







介绍
此项目是一个语料库课程作业,是基于逗号的汉语子句识别。我对100篇生语料进行词性标注,然后对语料按逗号、句号、问号进行切分;然后每个片段里面抽取前三个词、后三个词、标点后的第一个词以及它的词性共14个元素转为向量,作为模型特征。根据手工标注的语料的标注结果获得每个片段的标签,最后输入分类模型进行分类。
笔者由于时间、精力有限,文中所写代码有不少问题,比如:引用的特征数量较少,准确率只有百分之八十左右。或许此方法没有很好地学习到如何划分字句。这是笔者的第一篇博客,请多多包含。
说明:由于标注的语料仅供内部使用,这里仅提供源代码。
引用论文:
李艳翠,冯文贺,周国栋,朱坤华.基于逗号的汉语子句识别研究[J].北京大学学报(自然科学版),2013,49(01):7-14.
论文摘要:根据篇章分析的任务和实践, 结合传统研究, 提出汉语的基本篇章单位为子句, 并从结构、功能、形式等方面给出其定义。分析了逗号与子句的关系, 并在标注语料上进行了基于逗号的汉语子句识别研究。首先手工标注了CTB6.0中前100篇文档的逗号是否为子句边界的信息, 在标注结果中抽取句法、词汇、长度等特征进行实验, 子句识别准确率为90%。然后利用信息增益选出贡献最大的 9 个特征, 使用它们也可获得较高的子句识别准确率。最后仅使用词法信息, 子句识别准确率可达84.5%。实验证明子句的定义合理, 基于逗号的子句识别在理论上和实验上均可行。
首先,介绍一下子句(小句)和基本篇章单元的概念。
基本篇章单元(Elementary Discourse Units,EDU)是句子中具有独立语义和独立功能的最小单位,是进行篇章分析的基本单位。
一个子句,简单地理解,就是结构完整、表达完整意思的一个片段,包括简单句、从句等。具体划分可以看一下例子:
1、浦东 开发开放是一项振兴上海,建设现代化经济、贸易、金融中心的跨世纪工程,2、因此大量出现的是以前不曾遇到过的新情况、新问题。3、对此,浦东不是简单的采取“干一段时间,等积累了经验以后再制定法规条例”的做法,4、而是借鉴发达国家和深圳等特区的经验教训,5、聘请国内外有关专家学者,6、积极、及时地制定和推出法规性文件,7、使这些经济活动一出现就被纳入法制轨道。8、去年初浦东新区诞生的中国第一家医疗机构药品采购服务中心,正因为一开始就比较规范,9、运转至今,10、成交药品一亿多元,11、没有发现一例回扣。
比如,“对此,浦东不是简单的采取“干一段时间,等积累了经验以后再制定法规条例”的做法”,不是简单的按照逗号划分,是要按照句子具体表达的意思进行划分。所以,是否能找到一种机器学习的方法,通过对每个片段的词性、词内容、片段与片段之间的关系等内容的学习,获得自动切分小句的方法。
具体流程
说明:由于标注的语料仅供学生内部使用,这里仅提供代码。
- 数据预处理: ①特征提取,②特征构造,③标签的获取。
- 模型使用
数据预处理
①特征提取
对bracketed标注好的数据集的第一篇到第一百篇的.fid文件,提取出 ID=[0-9]+>(.*?)标签里的内容,并通过判断提取到正文内容。然后,通过逗号、句号、问号等标点(不包括顿号)来切分每篇文章的正文内容,划分成一个个片段,通过正则表达式提取到每个如(NN 贸易)这样的结构,从而提取到每个片段需要的前三个词、后三个词、逗号后的第一个词以及这7个词的词性。这些词以及词性作为本次实验的特征。
输入数据展示(经过处理后的token列表以及tag列表)

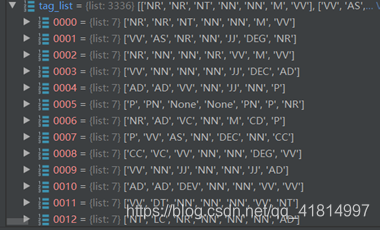
对Bracked文件夹下的内容(有对语料有稍许修改),先粗清洗语料,找到S ID = *> …的内容,然后按逗号和句号划分片段,并按这样的格式(NN 利益)爬取每个词以及它词性,最后经过稍微的处理,就能得到如图一、图二所示,经处理过后的token、tag列表。
def get_tag_token():
tag_list = []
tag_tmp_list = []
token_tmp_list = []
token_list = []
corpus = []
for i in range(1,101):
tag_tmp_list = []
token_tmp_list = []
filename = 'Cutting/bracketed/chtb_0'+str(i).rjust(3,'0')+'.fid'
file = open(filename,'r',encoding="GBK")
raws = file.read()
file.close()
res_SID = r'<S ID=[0-9]+>(.*?)</S>'
#粗清洗语料,找到<S ID = *> ...</S>的内容
S = re.findall(res_SID,raws,re.S|re.M)
content = []
n = 0
for raw in S:
if n>1:
content.append(raw)
n = n+1
p_cut_sen = r'(PU ,)|(PU 。)|(PU ;)|(PU :)|(PU ?)|(PU !)'
#按逗号和句号划分内容
contents = re.split(p_cut_sen,str(content))
p_cut_word = r'([A-Z]+ [\u4e00-\u9fa5]+)'
solved_content = []
for line in contents:
word_list = re.findall(p_cut_word,str(line),re.S|re.M) #每行直接定位到词性标注的内容,如(NN 利益)
if word_list:
if word_list[0] != 'VV 完':
sentence = ','.join(word_list)
solved_content.append(sentence)
#此步后的solved_content已经切分好了
corpus_doc = ''
n = 0
for sentence in solved_content:
words = sentence.split(',') #一个word里面结构是 VV 完 这样
for word in words:
if corpus_doc == '':
corpus_doc = corpus_doc + word.split()[1]
else:
corpus_doc = corpus_doc + ' ' + word.split()[1]
# 添加标点后的第一个词
if n == 0:
n = 1
else:
n = n + 1
tag_tmp_list.append(words[0].split()[0])
token_tmp_list.append(words[0].split()[1])
tmp = " ".join(word for word in tag_tmp_list)
tag_list.append(tmp)
tmp = " ".join(word for word in token_tmp_list)
token_list.append(tmp)
tag_tmp_list = []
token_tmp_list = []
if len(words)<3: #当每行的词项大于等于3时,
while(len(words) != 3): #当一个sentence里少于3个word时,补全到3个
words.append('None None')
# 前三个单词 后三个单词(注意要倒序)
need_words = words[0:3] + words[::-1][:3]
for x in need_words:
tag_tmp_list.append(x.split()[0])
token_tmp_list.append(x.split()[1])
if n == len(solved_content):
tmp = " ".join(word for word in tag_tmp_list)
tmp = tmp + ' None'
tag_list.append(tmp)
tmp = " ".join(word for word in token_tmp_list)
tmp = tmp + ' None'
token_list.append(tmp)
corpus.append(corpus_doc)
for i in range(len(token_list)):
tag_list[i] = tag_list[i].split(" ")
return tag_list,token_list,corpus
②特征构造
在《基于逗号的汉语子句识别研究》论文中,共有13类特征,我选取了前两类特征。第一类特征是F1_P_N、F1_W_N、F2_P_N、F2_W_N,从逗号到前一逗号或句首的范围内前面N个词的词性及词, 后面N个词的词性及词(本文N 取3)。第二类特征是F3、F4,逗号之后第一个词的词性和词。对于这些特征的词,我采用tf-idf算法,将这些词转化为词向量;对这些特征里面词性部分,我采用one-hot算法进行编码,再将词向量以及词性向量进行水平位置上的concatenate,获得本次的实验的输入数据。
将token列表转换成tf-idf向量,将tag列表转换成one-hot编码向量,然后再将两个向量进行水平位置上的融合,就得到了输入数据。
def get_data(token_list,tag_list):
tf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", max_df=0.6)
tf_token = tf.f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









