







mac的落格输入法通讯录正常是不能导入的,按小鹤双拼编码为例间接导入
- 1.mac版导出为vCard 文件
- 2. 安装python3的pypinyin库,这里需要有一定python基础,不会的可搜一下建立anaconda虚拟环境
- 3. 提取姓名,生成txt纯姓名文件
- 4. 按小鹤双拼编码生成,其中以位置为0最靠前为例:
- 5. 另一种格式,也是我正在用的,元音不使用o开头,直接拼:
- 6. 导入到输入法
- 7. 最后再手动把一些常用的词,放到靠后的位置,防止冲突
- 如图中“常畅”和“常常”会混淆,把位置0改为1。这里也可以先在txt中改完了,再导入,更方便: 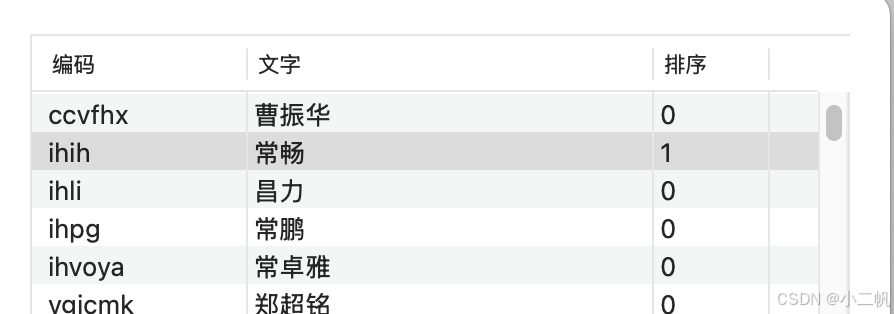
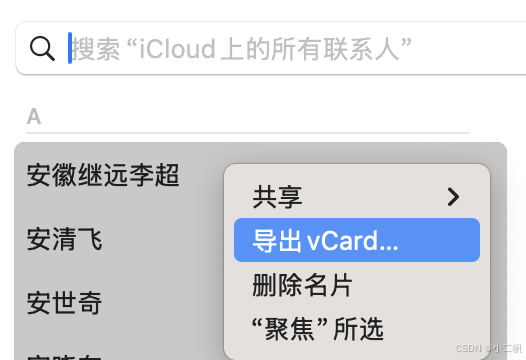
1.mac版导出为vCard 文件
通讯录 → cmd+a键全选 → 导出vCard → 改名为contacts.vcf
2. 安装python3的pypinyin库,这里需要有一定python基础,不会的可搜一下建立anaconda虚拟环境
在命令行安装:
pip install pypinyin
3. 提取姓名,生成txt纯姓名文件
新建一个extraction.py的文件,粘贴以下内容后,运行(命令行输入python extraction.py,回车)
# 打开并读取 vCard 文件
with open('contacts.vcf', 'r', encoding='utf-8') as file:
lines = file.readlines()
# 提取姓名
names = []
for line in lines:
if line.startswith('FN:'):
name = line[3:].strip()
names.append(name)
# 将姓名写入新的文本文件
with open('names.txt', 'w', encoding='utf-8') as output:
for name in names:
output.write(name + '\n')
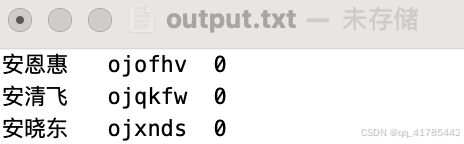
输出的names.txt如:

4. 按小鹤双拼编码生成,其中以位置为0最靠前为例:
这是第一种方案,注意其中的元音汉字:
安恩惠 对应 ojofhv,而不是anenhv,如果需要后者,请看下一节
再次新建一个python文件:encode.py并运行(命令行输入python encode.py并回车)
from pypinyin import pinyin, Style
# 根据 XML 的 Sheng 字典(键为编码,值为 pinyin 声母)
sheng_map = {
"a": "a",
"b": "b",
"c": "c",
"d": "d",
"e": "e",
"f": "f",
"g": "g",
"h": "h",
"i": "ch",
"j": "j",
"k": "k",
"l": "l",
"m": "m",
"n": "n",
"o": "",
"p": "p",
"q": "q",
"r": "r",
"s": "s",
"t": "t",
"u": "sh",
"v": "zh",
"w": "w",
"x": "x",
"y": "y",
"z": "z"
}
# 反向映射:给定 pinyin 声母,返回对应的小鹤编码
inverted_sheng = {}
for code, val in sheng_map.items():
if val not in inverted_sheng:
inverted_sheng[val] = code
# 如果 pinyin 声母为空,直接保留空串
if "" not in inverted_sheng:
inverted_sheng[""] = ""
# Yun(韵母)映射,键为转换结果,值可能含多个备选(用 "|" 分隔)
yun_map = {
"a": "a",
"b": "in",
"c": "ao",
"d": "ai",
"e": "e",
"f": "en",
"g": "eng",
"h": "ang",
"i": "i",
"j": "an",
"k": "uai|ing",
"l": "iang|uang",
"m": "ian",
"n": "iao",
"o": "uo|o",
"p": "ie",
"q": "iu",
"r": "uan|er",
"s": "ong|iong",
"t": "ue",
"u": "u",
"v": "ui|v",
"w": "ei",
"x": "ia|ua",
"y": "un",
"z": "ou"
}
# Special 特殊韵母映射
special_map = {
"aa": "a",
"ah": "ang",
"ai": "ai",
"an": "an",
"ao": "ao",
"ee": "e",
"eg": "eng",
"ei": "ei",
"en": "en",
"er": "er",
"oo": "o",
"ou": "ou"
}
def convert_char(ch):
"""
将单个汉字转换为小鹤双拼码:
1. 利用 pypinyin 获取无音调拼音(全拼)和声母
2. 反向查找声母得到对应编码
3. 韵母部分为 full_pinyin 去除声母部分
先在 Yun 映射中查找(例如 "ei" 对应键 "w"),
若未命中,则查 special_map,再否则直接保留
"""
full = pinyin(ch, style=Style.NORMAL, strict=False)[0][0]
init = pinyin(ch, style=Style.INITIALS, strict=False)[0][0]
initial_code = inverted_sheng.get(init, init)
# 取除去声母后的部分作为韵母
if full.startswith(init):
final_part = full[len(init):]
else:
final_part = full
final_code = None
# 优先在 Yun 映射中查找
for key, alternatives in yun_map.items():
if final_part in alternatives.split("|"):
final_code = key
break
# 若未找到,则尝试 special_map
if final_code is None:
final_code = special_map.get(final_part, final_part)
return initial_code + final_code
def convert_name(name):
"""对姓名中所有汉字均转换为小鹤双拼码,并拼接成完整字符串"""
return "".join(convert_char(ch) for ch in name)
def process_file(input_file, output_file):
"""读取输入文件(UTF-8,每行一个姓名),转换后按“姓名[TAB]编码[TAB]0”写入输出文件"""
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
name = line.strip()
if name:
code = convert_name(name)
outfile.write(f"{name}\t{code}\t0\n")
print(f"转换完成,结果已保存到 {output_file}")
# 设置输入、输出文件名(请确保 contacts.txt 为 UTF-8 编码,每行一个姓名)
input_filename = "contacts.txt"
output_filename = "output.txt"
process_file(input_filename, output_filename)
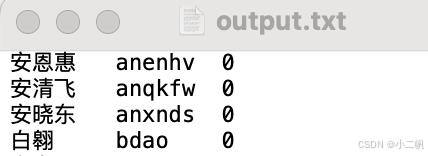
5. 另一种格式,也是我正在用的,元音不使用o开头,直接拼:
例如
昂:使用ah,而不是oh
代码:
from pypinyin import pinyin, Style
# 根据 XML 的 Sheng 字典(键为编码,值为 pinyin 声母)
sheng_map = {
"a": "a",
"b": "b",
"c": "c",
"d": "d",
"e": "e",
"f": "f",
"g": "g",
"h": "h",
"i": "ch",
"j": "j",
"k": "k",
"l": "l",
"m": "m",
"n": "n",
"o": "",
"p": "p",
"q": "q",
"r": "r",
"s": "s",
"t": "t",
"u": "sh",
"v": "zh",
"w": "w",
"x": "x",
"y": "y",
"z": "z"
}
# 构造反向映射:给定 pinyin 声母,返回对应的小鹤编码
inverted_sheng = {}
for code, val in sheng_map.items():
# 注意:对于无声母的情况,XML 中 key "o" 对应空字符串
if val not in inverted_sheng:
inverted_sheng[val] = code
# 对于空串,若存在则不输出任何声母
if "" in inverted_sheng:
# 如果查到无声母时默认得到 "o",则改为 ""
inverted_sheng[""] = ""
# Yun(韵母)映射:键为转换结果,值中可能含多个备选,用 "|" 分隔
yun_map = {
"a": "a",
"b": "in",
"c": "ao",
"d": "ai",
"e": "e",
"f": "en",
"g": "eng",
"h": "ang",
"i": "i",
"j": "an",
"k": "uai|ing",
"l": "iang|uang",
"m": "ian",
"n": "iao",
"o": "uo|o",
"p": "ie",
"q": "iu",
"r": "uan|er",
"s": "ong|iong",
"t": "ue",
"u": "u",
"v": "ui|v",
"w": "ei",
"x": "ia|ua",
"y": "un",
"z": "ou"
}
# Special 特殊韵母映射
special_map = {
"aa": "a",
"ah": "ang",
"ai": "ai",
"an": "an",
"ao": "ao",
"ee": "e",
"eg": "eng",
"ei": "ei",
"en": "en",
"er": "er",
"oo": "o",
"ou": "ou"
}
def convert_char(ch):
"""
将单个汉字转换为小鹤双拼码:
- 如果该汉字无声母(即 pinyin 初声为空),则直接使用其韵母(FINALS 部分);
特殊地,如果韵母为 "ang",则输出 "ah"。
- 如果有声母,则:
1. 利用反向映射得到小鹤声母编码;
2. 遍历 Yun 映射,查找 pinyin 的韵母(FINALS)对应的键;
如未命中,再查 special_map,若仍未命中则直接使用韵母。
"""
full = pinyin(ch, style=Style.NORMAL, strict=False)[0][0]
init = pinyin(ch, style=Style.INITIALS, strict=False)[0][0]
final_part = pinyin(ch, style=Style.FINALS, strict=False)[0][0]
# 若无声母,则直接使用韵母(特殊处理 "ang")
if init == "":
if final_part == "ang":
return "ah"
else:
return final_part
else:
initial_code = inverted_sheng.get(init, init)
final_code = None
# 先在 Yun 映射中查找
for key, alternatives in yun_map.items():
if final_part in alternatives.split("|"):
final_code = key
break
# 若未找到,再尝试 special_map
if final_code is None:
final_code = special_map.get(final_part, final_part)
return initial_code + final_code
def convert_name(name):
"""对姓名中每个汉字均转换为小鹤双拼码,并拼接成完整字符串"""
return "".join(convert_char(ch) for ch in name)
def process_file(input_file, output_file):
"""
读取输入文件(UTF-8 编码,每行一个姓名),
转换后以“姓名[TAB]编码[TAB]0”的格式写入输出文件。
"""
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
name = line.strip()
if name:
code = convert_name(name)
outfile.write(f"{name}\t{code}\t0\n")
print(f"转换完成,结果已保存到 {output_file}")
# 设置输入、输出文件名(请确保 contacts.txt 为 UTF-8 编码,每行一个姓名)
input_filename = "contacts.txt"
output_filename = "output.txt"
process_file(input_filename, output_filename)
6. 导入到输入法
把output.txt导入进去
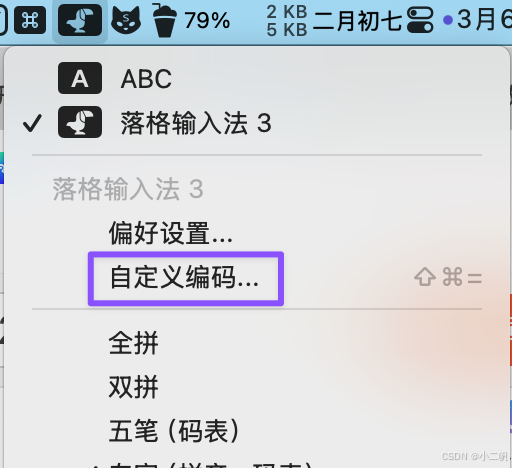
7. 最后再手动把一些常用的词,放到靠后的位置,防止冲突
如图中“常畅”和“常常”会混淆,把位置0改为1。这里也可以先在txt中改完了,再导入,更方便:

完结撒花~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









