



 当Python在读取非UTF-8编码的文件时,可能会出现Unicode解码错误。该错误指出UTF-8编码器无法解码特定字节。解决方法是在打开文件时指定正确的编码。可以使用chardet库检测文件的编码,例如检测到的编码格式为UTF-8,然后在读取文件时传入'encoding=检测到的编码',从而避免解码错误。
当Python在读取非UTF-8编码的文件时,可能会出现Unicode解码错误。该错误指出UTF-8编码器无法解码特定字节。解决方法是在打开文件时指定正确的编码。可以使用chardet库检测文件的编码,例如检测到的编码格式为UTF-8,然后在读取文件时传入'encoding=检测到的编码',从而避免解码错误。
首先说明一下原因:
字符编码是一组特定的规则,用于从原始二进制字节字符串(101010101010)映射到构成人类可读文本的字符(如:fuck等)。有很多不同的技术用以编码二进制数据集,如果不知道写入数据时的原始编码技术,硬生生地将数据转换成文本,那么最终会得到乱码文本。
在python 3中处理文本时,将遇到两种主要的数据类型:一个是字符串,这是文本的默认类型:;另一个是字节数据类型,这是整数序列。大部分数据集可能使用UTF-8编码,这也是Python默认解译的编码技术,因此在大多数情况下不会遇到问题,但是有时会出现一下错误信息。
Unicode解码错误:UTF-8编码译码器无法解码位置11处的0x99字节:无效起始字节————
UnicodeDecodeError Trackback(most recent call last): ....
这种问题的出现是因为读取了非UTF-8编码的文件。要解决此错误,需要在读取文件时传入正确的编码格式。咱们可以使用chardet模块检查当前文件的编码方式。
import chardet
with open('F:/2号词云.txt','rb') as rawdata:
result = chardet.detect(rawdata.read(1000))
print(result)
结果为:
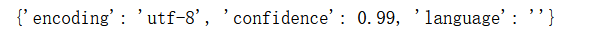
我这里的编码格式是utf-8,然后置信度(可相信程度)是99%。
然后大家可以在读取文件时,传入encoding=‘上面检测出来的编码格式’
,这样就不会在读文件时报错啦。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









