






1. 什么是CAP?
在分布式数据系统中,CAP原理中,有三个要素:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容忍性(Partition tolerance)
CAP原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可,考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障“用户感知到的一致性”。通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,“用户感知到的一致性”的时间窗口则取决于数据复制到一致状态的时间。
2. 什么是一致性?
在分布式系统中,一致性(Consistency)是指多副本(Replications)问题中的数据一致性。
数据一致性,往往指的是缓存和数据库的一致性。
事务的一致性(事务一致性指ACID),和原子性类似,都是从一个状态变到另一个状态,但不同的是,原子性追求这个过程不能出错,不论结果对不对,不能出错。但一致性更追求结果一致,比如A减少100,B增加100,这是一致的。当A减少100,B增加60,这是原子的,但不是一致的。
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
一致性出现的原因:数据的分布式存储是导致出现一致性的唯一原因
3. 数据一致性的种类
3.1 强一致性
强一致性(线性一致性):即复制是同步的。(同步就是保证两边是一致完成的)
强一致性两个要求:
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。
简言之,在任意时刻,所有节点中的数据是一样的。
3.2 弱一致性
弱一致性:即复制是异步的 (异步是前一方完成后,另一方再完成 且另一方如果不能完成的话不影响前一方)
数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
最终一致性(eventually consistent)就属于弱一致性。
3.3 强一致性和弱一致性举例
例如,对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性
用户更新网站头像,在某个时间点,用户向主库发送更新请求,不久之后主库就收到了请求。在某个时刻,主库又会将数据变更转发给自己的从库。最后,主库通知用户更新成功。
如果在返回“更新成功”并使新头像对其他用户可见之前,主库需要等待从库的确认,确保从库已经收到写入操作,那么复制是同步的,即强一致性。如果主库写入成功后,不等待从库的响应,直接返回“更新成功”,则复制是异步的,即弱一致性。
强一致性可以保证从库有与主库一致的数据。如果主库突然宕机,我们仍可以保证数据完整。但如果从库宕机或网络阻塞,主库就无法完成写入操作。
在实践中,我们通常使一个从库是同步的,而其他的则是异步的。如果这个同步的从库出现问题,则使另一个异步从库同步。这可以确保永远有两个节点拥有完整数据:主库和同步从库。 这种配置称为半同步。
3.4 顺序一致性
两个要求:
- 任何一次读都能读到某个数据的最近一次写的数据。(和强一致性一样)
- 系统的所有进程的顺序一致,而且是合理的。即不需要和全局时钟下的顺序一致,错的话一起错,对的话一起对。(强一致性的要求比顺序一致性更严格)
顺序一致性最早是用来描述多核 CPU 的行为的,定义如下:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
任何执行的结果都是相同的,就像所有处理器的操作都是按某种顺序执行的,每个处理器的操作都是按其程序指定的顺序出现在这个序列中。
如果可以找到一个所有 CPU 执行指令的排序,该排序中每个 CPU 要执行指令的顺序得以保持,且实际的 CPU 执行结果与该指令排序的执行结果一致,则称该次执行达到了顺序一致性。例如:
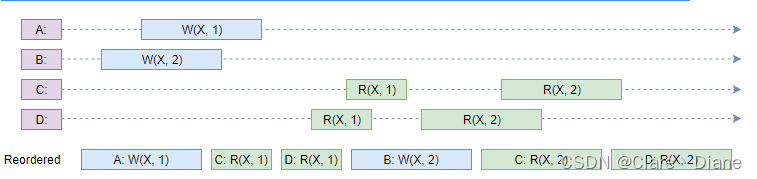
图中 W(X, 1) 代表将 1 写入变量 X;R(X, 1) 代表读取变量 X,值为 1;横轴代表时间;矩形的长短代表指令持续的时间长短,所以上图其实表示的是多核 CPU 的一次执行结果。
我们找到了指令的一个排序,排序中各个 CPU 的指令顺序得以保持(如 C: R(X, 1) 在 C: R(X, 2) 之前),这个排序的执行结果与 CPU 分开执行的结果一致,因此该 CPU 的执行是满足顺序一致性的。
注意到顺序一致性关心的是 CPU 内部执行指令的顺序,而不关心 CPU 之间的相对顺序。
更多正反例
考虑将上图的 C:R(X, 1) 与 D:R(X, 2) 替换一下呢?如下图:
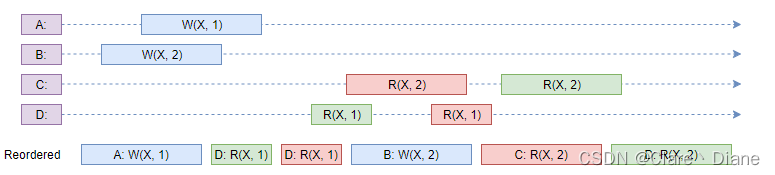
可以看到我们依然可以找到一个满足要求的全局排序,所以系统依旧满足顺序一致性。那如果我们只是将原图的 D:R(X, 1) 和 D:R(X, 2) 互换呢?如下图:

对于上图的系统,实际上是找不到一个全局的排序来满足顺序一致性的需求的。根本上,从 C 的顺序推导出 X 的写入顺序为 1 ->2,而同时由 D 推出写入顺序为 2->1 ,二者矛盾。那如果只有 A 在写入呢?

上图也不满足顺序一致性,由 C、D 推导出写入顺序为 1->2,而由 A 推出顺序为 2->1,矛盾。
顺序一致性难吗?
难,现代的多核 CPU 依然达不到顺序一致性。
我们知道 CPU 执行的主要瓶颈其实是在与内存交互,工程师为了让 CPU 能高速执行,在 CPU 内部使用了多级缓存。它的存在,使得即使 CPU 内部顺序执行指令,指令的结果也可能不满足顺序一致性:
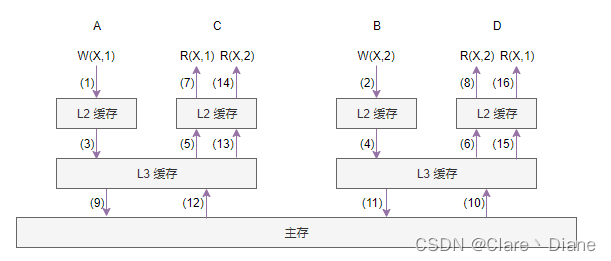
上图中 (n) 代表数据的读写步骤。如果 CPU 如上图执行,则得到的结果不满足顺序一致性。
另外 CPU 执行时会乱序执行指令。例如在一些情况下 CPU 会将数据写入的指令提前执行,因为写入内存是很耗时的。同样的,编译器在编译代码时也会重排代码中的指令的顺序,以提升整体的性能。
难以想象,没有了顺序一致性的保证,程序居然还能正确执行。其实,现代硬件体系遵循的其实是:
sequential consistency for data race free programs
无数据竞争程序的顺序一致性
即如果程序没有数据竞争,则 CPU 可以保证顺序一致性,而如果遇到数据竞争,就需要程序里手工使用一些数据同步的机制(如锁)。
工程领域总是伴随着各种权衡(trade-off),显然保证顺序一致性对 CPU 的性能优化有太多的阻碍,而 CPU 的高性能又是我们所追求的,两害相权取其轻。
Zookeeper 中的顺序一致性
Zookeeper 的一致性保证第一条是:
Sequential Consistency : Updates from a client will be applied in the order that they were sent.
顺序一致性:来自客户端的更新将按发送顺序应用。
顺序一致性:客户端发送的更新命令,服务端会按它们发送的顺序执行。 (其实 zookeeper 文档里描述的顺序一致性和本文描述的不太一样)
Zookeeper 的所有写操作都通过主节点进行,从节点复制修改操作,这样所有节点的更新顺序都和主节点相同,不会出现某个节点的更新顺序与其它节点不同的情况。
但是Zookeeper 允许客户端从从节点读取数据,因此如果客户端在读取过程中连接了不同的节点,则顺序一致性就得不到保证了。
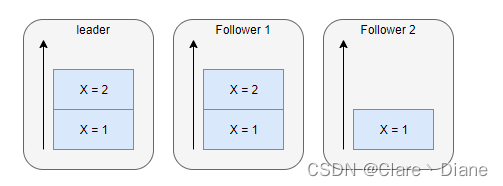
如上图,主节点的 X=2 消息还没有同步到 Follower 2,此时如果有两个客户端:
- A: 先后连接到 Follower 1 和 Follower 2,则读到 X 的值为
2 -> 1 - B: 先后连接到 Follower 2 和 Follower 1,则读到 X 的值为
1 -> 2
显然不满足顺序一致性,因此 zookeeper 又有“单一视图”的保证,保证在连接到 Follower 2 后,不会连上状态更老的 Follower 1。
3.5 最终一致性
不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
最终两个字用得很微妙,因为从写入主库到反映至从库之间的延迟,可能仅仅是几分之一秒,也可能是几个小时。
- 简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
最终一致性的种类
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
1. “读己之所写(read-your-writes)”一致性。当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
2. 会话(Session)一致性。这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
3. 单调(Monotonic)读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
4. 单调写一致性。系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









