







 本文介绍了Python中jieba库的使用,包括如何安装jieba,理解cut函数返回的generator对象,以及cut_all和cut_for_search的区别。还展示了lcut函数如何返回列表形式的分词结果,并提到了jieba.add_word()方法用于添加自定义词汇到分词库。
本文介绍了Python中jieba库的使用,包括如何安装jieba,理解cut函数返回的generator对象,以及cut_all和cut_for_search的区别。还展示了lcut函数如何返回列表形式的分词结果,并提到了jieba.add_word()方法用于添加自定义词汇到分词库。
首先你得安装jieba
pip install jieba如果连pip都没有的话 请百度一下
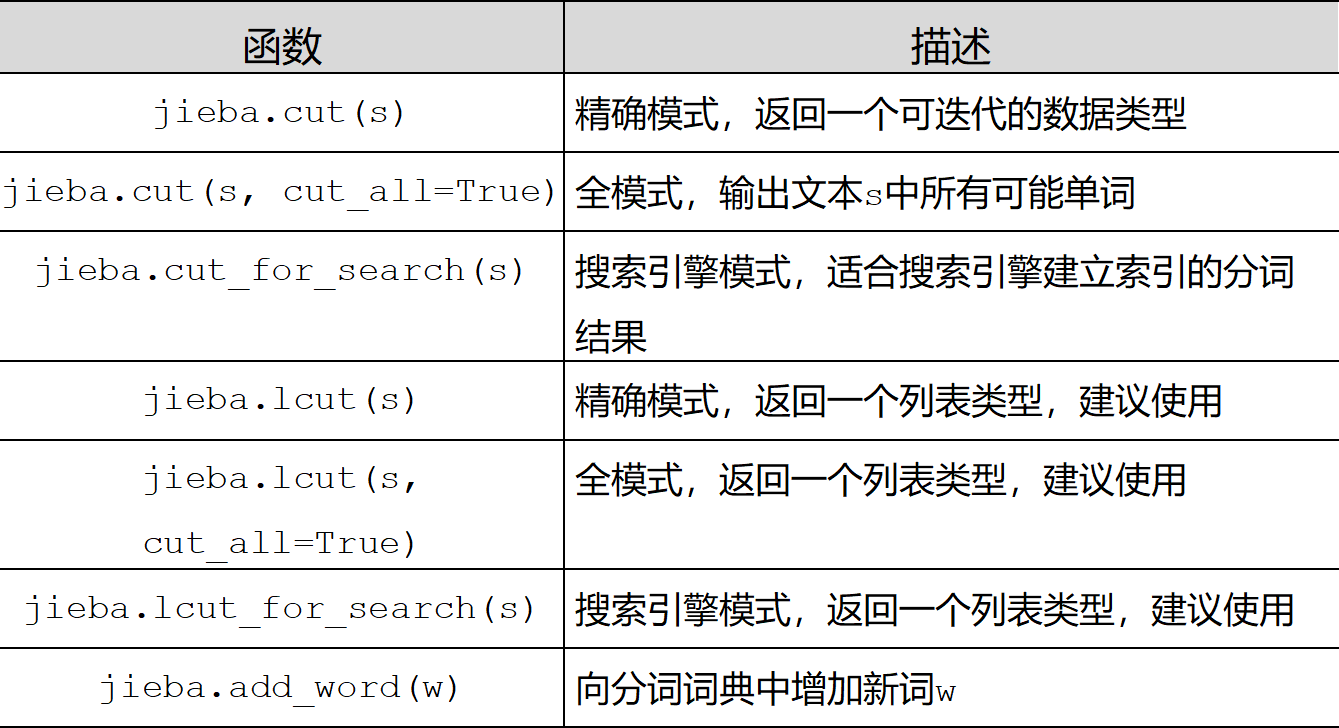
cut函数 返回是一个可迭代的generator对象
<generator object Tokenizer.cut at 0x108e6beb0>后面有个参数 cut_all = True,意思是 比如 万岁 他会把所有有可能组成的词汇都分隔出来
<generator object Tokenizer.cut at 0x10ef8fe40>jieba.cut_for_search() 用搜索引擎来分隔,也是返回的generator对象
然后lccut返回的就是一个列表模式了
s = "万岁!"
print(jieba.lcut(s))
['万岁', '!']
print(jieba.lcut(s,cut_all = True))
['万','岁','万岁', '!']
print(jieba.lcut_for_search(s))
['万岁', '!']
还有一个是jieba.add_word() 就是给本地分词库添加一个新词,比如 "就这" 这个词 可能jieba库不会识别为一个词语 你往里面添加 他以后就会识别了

















 4113
4113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









