






摘要
猪咳嗽声音监测是一种有效的呼吸疾病早期预警手段。至今,大多数研究集中于基于手动分割的单个声音数据集上,对高精度的猪咳嗽识别算法进行研究。然而,对连续声音的识别研究较少,无法满足实际工程应用的需求。同时,复杂场景(如多种声音重叠的大型猪舍环境)也鲜少被考虑。为此,本文提出了一种自动检测连续声音的算法,并提出了一种具有显著诊断意义的连续猪咳嗽识别方法。首先,提出了一种语音活动检测(VAD)方法来自动分割连续声音。接着,研究了多分类器融合策略以提升识别准确性。最后,提出了一种低复杂度的连续猪咳嗽识别方法。实验结果显示,在连续声音中的猪咳嗽召回率和精确率分别为93.1%和91.6%,远高于基准检测方法的67.3%和90.6%。连续猪咳嗽识别准确率达91.4%。从实际应用角度来看,本文的算法开发充分考虑了真实猪舍的复杂环境。
1.简介
猪呼吸道疾病因其高度传染性和高致死性严重制约了健康养殖的发展(Assavacheep & Thanawongnuwech, 2022; Ji, Yin等, 2022; Sassu等, 2018)。传统的早期预警方法主要依赖人工检查。近年来,越来越多的研究集中于猪咳嗽的自动检测,以提供预警(Racewicz等, 2021)。早期的研究提出了许多针对猪咳嗽识别的解决方案,并取得了良好的结果。研究人员尝试在语音识别中使用不同的声学特征和分类器,如梅尔频率倒谱系数(MFCC)(Chung等, 2013)、功率谱密度(PSD)(Exadaktylos等, 2008)特征及模糊C均值(Exadaktylos等, 2008; Hirtum & Berckmans, 2003)、支持向量机(SVM)(Chung等, 2013)和动态时间规整(Guarino等, 2008)分类器,咳嗽识别精度最高可达约94%(Chung等, 2013)。随着深度学习模型的发展,咳嗽识别精度进一步提升,例如卷积神经网络(Shen, Wang等, 2022; Song等, 2022)和深信网络(Li等, 2018)。我们团队近年来也开展了许多研究,首先研究了基于卷积神经网络的方法(Shen, Tu等, 2021; Yin等, 2021),随后集中于特征选择、特征融合(Ji, Shen等, 2022; Shen, Ji等, 2022)和分类器融合策略(Yin等, 2023)以提高复杂猪舍环境中的精度。在自建的包含2500个独立声音的数据集上,准确率达到99.2%。
尽管前述研究在识别准确性方面取得了进展,但仍存在明显不足。首先,大多数方法基于孤立的单一声音识别。由于缺乏连续声音的自动分割能力,这些方法无法在连续声音环境下实现有效的咳嗽检测,因而无法在实际工程中应用。其次,现有研究主要集中于单个咳嗽的识别,缺乏对连续咳嗽(即多个间隔极短的单独咳嗽)的识别,而连续咳嗽的识别对疾病的诊断和治疗具有重要意义。第三,缺乏标注的连续声音数据集。现有研究中所用的数据集大多是基于专家注释手动分割的单个声音数据,这样的处理丢失了连续声音中的一些重要信息。此外,现有的数据集相较于大规模猪舍中的实际声音环境过于简单。在实际的大型猪舍中,咳嗽声通常没有干扰,并且具有较高的信噪比,而非咳嗽声则包含种类有限的声音。然而,在真实的猪舍环境中,声音环境更加复杂,主要体现在以下两方面:首先,猪舍中的声源非常复杂,经常有多个声音重叠,例如咳嗽声可能与风扇噪音、人声或猪的叫声重叠。根据本研究数据集的统计结果,近五分之一的咳嗽声会与其他声音重叠。其次,非咳嗽声音种类繁多,达到十余种,不同非咳嗽声音的数量严重不均,且对非咳嗽声的标注既耗时又具有挑战性。
为了解决上述问题,本文提出了一种连续咳嗽自动检测方法,用于检测复杂猪舍环境中的单一和连续咳嗽声。本文的贡献如下:
- 建立了一个复杂猪舍环境下的连续声音数据集。
- 提出了一种自动检测连续声音中咳嗽的方法。
- 通过改进的VAD(语音活动检测)算法和多分类器融合算法显著提升了咳嗽检测的准确率。
- 提出了一种低复杂度的连续猪咳嗽识别方法。
本文其余内容结构如下:第二节介绍本研究所用的数据集。第三节详细描述了本文提出的猪咳嗽检测方法。第四节展示实验结果。第五节讨论结果。第六节为结论。
2.数据集
2.1数据收集
实验数据采集于一个大型育肥猪舍。该猪舍长27.5米,宽12.8米,高3.2米,由12个大栏和9个小栏组成。大栏长4.15米,宽3.6米,小栏长3.6米,宽2.75米。猪舍配备机械通风系统,猪只自动进食,地面为半缝隙的混凝土地板。工作人员每天早晚清扫和冲洗地板。共有128头猪分布在12个大栏中,如图1所示。其中两头有严重咳嗽症状的猪被隔离在靠近门口的13号栏中。在数据收集期间,这两头猪已连续多日出现咳嗽症状,每个栏中还有数头其他咳嗽的猪。

声音数据采集设备为一个麦克风(型号为LIQI LM320E,心形驻极体麦克风,频率范围100Hz-16kHz),连接到带有声卡(Conexant Smart Audio HD)的笔记本电脑上进行录音。由于实验条件限制,麦克风被固定在靠近门的大栏中,距离地面约1.4米,距离猪背部约0.8米。音频采样率设为44100 Hz,分辨率为16位,声音文件保存为“.wav”格式,连续采集了7天的数据。
2.2 数据集
在兽医的协助下,我们使用“Cool Edit Pro 2.1”软件对整段连续音频文件进行手动分割和标注。每个咳嗽声音段的开始和结束时间在连续的声音片段中被进一步标注,数据集的构成如表1所示。数据集分为两部分。第一部分包含316个连续咳嗽片段,每个片段时长为7到40秒,包含大量咳嗽声和少量非咳嗽声。第二部分为随机和均匀选取的连续非咳嗽片段,共25段,分别在早上、下午、傍晚和夜间采集,每段时长为10分钟,包含大量非咳嗽声和少量咳嗽声。两部分数据共包含3408个咳嗽声和3133个非咳嗽声,其中2898个单独的咳嗽组成了332个连续咳嗽。约五分之一的咳嗽声与其他声音重叠。非咳嗽声音包括多种声源,如猪的尖叫声、打鼾声、喷嚏声、人声、清洁噪音及其他声音。我们将数据集划分为训练集和测试集。
2.3数据集分析
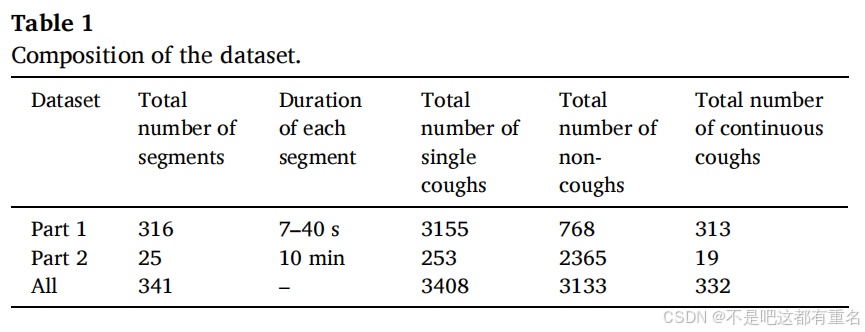
在大型猪舍中,通常饲养密度较高,猪只数量庞大。猪是发声活跃的动物,常因咬斗和打架而尖叫。同时,猪舍内还充满了各种机械噪声,这使得猪咳嗽的识别变得极具挑战性。复杂猪咳嗽的情况可归纳为以下三种情形:
-
(a)不同猪只的连续咳嗽重叠:如图2(a)所示,两个不同的咳嗽声相隔很近,可能被检测为一个声音,这样会导致咳嗽声难以被正确识别。
-
(b) 咳嗽声与微弱的非咳嗽声重叠:如图2(b)所示,重叠部分可能为部分或完全重叠,并且可能有多种声音重叠。在这种情况下,传统的VAD算法可能会漏检部分咳嗽声。
-
(c)咳嗽声与强烈的非咳嗽声重叠:如图2(c)所示,这种情况下VAD算法检测的难度最大。当两个声音完全重叠且非咳嗽声的强度远高于咳嗽声时,识别会变得非常困难。
3.提出的方法
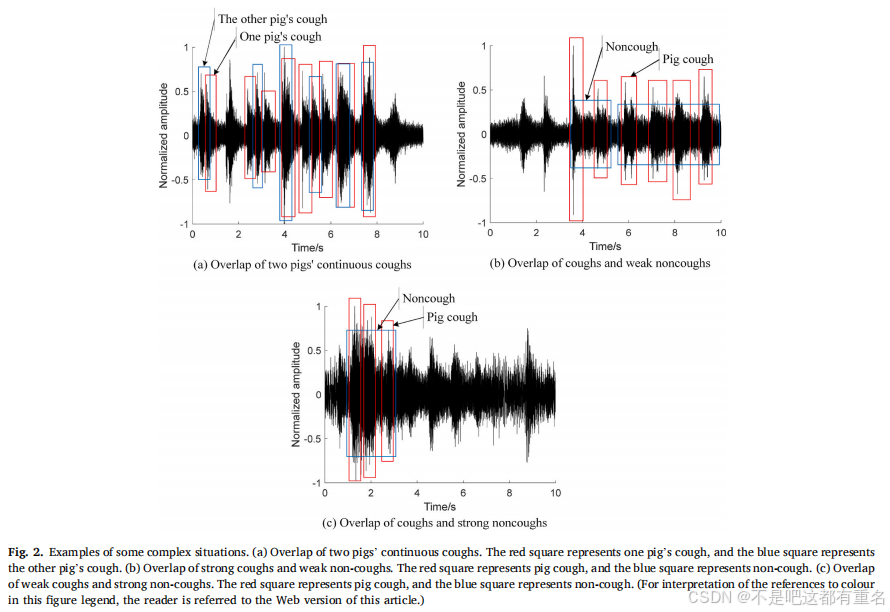
3.1所提出方法的架构
本文提出的方法框架如图3所示。首先将采集的连续声音缓冲成有重叠的片段,以避免单个咳嗽声被切分成两个片段。典型的缓冲区大小为5到15秒,重叠区可以设定为1到3秒。然后对片段进行预处理,包括预加重、滤波、分帧和加窗。接着,使用改进的语音活动检测(VAD)算法检测活跃声音,并记录活跃声音的开始和结束时间,用于判断是否为连续咳嗽。然后从检测到的活跃声音片段中提取声学特征和深度特征。将不同的特征输入不同的分类器,生成多个基分类器。这些基分类器通过基于准确率–多样性(AD)指标的选择算法进行筛选,并使用软投票法对筛选后的分类器进行融合,形成最终决策。如果检测到咳嗽声,还需基于VAD步骤中记录的信息进一步区分单一咳嗽和连续咳嗽。
3.2改进的VAD算法
传统的基于双重阈值能量检测(DTED)的VAD方法在背景噪声稳定且信噪比(SNR)较高的条件下能获得较好的检测效果(Exadaktylos等, 2008; Li等, 2018; Song等, 2022)。然而在复杂的猪舍环境中,这一方法存在两个明显的局限性:
1.噪声非平稳,信噪比随着时间快速变化。
2.连续咳嗽间隔时间短,其他声音的重叠使得能量明显高于背景噪声。
这种情况可能导致以下两种结果:
1.高阈值: 可能导致低SNR声音的误检。
2.低阈值: 可能导致多个声音被检测为一个单一声音。
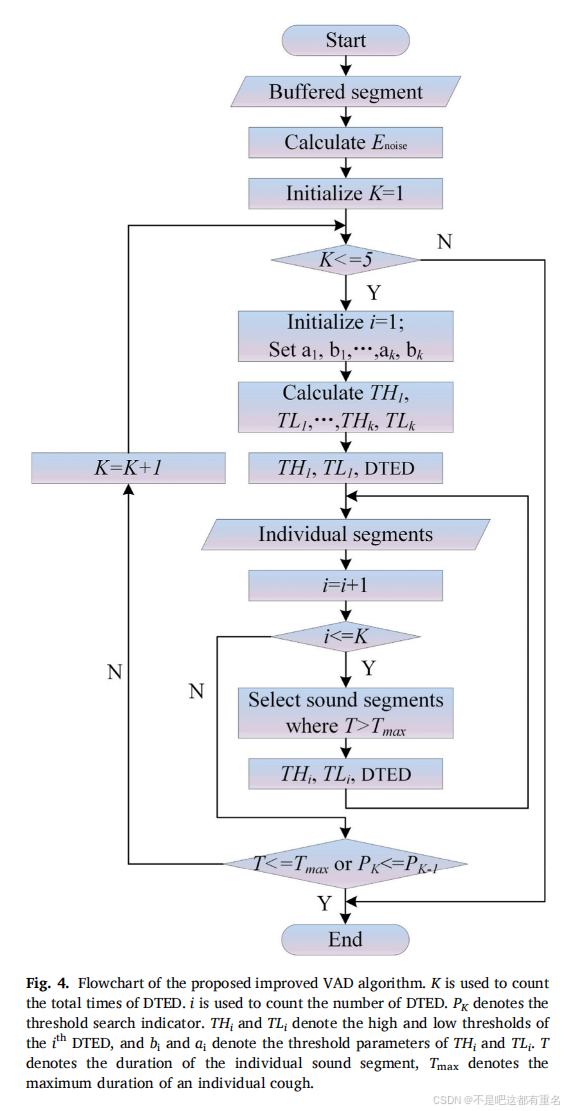
为解决这些问题,本文提出了一种改进的VAD算法,通过设置自适应多重阈值来优化检测过程,算法流程图如图4所示。
在DTED方法中设置了两个阈值。高阈值(
T
H
TH
TH)用于首次粗略判断声音是否活跃,低阈值(
T
L
TL
TL)用于确定活跃声音的起始和结束时间。定义
N
N
N帧背景噪声的能量为
E
n
o
i
s
e
E_{noise}
Enoise:
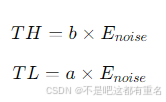
其中,
a
a
a和
b
b
b为经验设定或通过搜索获得的常数。
首先设定低阈值参数
a
1
a_1
a1和
b
1
b_1
b1,并对连续声音进行第一次DTED,以获得单一声音片段。若片段时长均小于最大单个咳嗽时长(
T
m
a
x
T_{max}
Tmax),则结束检测,否则重新设定
a
1
a_1
a1和
b
1
b_1
b1为更高的阈值参数
a
2
a_2
a2和
b
2
b_2
b2,并对时长大于
T
m
a
x
T_{max}
Tmax的声音片段进行第二次DTED。若获得的检测概率高于之前的检测概率,则继续重复上述步骤,直至所有片段时长小于
T
m
a
x
T_{max}
Tmax或DTED次数超过5次。
T
m
a
x
T_{max}
Tmax为实验数据统计得出的单个咳嗽的最大时长。所有阈值参数
a
a
a和
b
b
b均通过线性搜索进行优化。
在研究中发现,漏帧对分类性能的影响大于误帧,因此应尽量减少漏帧数。在此情况下,作为阈值搜索指标的帧检测概率无法准确反映漏帧和误帧的情况,因此我们定义了一个新的阈值搜索指标:
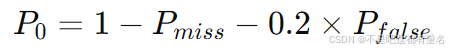
其中,
P
m
i
s
s
P_{miss}
Pmiss和
P
f
a
l
s
e
P_{false}
Pfalse分别表示帧漏检概率和帧误检概率,定义如下:
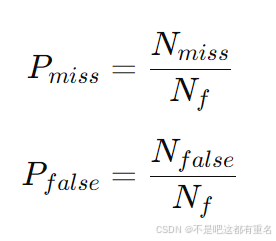
这里,
N
f
N_f
Nf代表一个声音片段的总帧数,
N
m
i
s
s
N_{miss}
Nmiss和
N
f
a
l
s
e
N_{false}
Nfalse分别代表漏帧和误帧的数量。由于背景噪声变化迅速,噪声能量实时更新:
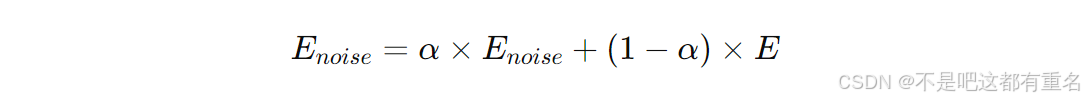
其中,
α
\alpha
α表示更新率,通常取值范围为0.9至0.98,较小的
α
\alpha
α表明更新速率更快,
E
E
E为当前噪声帧的能量。
3.3 改进分类算法
复杂的猪舍环境给准确识别猪咳嗽带来了巨大挑战。仅依赖单一分类器难以达到高准确率,多分类器融合提供了一种有效提升准确性的手段(Cui等, 2023; Ding等, 2023; Jiang等, 2021; Velpula & Sharma, 2023)。我们在多分类器融合方面开展了研究,基于单一声音数据集获得了99.2%的准确率(Yin等, 2023)。在该研究中,通过多种特征构建多个基分类器,但相比本文数据集,先前的数据集相对简单,未考虑复杂咳嗽和丰富的非咳嗽特征。本研究增加了更多差异性特征和鲁棒性更强的分类器进行集成学习,并优化了所有基分类器组合的选择。
我们将之前的分类器融合方法作为基准。以下首先介绍基准方法框架,然后提出改进的分类器融合算法。
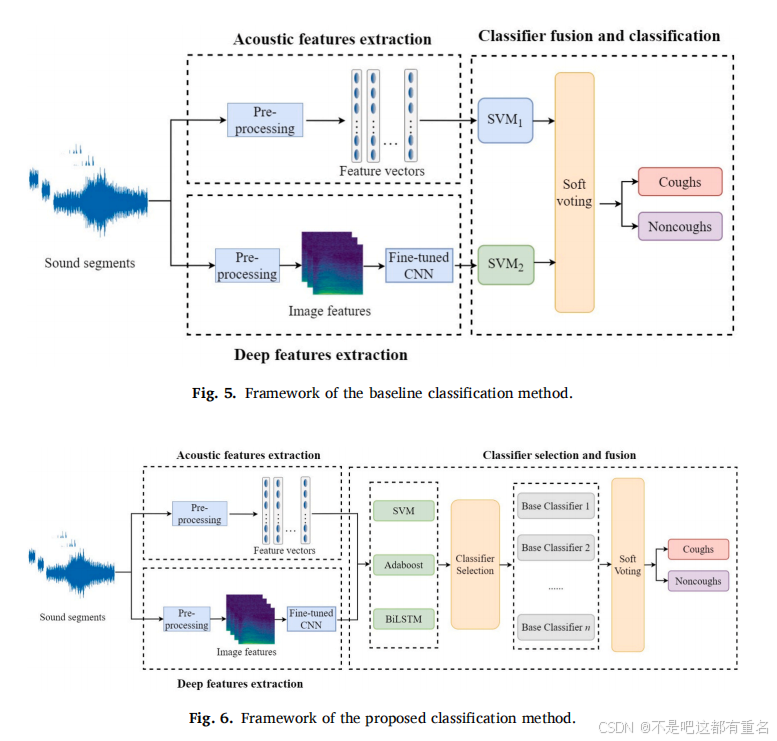
3.3.1 基线多分类器融合方法
基准方法的框架如图5所示。首先对单个声音片段进行预处理,并提取声学特征和深度特征。声学特征向量由梅尔频率倒谱系数(MFCC)和线性预测倒谱系数(LPCC)组成,深度特征则由微调的AlexNet从梅尔频谱图中提取。将MFCC与LPCC融合后,声学特征和深度特征分别输入两个SVM,最后通过软投票做出决策。
3.3.2 改进多分类器融合方法
改进后的多分类器融合方法框架如图6所示。我们选择了更加独特的特征和鲁棒性更强的分类器,并设计了一个分类器选择算法,以优化基分类器组合的选择。首先对声音片段进行预处理并提取声学特征和深度特征。LPCC在复杂环境中表现较差,因此选择MFCC和PSD作为声学特征。深度特征从频谱图、梅尔频谱图、常数Q变换(CQT)和MFCC彩色矩阵图的图像特征中提取。为降低复杂度,使用轻量级网络SqueezeNet替代AlexNet来提取深度特征。将声学特征和深度特征分别输入到SVM、自适应提升(AdaBoost)和双向长短时记忆网络(BiLSTM)等不同分类器中,利用分类器选择方法选择基分类器进行融合,最终通过软投票做出决策。
3.3.3 分类器选择的评价指标
在多分类器融合算法中,基分类器的选择是影响分类性能的关键步骤。选择基分类器时,不仅要选择高准确率的分类器,还需选择基分类器间差异较大的(Sagi & Rokach, 2018; Shiue等, 2021)。本文定义了一个准确率–多样性(AD)指标用于选择基分类器:
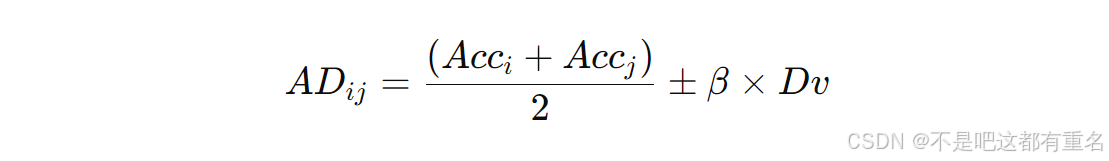
其中,
A
c
c
Acc
Acc为基分类器的准确率,
D
v
Dv
Dv为多样性度量。常用的多样性评价指标包括Q统计量、相关系数、不一致度量和双故障度量(Kuncheva & Whitaker, 2003)。若较大的
D
v
Dv
Dv表示较差的多样性,则使用减号,否则使用加号。权重
β
\beta
β用于平衡准确率和多样性。设所有基分类器的最大和最小准确率分别为
A
c
c
m
a
x
Acc_{max}
Accmax和
A
c
c
m
i
n
Acc_{min}
Accmin,多样性度量的最大和最小值分别为
D
v
m
a
x
Dv_{max}
Dvmax和
D
v
m
i
n
Dv_{min}
Dvmin,则
β
\beta
β可计算为:
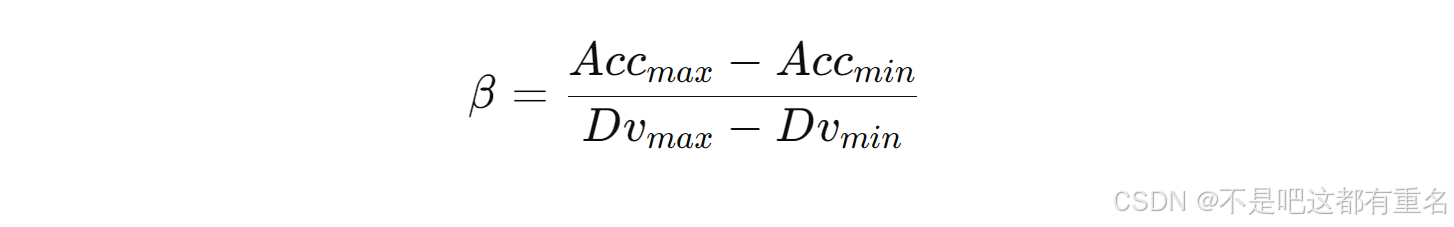
3.3.4 分类器选择
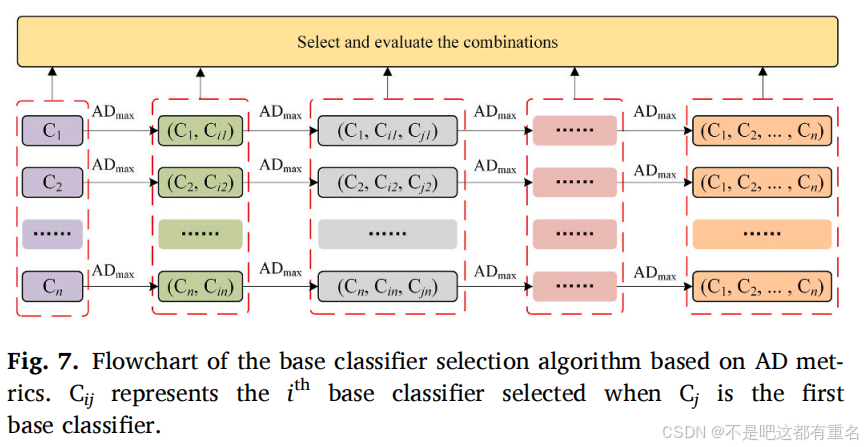
猪舍环境的复杂性导致数据样本的多样性极大,这反过来也使基分类器之间的多样性产生一定波动。因此,分类器选择算法应既高效又稳定可靠。本文提出的基分类器选择算法流程如图7所示。假设有
n
n
n个基分类器
C
1
,
C
2
,
…
,
C
n
C_1, C_2, …, C_n
C1,C2,…,Cn,我们依次选择每一个基分类器并根据分类器选择指标
A
D
AD
AD选取第二个基分类器。然后计算剩余基分类器与前两个基分类器之间的平均
A
D
AD
AD值,并选择第三个基分类器。重复此过程,直到选择出
n
n
n个基分类器。通过算法评估所有选中的组合并选择最佳组合作为最终的融合方案。该方法比选择所有组合更为高效,同时我们还采用数据扰动(Jiang等, 2021)来增加选择后的基分类器组合的多样性。
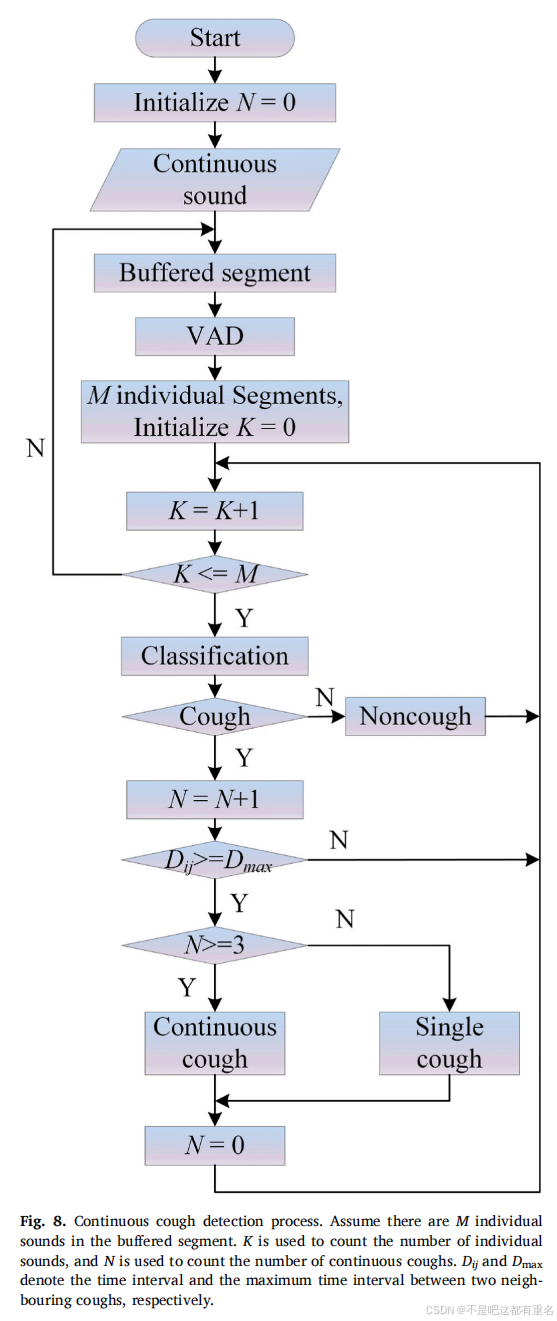
3.4 连续咳嗽声检测
连续咳嗽检测流程如图8所示。首先通过改进的VAD算法从缓冲的片段中检测出各个单独声音段,判断其是否为咳嗽声。如果不是咳嗽,则进入下一步分类判断。若检测到的咳嗽数量大于或等于3,并且相邻两个咳嗽之间的时间间隔小于最大咳嗽间隔,则判断为连续咳嗽,否则判断为单个咳嗽。最大咳嗽间隔是根据实验数据统计得出的数值。
3.5评价指标
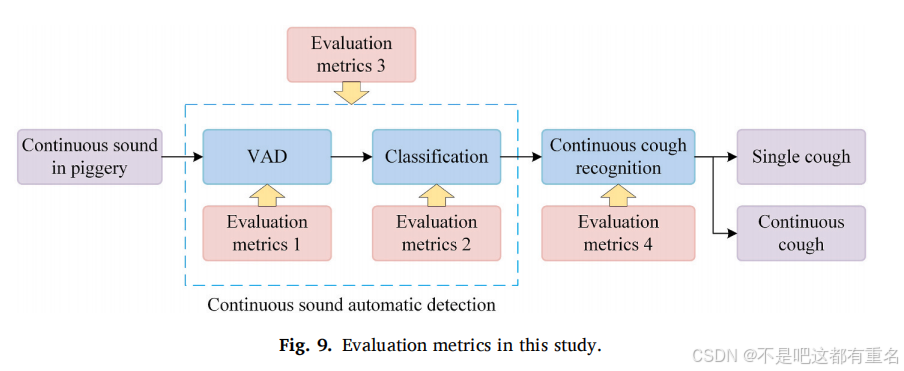
在不同流程中使用了四组评估指标,如图9所示。我们使用指标1和指标2来分别评估VAD和单个声音分类算法。连续声音自动检测过程包括VAD和单声音分类,因此使用指标3进行评估。指标4用于连续咳嗽识别的评估。
3.5.1 VAD的评估指标
根据帧漏检概率
P
m
i
s
s
P_{miss}
Pmiss和帧误检概率
P
f
a
l
s
e
P_{false}
Pfalse的定义(见公式(4)和(5)),我们可以得到帧检测概率
P
d
P_d
Pd,定义如下:
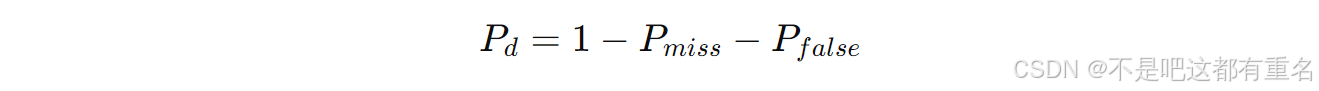
此外,还定义了以词向量为单位的咳嗽检测概率
P
w
d
P_{wd}
Pwd,定义如下:
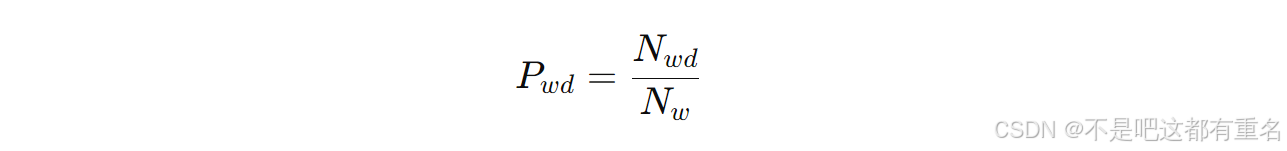
其中,
N
w
d
N_{wd}
Nwd和
N
w
N_w
Nw分别表示检测到的咳嗽数和咳嗽总数。在此我们不考虑帧误检,只要将某段声音检测为咳嗽声,则计为正确识别的咳嗽。
3.5.2 分类的评价指标
我们使用四个常用的评估指标:准确率、召回率、精确率和F1分数来评估单声音的分类。设
T
P
TP
TP为正确识别为咳嗽的咳嗽数,
T
N
TN
TN为正确识别为非咳嗽的非咳嗽数,
F
N
FN
FN为误识别为非咳嗽的咳嗽数,
F
P
FP
FP为误识别为咳嗽的非咳嗽数,则:

3.5.3 连续声音自动检测的评估指标
我们使用召回率(
R
e
c
a
l
l
C
Recall_C
RecallC)和精确率(
P
r
e
c
i
s
i
o
n
C
Precision_C
PrecisionC)来评估连续声音自动检测系统。设所有连续声音中包含的咳嗽数为
N
c
s
N_{cs}
Ncs,考虑到VAD的漏检和单声音分类中的误识别,正确检测的咳嗽数为
N
d
c
s
N_{dcs}
Ndcs,非咳嗽被检测为咳嗽的数量为
N
f
c
s
N_{fcs}
Nfcs,则:
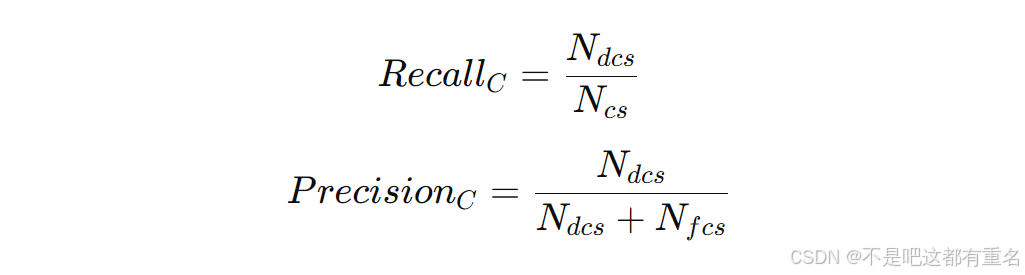
3.5.4 连续咳嗽识别的评估指标
我们使用连续语音识别中的词错误率(WER)作为猪连续咳嗽识别的评估指标。WER定义为:
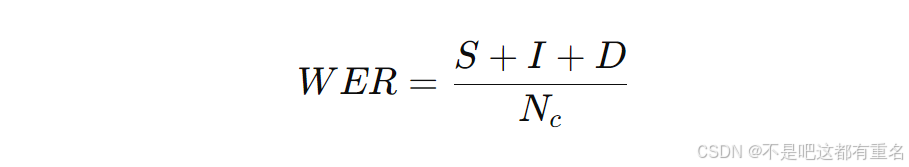
其中,
S
S
S为替换数,
I
I
I为插入数,
D
D
D为删除数,
N
c
N_c
Nc为连续咳嗽中的咳嗽总数。例如,一个连续咳嗽标记为(咳嗽, 咳嗽, 咳嗽, 咳嗽)。若检测结果为(咳嗽, 咳嗽, 咳嗽, 咳嗽, 咳嗽),多出的咳嗽为插入错误;若检测结果为(咳嗽, 咳嗽, 非咳嗽, 咳嗽),非咳嗽即为替换错误;若检测结果为(咳嗽, 咳嗽, 咳嗽),则漏掉的咳嗽为删除错误。
此外,还定义了连续咳嗽检测准确率
P
d
c
P_{dc}
Pdc来评估所提出的连续咳嗽检测算法的性能,定义如下:
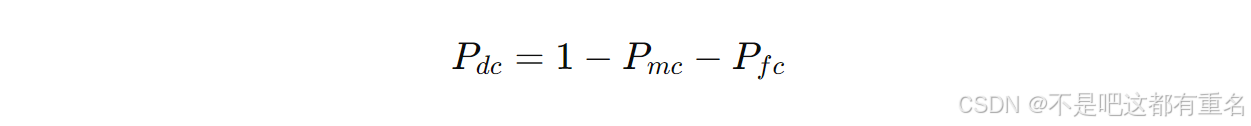
其中,
P
m
c
P_{mc}
Pmc为连续咳嗽漏检概率,
P
f
c
P_{fc}
Pfc为连续咳嗽误检概率,定义如下:
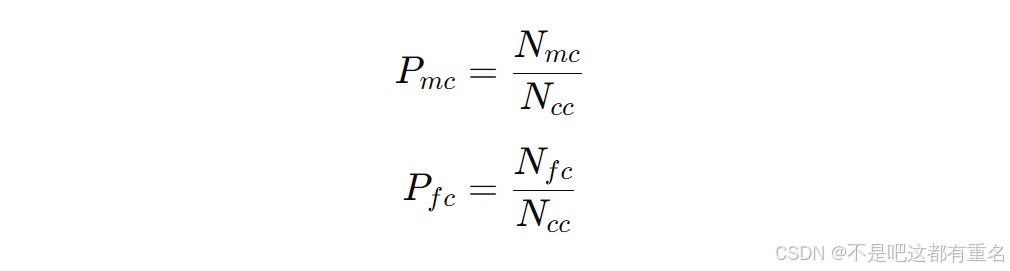
其中,
N
c
c
N_{cc}
Ncc表示连续咳嗽的总数,
N
m
c
N_{mc}
Nmc表示连续咳嗽的漏检数,
N
f
c
N_{fc}
Nfc表示连续咳嗽的误检数。在一个连续咳嗽中,即便某些单独咳嗽被误识别,只要至少一个咳嗽被正确识别为连续咳嗽,便视为该连续咳嗽被正确识别。例如,一个连续咳嗽标记为(咳嗽, 咳嗽, 咳嗽, 咳嗽, 咳嗽, 咳嗽, 咳嗽)。如果误识别为(咳嗽, 咳嗽, 咳嗽, 咳嗽, 非咳嗽, 非咳嗽),并检测出前四个咳嗽为一个连续咳嗽,则视该连续咳嗽为正确识别。
4.结果
在本章中,我们描述了本研究的实验结果。首先,介绍实验参数设置;其次,分析改进的VAD和分类方法的性能;再次,描述连续声音自动检测的性能;最后,展示连续咳嗽识别的结果。
4.1 实验参数
实验在配置为Intel Core i5-11400H CPU(2.70 GHz)和NVIDIA GeForce RTX 3050 GPU(4 GB显存)的计算机上进行,使用的分析软件为MATLAB 2021b。
本研究使用了深度学习工具箱和统计与机器学习工具箱。所有参数均通过优化过程仔细选择,并从计算与性能角度进行设置。SVM的“kernelFunction”设为“RBF”,核尺度“kernelScale”设为“auto”;AdaBoost的“NumLearningCycles”设为500,“Learners”为“templateTree”,“MaxNumSplits”设为5。在预处理步骤中,预加重系数为0.9375,FIR带通滤波器范围为100–16000 Hz,每帧时长为20毫秒,帧重叠为10毫秒,采用汉明窗。MFCC维数为13,提取PSD时快速傅里叶变换窗口长度为1024。对预训练卷积神经网络进行微调时,批次大小设为128,学习率为0.0001,训练轮数为30,优化器为Adam,损失函数为交叉熵。BiLSTM的参数设置如下:批次大小为64,学习率为0.001,训练轮数为300,隐藏层数为200,优化器为Adam,损失函数为交叉熵,输出模式为“last”。
4.2VAD的结果
在猪咳嗽的检测中,设置了咳嗽的有效声音片段长度为0.2至1.1秒,以过滤部分干扰信号。根据数据库中的数据计算出咳嗽时长的统计范围为0.22至0.97秒。对于提出的VAD方法,得到三组阈值:(2, 2.4)、(5, 5.5)和(15, 16),更新率 α \alpha α设为0.92。
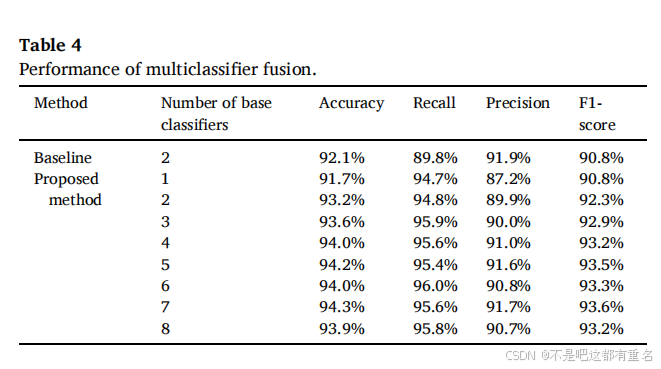
我们将提出的方法与传统DTED方法、基于双重阈值频带方差检测(DTFBVD)方法和基于双重阈值MFCC反谱距离检测(DTMISD)方法(Zhang等, 2020)进行了比较。结果如表2所示。传统方法在复杂环境中的检测概率明显较低,最高为DTED方法的词检测概率,仅为75.8%。而本方法的咳嗽检测概率达97.6%,显著高于传统方法。尽管本方法的帧误检概率略高,但帧漏检概率大幅减少,从而获得更高的帧检测概率(66.7%)。结果分析发现,未成功检测的咳嗽大多受到强干扰影响。
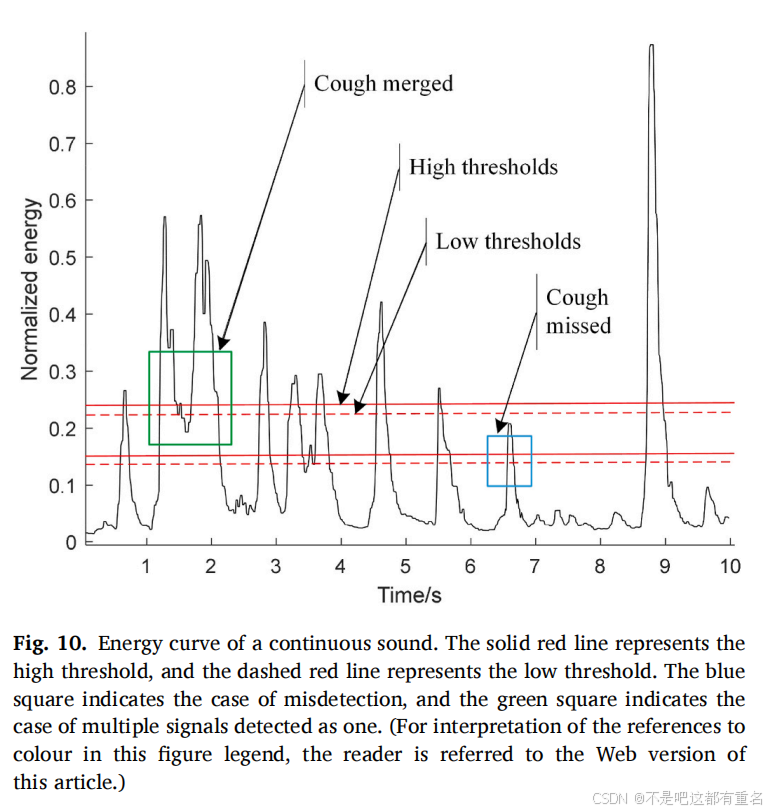
为了更清楚地说明提出的VAD算法的优势,我们展示了一段连续声音的能量曲线,如图10所示。实线红色表示高阈值,虚线红色表示低阈值。对于传统的双重阈值方法,一般选择一组阈值。高阈值会导致部分声音片段被漏检,如蓝色框所示,而低阈值则会导致多个声音被检测为一个声音,如绿色框所示。提出的VAD方法能够解决此类问题并提高检测概率。
4.3分类结果
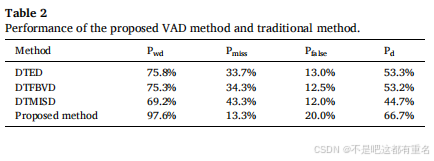
我们选择了两种声学特征、四种图像特征和三种分类器来构建基分类器。共有十八种组合可供选择。我们首先根据准确性排名和特征多样性选择了八个基分类器进行进一步选择和融合。SqueezeNet从图像特征中提取深度特征。选择的基分类器的性能如表3所示。
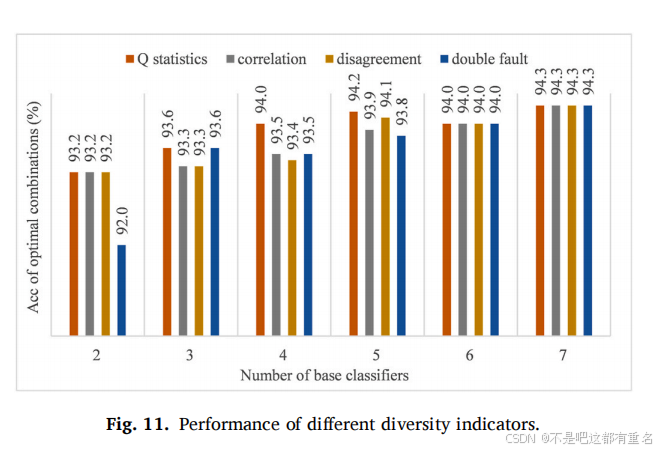
接下来,我们进一步选择最佳的融合分类器数量和融合方案。根据3.3节中描述的准确率-多样性评价指标和分类器选择方法,图11显示了不同数量基分类器融合的最佳组合准确率,其中横坐标表示融合基分类器的数量,纵坐标表示所选最佳基分类器组合的准确率。可以看到,Q统计量在所有组合中表现最佳,相关性和不一致性具有相似的性能,而双故障在不同数量的融合分类器下表现各异。当融合分类器数量为七个时,四个指标均达到相同的准确率。为了进一步验证所提出选择方法的可靠性及其在复杂环境中的适应性,我们融合了所有基分类器组合,发现使用Q统计量的基分类器组合基本上是选择方法获得的最佳组合。
我们将提出的多分类器融合方法(Q统计量)与基准方法(Yin等, 2023)进行了比较,结果如表4所示。基准方法在先前研究中实现了99.2%的准确率,但由于本研究数据库的复杂性,准确率下降至92.1%。提出的方法在融合两个分类器时达到了93.2%的准确率。随着融合基分类器数量增加,准确率逐渐提高,在融合八个分类器时略有下降。当融合七个基分类器时,最高准确率达94.3%。结果表明,通过增加特征和分类器的多样性并优化基分类器的选择和融合,可有效提高模型的抗干扰能力和准确性。
4.4连续声音自动检测结果
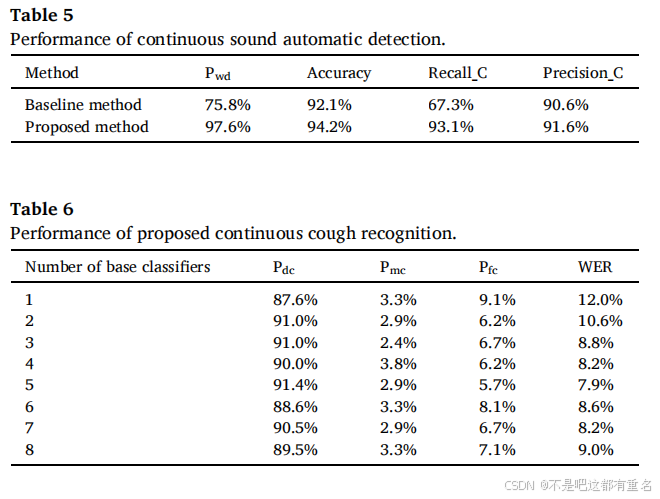
连续声音自动检测的性能如表5所示。基准检测方法由DTED算法和基准分类算法组成,而提出的检测方法由改进的VAD算法和改进的多分类器融合算法组成。结果显示,提出的连续声音自动检测算法获得了较高的检测准确率,召回率和精确率分别为93.1%和91.6%,明显高于基准方法。由于基准方法的VAD性能较差,其召回率仅为67.3%,远低于提出的方法。提出的方法确保了VAD和分类的准确性,从而实现了高精度的咳嗽声自动检测。
4.5连续咳嗽识别结果
连续猪咳嗽识别结果如表6所示。根据统计,相邻咳嗽之间的最大时间间隔设为1.5秒。可以看到,随着融合分类器数量的增加,词错误率(WER)显著降低,最低WER为7.9%。连续咳嗽识别的最佳检测准确率达到91.4%。结果表明,所提出的方法在复杂的猪舍环境中有效且可靠。
5.讨论
本研究的主要贡献在于实现了复杂猪舍环境中连续声音的自动检测及连续咳嗽声的识别,这对于算法的工程应用和疾病的诊断具有重要意义。之前的研究大多关注于单个声音的分类,忽视了连续声音的识别过程。尽管在单声音分类过程中已取得高精度,但没有考虑自动声音分割引起的精度损失。通过本研究发现,传统VAD方法在复杂猪舍环境中的检测概率较低,导致猪咳嗽的漏检率较高。Li等人(2019)和Zhao等人(2020)研究了基于BiLSTM-连接时间分类模型和深度神经网络-隐马尔科夫模型的连续声音识别。在这些研究中,他们同样使用了传统的DTED方法进行VAD,但未考虑VAD过程中的漏检问题。
在高信噪比且无其他声音重叠的情况下,本文提出的VAD算法与DTED方法的效果相当,检测准确率可达99%以上。然而,在大型猪舍中,信噪比随时间快速变化,咳嗽声易被其他声音覆盖,导致传统VAD方法的检测概率较低。我们尝试了其他先进的VAD方法,但它们在复杂猪舍环境中的表现同样不佳。
在多分类器融合方面,之前的研究仅考虑了少量的特征和分类器,而本文更全面地考虑了多种特征和分类器,选择了更具差异性的特征和更强鲁棒性的分类器进行集成学习。尽管LPCC特征在我们之前的研究中表现良好,但在本研究的复杂数据集中对噪声敏感,因此未予使用。我们还尝试了其他分类器,如k近邻(k-NN)和随机森林,其性能与SVM相当或略逊一筹,因此仅保留了SVM分类器。此外,基分类器的经验性选择可能导致次优的融合效果,选择所有组合的计算复杂度也较高。本文提出的分类器选择算法在确保分类器融合性能的同时,大大降低了计算复杂度。
目前没有公开的猪咳嗽数据集,现有研究均基于其私有数据集。本研究的数据集充分考虑了实际猪舍环境的复杂性,使所提出的方法更适合实际工程应用。数据集对分类结果有显著影响,同一算法在不同数据集上的分类准确性会有所不同。在我们之前的简单数据集(Yin等, 2023)上,本文提出的分类方法同样达到了99%以上的分类准确率。然而,在我们新设计的更接近真实猪舍环境的复杂数据集上,咳嗽识别准确率下降至94.2%,但仍比基准方法(92.1%)高出2.1%。分类准确率还会受到数据集中样本数量的影响,若样本数量过少或不平衡,分类准确率可能降低。在本研究中,我们未对非咳嗽声进行进一步标注。由于非咳嗽声音种类繁多,无法保证每种非咳嗽声的数量均等。我们尝试增加训练数据集中非咳嗽声的数量,发现随着非咳嗽声音数量的增加,准确率逐渐提高,当数量达到约2000时,准确率基本保持稳定。
在之前的研究中(Shen等, 2022; Yin等, 2023),我们深入讨论了不同神经网络在不同图像特征输入下的表现,并得出浅层卷积神经网络(如AlexNet)在处理猪咳嗽识别任务时优于深层卷积神经网络(如VGG16、VGG19、ResNet152),且梅尔频谱图的效果略优于CQT和普通频谱图。为了降低模型复杂性并便于工程应用,我们用轻量化的SqueezeNet替代AlexNet。实验结果表明,SqueezeNet与AlexNet的性能相似。在集成学习模型中,我们使用了SVM和轻量化的深度学习模型以减少内存占用,这使得模型在工程应用中具有良好的实用性。虽然随着融合分类器数量的增加,性能逐渐提高,但复杂度也会随之增加。在实际应用中,可以选择两到三个基分类器,以在复杂性和准确性之间进行折衷。
未来的研究方向包括探索基于端到端模型的连续咳嗽自动检测方法,以进一步提高准确性并降低模型复杂度。同时,我们计划进一步研究不同类型咳嗽的识别,如干咳和湿咳。此外,还将考虑基于麦克风阵列的猪咳嗽识别和定位研究。
6.总结
在本研究中,我们研究了一种在复杂猪舍环境中自动检测连续猪咳嗽的方法。所提出的改进VAD算法通过采用多重自适应动态阈值,有效地解决了传统方法的局限性,大大提高了检测概率,达到97.6%。改进的多分类器融合方法在复杂环境下有效提升了识别准确率,达到94.3%。在提高VAD和分类准确率的前提下,所提出的连续声音自动检测方法的召回率和精确率分别为93.1%和91.6%,而连续咳嗽识别方法则实现了91.4%的高准确率和7.9%的低词错误率(WER)。本研究为实际工程应用提供了有力的技术支持。未来工作中,我们将进一步提高准确率并降低模型的复杂性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











