






这篇论文是关于人脸重建的文章,由于商业信息原因,作者未公布相关源代码,只有评估模型的代码信息,源码地址:GitHub - barisgecer/GANFit: Project Page of 'GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction' [CVPR2019],虽然没有公布源码,但是提供了一个与GANFIT思想相类似的项目,地址为: GitHub - barisgecer/TBGAN: Project Page of 'Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks'。
1.1阅读时间:2023.4.10-4.14
1.2背景:
在最近的工作中,为了学习面部身份特征和三维变形模型的形状和纹理参数之间的关系,使用了可微的渲染器。纹理特征要么对应于线性纹理空间的组件,要么由自动编码器直接从野生图像学习。在所有的情况下,最先进的面部纹理重建方法的质量仍然不能在高保真建模纹理。
1.3使用数据集
1.3.1 MICC数据集:
包含53个人脸扫描数据的中性姿态数据集,包含3d模型(OBJ and VRML格式),坐标变换短视频和户内短视频和户外短视频等数据信息,官方下载链接:Media Integration and Communication Center / 3D faces dataset。
1.4基础知识
1.4.1 可微渲染器:
可微渲染器(Differentiable Renderer),是一种能够对3D模型进行渲染并生成可导输出的算法。
可微渲染器的主要思想是将传统的渲染算法中的一些非线性操作改为可导的函数。传统的渲染算法通常采用一些复杂的光照、材质和几何计算,这些计算往往是非线性的,导致了无法直接对其进行梯度计算。而可微渲染器通过将这些计算改为可导的函数,使得渲染操作可以被包含在深度学习模型中,并可以通过反向传播来计算梯度,从而实现端到端的训练和优化。
在GANFIT中,作者使用了可微渲染器来生成2D图像。具体来说,作者使用了一种基于边界框的渲染方法,将3D面部模型渲染成包含人脸的边界框。这个渲染方法通过投影矩阵将3D面部模型映射到2D图像平面上,并使用了一个可导的函数来计算每个像素的颜色值。这个可导的函数可以直接被包含在GANFIT中的深度学习模型中,使得整个系统可以被端到端地训练和优化。
传统渲染器:传统的渲染器通常采用光线追踪(ray tracing)或光栅化(rasterization)等技术来生成图像。在光线追踪中,通常从相机出发,沿着射线向场景中的物体发射光线。当光线与物体相交时,根据物体的材质和光照条件计算出光线的颜色和亮度等信息,然后将这些信息传递给下一个光线进行计算,最终得到相机视角下的图像。光线追踪可以模拟各种光照效果,但是计算量较大,渲染速度较慢。
在光栅化中,首先将3D场景中的物体投影到2D图像平面上,然后根据像素的位置和光照等信息计算出像素的颜色值。通常采用的是三角形光栅化技术,即将物体分解为很多个三角形,然后对每个三角形进行光栅化。光栅化可以实现实时渲染,但是由于不同像素之间的计算是独立的,难以处理全局光照效果。传统的渲染器通常采用一些复杂的光照、材质和几何计算,这些计算往往是非线性的,导致了无法直接对其进行梯度计算。
1.4.2 3dmm:
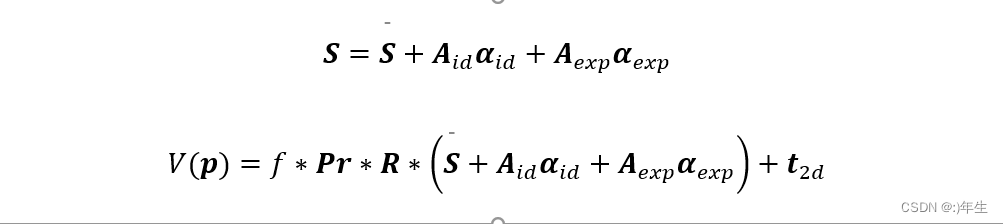
公式1:3DMM主要算法公式
第一个是3dmm的主要内容,第二个公式是3d人脸模型投影到2d平面,具体参数见上一文章。
1.5本文工作
在深度卷积神经网络(DCNN)成功的基础上构建,但采用一种完全不同的方法,从单一的野生图像进行3D形状和纹理重建。也就是说,与使用自我监督的回归方法或自编码器结构不同,重新审视基于优化的3DMM拟合方法,通过监督深度身份特征,并使用生成对抗网络(GAN)作为我们的面部纹理的统计参数表示。
特别地,本文带来的创新之处有:
•首次表明,在未包裹的UV空间上对完整的面部表面进行大规模高分辨率统计重建,可以成功地用于重建任意面部纹理,即使是在无约束记录条件下捕获的。【作者在这篇论文中首次尝试了一种新的方法,使用大规模高分辨率的面部数据进行建模,将面部表面的形状信息和纹理信息统计到一个平面UV空间上。这个方法可以成功地用于重建任意面部纹理,即使这些纹理是在不受控制的记录条件下捕捉到的。这个方法的意义在于,以前的面部重建方法通常需要面部数据的约束条件,比如需要控制光照和摄像机的角度等因素,才能得到较好的重建效果。而这个方法可以在不需要这些约束条件的情况下,仍然能够成功地进行面部重建,这为人脸识别、虚拟现实、面部表情合成等领域提供了更加广泛的应用空间。
】
•制定了一种新颖的3DMM拟合策略,它基于GAN和一个可微分的渲染器。
•设计了一种新颖的成本函数,它结合了人脸识别网络中深度身份特征的各种内容损失。
•演示了在任意记录条件下的优秀的面部形状和纹理重建,在定性和定量实验中显示出既逼真又保持身份。
1.5.1本文网络结构
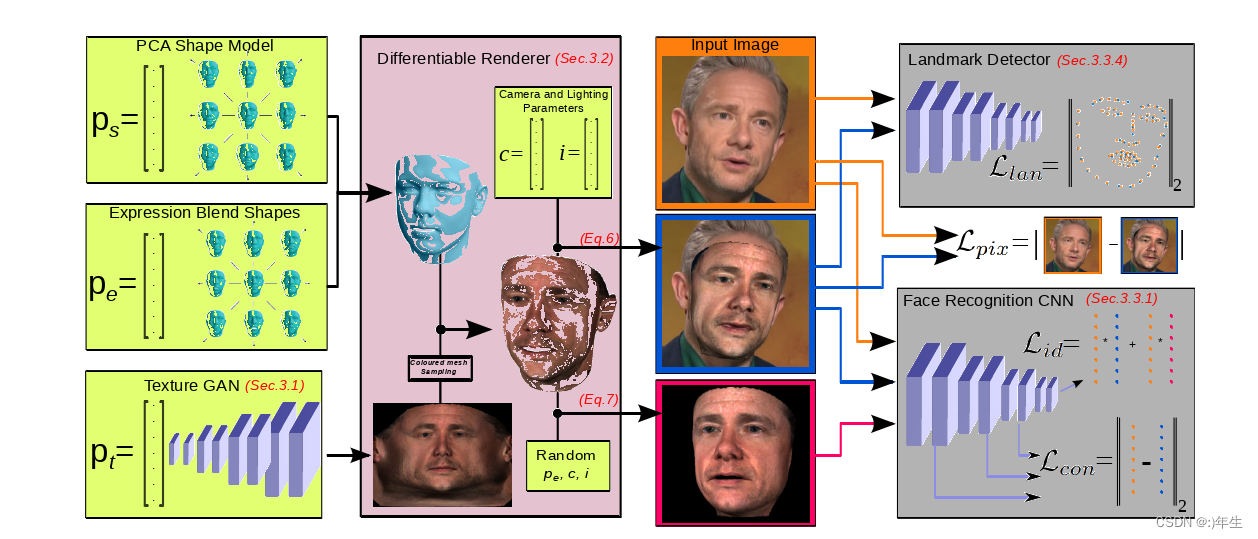
图一:本文网络结构
整个网络结构是一种基于优化的3D人脸重建方法,该方法采用高保真纹理生成网络作为统计先验,主要由三部分组成模型重建部分,可微渲染部分和图片比对损失部分组成,第一部分,利用三维变形形状模型(ps,pe)形成重构网格;纹理由渐进生长GAN框架训练的生成器网络(pt)的输出UV贴图;并通过可微渲染器投影成2D图像(中间粉色部分)。通过更新3DMM的潜参数和梯度下降纹理网络,以代价函数的形式最小化渲染图像与输入图像之间的距离(灰色部分)。在描述了使用可微渲染器生成图像的过程之后,我们制定了我们的代价函数以及将我们的形状和纹理模型拟合到测试图像上的过程,这些函数主要是基于人脸识别网络的丰富特征来实现平滑收敛,地标检测网络Llan用于对齐和粗糙形状估计。
1.5.2 本文修改后3DMM
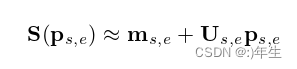
公式2:本文3dmm结构
其中ms,e在平均形状向量中,Us,e∈R3N×Ns,e是Us,e = [Us,Ue],其中Us是对应基础形状,Ue是对应基础表情。最后,Ps,e是Ns,e形状参数,可以根据单位和表达式基进行分割:Ps,e = [ps, pe]【这两个公式的形式比较相似,都是将三维形状表示为一个基础形状加上形状的变化,以及将纹理表示为一个基础纹理加上纹理的变化。
本文的3dmm与1999年原始论文中的3dmm不同的是。S(ps,e)≈ms,e+Us,eps,e是GANFIT中使用的3DMM模型,其中基础形状和纹理都是从一个大规模高分辨率的面部数据集中学习得到的,而形状和纹理的变化分别由形状参数ps和表情参数e来控制。这个模型可以用于任意的面部纹理重建,包括在不受控制的记录条件下捕捉到的面部纹理。
而S = S_0 + A_id alpha_id + A_exp alpha_exp是传统的3DMM模型,其中基础形状和纹理都是从一个特定的人脸数据集中学习得到的,并且形状和纹理的变化分别由形状参数alpha_id和表情参数alpha_exp来控制。这个模型需要受控制的条件来保证形状和纹理的一致性,因为它只能用于同一个人的纹理重建,而不能用于不同人脸的纹理重建。这两个公式所表示的模型不同,GANFIT中使用的3DMM模型相对于传统的3DMM模型在适用性和准确性上有所提高。
1.5.3 模型拟合
拟合3DMM进行三维人脸的拟合和纹理重建,通过求解基于能量的非线性成本优化问题,恢复一组参数p = [ps,e, pt, pc, pl],其中pc为相机模型相关参数,pl为光照模型相关参数。优化可以表示为
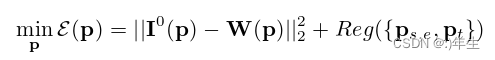
公式3:3dmm模型拟合
(这个公式表示的是一个非线性能量优化问题,通过最小化能量函数 E(p) 来找到最优的参数向量 p。其中,||I0(p)−W(p)||22 表示从原始图像 I0(p) 与由参数 p 所重建的图像 W(p) 之间的平方误差,即重建图像与原始图像之间的差异。Reg({ps,e,pt}) 表示正则化项,用于限制参数的范围,避免过拟合。)其中I0为拟合的测试图像,W为p参数控制的生成的图像。最后Reg为正则化项,主要与纹理和形状参数有关。对于上述代价函数的数值优化,用一个显著的方法就是使用手工制作的特征(即H)来表示纹理,将损失函数简化为:
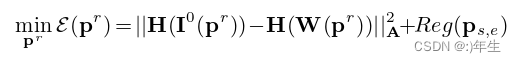
公式4:优化3dmm模型拟合
这个公式也是一个非线性能量优化问题,通过最小化能量函数 E(pr) 来找到最优的参数向量 pr。其中,||H(I0(pr))−H(W(pr))||2A【其中||a||2 a = aTAa, a是与纹理统计模型的正交空间,pr是约简参数pr = {ps,e, pc}的集合。用高斯-牛顿法求解式4中的优化问题。该方法的主要缺点是无法重建面部纹理【高斯-牛顿法是一种迭代优化算法,用于求解非线性最小二乘问题。在式4中,我们要最小化数据项和正则化项之和,这是一个非线性能量优化问题,可以使用高斯-牛顿法求解。
高斯-牛顿法是一种迭代算法,每次迭代都需要计算目标函数的一阶导数和二阶导数。具体来说,在每次迭代中,我们先计算当前参数向量 pr 所对应的图像 W(pr),然后计算目标函数 E(pr) 关于参数向量 pr 的一阶导数和二阶导数,进而求解更新方向,即 Hessian 矩阵的逆乘以梯度向量。最后,我们将更新方向乘以一个步长,得到新的参数向量,然后继续迭代,直到满足终止条件。
然而,高斯-牛顿法的主要缺点是无法重建面部纹理。因为在该方法中,表情参数 e 与纹理参数共享同一个空间,无法区分它们的贡献。具体来说,面部纹理是由纹理参数控制的,但是表情参数 e 也会影响面部纹理的重建,因为它们与纹理参数共享同一个空间。这样,当表情变化较大时,纹理参数就无法正确地反映面部纹理的细节,从而导致重建的面部纹理质量较差。
因此,为了解决这个问题,一些研究者提出了使用纹理空间来分离表情和纹理的方法,例如在文章中所提到的方法。通过将表情和纹理分别建模,可以更准确地重建面部纹理,从而提高重建质量。】 表示从原始图像 I0(pr) 与由参数 pr 所重建的图像 W(pr) 之间在 A 空间中的平方误差,即纹理的差异。A 表示正交于纹理的统计模型的空间,因此可以看作是一个纹理的去相关空间。更具体地,||H(I0(pr))−H(W(pr))||2A 是一个数据项,它衡量了由参数 pr 所重建的图像纹理与原始图像纹理之间的差异。数据项越小,说明重建的图像纹理越接近原始图像纹理。同时,为了防止过拟合,需要加入正则化项,
参数向量 pr 包括了几何参数 ps、表情参数 e 和相机参数 pc。其中,ps 和 e 用于描述三维几何形状和表情,pc 用于描述相机的位置、姿态和内部参数。正则化项 Reg(ps,e) 用于限制 ps 和 e 的取值范围,以避免过拟合。
1.5.4 GAN网络
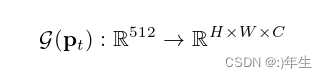
公式5:GAN网络
在纹理建模中, 主成分分析方法其高斯特性,常常无法捕捉高频细节,导致纹理模糊变得更加明显,纹理建模是三维重建中保存身份和照片真实性的关键组成部分。GAN在捕捉这些细节方面非常有效。然而,当训练图像处于半对齐状态时,它们难以保持目标分布的三维相干性(三维重建过程中保持一致性的问题)。我们发现,用每像素对齐的真实纹理的UV表示训练的GAN能够避免这个问题,并能够从99.9%的潜在空间生成真实和相干的UV,同时很好地推广到未见的数据。为了利用这种完美的和谐,作者训练一个逐步增长的GAN来建模10000个高分辨率纹理的UV表示的分布。代替传统中的3DMM纹理模型。针对潜在参数pt,即minpt |G(pt)−I(uv)|,最小化UV空间中目标纹理与网络输出G(pt)之间的每像素曼哈顿距离。
1.5.5 可微渲染器阶段(中间网络阶段-投影到2D)
使用一个可微的渲染器,在给定摄像机和光照参数的情况下,基于延迟着色模型,将3D重建投影到2D图像平面上。由于每个顶点的颜色和法线属性是用重心坐标插值在相应的像素上的,梯度可以很容易地通过渲染器反向传播到潜在的参数。
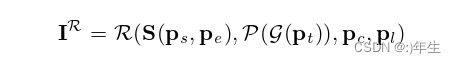
公式6:渲染图片算法
通过针孔摄像机模型,将摄像机位于[Xc, Yc, zZc],指向[xc, yc, zc],焦距为fc的笛卡尔原点中心[0,0,0]的三维纹理网格投影到二维图像平面上。照明是直接光源在三维坐标[xl, yl, zl]的颜色值[rl, gl, bl],和环境照明的颜色[ra, ga, ba]。3DMM几何图形(Ps,e),GAN纹理g(pt),相机参数(pc = [xc, yc, zc, xc, yc, zc, fc])和照明参数(pl = [xl, yl, zl, rl, gl, bl, ra, ga, ba])的渲染图像。
此外,作者添加了以随机的表情、姿态和光照来呈现一副图像【作者生成了一个另外的图片来提高模型对于不同表情、姿势和光照等因素的泛化能力,以更好地建模身份相关的参数,这个额外的图片可以增加数据的多样性,并且可以用于训练更健壮的模型】,以便在这些变化下较好地概括与身份相关的参数。我们从正态分布的300W-3D数据集上采样相机和光照参数:ˆpc ~ N(ˆµc,ˆσc)和pˆl ~
N(ˆµl,^σl)。这个呈现的图像与IR(即,具有相同的ps和pt参数)表示如下:
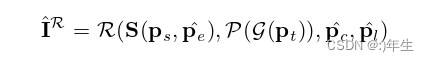
公式7:渲染图片(随机光照和相机参数)算法
1.6损失函数(第三部分)
1.6.1 身份损失(Face Recognition CNN Lid)
身份差异"(Identity difference)通常指的是两个或多个不同的人之间在外貌上的差异,也可以指同一个人在不同状态下(如不同表情、姿势、光照等)外貌的差异。在人脸重建领域,身份差异是指重建出来的人脸与目标人物在身份上的差异,也就是重建出来的人脸与目标人物在外貌上的相似程度。
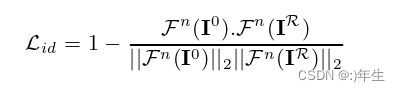
公式8:身份损失算法
给定一个由n个卷积滤波器组成的预处理人脸识别网络Fn(I): RH×W×C→R512,我们计算真实目标图像的身份特征(即嵌入)与我们的呈现图像之间的余弦距离。公式中的Fn表示将输入图像或重建结果I0或IR经过卷积神经网络的一层后得到的特征向量,Fn(I0)和Fn(IR)分别表示输入图像和重建结果在该网络层的特征向量。公式中的||表示向量的欧几里得范数,所以Fn(I0)||2表示输入图像在该网络层特征向量的平方和,而||Fn(IR)||2表示重建结果在该网络层特征向量的平方和。整个公式的意义是,将输入图像和重建结果在该网络层特征向量之间的内积(即两者之间的相似度)归一化,然后用1减去这个相似度作为loss,以衡量重建结果和输入图像之间的身份差异。
在这部分中,作者重新定义了一个新的身份损失函数(ˆLid),其中用生成的额外图像(ˆIR)代替了原始图像(IR),从而确保重建图像(ˆIR)在不同的姿势、表情和光照条件下更好地匹配目标身份,提高了重建图像的质量。
1.6.2 内容损失(Content Loss Lcon)
人脸识别网络经过训练,去除卷积层中除抽象身份信息外的各种属性(如表情、光照、年龄、姿势等)。尽管他们的优势,在最后一层的激活丢弃了一些对3D重建有用的中级特征,例如依赖于年龄的变化。因此,通过在人脸识别网络中利用中间特征表示来处理身份内容丢失是有效的,这种中间表示对像素级变形仍然是鲁棒的,而且不会太抽象而错过一些细节。为此,将中间激活的归一化欧几里德距离,即内容损失,最小化到输入和渲染图像之间,损失项如下:
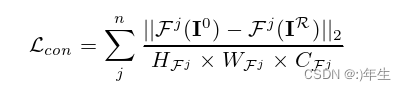
公式9:内容一致性损失算法
其中,n表示特征图的数量,Fj(I0)和Fj(IR)分别表示原始图像和重建图像在第j个特征图上的特征表示,||...||2表示L2范数,HFj、WFj和CFj分别表示第j个特征图的高度、宽度和通道数。该公式的含义是计算原始图像和重建图像在不同特征图上的特征表示之间的欧几里得距离,并对所有特征图上的距离求和,从而得到重建图像和原始图像之间的对比损失。该损失函数可以帮助网络学习生成更加准确和清晰的重建图像。
1.6.3 像素损失(Pixel Loss Lpix)
身份和内容损失项对可见纹理的反照率进行优化,光照条件直接根据像素值差进行优化。虽然这个代价函数相对简单,但它足以优化灯光参数,如环境颜色、方向、距离和光源的颜色。
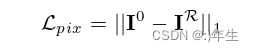
公式10: 像素损失算法
由于该损失函数支持最高分辨率的像素级比较,因此可以捕捉到图像的精细纹理,帮助网络学习更好地保留图像的细节信息。但是,由于计算成本很高,为了减少计算复杂度,该损失函数需要在identity loss和content loss之前将图像缩小到112×112大小。
1.6.4 地标损失(Landmark Loss Llan)
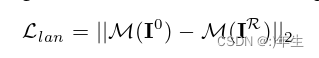
公式11: 地标损失算法
为了与网络兼容,我们在相同的设置下对齐输入和呈现的图像。然而,这个过程忽略了纵横比和重建的规模。因此,我们采用深人脸对齐网络M(I): RH×W×C→R68×2(68个关键特征点)来检测输入图像的地标位置,并通过更新形状、表情和相机参数将渲染的几何图形对齐到该图像上。
这个损失函数是用来衡量重建图像的人脸关键点与输入图像的人脸关键点之间的距离的。通过使用一个深度人脸对齐网络,将输入图像的人脸关键点检测出来,并将重建的几何结构对齐到输入图像上,通过更新形状、表情和相机参数实现对齐。由于重建图像的人脸关键点位置与相机参数密切相关,因此这个损失函数提供了重建图像与输入图像对齐的重要信息。最终,Llan通过计算输入图像和重建图像的人脸关键点之间的欧几里得距离来衡量重建图像与输入图像的对齐质量。
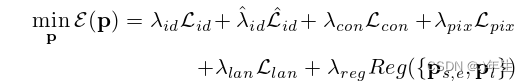
公式12: 模型拟合总损失算法
用λ参数对每个损失项进行加权。为了防止形状和表达模型以及照明参数夸张到任意偏向损失项,我们通过Reg({ps,e, pl})正则化这些参数【
λidLid:身份损失,用于确保重建的人脸与输入的人脸为同一人。
ˆλidˆLid:使用随机参数渲染的重建图像的身份损失,用于确保重建的人脸在不同的姿态、表情和光照条件下也能保持一致的身份。
λconLcon:内容损失,用于保留重建图像的细节和纹理。
λpixLpix:像素损失,用于确保重建图像与输入图像在像素级别上一致。
λlanLlan:关键点损失,用于确保重建的人脸与输入的人脸在关键点上一致。
λregReg({ps,e,pl}):正则化损失,用于限制参数的范围,防止过度拟合
】
1.7实验结果
在所有的实验中,使用沙漏二维地标检测【Hourglass网络是一种具有逐层下采样和上采样操作的全卷积神经网络,通常用于图像分割和关键点检测任务。使用Hourglass网络检测输入人脸图像中的68个关键点位置,这些关键点位置可以用于将不同人脸图像对齐到同一个固定的模板上。这个对齐过程对于训练和测试3D人脸重建模型非常重要,因为它能够消除不同图像之间的位姿和旋转差异】检测68个地标位置,将给定的人脸图像与我们的固定模板对齐。对于身份特征,采用ArcFace网络的预训练模型。对于生成器网络G,用大约10000张512 × 512分辨率的UV图训练一个逐步增长的GAN。使用Large Scale Face Model来表示维度(Ns) = 158的3DMM形状模型,以及从4DFAB数据库中学习到的ne = 29的表达模型。在拟合过程中,以0.01的学习速率使用Adam Solver对参数进行优化。平衡因子设为:λid: 2.0,ˆλid: 2.0, λcon: 50.0, λpix: 1.0, λlan: 0.001, λreg:{0.05, 0.01}。在Nvidia GTX 1080 TI GPU上,拟合可以在大约30秒内完成单个图像的拟合。
1.7.1 质量对比

图二:比对结果
定性结果与其他最先进的方法在MoFA - Test数据集上的比较。第2 - 5行显示与纹理几何的比较,第6 - 8行只比较形状。图中最好用彩色和缩小的方式查看。

图三:消融实验结果
图3(c)表明,反照率与光照很好地解纠缠,模型准确地捕捉了光的方向。图3(d-f)显示了每个恒等项都有助于保持恒等,图3(h)显示了所有的显著性恒等特征。尽管如此,整体重建利用像素强度来捕捉更好的反照率和照度,如图3(g)所示。最后,图5(i)显示了纹理相对于基于pca的纹理的优越性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









