







文章目录
DQL语言
1. 基础查询
基础查询即只有select和from的查询。
语法:
select 查询列表 from 表名; # 不是from库名
-- 查询的基本语法如上所示
-- 查询列表可以是:表中的字段、常量值、表达式、函数,可以由多个部分组成,用逗号隔开
-- 例如:select id,name from user;
-- select count(*) from user;
特点:
查询的结果集是一个虚拟表,不是实际数据库中的表
select 查询列表类似于System.out.println(打印内容)
区别: select后面的查询列表可以由多部分组成,逗号隔开,
System.out.println()的打印内容只能有一个
执行顺序: 1.from子句,2.select子句
1.1 查询字段
1.1.1 查询单个字段
-- 语法
select 字段名 from 表名;
-- 示例
select id from user;
1.1.2 查询多个字段
-- 逗号隔开
-- 示例
select id,name,sex from user;
1.1.3 查询全部字段
-- 语法:有两种方式,一种是按照查询多个字段的方式写出所有字段名,另外一种是使用通配符"*"号
select 字段名,字段名,字段名,... from 表名;
# 或
select * from 表名;
-- 示例
select * from user;
1.2 无意义查询?
1.2.1 查询常量
-- 语法:直接在select后面跟常量,没有实际意义
select 常量值;
-- 示例
select 100;
select '张三';
1.2.2查询表达式
-- 语法:直接在select后面跟运算表达式
select 表达式;
-- 示例
select 100%12;
1.3 查询函数
(调用函数,获取返回值)
-- 语法:直接在select后面跟函数名
select 函数名;
-- 示例
SELECT VERSION();
SELECT DATABASE();
SELECT USER();
1.4 起别名
别名的用处:
①便于理解,有些字段可能过长
②如果在多张表的查询中有重复的字段的情况,可以使用别名区分开来。
注意:
①可以对表名起别名。
②也可以对字段名起别名。
起别名的方式:
- 使用AS关键字
- 使用空格
-- 语法:其中[AS]是一个可选项,即可以使用AS表明,也可以省略不写,都表示是别名
select 字段名 [AS] 别名 from 表名;
-- 示例
select last_name AS 姓,first_name AS 名 from user;
select last_name 姓,first_name 名 from user;
-- 特别注意:如果别名中含有如空格这样的特殊字符,要用双引号或单引号引起来
select salary AS "工 资" from employee;
1.5 "+"号运算
MySQL中加号运算:仅数字运算符作用
| 加号俩端数据类型 | 处理方式 | 例 | 结果 |
|---|---|---|---|
| 都是数值型 | 加法运算 | SELECT 100+90 | 190 |
| 至少一方是非数值型 | 将非数值类型转换为数值类型,转换成功做加法运算,转换失败先转为0再做加法 | SELECT ‘a’+100 | 100 |
| 至少一方是null | 结果一定为null | SELECT null+100 | null |
如果有一个需求: 查询first_name和last_name拼接成的全名,并且起别名为姓 名,处理方式:
- 方案一: 使用"+": 不行,在java中+可以当字符拼接符,MySQL中不行
- 方案二: 使用concat()拼接函数:
SELECT CONCAT(first_name,last_name) AS "姓 名"
FROM employees;
1.6 去重
去重的含义是去掉重复的记录,只需要在select后面跟DISTINCT关键字即可
-- 语法
select distinct 字段名 from 表名;
-- 示例
select distinct name from user;
IFNULL(表达式1,表达式2)函数:
-- 表达式1 : 可能为null的字段或表达式
-- 表达式2 : 如果1为null,则最终结果显示的值
-- 功能: 如果1为null,则显示2,否则显示1
1.7 查看表的结构
-- 1. 基础方法: DESC 表名;
-- 2. 进阶方法: SHOW COLUMNS FROM 表名;
# 例:
DESC name;
SHOW COLUMNS FROM name;
2. 条件查询
# 基本语法:
SELECT 查询列表
FROM 表名
WHERE 筛选条件;
# 执行顺序:1.FROM子句2.WHERE子句3.SELECT子句
# 每走完一个子句都得到一个虚拟的表(查询结果)
# 例如:求男性工资大于5000:
SELECT man FROM user WHERE salary>5000;
条件查询按情况分为三类:
-
按条件表达式筛选
-
按逻辑表达式筛选
-
模糊查询
2.1 按条件表达式筛选
常用的条件运算符有:>、<、=、!=、<>、>=、<=等。
注意 :
- 一个等于号
- MySQL中不等于为<>,但也兼容了java的!=
-- 语法
select 查询列表 from 表名 where 字段名 条件运算符 常量值
-- 示例
select * from user where sex='男';
select * from user where age>=18;
2.2 按逻辑表达式筛选
在MySQL中的逻辑运算符主要有:and、or、not。分别对应与、或、非。
分别对应于java中的:&& , || , ! ,MySQL中也兼容了这种写法
-- 语法
# AND和OR运算符的语法
select 查询列表 from 表名 where 条件表达式1 [AND|OR] 条件表达式2;
# NOT运算符的语法
select 查询列表 from 表名 where NOT(条件表达式);
-- 示例
select * from user where age>=18 AND age<=24;# 查询年龄在18到24的用户信息
select * from user where NOT(age>=18 AND age<=24);# 查询年龄不在18到24的用户信息
2.3 模糊查询
模糊查询部分匹配,不是完全匹配
模糊查询有以下几个关键字并按此分类:
- like
- in
- between and
- is null/is not null
2.3.1 like
like一般和通配符搭配使用,对字符型数据进行匹配
常见俩个通配符:
-
%:匹配任意多个字符,也包含0个字符.
如’%e%'表示e前面后面都可以有任意个字符
'%e’表示e前面可以有任意个字符,后面不可以再包含字符 -
_:匹配任意单个字符.
如:’__e’表示第三个字符为e,后面不再包含字符
-- 语法
select 查询列表 from 表名 where 字段名 like 匹配的字符串;
-- 示例
select * from user where name like '%王%';# 查询用户名中带有"王"的记录
select * from user where name like '_玲';
# 查询用户名中第二个字符为"玲"的记录
如果要去匹配"%“和” _ "字符,那么就需要进行转义,转义的语法如下:
-- 语法:
'任意字符_' ESCAPE '任意字符'
# 表示将任意字符设置为转义字符
-- 示例:
'$_' ESCAPE '$'; # 将$设置为转义字符
# 匹配名字为"_三"的记录,这里"_"作为一个普通字符而不是通配符使用
转义后:select * from user where name like '/_三' ESCAPE '/';
# 表示"/"之后的"_"不作为通配符
# 也可以直接:
select * from user where name like '/_三'
# MySQL兼容了这种写法,但不推荐
也有not like
2.3.2 in
in用来判断某字段的值是否属于in列表中的某一项。
即某字段是否属于指定列表之内
也有 not in
特点如下:
①使用in提高语句简洁度
②in列表的值类型必须一致或兼容(即类型需一致)
③in列表中不支持通配符
-- 语法
select 查询列表 from 表名 where 字段名 IN (匹配的列表);
-- 示例
select * from user where sex in ('男','女');
# 匹配性别为"男"或"女"的记录
# 等价于:
SELECT * from user where sex = '男' OR sex = '女';
-- 使用in比以上语句简洁
SELECT *
FROM employees
WHERE job_id NOT IN('SH_CLERK','IT_PROG');
# 查询工种编号既不是SH_CLERK也不是IT_PROG的
2.3.3 between and
between and用来匹配在一个范围内的记录,如年龄在18到24的记录。
between and的特点如下:
①使用between and 可以提高语句的简洁度
②包含临界值
③两个临界值不要调换顺序
-- 语法
select 查询列表 from 表名 where 字段名 BETWEEN 起始临界值 AND 结束临界值;
-- 示例
select * from user where age>=18 and age<=24;# 使用条件运算符查询
select * from user where age BETWEEN 18 AND 24;
-- 上面的语句等价于该SQL句,使用between and限定范围
select * from user where age BETWEEN 18 AND 24;
-- 查询年龄不是18-24之间的
2.3.4 is null
=、!=、<>不能用来判断null值。
因此MySQL提供了is null和is not null来判断是否是null值。
-- 语法
select 查询列表 from 表名 where 字段名 IS NULL;# 判断某字段为null值的记录
select 查询列表 from 表名 where 字段名 IS NOT NULL;# 判断某字段不为null值的记录
-- 示例
select * form user where id IS NULL;# 查询id为null值的记录
select * from user where is IS NOT NULL;# 查询id不为null值的记录
注意:MySQL还提供了一个"<=>"安全等于用于判断null值和普通数值。
is null VS <=>:
-
IS NULL:仅仅可以判断NULL值,可读性较高,建议使用
-
<=>:既可以判断NULL值,又可以判断普通的数值,可读性较低
3. 排序查询
排序指按照某种顺序进行排列。
在MySQL中排序用到的关键字有ASC和DESC。
- ASC是"ascend"的缩写,意为"上升",表示升序;
- DESC是"descend"的缩写,意为"下降",表示降序。
基本语法如下:
select 查询列表
from 表名
[where 筛选条件]
ORDER BY 排序的字段或表达式 [ASC/DESC];
排序查询特点如下:
1、asc代表的是升序,可以省略;desc代表的是降序
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段或者列数,以及以上的组合
3、order by子句在查询语句的最后面(执行顺序也最后),除了limit子句
3.1 按单个字段排序
-- 语法:直接在ORDER BY后面添加单个字段排序
# 按单个字段进行升序或降序排列
select 排序列表 from 表名 ORDER BY 字段名 [DESC|ASC];
-- 示例
# 按工资进行降序排列
select * from employees ORDER BY salary DESC;
3.2 添加条件再排序
-- 语法:在ORDER BY之前添加where进行条件筛选
SELECT 排序列表 FROM 表名 WHERE 筛选条件 ORDER BY 字段名 [DESC|ASC];
-- 示例
# 查询部门编号>=90的员工信息,并按员工编号降序
SELECT * FROM employees where department_id>=90 ORDER BY employee_id DESC;
3.3 按表达式筛选
-- 语法:在ORDER BY后面跟着计算的表达式进行排序
SELECT 排序列表 FROM 表名 ORDER BY 表达式 [DESC|ASC];
-- 示例
# 查询员工信息,按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
3.4 按别名排序
-- 语法:为字段添加别名,然后在ORDER BY后面用别名排序
select 字段1,字段2 别名,字段3,... from 表名 ORDER BY 别名 [DESC|ASC];
-- 示例
# 查询员工信息,按年薪升序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪 FROM employees ORDER BY 年薪 ASC;
3.5 按函数进行排序
-- 语法:使用函数对字段进行处理排序
SELECT 字段 FROM 表名 ORDER BY 函数(字段) [DESC|ASC];
-- 示例
# 查询员工名,并且按名字的长度降序
SELECT LENGTH(last_name),last_name FROM employees ORDER BY LENGTH(last_name) DESC;
3.6 按多个字段进行排序
-- 语法:可以在ORDER BY后面添加多个待排序的字段
SELECT 排序列表 FROM 表名 ORDER BY 字段名1 [DESC|ASC],字段名2 [DESC|ASC],...;
-- 示例
# 查询员工信息,要求先按工资降序,再按employee_id升序
SELECT * FROM employees ORDER BY salary DESC,employee_id ASC;
3.7 按列数排序
-- 较少使用,冗余性太强
-- 语法: 在ORDER BY后面直接写列数,则按表中第n列数据进行排序
-- 示例: 按第二列排序
SELECT * FROM employees ORDER BY 2 ASC;
4. 分组函数
对一组数据用来统计使用得到一个结果,所以又称为聚合函数或统计函数或组函数。
分组函数有如下几种:
- SUM:求和
- AVG:平均值
- MAX:最大值
- MIN:最小值
- COUNT:计算非空字段个数
分组函数的特点:
1、sum、avg一般用于处理数值型,max、min、count可以处理任何类型。
2、以上分组函数都忽略null值,即只有一行中有任意一列不为NULL,都会被分组函数统计在内。
3、可以和distinct搭配实现去重的运算。
4、count函数的单独介绍,一般使用count(*)用作统计行数。
5、和分组函数一同查询的字段要求是group by后的字段。
4.1 简单应用
-- 语法
select 分组函数(字段名) from 表名;
-- 示例
SELECT SUM(salary) FROM employees;
SELECT AVG(salary) FROM employees;
SELECT MIN(salary) FROM employees;
SELECT MAX(salary) FROM employees;
SELECT COUNT(salary) FROM employees;
SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM employees;
4.2 和DISTINCT搭配使用
-- 语法,DISTINCT放在字段名之前,包含在分组函数之内
select 分组函数(DISTINCT 字段名) from 表名;
-- 示例
SELECT SUM(DISTINCT salary),SUM(salary) FROM employees;
SELECT COUNT(DISTINCT salary),COUNT(salary) FROM employees;
4.3 COUNT(*)和COUNT(1)
SELECT COUNT(salary) FROM employees;# 统计salary的总行数,如果salary字段为null值则不统计在内
SELECT COUNT(*) FROM employees;# 统计employees表的总行数,只要一行中有一个数据不为空就会被算上
SELECT COUNT(1) FROM employees;# 统计employees表的总行数,相当于在表中加上一个值全为1的常量列
效率:
- MYISAM存储引擎下 ,COUNT(*)的效率高
- INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些。
5. 分组查询
对一张表分成若干组,然后每个组统计分析得到一个结果
分组查询使用GROUP BY,语法如下:
select 查询列表
from 表名
[where 筛选条件]
GROUP BY 分组的字段
[having 分组后筛选]
[order by 排序的字段];
/*
执行顺序:
1. from
2. where
3. group up
4. having
5. select
6. order by
*/
特点:
- 1、分组函数外查询的字段必须是group by后出现的字段,即被分组的字段(注:查看简单分组的示例)
(查询其他字段无意义,不肯定其他字段如何分组) - 2、分组查询中的筛选条件分为两类:分组前筛选和分组后筛选
| 数据源 | 位置 | 关键字 |
|---|---|---|
| 分组前查询 | 原始表 | group by 子句的前面 |
| 分组后查询 | 分析后的结果集 | group by 子句的后面 |
注:一般来讲,能用分组前筛选的,尽量使用分组前筛选,提高效率。
- 3、分组可以按单个字段也可以按多个字段
- 4、可以搭配着排序使用
5.1 简单分组
-- 语法
select 查询列表 from 表名 GROUP BY 字段名;
-- 示例
SELECT AVG(salary),job_id FROM employees GROUP BY job_id;# 查询每个工种的员工平均工资
SELECT COUNT(*),location_id FROM departments GROUP BY location_id;# 查询每个位置的部门个数
5.2 实现分组前的筛选
-- 语法
select 查询列表 from 表名 WHERE 筛选条件 GROUP BY 字段名;
-- 示例
SELECT MAX(salary),department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;# 查询邮箱中包含a字符的每个部门的最高工资
SELECT AVG(salary),manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;# 查询有奖金的每个领导手下员工的平均工资
5.3 实现分组后的筛选
分组后的结果会形成一张新的虚拟表,也可以进行条件筛选,不过需要用到关键字HAVING。
-- 语法
select 查询列表
from 表名
[WHERE 分组前的筛选条件]
GROUP BY 字段名
HAVING 分组后的筛选条件;
-- 示例1:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
-- 示例2:查询哪个部门的员工个数>5
-- 分析: 先查询每个部门的员工个数,然后筛选哪个部门员工个数>5
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
-- 示例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
SELECT manager_id,MIN(salary)
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000;
5.4 添加排序
添加排序只需要在最后面添加一个ORDER BY子句即可。
-- 语法
select 查询列表 from 表名 [WHERE 分组前的筛选条件] GROUP BY 字段名 HAVING 分组后的筛选条件 ORDER BY 字段名;
-- 示例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
SELECT job_id,MAX(salary) m
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING m>6000
ORDER BY m ;
5.5 按多个字段排序
按多个字段分组只需要在GROUP BY后面添加多个待分组的字段即可。
-- 语法:
select 查询列表 from 表名 [WHERE 分组前的筛选条件] GROUP BY 字段名1,字段名2,字段名3,.. [HAVING 分组后的筛选条件] [ORDER BY 字段名];
-- 示例:查询每个工种每个部门的最低工资,并按最低工资降序
SELECT MIN(salary),job_id,department_id
FROM employees
GROUP BY department_id,job_id
ORDER BY MIN(salary) DESC;
6. 连接查询(多表查询)
当查询的字段来自于多个表时,就会用到连接查询。
笛卡尔乘积现象:表1有m行,表2有n行,查询结果m*n行
发生原因: 没有有效的连接条件
如何避免: 添加有效的连接条件
连接查询按年代分类可以分为:
sql92标准:仅仅支持内连接。(MySQL标准下)
sql99标准:支持内连接+外连接(左外和右外)+交叉连接,较为推荐。
按功能可以分为:
- 内连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接
- 右外连接
- 全外连接
- 交叉连接
6.1 sql92标准
6.1.1 等值连接
等值连接是我们使用最多的,就是求多张表的交集部分。
特点:
① 多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③ 多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
-- 基础语法
select 查询列表
from 表1,表2,...
WHERE 连接条件;(条件为"="的连接查询)
-- 示例1:查询女神名和对应的男神名
SELECT NAME,boyName
FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
6.1.1.1 为表起别名
取别名就是为了提高语句的简洁度和区分多个重名的字段。
但注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定(即只能用别名.字段名的方式查询字段)。
-- 语法
select 查询列表 from 表1 [AS] 别名1,表2 [AS] 别名2,... WHERE 连接条件;
-- 示例:查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM employees AS e,jobs AS j
WHERE e.`job_id`=j.`job_id`;
表顺序任意调换
6.1.1.2可以添加筛选条件,分组,与排序
筛选条件:
-- 语法
select 查询列表 from 表1,表2,... WHERE 连接条件 AND 筛选条件;
-- 示例1:查询有奖金的员工名、部门名
SELECT last_name,department_name,commission_pct
FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
AND e.`commission_pct` IS NOT NULL;
-- 示例2:查询城市名中第二个字符为o的部门名和城市名
SELECT department_name,city
FROM departments d,locations l
WHERE d.`location_id` = l.`location_id`
AND city LIKE '_o%';
分组:
-- 语法
select 查询列表 from 表1,表2,... WHERE 连接条件 [AND 筛选条件] [GROUP BY 分组字段];
-- 示例:查询每个城市的部门个数
SELECT COUNT(*) 个数,city
FROM departments d,locations l
WHERE d.`location_id`=l.`location_id`
GROUP BY city;
排序:
-- 语法
select 查询列表 from 表1,表2,... WHERE 连接条件 [AND 筛选条件] [GROUP BY 分组字段] [ORDER BY 排序字段 DESC|ASC];
-- 示例:查询每个工种的工种名和员工的个数,并且按员工个数降序
SELECT job_title,COUNT(*)
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`
GROUP BY job_title
ORDER BY COUNT(*) DESC;
6.1.1.3三表或以上查询
-- 语法
select 查询列表
from 表1,表2,...
WHERE 连接条件1
AND 连接条件2 ...
[AND 筛选条件]
[GROUP BY 分组字段]
[ORDER BY 排序字段 DESC|ASC];
-- 示例:查询员工名、部门名和所在的城市,且城市名s开头,并按部门名降序排序
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`
AND city LIKE 's%'
ORDER BY department_name DESC;
6.1.2 非等值连接
非等值连接指的是通过某种特定条件使两张表相连,WHERE后面跟着条件。
即将"="改为其他条件
-- 示例:查询员工的工资和工资级别
SELECT salary,grade_level
FROM employees e,job_grades g
WHERE salary BETWEEN g.`lowest_sal` AND g.`highest_sal`
# 逐一拿salary和每一行的最高最低工资匹配寻找工资级别
6.1.3 自连接
自连接必须借助别名来完成,对一个表起两个别名,当成两个表使用,自己与自己连接
用途可能是表中的某一字段的值正好是表中其他字段的值,比如评论表中的回复ID就是其他评论的主键ID。
-- 示例:查询员工名和上级的名称
# 表中有员工ID与领导ID,所以可把自己分别当成员工表与领导表
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
6.2 sql99标准
sql99标准中不仅有内连接还有外连接。
它的基本语法格式是:
-- 语法
select 查询列表
from 表1 别名1
[连接类型]
join(加入,在这里代表连接) 表2 别名2
on 连接条件
[WHERE 筛选条件]
[GROUP BY 分组]
[HAVING 筛选条件]
[ORDER BY 排序列表]
-- 注:
-- 连接类型有:内连接inner(内)、外连接之左外连接left outer(外)、外连接之右外连接right outer、外连接之全外连接full outer、交叉连接cross。其中inner、outer可以省略。
6.2.1 内连接
-- 内连接基本语法
select 查询列表
from 表1 别名1
INNER
join 表2 别名2
on 连接条件
[WHERE 筛选条件]
[GROUP BY 分组]
[HAVING 筛选条件]
[ORDER BY 排序列表]
也分为等值、非等值、自连接三种情况。
特点如下:
①添加排序、分组、筛选
②inner可以省略
③ 筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
④inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
总之,内连接都是查询多表的交集。
6.2.1.1 与sql92内连接区别:
- 将表从逗号隔开变成使用JOIN关键字
- 将连接条件与筛选条件加入ON关键字实现分离,提高代码可读性
6.2.1.2等值连接
-- 示例1:查询员工名、部门名
SELECT last_name,department_name
FROM departments d
INNER JOIN employees e
ON d.department_id=e.department_id;
-- 示例2:查询名字中包含e的员工名和工种名(添加筛选)
SELECT last_name,job_title
FROM employees e
INNER JOIN jobs j
ON e.`job_id`= j.`job_id`
WHERE e.`last_name` LIKE '%e%';
-- 示例3:查询部门个数>3的城市名和部门个数,(添加分组+筛选)
SELECT city,COUNT(*) 部门个数
FROM departments d
INNER JOIN locations l
ON d.`location_id`=l.`location_id`
GROUP BY city
HAVING COUNT(*)>3;
-- 示例4:查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序(添加排序)
SELECT COUNT(*) 个数,department_name
FROM employees e
INNER JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY department_name
HAVING COUNT(*)>3
ORDER BY COUNT(*) DESC;
-- 示例5:查询员工名、部门名、工种名,并按部门名降序(添加三表连接,俩次INNER JOIN)
SELECT last_name,department_name,job_title
FROM employees e
INNER JOIN departments d ON e.`department_id`=d.`department_id`
INNER JOIN jobs j ON e.`job_id` = j.`job_id`
ORDER BY department_name DESC;
6.2.1.3 非等值连接
非等值连接就是通过限定条件来使多张表关联,比如说一张表中某字段在另一张表的某两个字段的范围之内。
-- 示例1:查询员工的工资级别
SELECT salary,grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
-- 示例2:查询工资级别的个数>20的级别个数,并且按工资级别降序
SELECT COUNT(*),grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`
GROUP BY g.grade_level
HAVING COUNT(*)>20
ORDER BY grade_level DESC;
6.2.1.4 自连接
-- 示例1:查询员工的名字、上级的名字
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`;
-- 示例2:查询姓名中包含字符k的员工的名字、上级的名字(添加筛选)
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`
WHERE e.`last_name` LIKE '%k%';
6.2.2 外连接
外连接主要用于查询一个表中有,而另外一个表中没有的记录。
特点如下:
1、外连接的查询结果为主表中的所有记录(主表全部显示)
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录(所以显示主表所有记录)
2、左外连接,left join左边的是主表;右外连接,right join右边的是主表
3、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
-- 基本语法
select 查询列表
from 表1 别名1
LEFT|RIGHT|FULL [OUTER] JOIN 表2 别名2
ON 连接条件;
-- 示例:左外连接
SELECT b.*,bo.*
FROM boys bo
LEFT OUTER JOIN beauty b
ON b.`boyfriend_id` = bo.`id`;
6.2.2.1 左外连接
示例:
-- 示例:查询男朋友不在男神表的的女神名
SELECT * FROM beauty LEFT JOIN boys ON beauty.boyfriend_id=boys.id;
6.2.2.2 右外连接
示例:
SELECT * FROM beauty RIGHT JOIN boys ON beauty.boyfriend_id=boys.id;
6.2.3 全外连接
全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的,所以它的SQL语句为:
-- mysql不支持下面的全外连接,所以会报错
SELECT b.*,bo.*
FROM beauty b
FULL OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.id;
mysql 不支持 直接写full outer join 或者 full join 来表示全外连接但是可以用union联合查询 代替.
但可以用下面的语句来间接达到全外连接的效果:
SELECT * FROM beauty LEFT JOIN boys ON beauty.boyfriend_id=boys.id
UNION
SELECT * FROM beauty RIGHT JOIN boys ON beauty.boyfriend_id=boys.id;
如果要查询表1中有而表2中没有的以及表2中有而表1中没有的部分(全外连接去交集),则可以使用下面的SQL语句:
(一般查询没有的记录筛选条件为从表某项为IS NULL)
SELECT * FROM beauty LEFT JOIN boys ON beauty.boyfriend_id=boys.id
WHERE boys.id IS NULL
# 这里要的是从表的字段为NULL,左外连接的从表是LEFT JOIN后面的表
UNION # 连接两个查询结果集
SELECT * FROM beauty RIGHT JOIN boys ON beauty.boyfriend_id=boys.id
WHERE beauty.boyfriend_id IS NULL;
# 这里要是从表的字段为NULL,右外连接的从表是RIGHT JOIN前面的表
6.2.4 内外连接(JOIN连接)总结
6.2.4.1 左外连接:
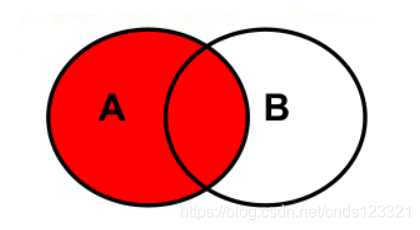
-- SQL语句如下:
SELECT 查询列表 FROM A
LEFT JOIN B
ON A.key=B.key# 其中A.key=B.key指的是连接条件
6.2.4.2 右外连接
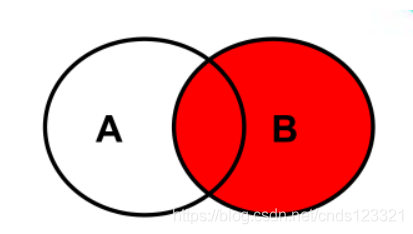
-- SQL语句如下:
SELECT 查询列表 FROM A
RIGHT JOIN B
ON A.key=B.key# 其中A.key=B.key指的是连接条件
6.2.4.3 内连接
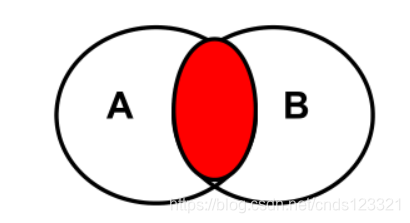
-- SQL语句如下:
SELECT 查询列表 FROM A
INNER JOIN B
ON A.key=B.key# 其中A.key=B.key指的是连接条件
-- 注:
-- 内连接求的是多张表的交集部分
6.2.4.4 左外连接去除交集
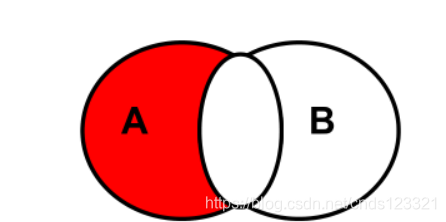
SELECT 查询列表 FROM A
LEFT JOIN B
ON A.key=B.key
WHERE B.key IS NULL;# 将从表B的连接条件作为NULL值判断
6.2.4.5 右外连接去除交集
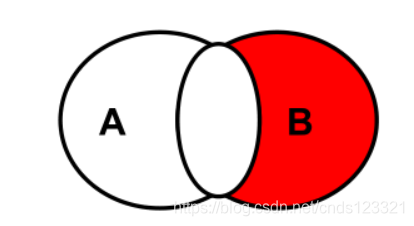
SELECT 查询列表 FROM A
RIGHT JOIN B
ON A.key=B.key
WHERE A.key IS NULL;# 将从表A的连接条件作为NULL值判断
6.2.4.6 全外连接
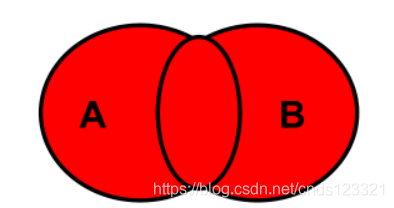
SELECT 查询列表 FROM A
FULL JOIN B
ON A.key=B.key;# 全外连接就是求并集
# MySQL不支持这种full的全外连接,只能使用UNION联合查询
6.2.4.7 全外连接去除交集
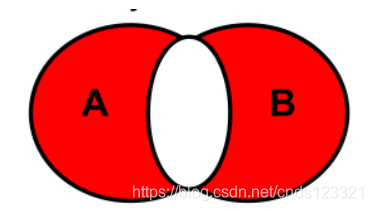
SELECT 查询列表 FROM A
FULL JOIN B
ON A.key=B.key
WHERE A.key IS NULL OR B.key IS NULL;
# MYSQL一样不支持这个
6.2.4.8 实例:
-- 左外连接
select * from beauty
left join boys
on beauty.boyfriend_id=boys.id;
-- 右外连接
select * from beauty
right join boys
on beauty.boyfriend_id=boys.id;
-- 内连接
select * from beauty
inner join boys
on beauty.boyfriend_id=boys.id;
-- 左外连接去除交集
select * from beauty
left join boys
on beauty.boyfriend_id=boys.id
where boys.id IS NULL;
-- 右外连接去除交集
select * from beauty
right join boys
on beauty.boyfriend_id=boys.id
where beauty.boyfriend_id IS NULL;
-- 全外连接(MySQL不能运行)
select * from beauty
full join boys
on beauty.boyfriend_id=boys.id;
-- 全外连接去除交集(MySQL不能运行)
select * from beauty
full join boys
on beauty.boyfriend_id=boys.id
where boys.id IS NULL
OR beauty.boyfriend_id IS NULL;
6.3 sql92和99标准的比较
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高
7. 子查询
子查询就是出现在其他语句中的select语句(写在括号里),就称之为子查询或内查询,而外部的查询语句称之为主查询或外查询。
子查询按照结果集的行列数不同,可以分为如下几类(行列指的是子查询的结果集):
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集只有一行多列)
表子查询(结果集一般为多行多列)
一般来说,还可以按照子查询出现的位置进行划分:
在select后面:仅仅支持标量子查询
在from后面:支持表子查询
在where或having后面:标量子查询、列子查询、表子查询(注:最为重要,理应掌握,学会这个基本其他的也都会了)
在exists后面:支持单列的子查询(相关子查询)
7.1 where或having后面
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符(< >= <= = <>)使用;
列子查询,一般搭配着多行操作符(in、any/some、all)使用
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
建议先写子查询,再写外查询,可以根据子查询结果判断使用什么操作符(避免标量子查询,列子查询的用错)
7.1.1 标量子查询
标量子查询即查询结果只有一行一列的结果集。看下面的案例:
-- 示例1:谁的工资比 Abel 高?
# 第一步:查询Abel的工资
select salary
from employees
where last_name='Abel';
# 第二步:查询员工信息,满足salary>Abel的工资
select *
from employees
where salary >(
select salary
from employees
where last_name='Abel'
);
-- 示例2:返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id 和工资
# 第一步:查询141号员工的job_id
select job_id
from employees
where job_id=141;
# 第二步:查询143号员工的salary
select salary
from employees
where job_id=143;
# 第三步:将第一步和第二步的结果作为子查询
select job_id,salary
from employees
where job_id=(
select job_id
from employees
where job_id=141
)
and salary>(
select salary
from employees
where job_id=143
);
-- 示例3:返回公司工资最少的员工的last_name,job_id和salary
# 第一步:查询公司的最低工资
select MIN(salary)
from employees;
# 第二步:查询工资等于第一步结果的员工的last_name、job_id和salary
select last_name,job_id,salary
from employees
where salary=(
select MIN(salary)
from employees
);
-- 示例4:查询最低工资大于50号部门最低工资的部门id和其最低工资
# 第一步:查询每个部门的最低工资
select MIN(salary),department_id
from employees
group by department_id;
# 第二步:查询50号部门的最低工资
select MIN(salary)
from employees
where department_id=50;
# 第三步:找出第一步结果中比第二步结果中大的记录
select MIN(salary),department_id
from employees
group by department_id
having MIN(salary)>(
select MIN(salary)
from employees
where department_id=50
);
但要注意,如果子查询的结果是列表(即不是一行一列的情况),那么是非法使用标量子查询。例如下面的情况:
因为查询结果不是标量子查询,而使用了标量子查询的单行操作符(>)所以会报错
select MIN(salary),department_id
from employees
group by department_id
having MIN(salary)>(
select salary
from employees
where department_id=50
);
7.1.2 列子查询
列子查询即子查询的结果为一列多行结果集。
多行比较操作符:
| 操作符 | 含义 |
|---|---|
| IN/NOT IN | 等于列表中任意一个 |
| ANY/SOME | 和子查询返回的某一个值比较(满足任意一个即可) |
| ALL | 和子查询返回的所有值比较 |
- ANY关键字的子查询
ANY关键字表示满足其中任意一个条件。
使用ANY关键字时,只要满足内层查询语句返回的结果中的任意一个,就可以通过该条件来执行外层查询语句。示例如下:
-- 带any关键字的子查询
select *
from userinfo
where uid < any(# uid<MAX();
select us.uid
from us,userinfo
where us.uid=userinfo.uid
and sid=2
);
- 带all关键字的子查询
ALL关键字表示满足所有条件。
使用ALL关键字时,只有满足内层查询语句返回的所有结果,才可以执行外层查询语句。示例如下:
-- 带all关键字的子查询
select *
from userinfo
where uid > all(# 表示大于所有的
select us.uid
from us,userinfo
where us.uid=userinfo.uid
and sid=2
);
案例如下:
-- 示例1:返回location_id是1400或1700的部门中的所有员工姓名
# 第一步:查询location_id是1400或1700的部门id
select department_id
from employees
where location_id=1400 or location_id=1700;
# 第二步:查询员工的部门id是否在第一步的结果中,如果在则显示员工姓名
select last_name
from employees
where department_id in (
select department_id
from employees
where location_id=1400 or location_id=1700
);
-- 示例2:返回其它工种中比job_id为‘IT_PROG’工种任一工资低的员工的员工号、姓名、job_id 以及salary
# 第一步:查询job_id为'IT_PROG'的工资
select distinct salary
from employees
where job_id='IT_PROG';
# 第二步:查询其它工种中比第一步结果中任一工资低的员工信息
select last_name,employee_id,job_id,salary
from employees
where salary < ANY(
select distinct salary
from employees
where job_id='IT_PROG'
) and job_id!='IT_PROG';
-- 示例3:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工的员工号、姓名、job_id 以及salary
# 第一步:查询job_id为'IT_PROG'的工资
select distinct salary
from employees
where job_id='IT_PROG';
# 第二步:查询其它工种中比第一步结果中任一工资低的员工信息
select last_name,employee_id,job_id,salary
from employees
where salary < ALL(# 注:和上面的代码仅此处不同
select distinct salary
from employees
where job_id='IT_PROG'
) and job_id!='IT_PROG';
7.1.3 表子查询
结果集为一行多列或多行多列的子查询。案例如下:
-- 示例1:查询员工编号最小并且工资最高的员工信息
-- 标量子查询做法:
# 第一步:查询最小的员工编号
select MIN(employee_id)
from employees;
# 第二步:查询最高的工资
select MAX(salary)
from employees;
# 第三步:查询同时满足第一步和第二步结果的记录
select *
from employees
where employee_id=(
select MIN(employee_id)
from employees
)and salary=(
select MAX(salary)
from employees
);
-- 表子查询做法(要求俩个筛选条件相同,如都是等于号):
select *
from employees
where (employee_id,salary) = (
select MIN(employee_id), MAX(salary)
from employees
);
7.2 select后面
在select后面仅仅支持标量子查询,即结果集为一行一列的子查询。案例如下:
-- 以下示例为,脱裤子放屁
-- 示例1:查询每个部门的员工个数
SELECT d.*,(
SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.`department_id`
) 员工个数
FROM departments d;
-- 示例2:查询员工号=102的部门名
SELECT (
SELECT department_name,e.department_id
FROM departments d
INNER JOIN employees e
ON d.department_id=e.department_id
WHERE e.employee_id=102
) 部门名;
7.3 from后面
也可以将子查询放在from后面,将子查询结果充当一张表,但是要求必须起别名。案例如下:
-- 案例1:查询每个部门的平均工资的工资等级
# 第一步:查询每个部门的平均工资
select avg(salary),department_id
from employees
group by department_id;
# 第二步:内连接第一步的结果集和job_grades表,筛选平均工资
select ag_dep.*,g.grade_level
from (
select avg(salary) ag,department_id
from employees
group by department_id
) ag_dep
inner join job_grades g
on ag_dep.ag between lowest_sal and highest_sal;
7.4 exists后面
exists是一个关键字,判断是否存在,如果存在则返回1,不存在则返回0.
使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。
如果内层查询语句查询到满足条件的记录,就返回一个真值(true),否则,将返回一个假值(false)。
当内层返回的值为true时,外层查询语句将进行查询;当返回的为false时,外层查询语句不进行查询或者查询不出任何记录。
与EXISTS关键字刚好相反,使用NOT EXISTS关键字时,当返回的值是true时,外层查询语句不执行查询;当返回值是false时,外层查询语句将执行查询。
它的基本语法如下:
[NOT] EXISTS(完整的查询语句);
-- NOT是一个可选项,如果加上,表示不存在
# 示例,查询有无名字叫'张三丰'的员工信息
SELECT EXISTS (
SELECT *
FROM employees
WHERE last_name = '张三丰'
) 有无张三丰;
案例如下:
-- 示例1:查询有员工的部门名
# 使用IN关键字完成
select department_name
from departments d
where d.department_id in(
select department_id
from employees
);
# 使用EXISTS关键字完成
select department_name
from departments d
where EXISTS(
select *
from employees e
where d.department_id=e.department_id
);
8. 分页查询
分页广泛应用于各大网站
即当要显示的数据一页显示不完时,就需要用到分页查询。
分页查询的基本语法如下:
-- 语法
select 查询列表
from 表
[
连接类型 join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选条件
order by 排序字段
]
LIMIT [offset(起始条目索引),] size(显示的条目数);
-- offset表示要显示条目的起始索引,从0开始,是一个可选项,如果不写的话就从0开始。
-- size是指要显示多少条记录
/*
基础查询语句执行顺序:
1. from子句
2. JOIN子句
3. on子句
4. where子句
5. group by 子句
6. having子句
7. select子句
8. order by子句
9. limit子句
*/
注意:limit语句要放在查询语句的最后。
在实际开发中,我们只需要知道当前页码和每页显示条数就可以写SQL从数据库中获取数据记录了。
它们有如下关系:
-- index 当前页码,页码从1开始,但因为起始索引由0开始,所以需要减1
-- size 每页显示条数
select 查询列表 from 表 LIMIT (index-1)*size,size;
-- 例如 :
/*
page size = 10
1 查询这一页:limit 0,10
2 查询这一页:limit 10,10
3 查询这一页:limit 20,10
*/
示例如下:
-- 示例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5; #0可以省略
-- 示例2:查询第11条——第25条
SELECT * FROM employees LIMIT 10,15;
-- 示例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT * FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10 ;
注:如果要查找前几名或后几名通常要使用排序,即经常搭配order by使用。
9. 联合查询
联合查询要使用的关键字是UNION,将多条查询语句的结果合并为一个结果。
基本语法如下:
查询语句1
UNION
查询语句2
UNION
...
联合查询主要用于,要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时(注:一张表是id和name字段,那么另外一张表也必须是查询相同类型、相同列数的字段,才能进行整合,联合查询是在行上进行拼接(多出来几行),而不是在列上进行拼接(多出来几列))。
联合查询的特点:
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
示例如下:
-- 示例1:查询部门编号>90或邮箱包含a的员工信息
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;;
# 或
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
-- 示例2:查询中国用户中男性的信息以及外国用户中年男性的用户信息
SELECT id,cname FROM t_ca WHERE csex='男'
UNION ALL
SELECT t_id,tname FROM t_ua WHERE tGender='male';
10.总结:
1.查询语句书写顺序:
select–>from–>[类型] join/outer–>on–>where–>group by–>having–>order by–>limit
2.执行顺序:
from–>[类型] join/outer–>on–>where–>group by–>having–>select–>order by–>limit














 4012
4012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









