







文章目录
前言
众所周知 Spring 是一个非常优秀的框架,也是一个把设计模式用的淋漓尽致的框架,Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量级开源框架,为开发Java应用程序提供全面的基础架构支持。Spring负责基础架构,因此Java开发者可以专注于应用程序的开发。
一、Spring 中设计模式命名规范及类型
- Spring 是一个把设计模式用的淋漓尽致的框架,从类的命名就能看得出来,如下面表格所示:
| 设计模式名称 | 举例 |
|---|---|
| 工厂模式 | BeanFactory |
| 装饰者模式 | BeanWrapper |
| 代理模式 | AopProxy |
| 委派模式 | DispatcherServlet |
| 策略模式 | HandlerMapping |
| 适配器模式 | HandlerAdapter |
| 模板模式 | JdbcTemplate |
| 观察者模式 | ContextLoaderListener |
- 设计模式根据特性分为三种类型,分别为创建型模式、结构性模式、行为型模式如下表所示:
| 类型 | 名称 | 英文 |
|---|---|---|
| 创建型模式 | 工厂模式 | Factory Pattern |
| 单例模式 | Singleton Pattern | |
| 原型模式 | Prototype Pattern | |
| 结构性模式 | 适配器模式 | Adapter Pattern |
| 装饰者模式 | Decorator Pattern | |
| 代理模式 | Proxy Pattern | |
| 行为型模式 | 策略模式 | Strategy Pattern |
| 模板模式 | Template Pattern | |
| 委派模式 | Delegate Pattern | |
| 观察者模式 | Observer Pattern |
注意:
设计模式从来都不是单个模式独立出现,在实际应用中,通常都是多个设计模式混合使用。
二、Spring 中设计模式详解
1. 工厂模式
现实生活中,原始社会自给自足(没有工厂),农耕社会小作坊(简单工厂,民间酒坊),工业革命流水线(工厂方法,自产自销),现代产业链代工厂(抽象工厂,富士康)。我们的项目代码同样是由简到繁一步一步迭代而来的,但对于调用者来说,却越来越简单。
1.1 简单工厂模式
简单工厂模式是指由 一个 工厂对象创建哪一个产品类的实例。简单工厂模式只适合用于工厂类创建对象较少的场景,且客户端只需要传入工厂类的参数,对于如何创建对象不需要关心。
接下来上代码演示,阿峰课堂目前设有java和python课程先定义一个ICourse接口:
public interface ICourse {
// 录制视频
void recoird();
}
创建一个 Java 课程的实现 JavaCourse 类和 Python 课堂的实现 PythonCourse 类:
public class JavaCourse implements ICourse {
@Override
public void recoird() {
System.out.println("录制 Java 课程");
}
}
public class PythonCourse implements ICourse {
@Override
public void recoird() {
System.out.println("录制 Python 视频");
}
}
我们再使用客户端调用代码:
public class Test {
public static void main(String[] args) {
ICourse javaCourse = new JavaCourse();
ICourse pythonCourse = new PythonCourse();
javaCourse.recoird();
pythonCourse.recoird();
}
}
类图以及时序图如下:
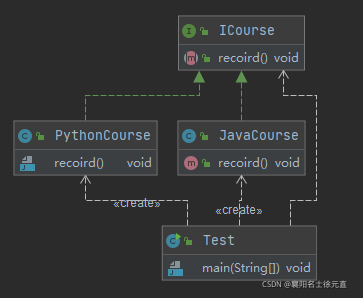
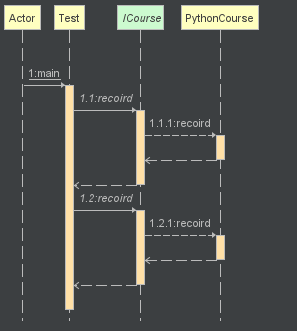
在类图中我们可以发现应用层代码需要依赖 JavaCourse 和 PythonCourse,如果业务扩展,继续增加更多的课程,那么客户端的依赖就会越来越臃肿。因此需要我们隐藏创建的细节,现在我们使用简单工厂模式对代码进行优化。
创建工厂类 CourseFactory:
public class CourseFactory{
public static ICourse create(String name) {
switch (name) {
case "java":
return new JavaCourse();
case "python":
return new PythonCourse();
default:
return null;
}
}
}
修改客户端的代码:
public class Test01 {
public static void main(String[] args) {
ICourse java = CourseFactory.create("java");
if (java != null) {
java.recoird();
}
ICourse python = CourseFactory.create("python");
if (python != null) {
python.recoird();
}
}
}
接下来我们再看看下类图以及时序图:
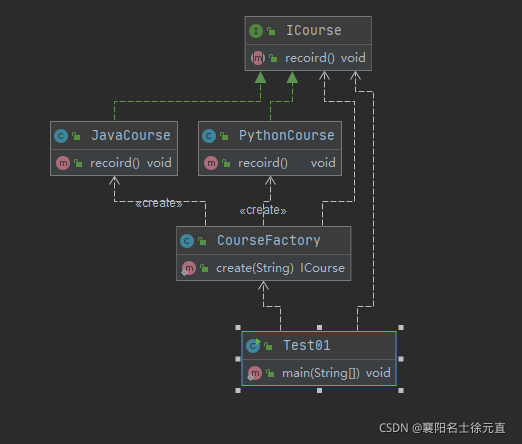
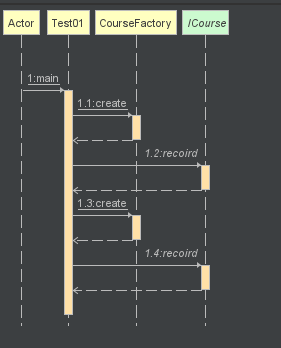
从类图和时序图可以发现客户端只需要依赖于工厂类,然后根据参数去创建相应的类,使得调用更加的简便,但是如果我们的业务继续扩展,那么工厂中的创建方法就要每次根据产品的增加而修改代码逻辑,不符合开闭原则,因此我们可以使用反射继续对简单工厂模式进行优化修改工厂的创建方法:
public class CourseFactory02 {
public static ICourse create(Class<? extends ICourse> clazz) {
try {
return clazz.newInstance();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return null;
}
}
客户端代码如下:
public class Test02 {
public static void main(String[] args) {
ICourse java = CourseFactory02.create(JavaCourse.class);
if (java != null) {
java.recoird();
}
ICourse python = CourseFactory02.create(PythonCourse.class);
if (python != null) {
python.recoird();
}
}
}
优点和缺点
优点:
- 工厂类包含必要的逻辑判断,可以决定在什么时候创建哪一个产品的实例。客户端可以免除直接创建产品对象的职责,很方便的创建出相应的产品。工厂和产品的职责区分明确。
- 客户端无需知道所创建具体产品的类名,只需知道参数即可。 也可以引入配置文件,在不修改客户端代码的情况下更换和添加新的具体产品类。
缺点:
- 简单工厂模式的工厂类单一,负责所有产品的创建,职责过重,一旦异常,整个系统将受影响。且工厂类代码会非常臃肿,违背高聚合原则。
- 使用简单工厂模式会增加系统中类的个数(引入新的工厂类),增加系统的复杂度和理解难度
- 系统扩展困难,一旦增加新产品不得不修改工厂逻辑,在产品类型较多时,可能造成逻辑过于复杂
- 简单工厂模式使用了 static 工厂方法,造成工厂角色无法形成基于继承的等级结构。
应用场景:
对于产品种类相对较少的情况,考虑使用简单工厂模式。使用简单工厂模式的客户端只需要传入工厂类的参数,不需要关心如何创建对象的逻辑,可以很方便地创建所需产品。
1.2 工厂方法模式
工厂方法模式是指定义一个创建对象的接口,但让实现这个接口的类觉定实例化哪个类,工厂方法模式让类的实例化推迟到子类进行。在工厂方法模式中用户只需要关心所需产品对应的工厂,无需关心创建细节,而且加入新的产品时符合开闭原则。
工厂方法模式主要解决产品扩展的问题。在简单工厂模式中,随着产品链的丰富,如果每个课程的创建逻辑有区别,则工厂的职责会变得越来越多,有点像万能工厂,不便于维护。根据单一原则我们将职能继续拆分,专人干专事。java 课程由 java 工厂创建,Python 课程由 Python 工厂创建,对工程本身也做一个抽象。实现如下先创建 ICourseFactory 接口:
public interface ICourseFactory {
ICourse create();
}
再分别创建子工厂:
public class JavaFactory implements ICourseFactory {
@Override
public ICourse create() {
return new JavaCourse();
}
}
public class PythonFactory implements ICourseFactory {
@Override
public ICourse create() {
return new PythonCourse();
}
}
测试类如下:
public class Test01 {
public static void main(String[] args) {
JavaFactory javaFactory = new JavaFactory();
ICourse java = javaFactory.create();
java.recoird();
PythonFactory pythonFactory = new PythonFactory();
ICourse python = pythonFactory.create();
python.recoird();
}
}
我们来看一下类图和时序图:
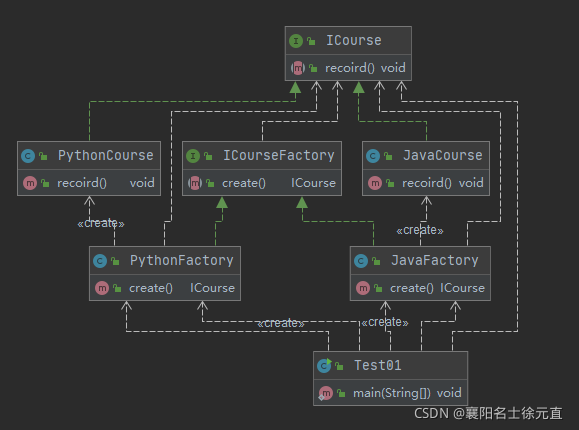
工厂方法模式适用于一下场景:
- 创建对象需要大量重复的代码。
- 客户端不依赖于产品类实例如何被创建、如何倍实现等细节。
- 一个类通过其子类来指定创建哪个对象。
工厂方法模式也有缺点:
- 类的个数容易过多,增加发杂度。
- 增加了系统的抽象性和理解难度。
1.3 抽象方法模式
抽象工厂模式是指提供一个创建一系列相关或相关依赖对象的接口,无须指定它们的具体类。客户端不依赖产品类实例如何被创建、如何倍实现等细节,强调的时一系列相关的产品对象一起使用创建对象需要大量重复的代码,需要提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现。
讲解抽象工厂之前,我们要了解两个概念:产品等级结构和产品族。
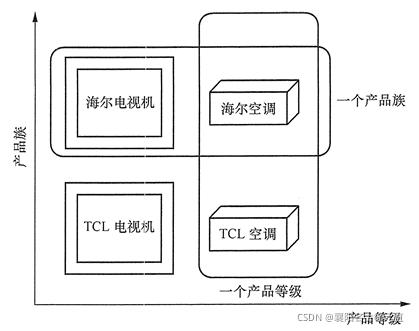
根据上图简单的来说,海尔下的所有产品都是属于一个产品族的,所有相同的产品属于同一个产品等级,我们通过一个例子进一步加深对抽象工厂的理解。阿峰课堂又有了新标准,每个课程不仅要提供课程的录播视频,还要提供老师的课堂笔记。相当于现在的业务变更为同一课程不单纯包含一个课程信息,同时包含录播视频,课堂笔记。 在产品等级增加两个产品:IVideo 录播视频和 INote 课堂笔记。
IVideo 接口如下:
public interface IVideo {
void record();
}
INote 接口如下:
public interface INote {
void edit();
}
然后创建一个抽象工厂类 CourseFactory:
public interface CourseFactory {
INote createNote();
IVideo createVideo();
}
接下来,创建 Java 产品族的 Java 视屏类 JavaVideo:
public class JavaVideo implements IVideo {
@Override
public void record() {
System.out.println("java 录频");
}
}
扩展产品等级 Java 课堂笔记类 JavaNote:
public class JavaNote implements INote{
@Override
public void edit() {
System.out.println("编写 java 笔记");
}
}
创建 Java 产品族的具体工厂 JavaCourseFactory:
public class JavaCourseFactory implements CourseFactory {
@Override
public INote createNote() {
return new JavaNote();
}
@Override
public IVideo createVideo() {
return new JavaVideo();
}
}
然后创建 Python 产品的 Python 视频类 PythonVideo:
public class PythonVideo implements IVideo {
@Override
public void record() {
System.out.println("python 录频");
}
}
扩展产品等级 Python 课堂笔记 PythonNote:
public class PythonNote implements INote {
@Override
public void edit() {
System.out.println("编写 python 笔记");
}
}
创建 Python 产品族的具体工厂 PythonCourseFactory:
public class PythonCourseFactory implements CourseFactory {
@Override
public INote createNote() {
return new PythonNote();
}
@Override
public IVideo createVideo() {
return new PythonVideo();
}
}
客户端代码如下:
public class Test01 {
public static void main(String[] args) {
JavaCourseFactory javaCourseFactory = new JavaCourseFactory();
javaCourseFactory.createNote().edit();
javaCourseFactory.createVideo().record();
PythonCourseFactory pythonCourseFactory = new PythonCourseFactory();
pythonCourseFactory.createNote().edit();
pythonCourseFactory.createVideo().record();
}
}
类图和时序图如下:
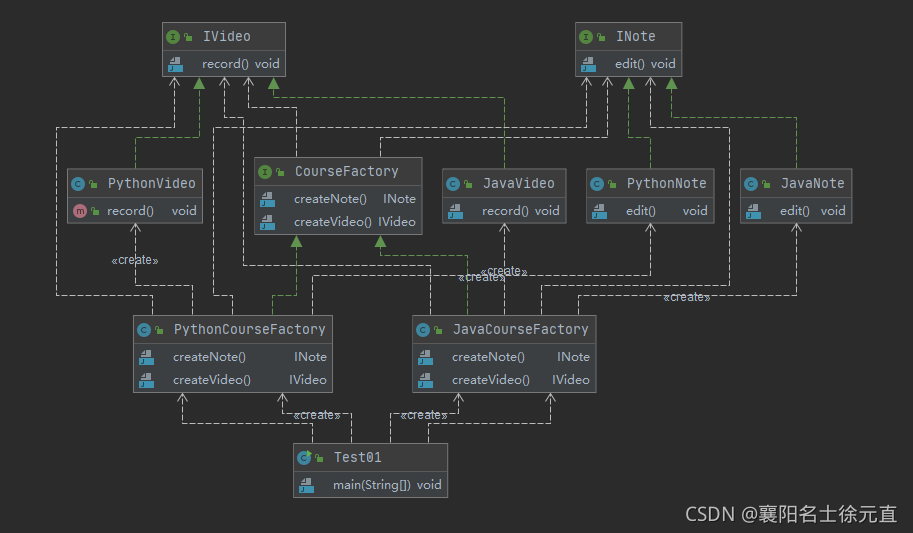
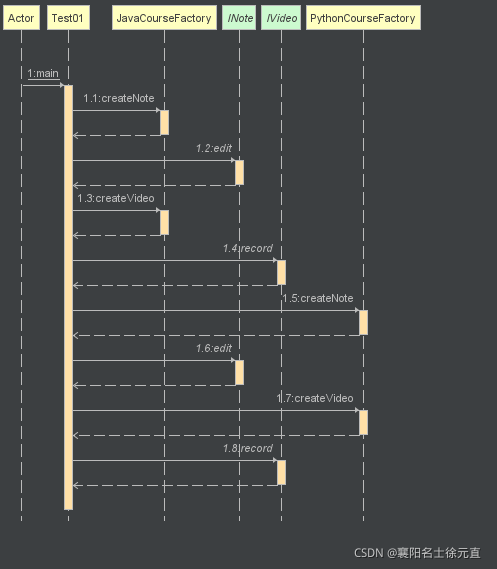
上面的代码完整地描述了两个产品族:Java 课程和 Python
课程,也描述了两个产品等级视频和笔记。抽象工厂模式非常完整清晰地描述了这一层复杂的关系。但是,如果我们要继续扩展产品等级,那么我们地代码从抽象工厂到具体工厂要全部调整,很明显不符合开闭原则。有次可知抽象工厂模式也是由缺点的:
- 规定了所有可能被创建地产品集合,产品族中扩展新的产品困难,需要修改抽象工厂的接口。
- 增加了系统的抽象性和理解难度。
2. 单例模式
单例(Singleton)模式的定义:指一个类只有一个实例,且该类能自行创建这个实例的一种模式。例如,Windows 中只能打开一个任务管理器,这样可以避免因打开多个任务管理器窗口而造成内存资源的浪费,或出现各个窗口显示内容的不一致等错误。
在计算机系统中,还有 Windows 的回收站、操作系统中的文件系统、多线程中的线程池、显卡的驱动程序对象、打印机的后台处理服务、应用程序的日志对象、数据库的连接池、网站的计数器、Web 应用的配置对象、应用程序中的对话框、系统中的缓存等常常被设计成单例。
单例模式在现实生活中的应用也非常广泛,例如公司 CEO、部门经理等都属于单例模型。J2EE 标准中的 ServletContext 和 ServletContextConfig、Spring 框架应用中的 ApplicationContext、数据库中的连接池等也都是单例模式。
单例模式有 3 个特点:
- 单例类只有一个实例对象;
- 该单例对象必须由单例类自行创建;
- 单例类对外提供一个访问该单例的全局访问点。
2.1 饿汉式
饿汉式单例模式在类加载的时候就立即初始化,并且创建单例对象。它绝对线程安全,在线程还没出现就实例化了,不可能存在访问安全问题。
优点:没有加任何锁,执行效率比较高,用户体验比懒汉式单例模式更好。
缺点:类加载的时候就初始化,不管用不用都占着空间,造成了内存的浪费。
spring 中 IOC 容器 ApplicationContext 本身就是典型的饿汉式单例模式。接下来看一段代码:
public class HungrySingleton {
private static final HungrySingleton singleton = new HungrySingleton();
// 构造方法私有化
private HungrySingleton(){
}
// 提供public的获取方法
public static HungrySingleton getInstance(){
return singleton;
}
}
还有一种方法利用静态代码块机制:
public class HungryStaticSingleton {
public static final HungryStaticSingleton singleton;
static {
singleton = new HungryStaticSingleton();
}
private HungryStaticSingleton() {
}
public static HungryStaticSingleton getInstance() {
return singleton;
}
}
2.2 懒汉式
懒汉单例模式的特点是:被外部类调用的时候内部类才会加载。下面看懒汉式单例模式的简单实现 LazySimpleSingleon:
public class LazySimpleSingleton {
private static LazySimpleSingleton lazySimpleSingleton = null;
private LazySimpleSingleton() {
}
public static LazySimpleSingleton getInstance() {
if (lazySimpleSingleton == null) {
lazySimpleSingleton = new LazySimpleSingleton();
}
return lazySimpleSingleton;
}
}
然后写一个线程类 ExectorThread:
public class ExectorThread implements Runnable {
@Override
public void run() {
LazySimpleSingleton instance = LazySimpleSingleton.getInstance();
System.out.println(Thread.currentThread().getName()+":"+instance);
}
}
客户端测试代码如下:
public class Test01 {
public static void main(String[] args) {
Thread t1 = new Thread(new ExectorThread());
Thread t2 = new Thread(new ExectorThread());
Thread t3 = new Thread(new ExectorThread());
t1.start();
t2.start();
t3.start();
System.out.println("End");
}
}
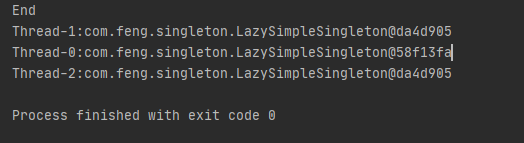
上面我们拿了不同的结果,这意味着上面的单例存在线程安全隐患。此时我们使用断点调试看一下,献给ExectorThread类打上断点,如下图所示:
使用鼠标右键切换为Thread模式,如下图所示:
然后给 LazySimpleSingleton 类打上断点,同样标记为Thread 模式,如下图所示:

切换为客户端测试代码,同样打上断点,同时改为 Thread 模式,如下图所示:
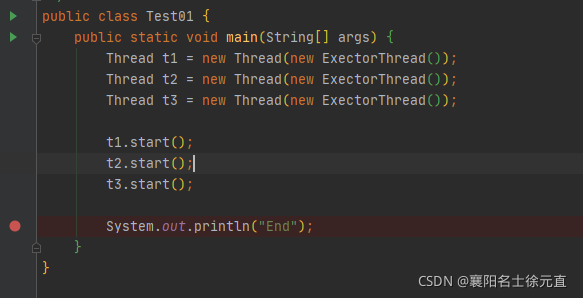
打开 Debug 后会看到 Debug 控制台可以自由切换 Thread 的运行状态,如下图所示:
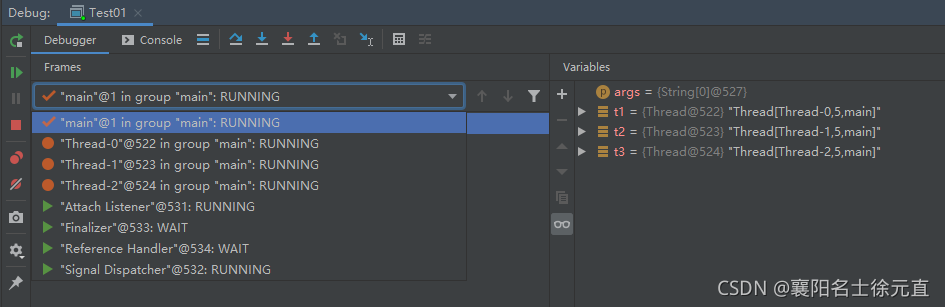
线程执行到这一步时切换线程:
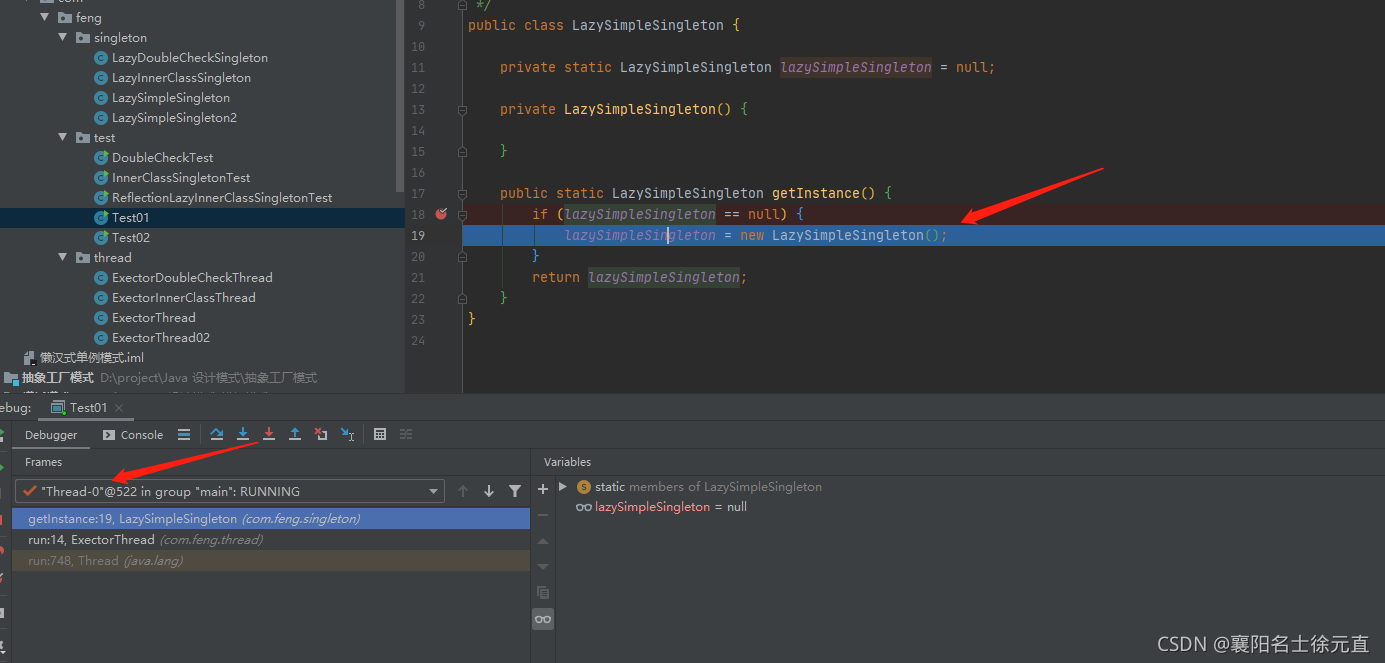
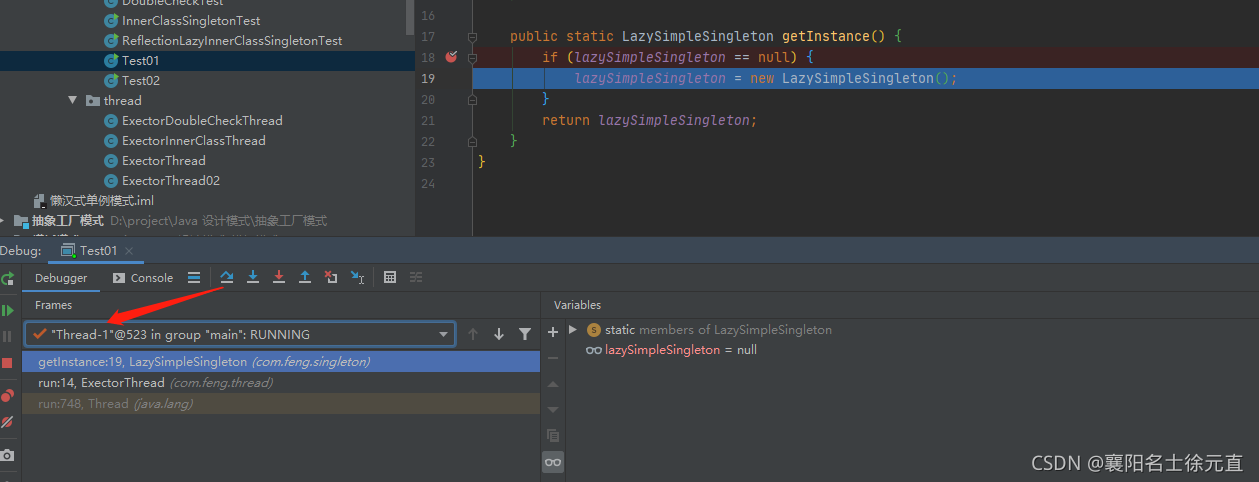
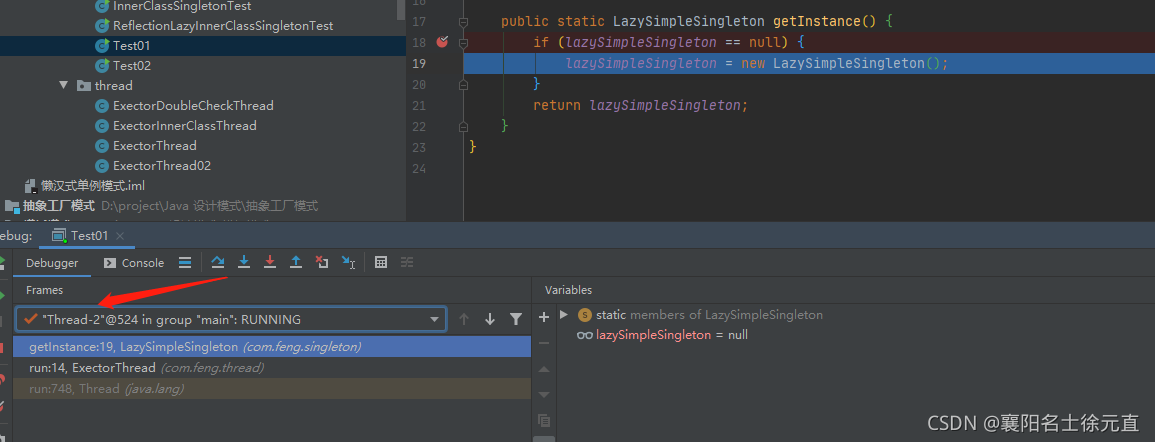
我们可以清楚的看见单例对象初始化了三次最后打印结果如下图所示:

这里的线程安全隐患依旧存在。那么我们该如何优化代码,使得懒汉式单例模式在线程环境下安全呢?我们可以在 getInstance() 加上 synchronized 关键字,是的这个方法变成线程同步方法:
public class LazySimpleSingleton2 {
private static LazySimpleSingleton2 lazySimpleSingleton2= null;
private LazySimpleSingleton2() {
}
// 增加同步锁
public synchronized static LazySimpleSingleton2 getInstance() {
if (lazySimpleSingleton2 == null) {
lazySimpleSingleton2 = new LazySimpleSingleton2();
}
return lazySimpleSingleton2;
}
}
我们继续按照线程调试调试一下,当执行其中一个线程并调用 getInstance() 方法时,另一个线程在调用 getInstance() 方法,线程的状态由 RUNNING 变为了 MONITOR,出现阻塞。直到第一个线程执行完,第二个线程才恢复到 RUNNING 状态继续调用 getInstance() 方法,如下图所示:
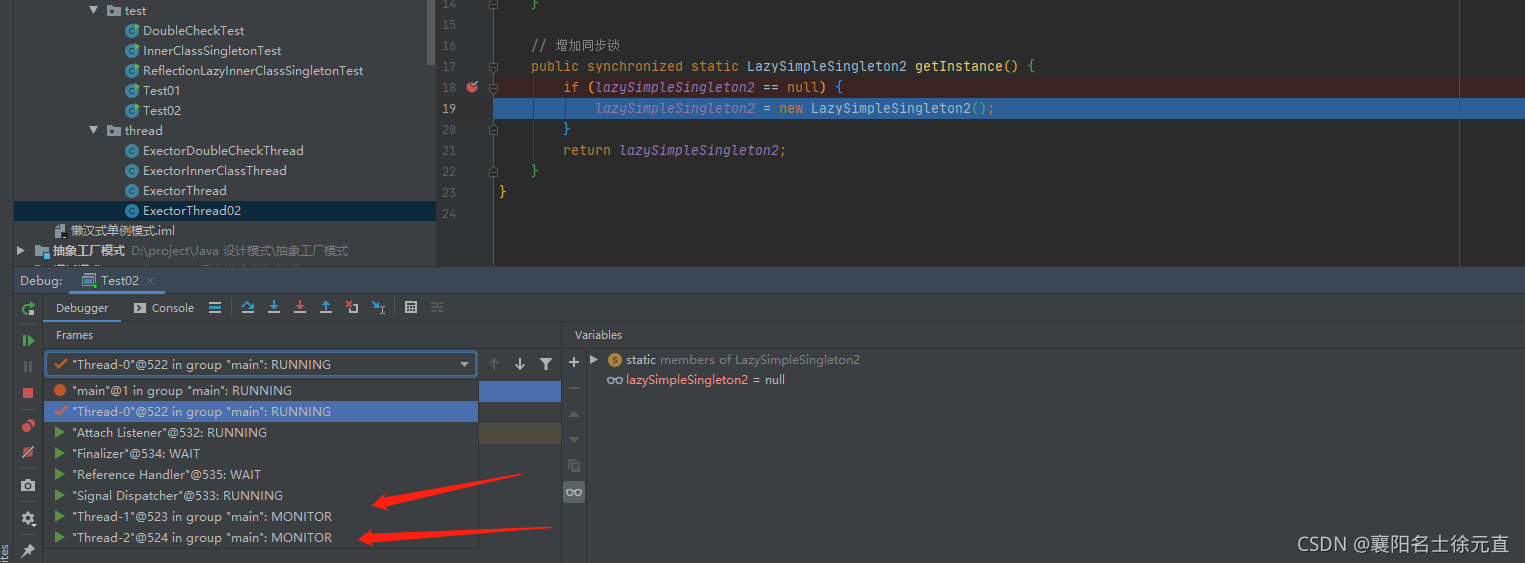
线程的安全问题解决了。但是,用 synchronized 加锁时,在线程数量比较多的情况下,如果 CPU 分配压力上升,则会导致大批线程阻塞,从而导致程序性能大幅下降。那么我们可以使用双重检查锁的单例模式:
public class LazyDoubleCheckSingleton {
private volatile static LazyDoubleCheckSingleton lazy = null;
private LazyDoubleCheckSingleton() {
}
public static LazyDoubleCheckSingleton getInstance(){
if (lazy==null){
synchronized (LazyDoubleCheckSingleton.class){
if (lazy==null){
lazy = new LazyDoubleCheckSingleton();
}
}
}
return lazy;
}
}
当第一个线程调用 getInstance() 方法时,第二个线程也可以调用。当地一个线程执行到 synchronized 时会上锁,第二个线程就会变为 MONITOR 状态出现阻塞,此时阻塞并不是基于整个LazySimpleSingleton 类的阻塞,而是在 getInstance() 方法内部的阻塞。
但是,用到 synchronized 关键字总归要上锁,对程序性能还是存在一定影响,我们可以从类的初始化的角度来考虑使用静态内部类的方式:
public class LazyInnerClassSingleton {
// 默认
private LazyInnerClassSingleton() {
}
public static final LazyInnerClassSingleton getInstance() {
// 在返回之前一定会先加载内部类
return LazyHolder.LAZY;
}
private static class LazyHolder {
// 只加载一次
private static final LazyInnerClassSingleton LAZY = new LazyInnerClassSingleton();
}
}
这种方式兼顾了饿汉式的内存浪费问题和 synchronized 的性能问题,内部类一定是在方法调用之前初始化,巧妙地避免了线程安全问题。
2.3 反射破坏单例
我们发现上面两个介绍地单例模式除了构造方法加上 private 关键字,没有做任何处理。我们如果使用反射来调用构造方法,在调用 getInstance() 方法,应该有两个不同地实例我们先编写测试类:
public class ReflectionLazyInnerClassSingletonTest {
public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
Class<?> clazz = LazyInnerClassSingleton.class;
Constructor<?> declaredConstructor = clazz.getDeclaredConstructor(null);
// 强制访问 private的构造方法也可访问
declaredConstructor.setAccessible(true);
Object o1 = declaredConstructor.newInstance();
Object o2 = declaredConstructor.newInstance();
// 可以通过构造方法创建两个对象 单例无效
System.out.println(o1);
System.out.println(o2);
}
}
结果如下图:
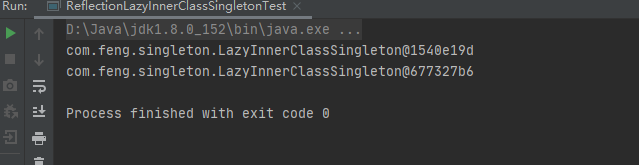
显然,创建了两个不同地实例,现在我们在其构造方法中做一些限制,一旦出现多个重复创建,则抛出异常:
public class LazyInnerClassSingleton {
// 默认
private LazyInnerClassSingleton() {
// 加了这个判断可有效解决 反射破环单例
if (LazyHolder.LAZY != null) {
throw new RuntimeException("不允许创建多个实例");
}
}
public static final LazyInnerClassSingleton getInstance() {
// 在返回之前一定会先加载内部类
return LazyHolder.LAZY;
}
private static class LazyHolder {
// 只加载一次
private static final LazyInnerClassSingleton LAZY = new LazyInnerClassSingleton();
}
}
在运行下测试结果如下:

3. 原型模式
原型(Prototype)模式的定义如下:用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型相同或相似的新对象。在这里,原型实例指定了要创建的对象的种类。用这种方式创建对象非常高效,根本无须知道对象创建的细节。例如,Windows 操作系统的安装通常较耗时,如果复制就快了很多。在生活中复制的例子非常多,这里不一一列举了。
原型模式的优点:
- Java 自带的原型模式基于内存二进制流的复制,在性能上比直接 new 一个对象更加优良。
- 可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份,并将其状态保存起来,简化了创建对象的过程,以便在需要的时候使用(例如恢复到历史某一状态),可辅助实现撤销操作。
原型模式的缺点:
- 需要为每一个类都配置一个 clone 方法 clone
- 方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违背了开闭原则。
- 当实现深克隆时,需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来会比较麻烦。因此,深克隆、浅克隆需要运用得当。
原型模式的克隆分为浅克隆和深克隆。
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
3.1 浅克隆
一个标准的浅克隆应该是这样设计的,先创建原型 Prototype 接口:
public interface Prototype {
Prototype clone();
}
创建具体的克隆类 ConcretePrototypeA:
public class ConcretePrototypeA implements Prototype {
private Integer age;
private String name;
private List hobbies;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List getHobbies() {
return hobbies;
}
public void setHobbies(List hobbies) {
this.hobbies = hobbies;
}
@Override
public ConcretePrototypeA clone() {
ConcretePrototypeA concretePrototypeA = new ConcretePrototypeA();
concretePrototypeA.setAge(this.age);
concretePrototypeA.setName(this.name);
concretePrototypeA.setHobbies(this.hobbies);
return concretePrototypeA;
}
}
创建 Client 类:
public class Client {
private Prototype prototype;
public Client(Prototype prototype) {
this.prototype = prototype;
}
public Prototype startClone(Prototype prototype){
return (Prototype) prototype.clone();
}
}
测试代码如下:
public class ShallowCloneTest {
public static void main(String[] args) {
ConcretePrototypeA concretePrototypeA = new ConcretePrototypeA();
concretePrototypeA.setAge(22);
concretePrototypeA.setName("wdf");
concretePrototypeA.setHobbies(new ArrayList());
System.out.println("concretePrototypeA = " + concretePrototypeA);
Client client = new Client(concretePrototypeA);
ConcretePrototypeA concretePrototypeClone = (ConcretePrototypeA)client.startClone(concretePrototypeA);
System.out.println("concretePrototypeClone = " + concretePrototypeClone);
List hobbies = concretePrototypeA.getHobbies();
List hobbiesClone = concretePrototypeClone.getHobbies();
System.out.println("hobbies = " + hobbies);
System.out.println("hobbiesClone = " + hobbiesClone);
hobbies.add("1");
// 对象中的引用类型地址值相同
// 浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。
System.out.println(hobbies);
System.out.println(hobbiesClone);
System.out.println(hobbies == hobbiesClone);
concretePrototypeA.setAge(23);
System.out.println(concretePrototypeA.getAge());
System.out.println(concretePrototypeClone.getAge());
}
}
运行结果如下:
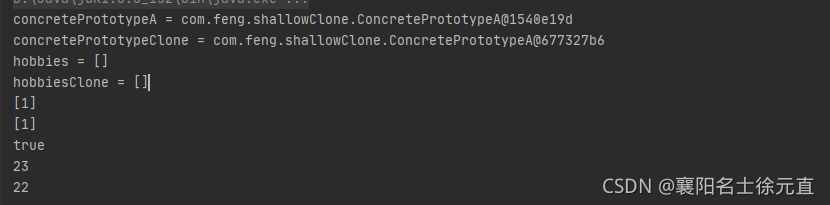
从测试结果可以看出,hobbies 的引用地址是相同的,意味着复制的不是值,而是引用地址。这样的话,如果我们修改任意一个对象的属性值,则 concretePrototype 和 concretePrototypeClone 的 hobbies 值都会改变,这就是我们常说的浅克隆。浅克隆只是完整复制了值类型数据,没有赋值引用对象。换言之,所有的引用对象仍然指向原来的对象。
3.2 深克隆
重写clone()方法使用序列化方法实现深克隆。其代码如下:
public class Employee implements Cloneable,Serializable{
private static final long serialVersionUID = 1L;
private String name;
private int age;
private String[] hobbies;
public Employee(String name, int age, String[] hobbies) {
this.name = name;
this.age = age;
this.hobbies = hobbies;
}
public static long getSerialVersionUID() {
return serialVersionUID;
}
public String[] getHobbies() {
return hobbies;
}
public void setHobbies(String[] hobbies) {
this.hobbies = hobbies;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append("姓名:"+name+",");
sb.append("年龄:"+age+"\n");
return sb.toString();
}
@Override
protected Employee clone() {
Employee employss = null;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try {
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
try {
ObjectInputStream ois = new ObjectInputStream(bais);
employss = (Employee) ois.readObject();
ois.close();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
return employss;
}
}
测试代码如下:
public class Test {
public static void main(String[] args) {
Employee employee = new Employee("wdf",22,new String[]{"敲代码"});
Employee employeeClone = employee.clone();
System.out.println(employee.getHobbies());
System.out.println(employeeClone.getHobbies());
}
}
运行结果如下:

我们可以发现属性中引用的其他对象也会被克隆,不再指向原有对象地址。
4. 代理模式
代理模式的定义:由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
代理模式的主要优点有:
- 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用;
- 代理对象可以扩展目标对象的功能;
- 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度,增加了程序的可扩展性
其主要缺点是:
- 代理模式会造成系统设计中类的数量增加 在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;
- 增加了系统的复杂度;
根据代理的创建时期,代理模式分为静态代理和动态代理。
静态:由程序员创建代理类或特定工具自动生成源代码再对其编译,在程序运行前代理类的 .class 文件就已经存在了。
动态:在程序运行时,运用反射机制动态创建而成
4.1 静态代理
举个例子,有些人到了适婚年龄,其父母就会迫不及待地抱孙子,于是父母就开始到处为自己地子女相亲下面来看代码实现:
顶层接口 Person 地代码如下:
public interface Person {
void findLove();
}
儿子要找对象,实现 Son 类:
public class Son implements Person {
@Override
public void findLove() {
System.out.println("儿子要求:肤白貌美");
}
}
父亲要帮儿子相亲,实现 Father 类:
public class Father {
private Son son;
public Father(Son son) {
this.son = son;
}
public Son getSon() {
return son;
}
public void setSon(Son son) {
this.son = son;
}
public void findLove(){
System.out.println("父亲帮忙物色");
son.findLove();
System.out.println("物色完毕");
}
}
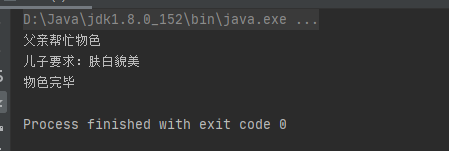
测试代码:
public class Test {
public static void main(String[] args) {
Father father = new Father(new Son());
father.findLove();
}
}
类图以及时序图如下
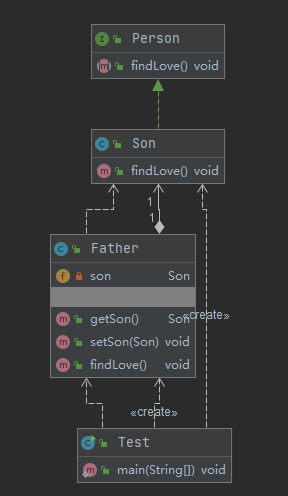
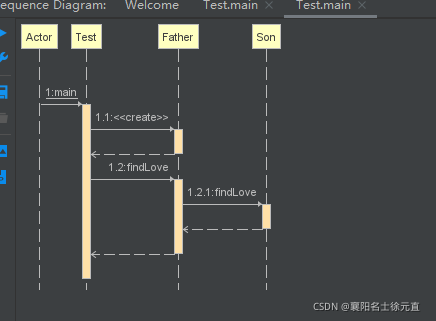
运行结果如下:
4.2 动态代理
动态代理和静态代理地基本思路是一致地,只不过动态代理功能更加强大,随着业务地扩展适应性更强,如果还以找对象为例,那么使用动态代理相当于能够适应复杂地业务场景。不仅包括父亲给儿子找对象,如果找对象这项业务发展成了一个产业,出现了媒婆、婚介所等,那么使用静态代理成本太高了。需要一个更加通用地解决方案。
创建媒婆类 JDKProxy:
public class JDKProxy implements InvocationHandler {
private Object target;
public Object getInstance(Object target){
this.target = target;
Class<?> clazz = target.getClass();
// 传入被代理对象的类加载器 和 方法 , 代理对象
return Proxy.newProxyInstance(clazz.getClassLoader(),clazz.getInterfaces(),this);
}
@Override
// 代理实现的逻辑 做了那些增强
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before();
Object o = method.invoke(this.target,args);
after();
return o;
}
private void before(){
System.out.println("媒婆帮你找对象");
System.out.println("开始物色");
}
private void after(){
System.out.println("物色结束");
}
}
创建单身客户类 Customer:
public class Customer implements Person {
@Override
public void findLove() {
System.out.println("小伙还是相亲");
}
}
测试代码如下:
public class Test {
public static void main(String[] args) {
Person instance = (Person) new JDKProxy().getInstance(new Customer());
instance.findLove();
}
}
运行结果如下:
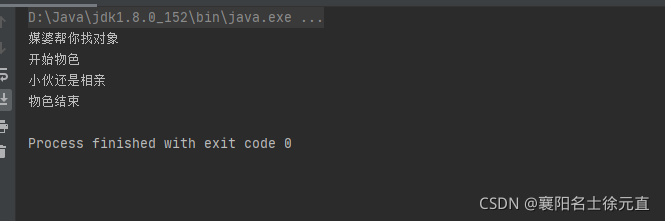
类图和时序图如下:
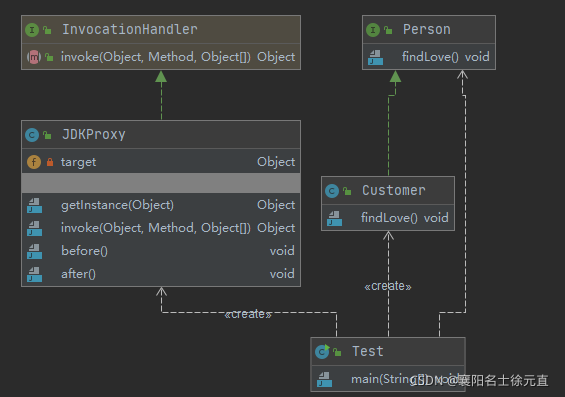
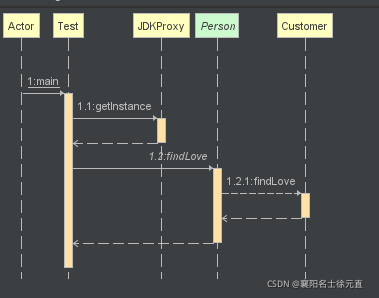
5. 委派模式
委派模式地基本作用就是负责任务地调用和分配,跟代理模式很像,可以看作一种特殊情况下地静态代理地全权代理,但是代理模式注重过程,委派模式注重结果。委派模式在 Spring 中应用的非常多,大家常用的 DispatcherServlet 就用到了委派模式。现实生活中也常有委派的场景发生,例如老板给项目经理下达任务,项目经理会根据实际情况给每个员工派发任务,代员工把任务完成后,再有项目经理向老板汇报结果。我们用代码实现一下这个业务场景,先看一下类图:
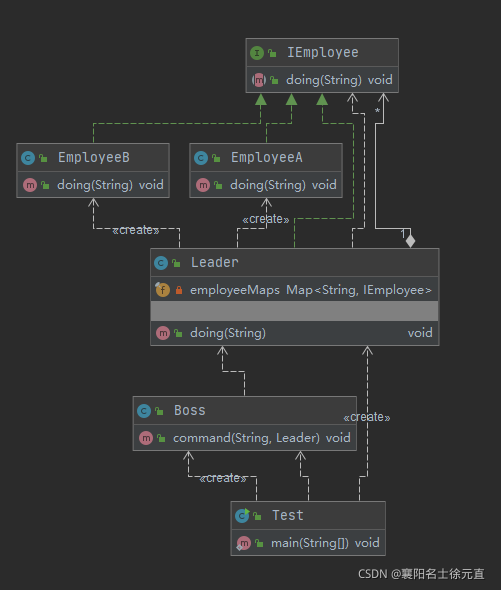
创建 IEmployee 员工接口:
public interface IEmployee {
void doing(String command);
}
创建员工类 EmployeeA和EmployeeB:
public class EmployeeA implements IEmployee {
@Override
public void doing(String command) {
System.out.println("我是员工A 现在开始 :"+command);
}
}
public class EmployeeB implements IEmployee {
@Override
public void doing(String command) {
System.out.println("我是员工B 现在开始 :"+command);
}
}
创建项目经理类 Leader:
public class Leader implements IEmployee {
private final Map<String, IEmployee> employeeMaps = new HashMap<>();
public Leader() {
employeeMaps.put("加密", new EmployeeA());
employeeMaps.put("登录", new EmployeeB());
}
@Override
public void doing(String command) {
IEmployee iEmployee = employeeMaps.get(command);
System.out.println("我是经理分发给" + iEmployee.getClass().getName());
employeeMaps.get(command).doing(command);
}
}
创建 Boss 类下达命令:
public class Boss {
public void command(String command, Leader leader){
leader.doing(command);
}
}
时序图如下: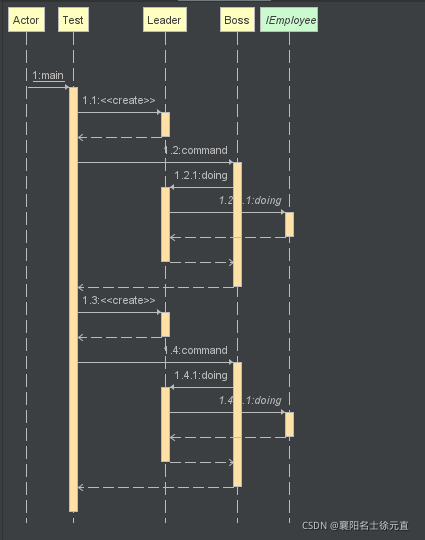
6. 策略模式
策略(Strategy)模式的定义:该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
策略模式的主要优点如下:
- 多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句,如 if…else
语句、switch…case 语句。- 策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
- 策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的。
- 策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
- 策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
其主要缺点如下:
- 客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。 策略模式造成很多的策略类,增加维护难度。
阿峰课堂经常有优惠活动,如优惠券抵扣、返现促销、拼团那么我们使用代码实现一下类图如下:
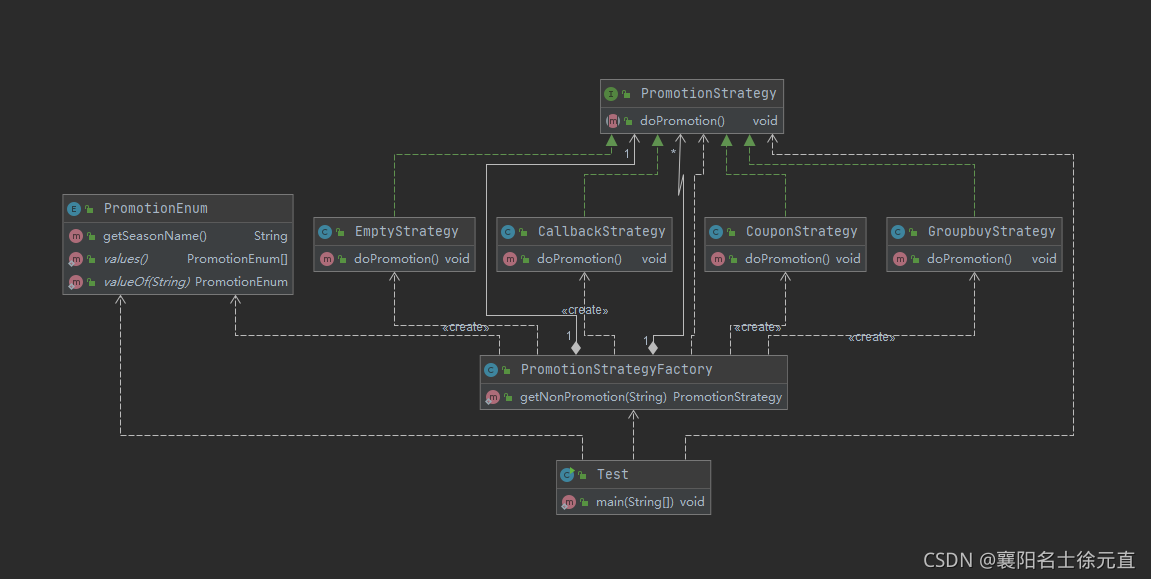
首先创建一个促销策略的接口 PromotionStrategy:
public interface PromotionStrategy {
void doPromotion();
}
然后分别创建优惠券策略类 CouponStrategy、返现促销策略类 CallbackStrategy、拼团策略类 GroupbuyStrategy和无优惠策略类 EmptyStrategy:
public class CallbackStrategy implements PromotionStrategy {
@Override
public void doPromotion() {
System.out.println("返现促销");
}
}
public class CouponStrategy implements PromotionStrategy {
@Override
public void doPromotion() {
System.out.println("优惠卷策略");
}
}
public class GroupbuyStrategy implements PromotionStrategy {
@Override
public void doPromotion() {
System.out.println("拼团促销");
}
}
public class EmptyStrategy implements PromotionStrategy {
@Override
public void doPromotion() {
System.out.println("无促销");
}
}
public interface PromotionStrategy {
void doPromotion();
}
创建枚举类 PromotionEnum:
public enum PromotionEnum {
//1.提供当前枚举类的对象,对各对象之间用","隔开,末尾对象";"结束
GOUPON("GOUPON"),
CALLBACK("CALLBACK"),
GROUPBUY("GROUPBUY");
// 2.声明Season对象的属性
private final String seasonName;
// 3.私有化类的构造器
PromotionEnum(String seasonName) {
this.seasonName = seasonName;
}
public String getSeasonName() {
return seasonName;
}
}
创建工厂类 PromotionStrategyFactory:
public class PromotionStrategyFactory {
private static final Map<String, PromotionStrategy> PROMOTION_STRATEGY_MAP = new HashMap<>();
static {
PROMOTION_STRATEGY_MAP.put(PromotionEnum.CALLBACK.getSeasonName(), new CallbackStrategy());
PROMOTION_STRATEGY_MAP.put(PromotionEnum.GOUPON.getSeasonName(), new CouponStrategy());
PROMOTION_STRATEGY_MAP.put(PromotionEnum.GROUPBUY.getSeasonName(), new GroupbuyStrategy());
}
private static final PromotionStrategy NON_PROMOTION = new EmptyStrategy();
private PromotionStrategyFactory() {
}
public static PromotionStrategy getNonPromotion(String key) {
PromotionStrategy promotionStrategy = PROMOTION_STRATEGY_MAP.get(key);
return promotionStrategy == null ? NON_PROMOTION : promotionStrategy;
}
}
创建客户端:
public class Test {
public static void main(String[] args) {
String key = PromotionEnum.GROUPBUY.getSeasonName();
PromotionStrategy nonPromotion = PromotionStrategyFactory.getNonPromotion(key);
nonPromotion.doPromotion();
}
}
时序图如下:

运行结果如下:
7. 模板模式
在面向对象程序设计过程中,程序员常常会遇到这种情况:设计一个系统时知道了算法所需的关键步骤,而且确定了这些步骤的执行顺序,但某些步骤的具体实现还未知,或者说某些步骤的实现与具体的环境相关。
例如,去银行办理业务一般要经过以下4个流程:取号、排队、办理具体业务、对银行工作人员进行评分等,其中取号、排队和对银行工作人员进行评分的业务对每个客户是一样的,可以在父类中实现,但是办理具体业务却因人而异,它可能是存款、取款或者转账等,可以延迟到子类中实现。
这样的例子在生活中还有很多,例如,一个人每天会起床、吃饭、做事、睡觉等,其中“做事”的内容每天可能不同。我们把这些规定了流程或格式的实例定义成模板,允许使用者根据自己的需求去更新它,例如,简历模板、论文模板、Word 中模板文件等。
模板方法(Template Method)模式的定义如下:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式。
该模式的主要优点如下:
- 它封装了不变部分,扩展可变部分。它把认为是不变部分的算法封装到父类中实现,而把可变部分算法由子类继承实现,便于子类继续扩展。
- 它在父类中提取了公共的部分代码,便于代码复用。 部分方法是由子类实现的,因此子类可以通过扩展方式增加相应的功能,符合开闭原则。
该模式的主要缺点如下:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象,间接地增加了系统实现的复杂度。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
- 由于继承关系自身的缺点,如果父类添加新的抽象方法,则所有子类都要改一遍。
以阿峰课堂的课程创建流程为例:发布预习资料->制作课件->在线直播-》提交课堂笔记-》提交源码->布置作业-》检查作业。类图如下:
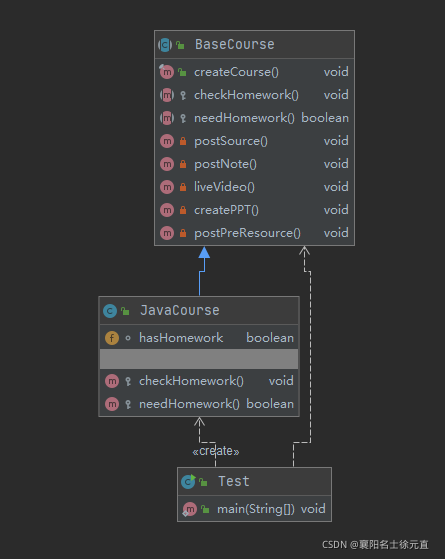
首先创建 NetworkCourse 抽象类:
public abstract class BaseCourse {
public final void createCourse() {
// 发布预习资料
postPreResource();
// 制作ppt
createPPT();
// 在线直播
liveVideo();
// 提交课堂笔记
postNote();
// 提交源码
postSource();
if (needHomework()) {
checkHomework();
}
}
// 检查作业
protected abstract void checkHomework();
// 钩子函数 是否有作业
protected abstract boolean needHomework();
private void postSource() {
System.out.println("提交源代码");
}
private void postNote() {
System.out.println("提交课件和笔记");
}
private void liveVideo() {
System.out.println("直播授课");
}
private void createPPT() {
System.out.println("创建备课PPT");
}
private void postPreResource() {
System.out.println("分发预习资料");
}
}
在上面的代码中有个钩子方法,设计钩子方法的主要目的是干预执行流程,使得控制行为更加灵活,更符合实际业务的需求。钩子方法的返回值一般为适合条件分支语句的返回值。我们可以根据自己的业务来决定是否使用钩子方法。接下来创建 JavaCourse 类:
public class JavaCourse extends BaseCourse {
boolean hasHomework;
public JavaCourse(boolean hasHomework) {
this.hasHomework = hasHomework;
}
@Override
protected void checkHomework() {
System.out.println("检查 java 作业");
}
@Override
protected boolean needHomework() {
return hasHomework;
}
}
创建 BigDataCourse 类:
public class BigDataCourse extends BaseCourse {
boolean hasHomework;
public BigDataCourse(boolean hasHomework) {
this.hasHomework = hasHomework;
}
@Override
protected void checkHomework() {
System.out.println("检查 大数据 作业");
}
@Override
protected boolean needHomework() {
return hasHomework;
}
}
客户端测试代码:
public class Test {
public static void main(String[] args) {
BaseCourse java = new JavaCourse(true);
java.createCourse();
System.out.println("-----------------");
BaseCourse bigData = new BigDataCourse(false);
bigData.createCourse();
}
}
运行结果如下:

8. 适配器模式
在现实生活中,经常出现两个对象因接口不兼容而不能在一起工作的实例,这时需要第三者进行适配。例如,讲中文的人同讲英文的人对话时需要一个翻译,用直流电的笔记本电脑接交流电源时需要一个电源适配器,用计算机访问照相机的 SD 内存卡时需要一个读卡器等。
在软件设计中也可能出现:需要开发的具有某种业务功能的组件在现有的组件库中已经存在,但它们与当前系统的接口规范不兼容,如果重新开发这些组件成本又很高,这时用适配器模式能很好地解决这些问题。
适配器模式(Adapter)的定义如下:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。适配器模式分为类结构型模式和对象结构型模式两种,前者类之间的耦合度比后者高,且要求程序员了解现有组件库中的相关组件的内部结构,所以应用相对较少些。
该模式的主要优点如下:
- 客户端通过适配器可以透明地调用目标接口。
- 复用了现存的类,程序员不需要修改原有代码而重用现有的适配者类。
- 将目标类和适配者类解耦,解决了目标类和适配者类接口不一致的问题。 在很多业务场景中符合开闭原则。
其缺点是:
- 适配器编写过程需要结合业务场景全面考虑,可能会增加系统的复杂性。
- 增加代码阅读难度,降低代码可读性,过多使用适配器会使系统代码变得凌乱。
现在大部分系统都已经支持多种登陆方式,如 QQ 登录、微信登录手机登录虽然登陆形式丰富了,但是登陆后台的处理逻辑可以不改我们可以用代码实现类图如下:
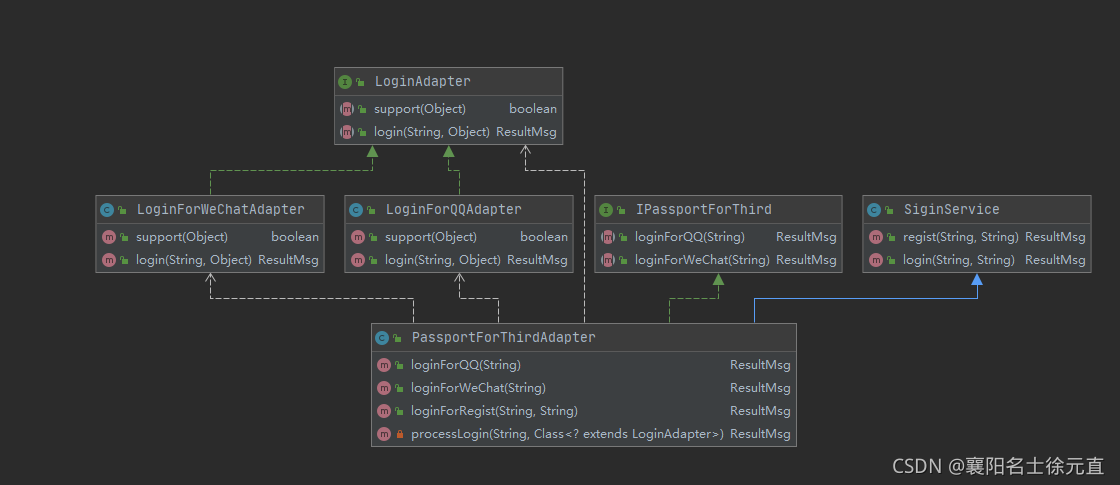
首先创建 LoginAdapter 接口:
public interface LoginAdapter {
boolean support(Object adapter);
ResultMsg login(String id,Object adapter);
}
然后分别实现不同的登陆方式QQ和微信登录:
public class LoginForQQAdapter implements LoginAdapter {
@Override
public boolean support(Object adapter) {
return adapter instanceof LoginForQQAdapter;
}
@Override
public ResultMsg login(String id, Object adapter) {
System.out.println("qq登录成功");
return null;
}
}
public class LoginForWeChatAdapter implements LoginAdapter {
@Override
public boolean support(Object adapter) {
return adapter instanceof LoginForWeChatAdapter;
}
@Override
public ResultMsg login(String id, Object adapter) {
System.out.println("微信登录");
return null;
}
}
创建第三方登录兼容接口 IPassportForThird:
public interface IPassportForThird {
ResultMsg loginForQQ(String id);
ResultMsg loginForWeChat(String id);
}
实现兼容 PassportForThirdAdapter:
public class PassportForThirdAdapter extends SiginService implements IPassportForThird {
@Override
public ResultMsg loginForQQ(String id) {
return processLogin(id, LoginForQQAdapter.class);
}
@Override
public ResultMsg loginForWeChat(String id) {
return processLogin(id, LoginForWeChatAdapter.class);
}
public ResultMsg loginForRegist(String username, String passport) {
super.regist(username, passport);
return super.login(username, passport);
}
private ResultMsg processLogin(String key, Class<? extends LoginAdapter> clazz) {
try {
LoginAdapter adapter = clazz.newInstance();
if (adapter.support(adapter)) {
return adapter.login(key, adapter);
} else {
return null;
}
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
}
客户端代码如下:
public class Test {
public static void main(String[] args) {
IPassportForThird passportForThirdAdapter = new PassportForThirdAdapter();
passportForThirdAdapter.loginForQQ("1111");
}
}
时序图如下:
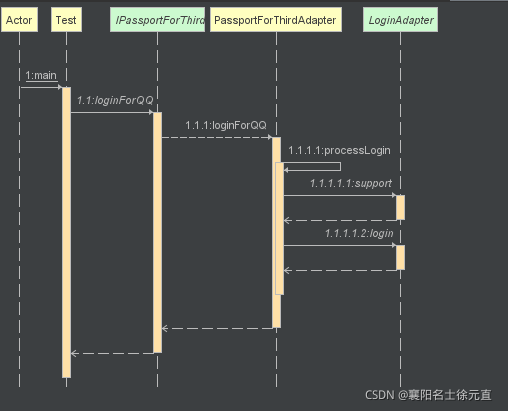
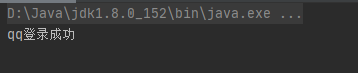
运行结果如下:
9. 装饰者模式
上班族大多都有睡懒觉的习惯,每天早上上班时间都很紧张,于是很多人为了多睡一会,就会用方便的方式解决早餐问题。有些人早餐可能会吃煎饼,煎饼中可以加鸡蛋,也可以加香肠,但是不管怎么“加码”,都还是一个煎饼。在现实生活中,常常需要对现有产品增加新的功能或美化其外观,如房子装修、相片加相框等,都是装饰器模式。
在软件开发过程中,有时想用一些现存的组件。这些组件可能只是完成了一些核心功能。但在不改变其结构的情况下,可以动态地扩展其功能。所有这些都可以釆用装饰器模式来实现。
装饰器(Decorator)模式的定义:指在不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式,它属于对象结构型模式。
装饰器模式的主要优点有:
- 装饰器是继承的有力补充,比继承灵活,在不改变原有对象的情况下,动态的给一个对象扩展功能,即插即用
- 通过使用不用装饰类及这些装饰类的排列组合,可以实现不同效果 装饰器模式完全遵守开闭原则
其主要缺点是:
- 装饰器模式会增加许多子类,过度使用会增加程序得复杂性。
下面我们用代码还原一下买煎饼的例子类图如下:
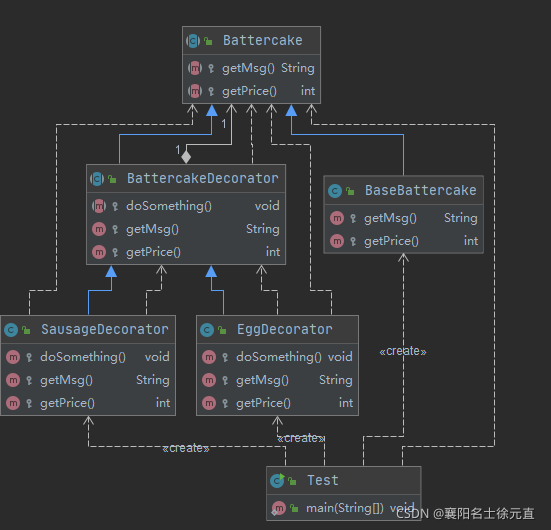
首先创建一个煎饼抽象类 Battercake:
public abstract class Battercake {
protected abstract String getMsg();
protected abstract int getPrice();
}
创建一个基础套餐 BaseBattercake:
public class BaseBattercake extends Battercake {
@Override
protected String getMsg() {
return "煎饼";
}
@Override
protected int getPrice() {
return 5;
}
}
在创建一个扩展的抽象装饰者 BattercakeDecorator:
public abstract class BattercakeDecorator extends Battercake {
private Battercake battercake;
public BattercakeDecorator(Battercake battercake) {
this.battercake = battercake;
}
protected abstract void doSomething();
@Override
protected String getMsg() {
return this.battercake.getMsg();
}
@Override
protected int getPrice() {
return this.battercake.getPrice();
}
}
接下来创建鸡蛋装饰者 EggDecorator:
public class EggDecorator extends BattercakeDecorator {
public EggDecorator(Battercake battercake) {
super(battercake);
}
@Override
protected void doSomething() {
}
@Override
protected String getMsg() {
return super.getMsg() + "+1个鸡蛋";
}
@Override
protected int getPrice() {
return super.getPrice() + 1;
}
}
最后创建香肠装饰者:
public class SausageDecorator extends BattercakeDecorator {
public SausageDecorator(Battercake battercake) {
super(battercake);
}
@Override
protected void doSomething() {
}
@Override
protected String getMsg() {
return super.getMsg() + "+1根香肠";
}
@Override
protected int getPrice() {
return super.getPrice() + 2;
}
}
客户端测试代码如下:
public class Test {
public static void main(String[] args) {
Battercake battercake;
// 点一个基础套餐
battercake = new BaseBattercake();
// 加一个鸡蛋
battercake = new EggDecorator(battercake);
// 在加一个鸡蛋
battercake = new EggDecorator(battercake);
// 再加一个香肠
battercake = new SausageDecorator(battercake);
System.out.println(battercake.getMsg() + ",总价:" + battercake.getPrice());
}
}
yu
10. 观察者模式
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pring中














 3238
3238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









