面的注释内容所示,读写 volatile 变量操作(即 getstatic 操作和 putstatic 操作)时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面两点:
1.可见性
1)写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
2)而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据
2.有序性
1)写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
2)读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
3.更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性
4.happens before
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
下面说的变量都是指成员变量或静态成员变量
1)线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见

2)线程对 volatile 变量的写,对接下来其它线程对该变量的读可见

3)线程 start 前对变量的写,对该线程开始后对该变量的读可见
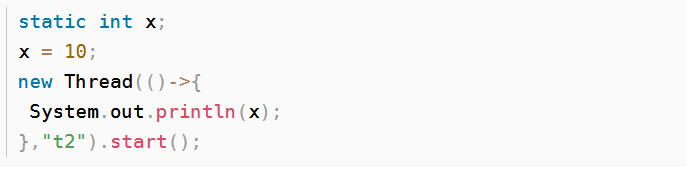
4)线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待它结束)线程结束前会将工作内存中的值刷新回主内存

5)线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过 t2.interrupted 或 t2.isInterrupted)

6)对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
7)具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z ,配合 volatile 的防指令重排,有下面的例子
5.线程安全单例模式
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
1)懒汉式

2)枚举

3)懒汉式

缺点:锁住的是类对象,锁的范围过大
4)DCL

5)静态内部类

五.共享模型之无锁
管程即 monitor 是阻塞式的悲观锁实现并发控制,这章我们将通过非阻塞式的乐观锁的来实现并发控制
取款例子(无锁实现)

1)CAS与Volatile

注意:
1.如果两者相等,就说明该值还未被其他线程修改,此时便可以进行修改操作。
2.如果两者不相等,就不设置值,重新获取值 preVal(调用get方法),然后再将其设置为新的值 nextVal(调用cas方法),直到修改成功为止。
1)其实 CAS 的底层是lock cmpxchg指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性
2) 在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
- volatile
1)获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
2)它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意:
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果

2.为什么无锁效率高
1)无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。打个比喻:线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火,等被唤醒又得重新打火、启动、加速… 恢复到高速运行,代价比较大
2)无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。(在线程数少于CPU核数时效率高)
3.CAS特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
1.CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。(自旋重试)
2.synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。(阻塞等待)
CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
1)因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
2)但如果竞争激烈(写操作多),可以想到重试必然频繁发生,反而效率会受影响
4.原子整数
java.util.concurrent.atomic并发包提供了一些并发工具类,这里把它分成五类:
使用原子的方式更新基本类型
AtomicInteger:整型原子类
AtomicLong:长整型原子类
AtomicBoolean :布尔型原子类
5.原子引用

为什么需要原子引用类型?保证引用类型的共享变量是线程安全的(确保这个原子引用没有引用过别人)。
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用引用类型原子类。
AtomicReference:引用类型原子类
AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
AtomicMarkableReference :原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起。
ABA问题
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又改回 A 的情况,如果主线程希望:只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号。使用AtomicStampedReference来解决。

AtomicMarkableReference
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如:A -> B -> A ->C,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference 。
6.原子数组
使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类
AtomicLongArray:长整形数组原子类
AtomicReferenceArray :引用类型数组原子类
上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerArray 为例子来介绍,代码如下:


7.字段更新器
1.AtomicReferenceFieldUpdater // 域 字段
2.AtomicIntegerFieldUpdater
3.AtomicLongFieldUpdater
注意:利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常

8.原子累加器
使用 LongAdder 性能提升的原因很简单,就是在有竞争时,设置多个累加单元(但不会超过cpu的核心数),Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
原理
LongAdder 类有几个关键域
public class LongAdder extends Striped64 implements Serializable {}
下面的变量属于 Striped64 被 LongAdder 继承。

Cas实现自旋锁

原理之伪共享
其中 Cell 即为累加单元

下面讨论 @sun.misc.Contended 注解的重要意义
得从缓存说起,缓存与内存的速度比较

因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。缓存离 cpu 越近速度越快。 而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long),缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中,CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效。

因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因 此缓存行可以存下 2 个的 Cell 对象。这样问题来了: Core-0 要修改 Cell[0],Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效,@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
1)add方法分析
LongAdder 进行累加操作是调用 increment 方法,它又调用 add 方法。
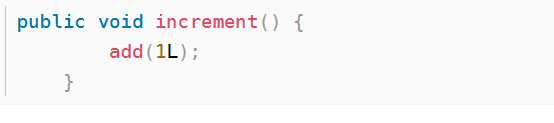
第一步:add 方法分析,流程图如下


第二步:longAccumulate 方法分析,流程图如下:

每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)

2)Unsafe
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得。LockSupport 的 park 方法,cas 相关的方法底层都是通过Unsafe类来实现的。
// Unsafe 使用了单例模式,unsafe 对象是类中的一个私有的变量

Unsafe模拟原子整数



六.共享模型之不可变
1、日期转换的问题
问题提出,下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的,有很大几率出现 java.lang.NumberFormatException 或者出现不正确的日期解析结果。

思路 - 不可变对象
如果一个对象不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改!这样的对象在 Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类 DateTimeFormatter
2、不可变设计
String类中不可变的体现

- final 的使用
发现该类、类中所有属性都是 final 的
1.属性用 final 修饰保证了该属性是只读的,不能修改
2.类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
2)保护性拷贝
但有同学会说,使用字符串时,也有一些跟修改相关的方法啊,比如 substring 等,那么下面就看一看这些方法是如何实现的,就以 substring 为例:

发现其内部是调用 String 的构造方法创建了一个新字符串,再进入这个构造看看,是否对 final char[] value 做出了修改:

结果发现也没有,构造新字符串对象时,会生成新的 char[] value,对内容进行复制。这种通过创建副本对象来避免共享的手段称之为【保护性拷贝(defensive copy)】
3、模式之享元
1)简介
简介定义英文名称:Flyweight pattern. 当需要重用数量有限的同一类对象时,归类为:Structual patterns
2)体现
在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法。
例如 Long 的 valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对象:

3)DIY 实现简单的数据库连接池
例如:一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。 这时预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。
代码实现如下



以上实现没有考虑:
1.连接的动态增长与收缩
2.连接保活(可用性检测)
3.等待超时处理
4.分布式 hash
对于关系型数据库,有比较成熟的连接池的实现,例如 c3p0、druid 等
对于更通用的对象池,可以考虑用 apache commons pool,例如 redis 连接池可以参考 jedis 中关于连接池的实现。
4、final的原理
1)设置 final 变量的原理
理解了 volatile 原理,再对比 final 的实现就比较简单了


发现 final 变量的赋值也会通过 putfield 指令来完成,同样在这条指令之后也会
加入写屏障,保证在其它线程读到它的值时不会出现为 0 的情况

无状态
在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为【无状态】















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









