







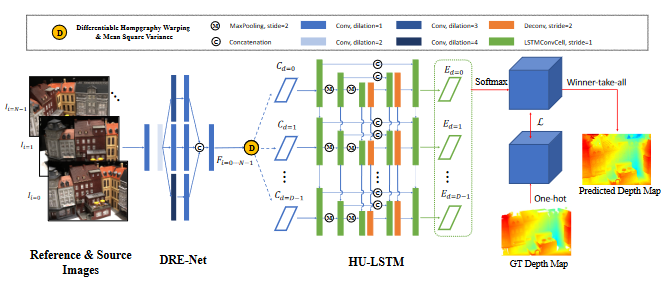
MVSNet系列总结(有监督学习方法)
- 1.MVSNet ECCV2018
- 2.RMVSNet CVPR2019
- 3.P-MVSNet ICCV2019
- 4.MVSCRF ICCV2019
- 5.PointMVSNet ICCV2019
- 6.cascade MVSNet CVPR2020
- 7.UCSNet CVPR2020
- 8.CVP-MVSNet CVPR2020
- 9.Fast-MVSNet CVPR2020
- 10.CIDER AAAI2020
- 11.PVA-MVSNet ECCV2020
- 12.D2HC-RMVSNet ECCV2020 Spotlight
- Vis-MVSNet 2020 BMVC(CCF C) & 2022 IJCV(CCF A)
- 13.AA-RMVSNet ICCV2021
- 14.Epp-mvsnet CVPR2021
- 15.Patchmatchnet CVPR2021
- 16.GBi-Net CVPR 2021
- 17.NP-CVP-MVSNet CVPR2022
- 18.UniMVSNet CVPR 2022
- 19.PVSNet IJCV 2022
| 论文 | 特点 | DTU(acc/com/overall)越低越好 | Tanks’mean(inter/advanced)越高越好 |
|---|---|---|---|
| MVSNet(2018) | 开山之作 | 0.396/0.527/0.462 | 43.48 |
| RMVSNet(2019) | 引入RNN,主打减少内存消耗(但时间增加) | 0.383/0.452/0.417 | 48.40/24.91 |
| PointMVSNet(2019) | 直接操作点云,同样减少内存消耗,时间增加不明显 | 0.361/0.421/0.391 | 48.27 |
| P-MVSNet(2019) | 对卷积核做文章,使用特殊卷积核更好地在2D像素点周围、3D深度方向聚合信息 | 0.406/0.434/0.420 | 55.62 |
| MVSCRF(2019) | 引入条件随机场来对深度图做平滑优化 | 0.371/0.426/0.398 | 45.73 |
| cascade MVSNet(2020) | 使用2D UNet的多尺度图像特征,迭代更新深度推断的精度和尺寸 | 0.325/0.385/0.355 | 56.42/31.12 |
| UCSNet (2020) | 使用2D UNet的多尺度图像特征,迭代更新深度推断的精度和尺寸(与UCSNet区别在使用不确定性图来决定下一次深度取值范围) | 0.338/0.349/0.344 | 54.83 |
| CVP-MVSNet(2020) | 使用图像金字塔,构建局部代价体,用类似PointMVSNet推断深度的残差累加到上一次迭代推断出的深度图上 | 0.296/0.406/0.351 | 54.03 |
| Fast-MVSNet (2020) | 利用数学高斯牛顿迭代法来优化(待补充) | 0.336/0.403/0.370 | 47.39 |
| CIDER (2020) | 不用方差构建代价体,而是引入特征图分组、内积计算相似度方法减小计算量和内存消耗 | 0.417/0.437/0.427 | 49.60/23.12 |
| PVA-MVSNet(2020) | 使用2D UNet的多尺度图像特征,在方差法构建代价体时引入自适应视角聚合模块来考虑部分视图下对应特征被遮挡的情况(降低该特征图下该特征的权重) | 0.379/.0336/0.357 | 54.46 |
| D2HC-RMVSNet(2020) | (待补充) | 0.395/0.378/0.386 | 59.20 |
| Vis-MVSNet(2022) | 在每个源视图和参考视图间构建pair-wise代价体,并推断出一张深度图和不确定性图,使用不确定性图来fusion最终的代价体 | 0.369/0.361/0.365 | 60.03 |
| EPP-MVSNet(2021) | 考虑自适应选取极线上对应的2D特征,利用熵来选取采样区间缩小范围,使用伪3D卷积代替普通3D CNN卷积 | 0.413/0.3296/0.355 | 61.68 |
| AA-RMVSNet(2021) | 使用可变形卷积核,同时也用PVA的策略考虑遮挡权重问题 | 0.376/0.339/0.357 | 61.51 |
| PatchmatchNet(2021) | 多尺度由粗到细优化、组关联度、考虑视图间遮挡因素、可变卷积等,并且引入传播的概念来让各点试探周围同物体表面的深度值 | 0.427/0.277/0.352 | 53.15/32.31 |
| GBI-Net(2021) | 将深度推断看做一个二分搜索问题,高效查找预测深度 | 0.315/0.262/0.289 | 61.42/37.32 |
| RC-MVSNet (2022) | (待补充) | 0.369/0.295/0.345 | 55.04 |
| Transmvsnet(2022) | (待补充) | 0.321/0.289/0.305 | 63.52 |
| CDFSNet(2022) | (待补充) | 0.352/0.280/0.316 | 61.58 |
| NP-CVP-MVSNet (2022) | 考虑多Stage深度采样时第一个stage预测的单峰深度区间未必适用于后续高精度stage下该patch内某些下像素的真实深度,采用针对各像素选取深度概率最高的K个区间在下一个stage作为深度采样区间 | 0.356/0.275/0.315 | 59.64 |
1.MVSNet ECCV2018
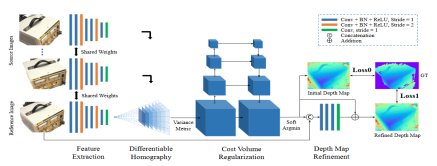
作者Yao Yao,MVSNet系列的开山之作.
- 构建了使用多张图像推断深度的MVSNet Pipeline:
特征提取 - 单应变换 - 特征体 - 代价体 - 正则化 - 深度推断 - 后处理- 与传统方法相比:精度不如,但完整度更高
- (截止2022年基于学习方法的精度还都比不上传统方法,但完整度上普遍较高)
2.RMVSNet CVPR2019
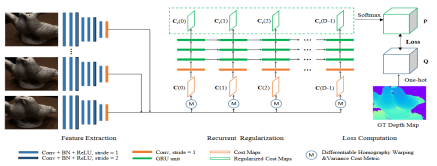
Yao Yao续作,将RNN引入MVSNet系列,开启用时间换空间的优化方向。
- 在Pipline的正则化、深度推断、后处理三个部分做了优化:
1.正则化:引入循环神经网络GRU模块在深度方向上逐步正则化(相当于时间方向)
2.深度推断:看作多分类任务而非深度回归任务来处理
3.细分优化深度图:解决多分类导致的阶梯现象(sub-pixel accuracy)
- 相比MVSNet提高精度和完整度同时减少了内存消耗,相应的训练时长剧增。
3.P-MVSNet ICCV2019
在正则化部分做优化,主要特点在使用“向异性”的卷积核在空间上下文、深度方向上聚合信息,而不是单纯使用UNet来做。
- 在Pipline的正则化部分做了优化:
分别以patch和pixel为单位,引入各向异性的卷积核(即mxn型卷积核,如7x1,各向同性的为nxn型,如3x3),分别在空间上下文(2D周围方向,如用3x3x1卷积核)、深度(3D深度方向,如用1x1x7卷积核)聚合信息,优化原始的代价体以推断更准确的深度图
- 相比MVSNet完整度损失降低,但精度损失略高,overall(精度、完整度损失之和的均值)更低
4.MVSCRF ICCV2019
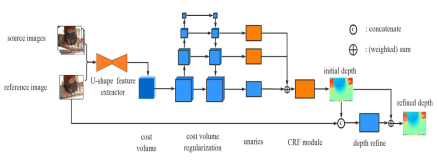
(待补充)
5.PointMVSNet ICCV2019
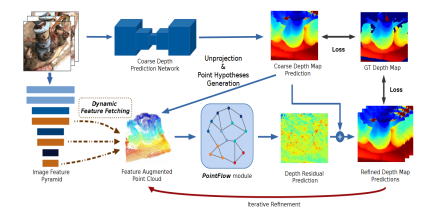
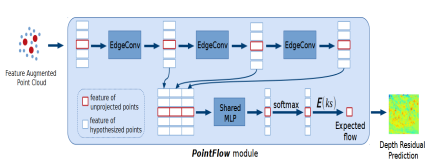
为了避免在构建代价体部分所付出的巨大内存代价,选择直接在点云上进行操作;
引入迭代多轮次优化深度推断的思想,使用“深度残差”思路,寻找各点预测深度与真实深度之间的差值并不断优化深度图。
- 使用Pipline的基础上做了较大改动,引入了迭代优化的思想,并在点云上进行处理
1.一个简单的MVSNet Pipline
2.基于粗略推断的深度图构建出原始点云,并基于原始点云构建增强点云(以原始点云中各3D点为中心,沿深度方向前后各取一些假设点,即真实点可能在的位置),随后找到增强点云上3D点对应图片位置上的2D特征,构建各点的2D-3D混合特征;
3.将2D-3D特征输入PointFlow模块,根据点云的局部结构特征对点云进行操作,最终输出的是深度残差图,即各点相对于原始推断深度的差值
4.原始深度图+残差深度图获取新深度图,随后迭代2.3步骤
- 相比MVSNet完整度、精度损失都有降低,且在内存消耗上减少,时间上略有增加
2019年的这四篇文章各有特点,其中RMVSNet、PointMVSNet更是打开了可以继续沿着往下做的思路:
| 论文 | 特点 | DTU(acc/com/overall)越低越好 | Tanks(mean)越高越好 |
|---|---|---|---|
| MVSNet | 开山之作 | 0.396/0.527/0.462 | 43.48 |
| RMVSNet | 引入RNN,主打减少内存消耗(但时间增加) | 0.383/0.452/0.417 | 48.40 |
| PointMVSNet | 直接操作点云,同样减少内存消耗,时间增加不明显 | 0.361/0.421/0.391 | 48.27 |
| P-MVSNet | 对卷积核做文章,使用特殊卷积核更好地在2D像素点周围、3D深度方向聚合信息 | 0.406/0.434/0.420 | 55.62 |
| MVSCRF | 引入条件随机场来对深度图做平滑优化 | 0.371/0.426/0.398 | 45.73 |
6.cascade MVSNet CVPR2020
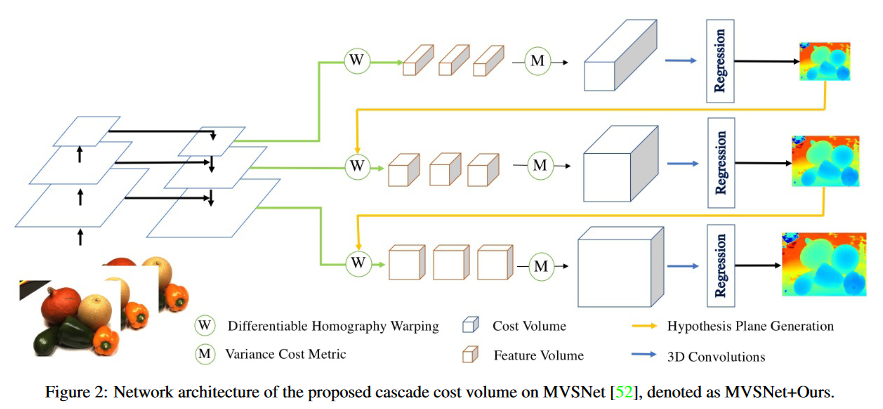
- 在Pipline的特征提取、单应变换部分做了优化,并使用迭代优化思想:
1.特征提取:使用2D Unet来提取不同尺度的特征供不同迭代轮次使用
2.单应变换:在不同的迭代轮次,分别使用上一轮的深度推断图,基于各点的上一轮预测深度来更新本轮的深度采样区间,继续按pipline的方法构建代价体、推断深度图,从而使各点深度推断越来越精确
- 相比MVSNet完整度、精度损失都有降低,且在内存消耗上减少,时间上略有增加
7.UCSNet CVPR2020
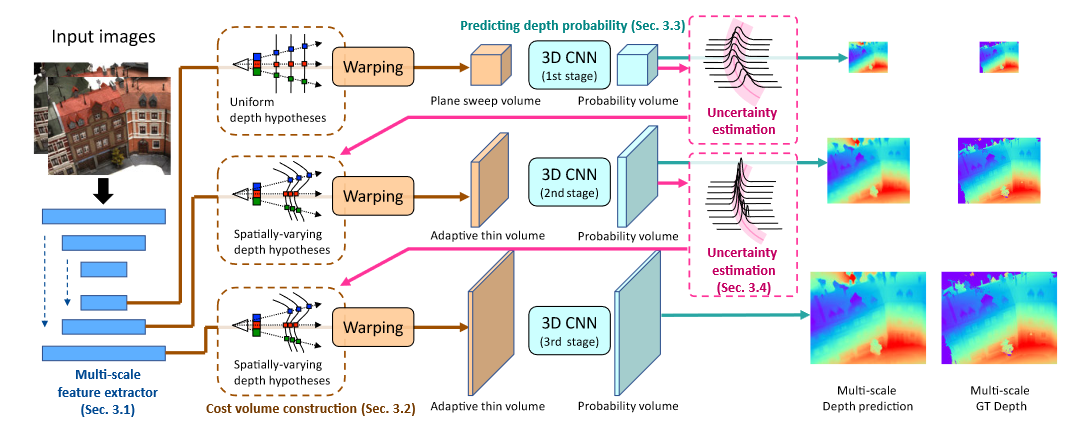
- 在Pipline的特征提取、单应变换部分做了优化,并使用迭代优化思想:
1.特征提取:使用2D Unet来提取不同尺度的特征供不同迭代轮次使用
2.单应变换:在不同的迭代轮次,分别使用上一轮的深度推断图,基于各点的上一轮预测深度来更新本轮的深度采样区间(具体区间大小选择基于“不确定性估计”,即在上一轮次概率体推断深度图过程中,对每个像素点沿深度方向求方差,方差越小则确定性越高,下一轮次的深度区间选择可以越小),随后继续按pipline的方法构建代价体、推断深度图,从而使各点深度推断越来越精确
- ps: 与同年的cascade MVSNet非常相似,对比来看cascade MVSNet在DTU上精度高,但完整度和overall低;cascade MVSNet在Tanks上mean更高,都没有完全超越对方所以都发表了。
8.CVP-MVSNet CVPR2020
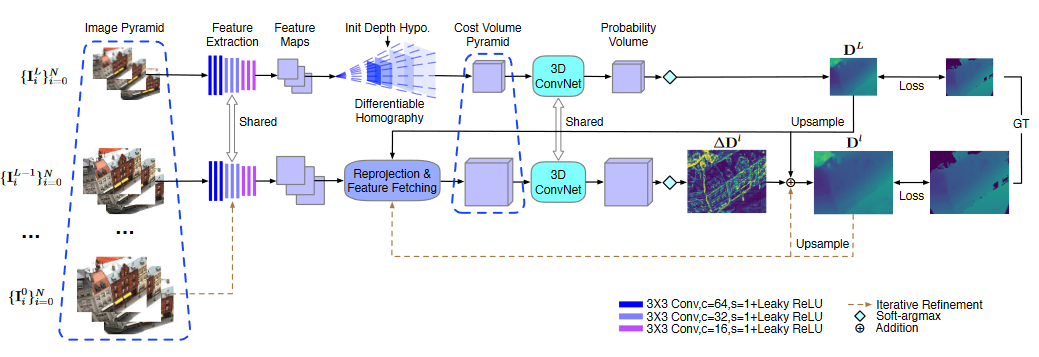
- 在Pipline的特征提取、代价体构建部分做了优化,并使用迭代优化思想:
1.特征提取:使用特征金字塔来提取不同尺度的特征供不同迭代轮次使用
2.代价体构建:在不同的迭代轮次,基于各点的上一轮预测深度获取对应初始3D点位置,并以该位置为中心,沿深度方向前后选取一些假设3D点(像素对应的真实3D点可能是初始的、也可能是我们选的这些存在Δd的假设点);
将这些点深度值作为深度采样值,选取这些深度下的对应2D图像特征计算方差以构建局部代价体,随后通过正则化来得到各点的深度残差值(与上一轮深度图上各点深度的Δd)- ps: 与PointMVSNet的思想类似,都是推断残差深度;与cascade MVSNet类似之处在于都在不同迭代轮次使用不同的深度采样值,不同处在于cascade MVSNet每一轮使用pipline(在深度区间上直接均匀采样假设深度值)来推断完整深度图,而CVP-MVSNet是构建局部代价体(使用初始推断3D点深度方向附近的假设点来选取深度假设)进行推断残差深度图
- 相比19年几篇在完整度、精度损失都有降低,输出深度图尺寸最大且时间消耗是最低,内存消耗相对也较少
9.Fast-MVSNet CVPR2020
10.CIDER AAAI2020
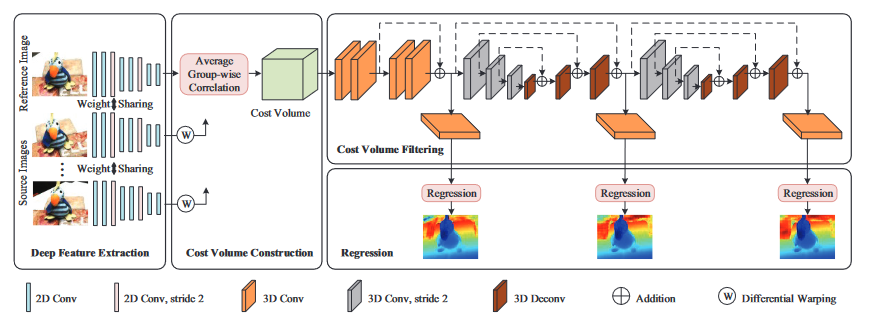
在Pipline的代价体构建、正则化部分做了优化:
1.代价体构建:单应变换之后不使用方差法,而是将特征图按通道分组,与参考视图对应通道做内积来计算相似度图构建代价体,减小了计算量和内存消耗
2.在正则化部分使用ResNet模块、两个3D Unet来进行正则化(论文指出该分组方法内存消耗小所以可以使用两个Unet,而之前的模型则不行)
在DTU数据集上表现一般(相比同2020年的几篇CVPR),但在Tanks上均值高且内存和时间消耗相对少
11.PVA-MVSNet ECCV2020
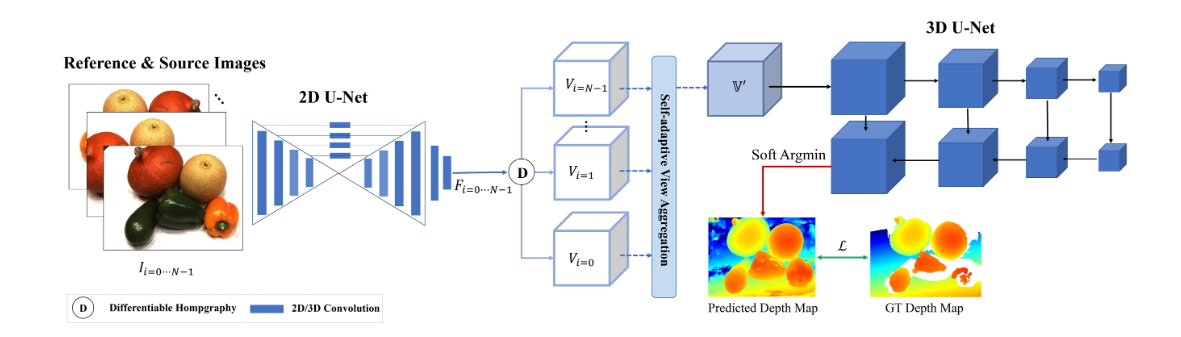
- 在Pipline的特征提取、代价体构建部分做了优化:
1.特征提取:使用2D Unet来提取特征
2.代价体构建:使用了一个叫做自适应视角聚合(self-adaptive view aggregation)的模块来构建代价体:即在不同视图的特征体聚合为代价体时不是直接取平均值,而是根据各视图下各像素点特征与参考视图对应点特征相似程度来赋予权重(相似度高说明该像素点在两视图下均可见,因此该点的代价匹配权重应该高一些)
完整度损失明显下降,在tanks上表现也不错
12.D2HC-RMVSNet ECCV2020 Spotlight
Vis-MVSNet 2020 BMVC(CCF C) & 2022 IJCV(CCF A)
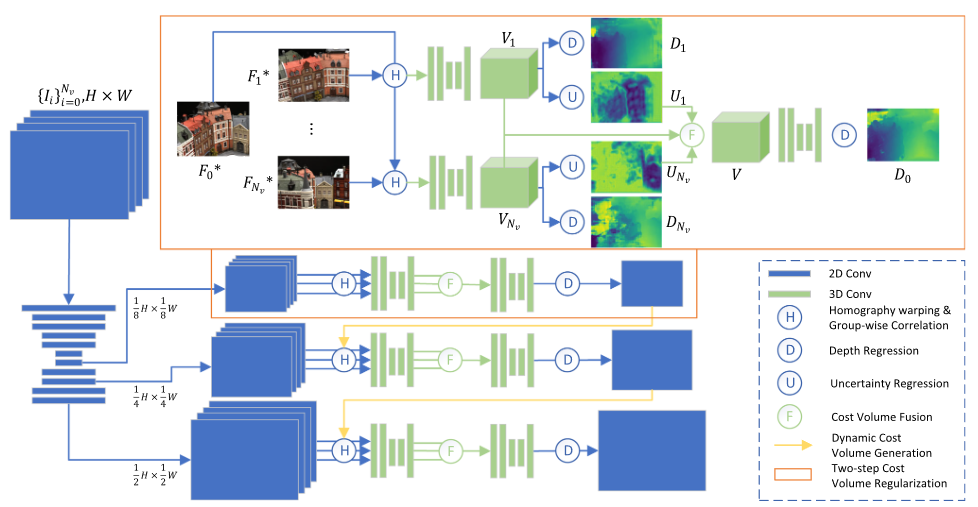
(1)创新点主要是在每个源图像与参考图像之间构建pair-wise的代价体
V
N
v
V_{N_{v}}
VNv,并据此推断深度图和不确定性图,最终依据不确定性图来执行fusion构建最终代价体V。

首先利用概率体中每个像素在各个深度的概率计算其熵,并利用一个浅层的2D CNN来获取不确定性图U,内在原因是熵可以判断分布的随机性,这与单峰分布负相关,而越近似单峰分布该处的深度置信度越高。
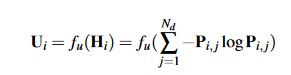
为了同时回归深度估计及其不确定性,论文假设深度估计遵循拉普拉斯分布(在论文What uncertainties do we need in bayesian deep learning for computer vision中提到),在这种情况下,估计的深度和不确定性可以通过最大化观察到的深度真实值的可能性实现:
p
(
D
g
t
,
i
∣
D
i
,
U
I
)
=
1
2
U
i
⋅
e
∣
D
i
−
D
g
t
,
i
∣
U
i
p(D_{gt,i}|D_{i},U_{I})=\frac{1}{2U_{i}}·e^\frac{{|D_{i} -D_{gt,i}|}}{U_{i}}
p(Dgt,i∣Di,UI)=2Ui1⋅eUi∣Di−Dgt,i∣
最小化上述负对数似然可以得到以下损失公式:
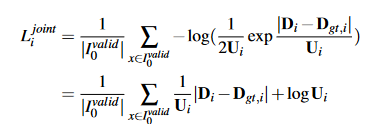
该损失也可以解释为使用正则化项对估计和真实值之间的 L1 损失应用衰减。(论文说这样做的直觉是应该减少错误样本的干扰?😥)
(2)利用CascadeMVSNet的方法,逐步缩小下一个Stage的深度采样区间(并未用到不确定性图)。
2020年涌现了很多优化的方法,整体来看有几篇文章的共同点有几个:
- 使用迭代优化思想,逐步提高推断深度图的尺寸和精度,以减少内存和时间消耗
- 使用图像金字塔来提取并利用不同层次的深度图像特征
- 构建代价体时不是单纯的使用平均方差,而考虑用组内积衡量相似度、或是考虑遮挡情况下有些特征在某视角下不可见的情况(赋予不同权重)
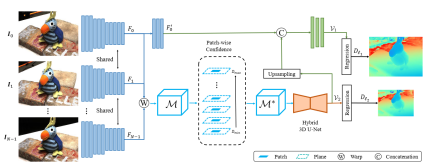
13.AA-RMVSNet ICCV2021
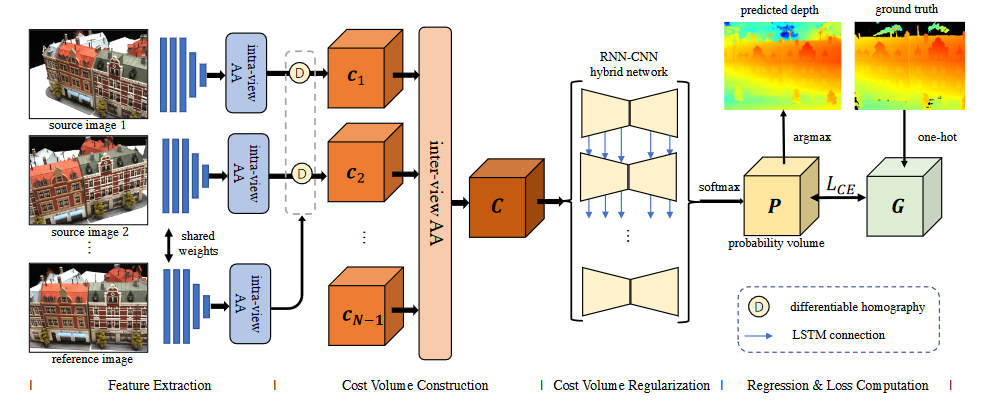
- 在Pipline的特征提取、代价体构建、正则化部分做了优化:
1.特征提取:使用inter-view adaptive aggregation模块,使用可变形卷积核
2.代价体构建:类似PVA-MVSNet的思想,使用intro-view adaptive aggregation
3.正则化部分使用3D Unet与LSTM的混合正则化网络
完整度相比20年的文章又有提升,overall略不如;在tanks上提高较大
14.Epp-mvsnet CVPR2021
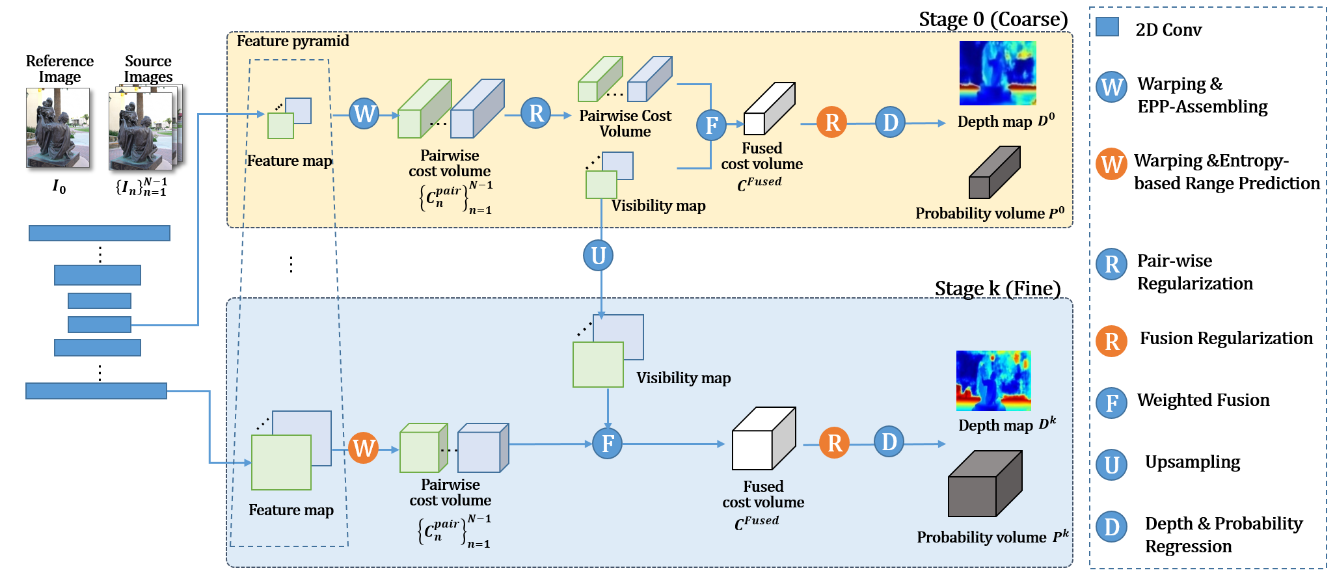
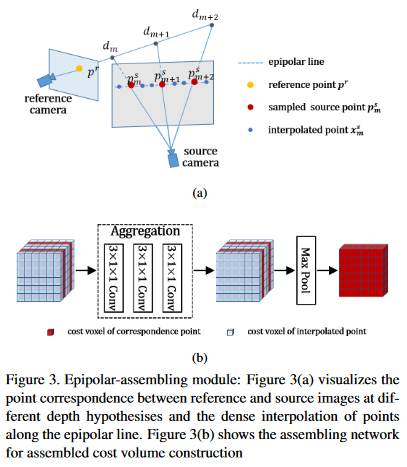
(1)考虑单应变换时通常都是直接使用对应变换后像素点的二维特征,如使用逆深度配置时即在极线上均匀间隔采样,这未能充分利用高分辨率图像极线上众多的特征,设置一个Epipolar-assembling模块来自适应地选取对应点间隔从而使用自适应的二维点特征。具体来讲,即在变换后的2D点前后位置插值特征点,随后得到由原始2D点和插值点特征组成的代价体,并通过聚合和pooling模块来得到最终的2D特征。
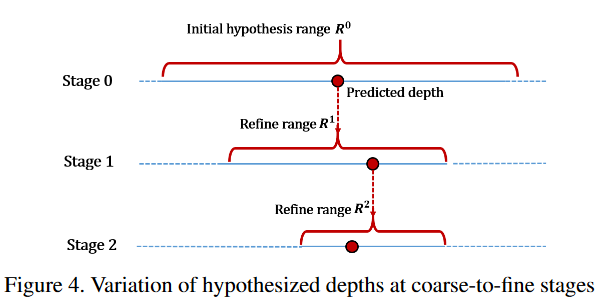
(2)在多个stage下逐渐缩小深度采样区间,提出Entropy-based refining strategy即基于熵的区间选取策略。

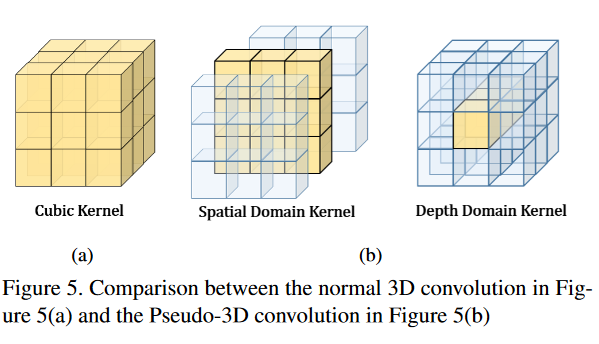
(3)论文认为考虑到代价体由普通立方 CNN 卷积的不同深度的相邻像素的成本量几乎没有相干性,反而会导致冗余计算和高成本,因此用伪 3D 卷积替换了普通的 3D 卷积运算符。
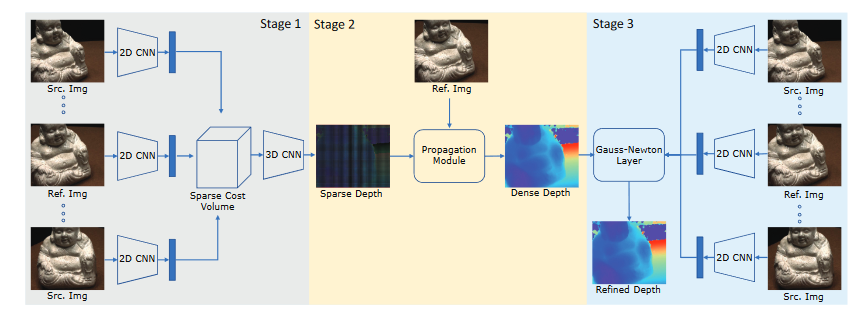
15.Patchmatchnet CVPR2021
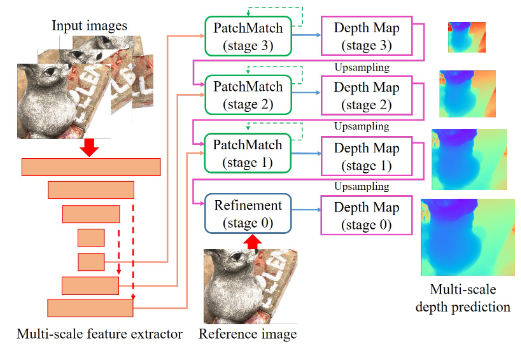
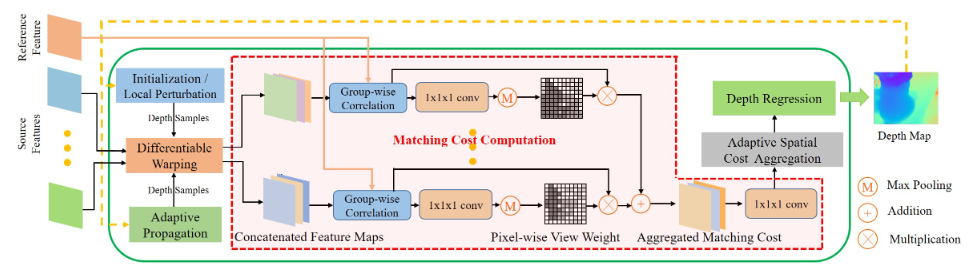
- PatchmatchNet使用了之前MVSNet中多种优化的技巧(多尺度由粗到细优化、组关联度、考虑视图间遮挡因素、可变卷积等),并且引入传播的概念来让各点试探周围同物体表面的深度值,详细见连接
精度不高,但完整度一下子提升很多;在tanks的高级数据集上也能进行并确定好结果。
2021年主要有3篇比较典型的MVSNet变型网络,基本都用到了20年已有的有效改进:
- 无一例外使用迭代优化思想,在尝试减少内存和时间消耗的基础上逐步提高推断深度图的尺寸和精度
- 使用图像金字塔来提取并利用不同层次的深度图像特征、或是用可变形卷积核获取更有代表性的特征
- 构建代价体时不是单纯的使用平均方差,而考虑用组内积衡量相似度、或是考虑遮挡情况下有些特征在某视角下不可见的情况(赋予不同权重)
相比之下,
- AA-RMVSNet沿袭之前的思路,主要是在特征提取增加可变形卷积核、正则化部分用混合RNN-CNN的网络
- EPP-MVSNNet主要是考虑在极线上用自适应选取对应2D特征的方法来充分利用高分辨率图像特征,同时用伪3D卷积加速
- PatchmatchNet可以说是集21年之前众多论文所用有效技巧的集大成之作,同时还引入了传播更新深度的方法,非常典型。
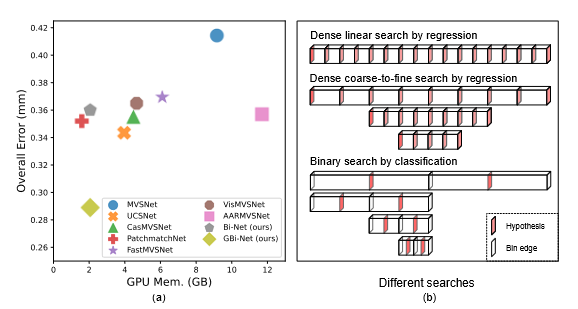
16.GBi-Net CVPR 2021
(1)将深度推断看做一个搜索问题,并使用二分查找的思路使用多个Stage来分类各像素的正确预测深度所在区间Bin(下图所示),通过每个Stage可以消除一半的搜索空间,从而能够在对数级的stage里收敛到较细的深度粒度,高效减少了构建稠密代价体过程导致的内存消耗问题。
(2)二分查找在高效的同时,可能会由于在上一个stage选择了错误的bin而导致接下来误差被累计和低精度,因此提出了一个ETB(error tolerance bins)模块,即当前stage的预测深度所在bin会被划分为两个更小的bin供下一个stage作为深度采样区间,此时在两块bin的左右各增加一个小区间bin来保证对错误预测的情况有一定的容忍度。
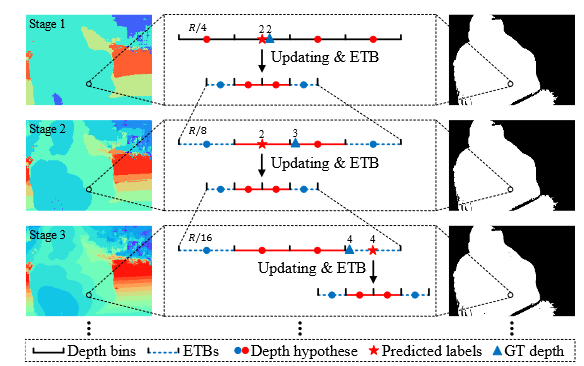
(3)在计算Loss时,首先会将各像素的真实深度进行one-hot编码得到真实概率体G(蓝色),与预测概率体(绿色)之间计算交叉熵损失;论文指出此时部分像素的真实深度值可能在我们设置的预测bin之外,从而会导致误差积累,因此提出一个Gradient-Masked Optimization模块,即图中黑色的Mask二值图,只有当各像素点真实深度在预测bin之内时为1并将其设为valid,最终参与梯度优化的都是有效像素点。
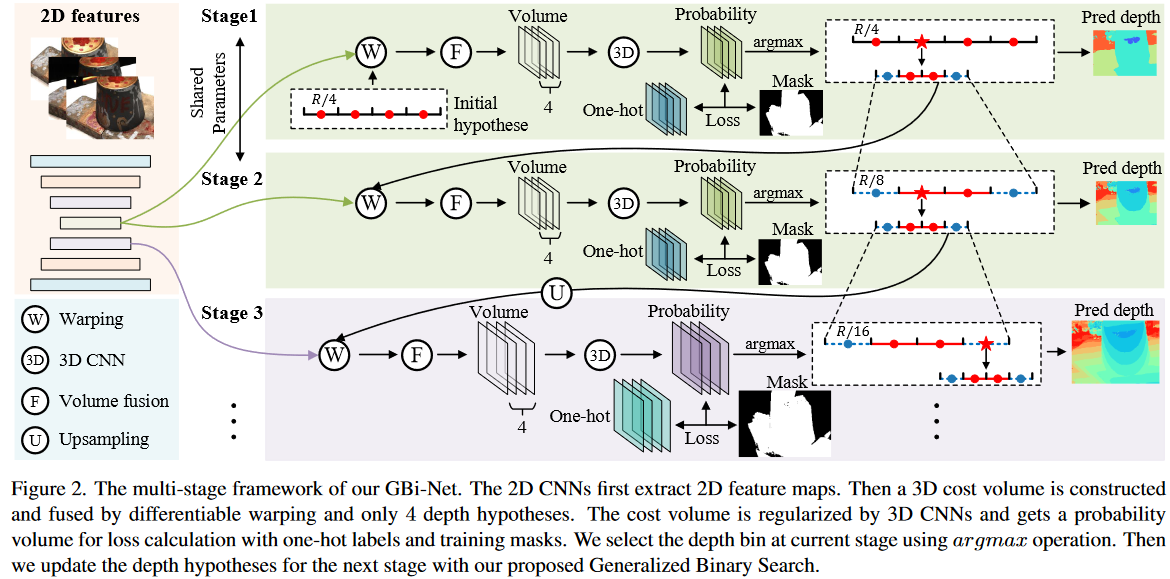
(4)最后又提出一个efficient gradient updating mechanism,即以更节省内存的方式训练网络——具体来说,计算损失并在每个阶段后立即反向传播梯度。梯度不会跨阶段累积,因此最大内存开销不会超过规模最大的阶段。为了使多阶段训练更稳定,我们首先将搜索阶段的最大数量设置为 2,并随着 epoch 数量的增加逐渐增加。(没太明白😥)
17.NP-CVP-MVSNet CVPR2022
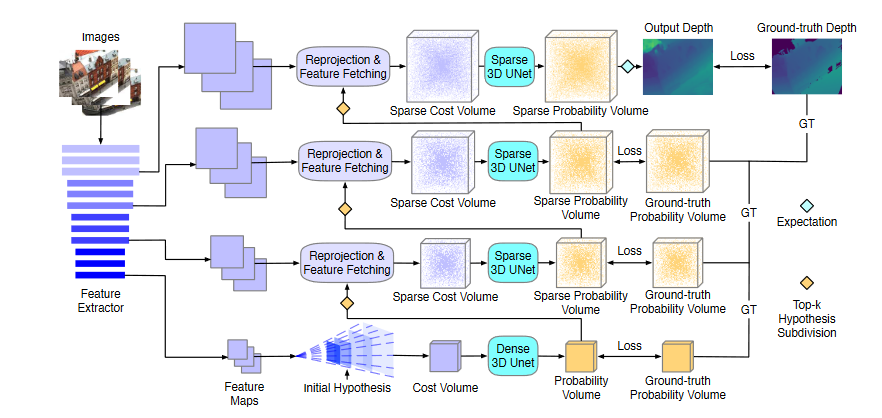
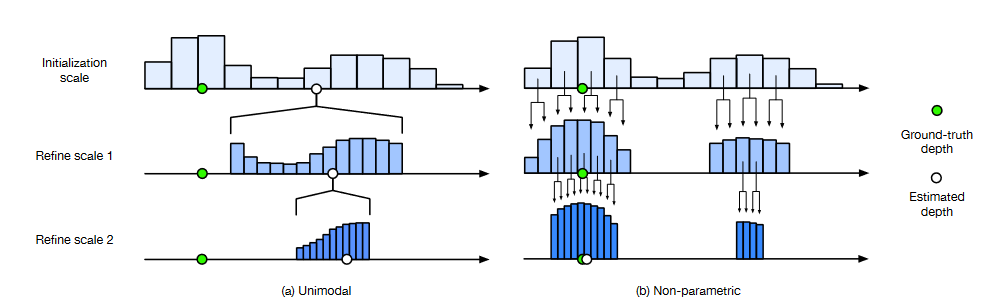
(1)考虑之前的迭代多轮次深度回归方法都是假设像素点的深度分布为单峰分布(Unimodal,图a),这可能出现首次深度推断就出现错误,进而在后续迭代中不断传播误差使得深度推断错误的问题;据此引入一个非参数(Non-parametric,图b)的深度概率模型来应对各像素的任意深度分布。
具体来讲,即选取概率最高的前K个深度假设,将其每一个划分为
d
−
1
4
Δ
d
,
d
+
1
4
Δ
d
d-\frac{1}{4}Δd,d+\frac{1}{4}Δd
d−41Δd,d+41Δd的两个深度假设,在下一个stage作为深度采样假设进行单应变换。
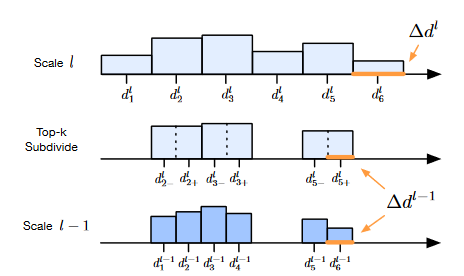
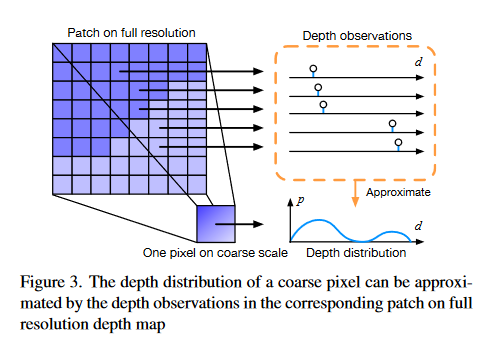
(2)解释了单峰分布会出现问题的原因之一——即在多次迭代推断深度的方法中一开始往往使用分辨率较小的图像以节省内存和时间消耗,这意味着稀疏尺度图像下一个像素的深度来自于高精度图像中一个patch的深度,由于深度分布不同它们本身可能就有较大的深度差异,如果单纯选取单峰模型则可能会导致在后续Stage中周围深度差异较大像素无法推断出其真实像素的情况。
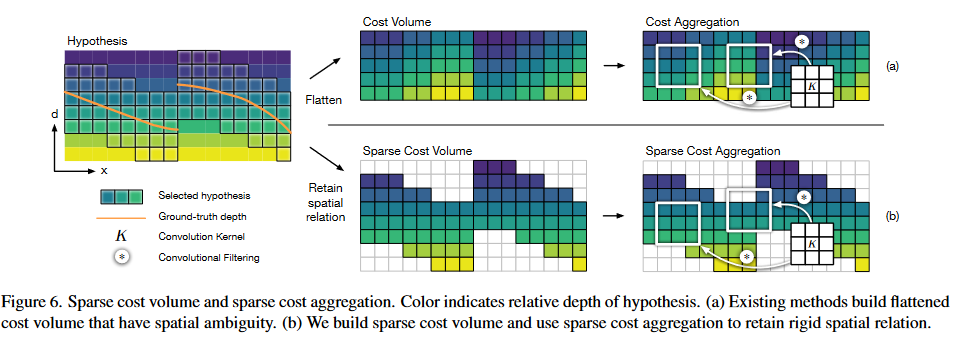
(3)由于使用上述非参数化的深度采样方式对各像素点采样深度并进行单应变化会导致各像素点的深度假设不同,想要使用传统的3D卷积在周围像素之间聚合深度信息变得不可行,提出了稀疏代价体(Sparse cost volume)和稀疏代价聚合(Sparse cost aggregation)的方法,具体的Sparse 3D Unet网络结构在supplymaterial给出。
在这种情况下,前几个stage的损失函数的定义也是比较预测像素深度值与真实像素深度值的分布(使用二元交叉熵损失),其中真实像素值的分布用各像素、与周围patch内的像素深度直方图进行归一化得到的结果来近似;最后一个Stage推断深度图后仍使用L1损失函数,最终整个流程的训练损失函数为各stage的损失加权。
(4)画图很好看,色彩搭配以及逻辑表达都值得学习;更重要的是学习思路,从之前方法中大家都在固定用的一个环节当中思考存在的问题,并阐释背后导致问题出现的原因(图示),随后细挖可以改进的方法,并解决这种“不常规”方法可能会带来的问题(如文章中的深度样本不一致导致无法常规3D卷积,而使用Sparse3D卷积),以及最终该方法需要怎样的损失函数来配合,需要做哪些调整(如文中说真实情况可能会多0而加概率权重)。当然,效果是最重要的,要利用最新文章的技巧来保证首先达到SOTA使得改进能够得以体现。
18.UniMVSNet CVPR 2022
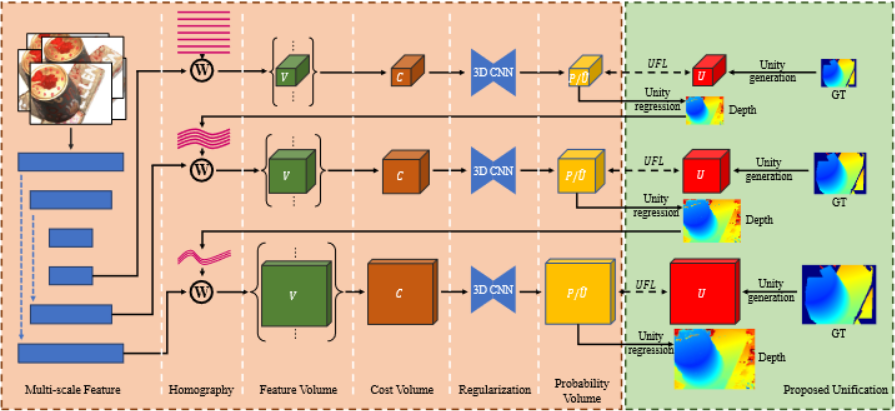
(1)用Unification方法来结合回归和分类方法推断深度的优势
回归:由于间接地学习代价体与深度权重之间的组合关系,容易过拟合
分类:可以直接约束代价体,但由于不连续导致深度不准确
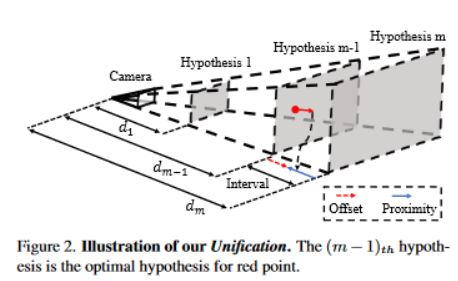
Unification: 先分类出距离最近的深度假设平面,然后回归出与该平面的接近度(proximity)
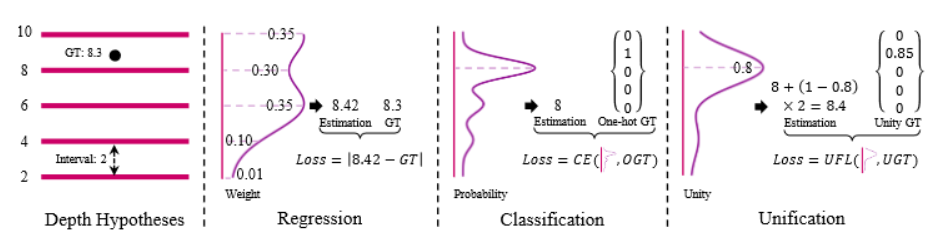
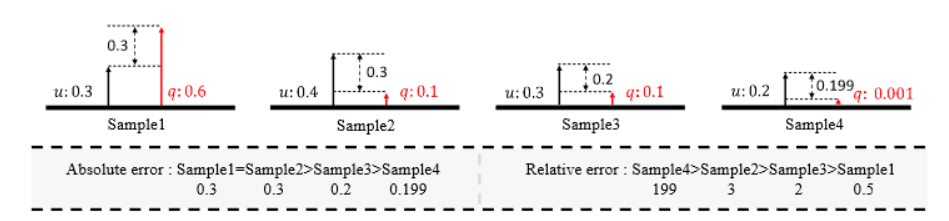
(2)针对MVS方法中深度样本采集需要尽量稠密、但真实深度样本单一导致的样本不平衡,以及模型应该对硬样本保持更多关注这两个问题,使用了检测领域常用的Focal Loss(FL)方法,并考虑真实样本值的数量级问题将其优化为Unified Focal Loss(UFL)作为训练损失函数使用。(Focal Loss这部分没看太明白,求解释😥)
(3)对之前MVSNet方法的pipeline的英文总结的很好,值得学习。
19.PVSNet IJCV 2022
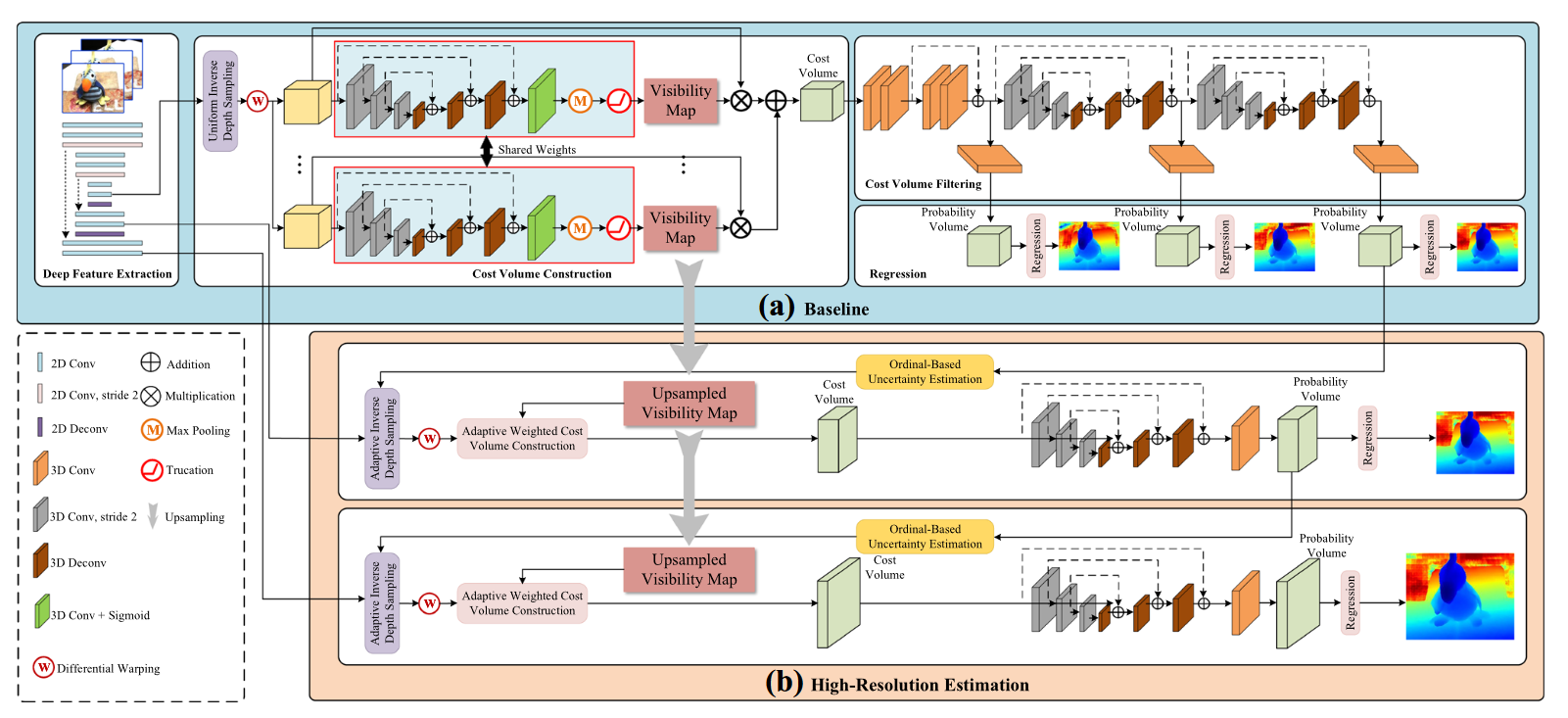
(1)在2020年CIDER的基础上,增加了可视图推断模块组成(a)baseline,同时又提出(b)高分辨率深度估计模块,该部分创新在于使用基于序数的自适应深度采样模块来在逆深度空间选取对应的深度假设。
(a)可视图visibility map计算公式:
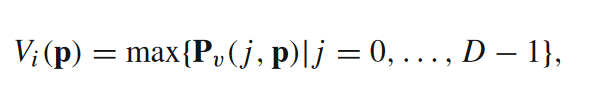
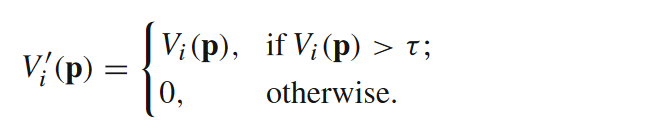
即利用各像素在概率体深度方向最大的概率值,并设置阈值排除低概率以降低错误匹配权重。
2022年
- GBI-Net则提供了一个全新的搜索深度思路,利用二分搜索来查找深度从而大幅度减少内存消耗。
- NP-CVP-MVSNet主要是考虑多stage回归深度时初始默认深度单峰分布可能造成的误差累计问题,提出不同的深度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









