






连接介绍
- 为了更加方便的介绍一下连接,我们先创建两个表格 t1 和 t2
CREATE TABLE t1 (m1 int, n1 char(1));
CREATE TABLE t2 (m2 int, n2 char(1));
INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
- 连接的本质是将各个需要连接的表中的记录拿出来,再根据某一个规则进行匹配组合加入结果集并返回
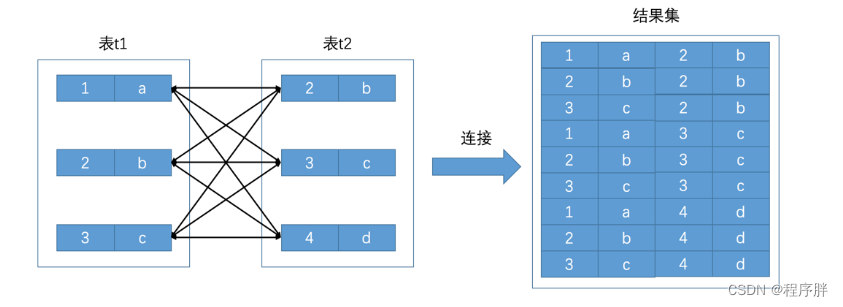
- 连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就可以称之为笛卡尔积。因为表t1中有3条记录,表t2中也有3条记录,所以这两个表连接之后的笛卡尔积就有3×3=9行记录。
- 我们可以连接很多个表,但是这样的话连接以后的数据量就会很大,查询的时候也会很消耗性能,所以在连接时候也需要加上一些查询条件,而过滤查询条件的形式可以分为两种:
- 涉及单表的条件
- 设计多表的条件
- 举个例子:
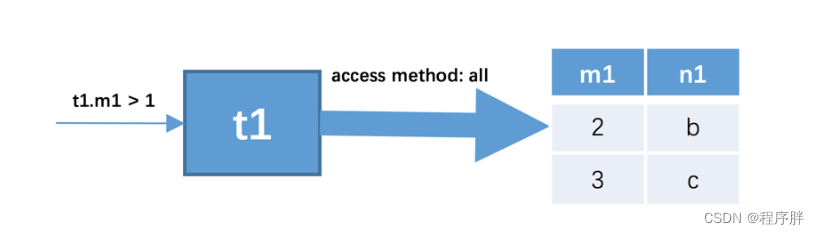
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd'; - 查询过程:
-
确定第一个需要查询的表,这个表称之为驱动表。
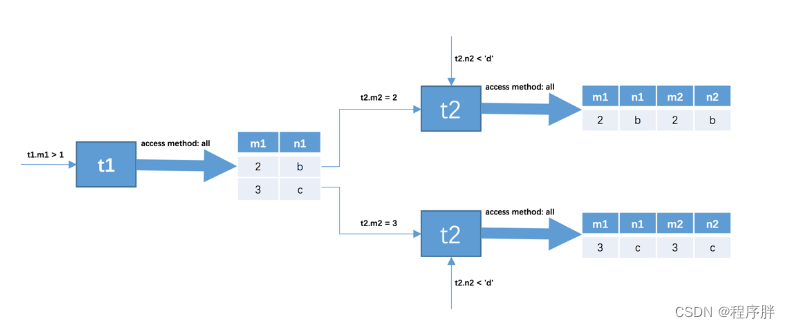
-
针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到t2表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。
-
- 举个例子:
连接原理
- 上面只是介绍连接,这里我们就需要了解一下连接的一些原理,了解为什么有些连接查询很快,有些会很慢?
- 我们需要了解一个概念,就是嵌套循环连接算法,将这个概念之前,先说一个上面的例子:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd'- 对于两表 t1 和 t2 连接的话,第一个需要查询的表,这个表称之为驱动表,而后面那个需要匹配的表就称之为被驱动表。
- t1 和 t2 的连接过程:
- 选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
- 了解完这个连接过程之后,我们想想,如果有第三个表的话,怎么办?答案是把前面两张表的结果集当作驱动表,第三张表当作被驱动表,重复上面的操作,这种过程像是一个嵌套的循环
- 所以我们把这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接
使用索引加快连接速度
- 了解完嵌套循环连接之后,我们需要思考,怎么样才能使得连接加快?
- 回答这个问题的时候我们还是要回到上面那个例子:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd' - 再来看一下过程:
- 从t1 查询到两条记录 2 b 和 3 c
- 嵌套循环连接需要根据这两条记录,去t2 里面查询两次
- 当t1.m1 = 2时,去查询一遍t2表,
SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < 'd'; - 当t1.m1 = 3时,再去查询一遍t2表,
SELECT * FROM t2 WHERE t2.m2 = 3 AND t2.n2 < 'd';
- 当t1.m1 = 2时,去查询一遍t2表,
- 看到这个过程有没有什么想法,是不是再查找t2表的时候可以通过索引去查找,也就是说我们可以通过索引去加快 t2 表的查找
- 方案如下:
- 方案一:在m2列上建立索引,因为对m2列的条件是等值查找
- 方案二:在n2列上建立索引,涉及到的条件是t2.n2 < ‘d’,可能用到range的访问方法,假设使用range的访问方法对t2表的查询的话,需要回表之后再判断在m2列上的条件是否成立。
- 如果 m2 和 n2都有索引的话,会择优一个消耗小的查询,并且只有在二级索引 + 回表的代价比全表扫描的代价更低时才会使用索引
基于块的嵌套循环连接
- 除了索引之外我们可以想想一些有关硬件方面的优化
- 讲个场景,上面的例子 t1 和 t2 只有3条,但是正常工作中肯定不止3条,成千上万条,并且我们做匹配的时候,都是把数据加载到内存中,所以在扫描表前面记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前面的记录从内存中释放掉。采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
- 为了解决这个问题,我们最好的方法是我们一次性把被驱动表和多条驱动表的数据匹配好然后再拉出来。
- 为了实现这个方法,mysql的设计提出了一个join buffer的概念,join buffer 顾名思义 连接缓存,执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。
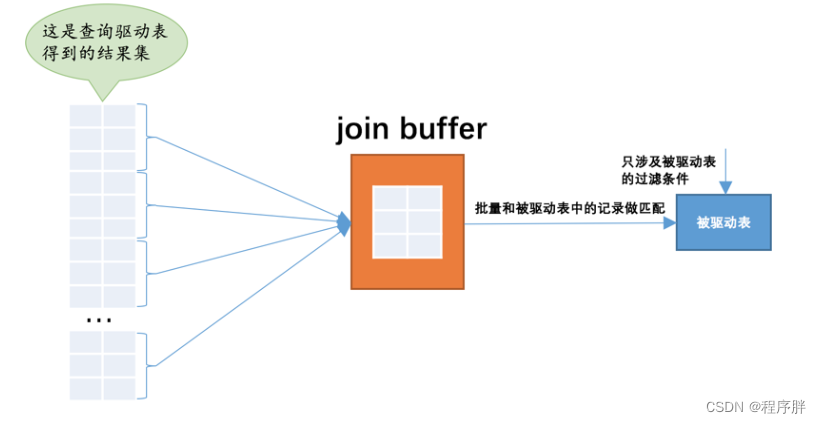
- 这个join buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节
总结
- 连接的实现是通过嵌套循环连接算法
- 嵌套循环连接算法的实现方式是:对于连接操作中的两个表,先将其中一个表作为外层循环,另一个表作为内层循环,依次遍历外层表和内层表的所有行,将符合连接条件的行组合起来。具体来说,对于每一行在外层表中找到对应的行,在内层表中找到符合连接条件的行,然后将两行合并成一行作为查询结果。由于需要对每行进行遍历,因此嵌套循环连接算法的时间复杂度为 O(mn),其中 m 和 n 分别为两个表的行数。
- 优化连接查询:
- 使用索引
- 使用子查询:使用子查询可以将外连接拆分为两个单独的查询,这可以减少查询中的数据量,从而提高查询性能。例如,可以首先从一个表中选择所需的记录,然后再与另一个表进行连接。
- 增加硬件资源:增加 MySQL 服务器的硬件资源,例如 CPU、内存和磁盘空间,可以提高查询性能。如果查询负载很高,可以使用主从复制和分区技术来分散查询负载。















 2442
2442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









