







文章目录
Catalog
在关系数据库 中, Catalog 是一个宽泛的概念,通常可以理解为一个容器或数据库对象命名空间中的一个层。在 SparkSQL 系统中, Catalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、 数据视图、数据分区与函数等)的统一管理。 Spark SQL 的 Catalog 体系涉及多个方面,不同层 次所对应的关系如图 所示。
SessionCatalog
Spark SQL 中的 Catalog 体系实现以 SessionCatalog 为主体,通过 SparkSession (Spark 程序入口)提供给外部调用。一般一个 SparkSession 对应一个 SessionCatalog。 本质上, Session Catalog 起到了一个代理的作用,对底层的元数据信息、临时表信息、视图信息和函数 信息进行了封装。

SessionCatalog
SessionCatalog的构造函数如下。

其中包含两个配置项conf、hadoopConf。
-
parser为解析器接口。在listFunctions(db: String, pattern: String)和lookupRelation(name: TableIdentifier)中被使用,用于对函数和表进行解析。
-
Global Temp View Manager (全局的临时视图管理):对应 DataFrame 中常用的 createGlobalTemp View 方法,进行跨 Session 的视图管理。主要功能依赖一个 mutable 类型的 HashMap 来对视图名和数 据源进行映射,其中的 key 是视图名的字符串, value 是视图所对应的 LogicalPlan (一般在创建该视图时生成) 。
-
FunctionResourceLoader (函数资源加载器):在 SparkSQL 中除内置实现的各种函数外,还 支持用户自定义的函数和 Hive 中的各种函数。 这些函数往往通过 Jar 包或文件类型提供, FunctionResourceLoader 主要就是用来加载这两种类型的资源以提供函数的调用。
-
FunctionRegistry (函数注册接口):用来实现对函数的注册 (Register)、查找(Lookup)和 删除(Drop) 等功能。一般来讲, FunctionRegistry 的具体实现需要是线程安全的,以支持并发访问。 在 Spark SQL 中默认实现是 SimpleFunctionRegistry,其中采用 Map 数据结构注册了各种内置的函数。
-
ExternalCatalog (外部系统 Catalog)::用来管理数据库(Databases)、数据表 (Tables)、数 据分区(Partitions)和函数(Functions)的接口 。 顾名思义,其目标是与外部系统交互, 并做到上述内容的非临时性存储,同样需要满足线程安全以支持并发访问。 ExternalCatalog 是一个抽象类,定义了上述 4 个方面的功能。 在 Spark SQL 中,具体 实现有 InMemoryCatalog 和 HiveExternalCatalog 两种。 前者将上述信息存储在内存中, 一 般用于测试或比较简单的 SQL 处理;后者利用 Hive 元数据库来实现持久化的管理,在生 产环境中广泛应用。
此外还拥有tempViews、currentDb两个变量,tempView是HashMap类型,储存临时视图。currentDb是字符串类型,指明现在正在使用的数据库名称。
HiveSessionCatalog
HiveSessionCatalog继承了Spark的默认SessionCatalog,并调整了一些成员的类型,以及新增了一些成员变量,专门用于管理Hive数据源的MetaStore。 HiveSessionCatalog中,它的externalCatlog类型转换为ExternalCatalog的子类HiveExternalCatalog,同时增加了一个成员变量HIveMetastoreCatalog(注意,这个成员之后会完整集成到HiveExternalCatalog中)。

ExternalCatalog
ExternalCatalog是系统Catalog的接口,提供访问function、partition和database的一系列方法。只作用为非临时的item,它的实现类必须是线程安全的,因为它会同时被多个线程访问。ExternalCatalog为Spark提供了和外部系统交互的能力。 ExternalCatalog有两个实现类:HiveExternalCatalog和InMemoryCatalog。
InMemoryCatalog
InMemoryCatalog将元数据储存在内存之中,其使用一个HashMap类型,储存数据库元信息。
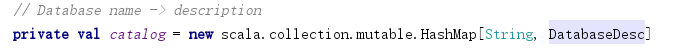
DatabaseDesc表示数据库元信息,TableDesc表示表元信息,CatalogFunction表示函数,其都储存在HashMap数据结构中。

InMemoryCatalog会将元数据全部储存在内存之中,所以不会在当前目录下创建metastore_db目录。数据库的真实数据(数据库、表数据)会储存在磁盘中,具体位置由spark.sql.warehouse.dir参数决定,默认在当前目录下的spark-warehouse目录。


HiveExternalCatalog
HiveExternalCatalog为Spark提供了与Hive MetaStore的交互能力。具体实现方法是,HiveExternalCatalog会通过hadoop相关的配置文件来实例化一个ClientForMetadata,所有的元数据访问方法都是通过这个client来和hive交互。

如果classpath中含有hive-site.xml文件,其会读取hive-site.xml文件中的hive.metastore.warehouse.dir作为Hive 的warehouse地址。但是如果conf中spark.sql.warehouse.dir被显示设置,那么它会覆盖hive.metastore.warehouse.dir,作为Hive的warehouse地址。
HiveClient会根据hive-site.xml中的配置信息连接Hive的元数据库,但是如果hive-site.xml配置信息错误甚至classpath中没有hive-site.xml文件,则client无法正常连接Hive的元数据库。则此时会在当前目录下创建metastore_db目录储存元数据,并将hive.metastore.warehouse.dir或者spark.sql.warehouse.dir作为自己的warehouse。
SparkSession初始化
由上述的Catalog体系中我们可以看出,主要分为Hive有关的Catalog和默认的Catalog两类。那么SparkSession中怎么决定创建哪种类型的Catalog呢?
这主要由spark.sql.catalogImplementation参数决定,其默认值为"in-memory",调用SparkSession.enableHiveSupport(),会将其改为“hive”。
SparkSession的初始化主要与两个内部变量有关:SharedState和SessionState。
SharedState
SharedState是SparkSession中定义的一个基于给定SQLContext来维护跨Session的所有状态的一个类。SharedState中包含变量:warehousePath、cacheManager、statusStore、externalCatalog、globalTempViewManager、jarClassLoader。这些变量对于所有的SparkSession都是公用的。

SessionState
SessionState是基于一个特定SparkSession维护所有单个session作用域的所有状态,它的类成员如下图所示。SessionState维护了SparkSQL中大部分的核心类,如SqlParser、Analyzer、Optimizer等等。这些具体类的实现类型根据当前Spark Application的模式会有所不同。

BaseSessionStateBuilder
SessionState是使用SessionStateBuilder进行创建的。其基类为BaseSessionStateBuilder。

BaseSessionStateBuilder定义所有Session所需的状态,并且在session的build方法调用时会真正去创建一个SessionState。同时在构建新的SessionState时,BaseSessionStateBuilder可以接收一个parent session state来对其的成员进行集成(parent session state为空则直接新建各组件,不为空,则对各组件进行clone)。
在BaseSessionStateBuilder内部创建conf、functionRegistry、experimentalMethods、sqlParser、resourceLoader、udfRegistration、analyzer、optimizer、planner、catalog等组件,上述组件均为新创建的对象。其中catalog组件创建过程:

可以看出catalog的创建使用了sparksession中的sharedState中的externalCatalog和globalTempViewManager。所以所有的SessionState中的SessionCatalog公用shared同一个externalCatalog和globalTempViewManager。
最后调用bulid方法,将上述组件传入,创建SessionState。

SessionStateBuilder和HiveSessionStateBuilder
SessionStateBuilder和HiveSessionStateBuilder是BaseSessionStateBuilder的子类,通过重写组件生成方法,可以改变传入build()方法中的组件类型。
SessionStateBuilder是BaseSessionStateBuilder的基本实现,HiveSessionStateBuilder是Spark针对Hive数据源的特定实现。
HiveSessionStateBuilder可以构建出一个能识别Hive数据源的SessionState。HiveSessionStateBuilder类对它的父类BaseSessionStateBuilder中的一些方法和成员变量进行了覆盖。
HiveSessionStateBuilder:其中catalog组件会创建成HiveSessionCatalog类型,同样构造函数中使用Session.sharedState的externalCatalog和globalTempViewManager。所以此时sharedState的externalCatalog应该是HiveExternalCatalog类型。
HiveSessionStateBuilder、HiveSessionCatalog、HiveExternalCatalog的使用条件均为spark.sql.catalogImplementation参数为hive时,其默认值为"in-memory",调用SparkSession.enableHiveSupport(),会将其改为“hive”。

除此之外HiveSessionStateBuilder还重写了其他的组件生成方法,以适应Hive环境。最后利用继承至BaseSessionStateBuilder的build方法,将各组件传入,即可生成适应Hive环境的SessionState。
SparkSession初始化过程
- SparkSession.getOrCreate()进行初始化。SparkSession在创建过程中能获取到所有的配置文件,包括是否连接Hive,Hive集群的对应配置。注意Spark中的SessionState和ShareState都是lazy变量,只有当第一次使用时才会进行初始化。

构造函数传入四个参数:SparkContext、existingSharedState、parentSessionState、extensions
初始化SharedState
- 初始化SessionState之前,首先要初始化SharedState。

如果SparkSession构造函数中传入的existingSharedState为空,则新创建一个new SharedState(sparkContext),否则直接使用existingSharedState。 - SharedState构造函数:先初始化warehousePath。读取配置信息,若有hive-site.xml配置信息且没有显式定义spark.sql.warehouse.dir(在SparkConf或者配置文件中定义),则从hive配置中获取hive.metastore.warehouse.dir作为warehousePath。否则,使用spark.sql.warehouse.dir作为warehousePath。(如果SparkConf中没有spark.sql.warehouse.dir信息,则使用默认值:当前路径下的spark-warehouse目录)
- SharedState构造函数中:接着初始化CacheManager、SQLListener。然后初始化externalCatalog。externalCatalogClassName函数中根据spark.sql.catalogImplementation决定使用InMemoryCatalog还是HiveExternalCatalog。根据warehouse创建default数据库。

- 最后初始化globalTempViewManager和jarClassLoader。
初始化SessionState
- 调用SparkSession中的sessionState方法,该方法中通过SparkSession.instantiateSessionState来对SessionState进行初始化。

- SparkSession构造函数中传入parentSessionState,对其进行clone,如果传入不为空,则使用clone对象。如果为空,则进行创建。sessionStateClassName函数根据spark.sql.catalogImplementation参数选择使用HiveSessionStateBuilder还是SessionStateBuilder。然后instantiateSessionState函数使用SessionStateBuilder创建SessionBuilder。其创建过程已在上进行叙述。
总结
关于sharedState和sessionState
综上可以看出,SparkSession重用sharedState,但是会新clone或者创建新的sessionState。但是每一个新的sessionState中的SessionCatalog中的externalCatalog和globalTempView都是重用sharedState的对象。但是如果在创建多个SparkSession时,传入的existingSharedState都为空,则多个SparkSession也会创建多个sharedState。
调用SparkSession对象的cloneSession()或者newSession()创建新的sparksession对象,会重用sharedState。但是新的sparksession会拥有新的sessionstate对象,从而拥有新的conf、functionRegistry、udfRegistration、resourceLoader、解析器、优化器、物理计划器、tempview(catalog中)等,从而将不同的sparksession的操作和配置隔离开。
关于Hive
如果SparkSession.enableHiveSupport(),spark.sql.catalogImplementation=“hive”,则sharedState初始化时,会创建HiveExternalCatalog。sessionState初始化时,会创建HiveSessionCatalog,调用HiveSessionStateBuilder,创建适合Hive数据源的SessionState。
否则,spark.sql.catalogImplementation=“in-memory”,sharedState初始化时创建ExternalCatalog,sessionState初始化时,会创建SessionCatalog,调用SessionStateBuilder,创建SessionState。
关于 warehousePath
如果classpath中有hive-site.xml文件,且Sparkconf没有定义spark.sql.warehouse.dir参数,则使用hive-site.xml中的hive.metastore.warehouse.dir作为warehousePath。
否则,使用spark.sql.warehouse.dir作为warehousePath(如果Sparkconf没有定义spark.sql.warehouse.dir参数,会使用StaticSQLConf中定义的默认值,即当前路径下的spark-warehouse目录)。
注意!!!:
-
使用spark-sql启动命令行,会首先初始化default数据库,元数据库中将default数据库的的路径记录为hive-site.xml文件中的hive.metastore.warehouse.dir路径,默认为/user/hive/warehouse,如果这时直接创建表,则会存储到default数据库中。而创建新的数据库以及新数据库中的表,则会存储在spark.sql.warehouse.dir目录中。

从spark-sql的启动日志中可以看到,首先初始化default数据库,然后再将 hive.metastore.warehouse.dir改成spark.sql.warehouse.dir。所以初始化default数据库时,使用的是 hive.metastore.warehouse.dir路径。
所以要正确使用spark-sql命令行,即正确设置default数据库的位置,必须将hive-site.xml 复制到 spark classpath中,设置spark.sql.warehouse.dir是没有用的。 -
而使用spark-shell和代码运行,则不会立刻初始化default数据库。在第一次需要用到default数据库时,初始化default数据库,此时元数据库中将default数据库的的路径记录为spark.sql.warehouse.dir目录。
关于metastore_db
如果spark.sql.catalogImplementation=“in-memory”,则元数据全部储存在内存之中,不会生成metastore_db元数据库目录,但是真实数据值会储存在warehousePath目录中。但是此时不支持创建表等结构,因为程序关闭之后表等结构的元数据将消失,表也将无法使用。
如果spark.sql.catalogImplementation=“hive”,但是hive-site.xml中的元数据库配置信息有误,无法正常连接,则会在当前目录生成metastore_db,储存元数据,使用warehousePath作为数据仓库,储存数据。
整体结构
















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









