






研一下学期,学习了孟宁老师的《高级软件工程》课程。对软件工程有了一个系统,深刻的认识。老师在上课时,诙谐幽默,深入浅出,实践与理论相结合,使我在学习的时候事半功倍。
为方便以后快速回忆,现对一些重点内容做个总结。
1. 码农的自我修养之必备技能
这章讲了身为一个程序员,必须要掌握的一些技能:Typing、VScode、git、vim、正则表达式。
1.1 Git

Git 本地版本库的基本用法
-
git init # 初始化一个本地版本库
-
git status # 查看当前工作区(workspace)的状态
-
git add [FILES] # 把文件添加到暂存区(Index)
-
git commit m “wrote a commit log infro” # 把暂存区里的文件提交到仓库
-
git log # 查看当前HEAD之前的提交记录,便于回到过去
-
git reset —hard HEAD^^/HEAD~100/commit-id/commit-id的头几个字符 # 回退
-
git reflog # 可以查看当前HEAD之后的提交记录,便于回到未来
-
git reset —hard commitid/commitid的头几个字符 # 回退
Git 远程版本库的基本用法
-
git clone命令官方的解释是“Clone a repository into a new directory”,即克隆一个存储库到一 个新的目录下。
-
git fetch命令官方的解释是“Download objects and refs from another repository”,即下载一个 远程存储库数据对象等信息到本地存储库。
-
git push命令官方的解释是“Update remote refs along with associated objects”,即将本地存储 库的相关数据对象更新到远程存储库。
-
git merge命令官方的解释是“Join two or more development histories together”,即合并两个 或多个开发历史记录。
-
git pull命令官方的解释是“Fetch from and integrate with another repository or a local branch”,即从其他存储库或分支抓取并合并到当前存储库的当前分支。
团队项目中的分叉合并
建议团队项目的每一个开发者都采用的工作流程大致如下:
- 1 克隆或同步最新的代码到本地存储库;
- 2 为自己的工作创建一个分支,该分支应该只负责单一功能模块或代码模块的版本控制;
- 3 在该分支上完成某单一功能模块或代码模块的开发工作;
- 4 最后,将该分支合并到主分支。
合并方法
默认的合并方式为"快进式合并"(fast-farward merge),会将分支里commit合并到主分支里,合并成一条时间线,与我们期望的呈现为一段独立的分支线段不符,因此合并时需要使用--no-ff参数关闭"快进式合并"(fast-farward merge)。
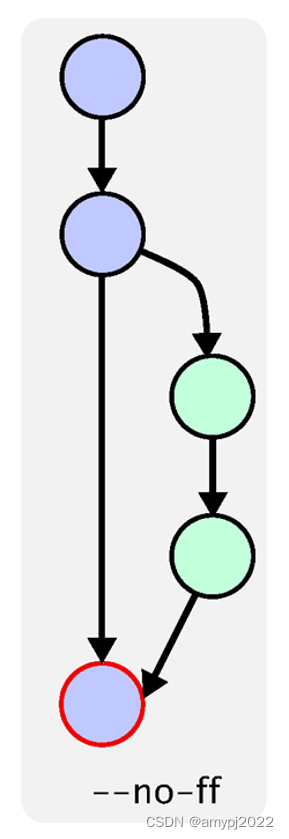

一、克隆或同步最新的代码到本地存储库 git clone https://DOMAIN_NAME/YOUR_NAME/REPO_NAME.git git pull
二、为自己的工作创建一个分支,该分支应该只负责单一功能模块或代码模块的版本控制; git checkout -b mybranch git branch
三、在该分支上完成某单一功能模块或代码模块的开发工作;多次进行如下操作: git add FILES git commit -m "commit log"
四、最后,先切换回master分支,将远程origin/master同步最新到本地存储库,再合并mybranch到master分支,推送到远程origin/master之后即完成了一项开发工作。 git checkout master git pull git merge --no-ff mybranch git push
Git Rebase
git rebase命令格式大致如下:
git rebase -i [startpoint] [endpoint]
其中-i的意思是--interactive,即弹出交互式的界面让用户编辑完成合并操作,[startpoint] [endpoint]则指定了一个编辑区间,如果不指定[endpoint],则该区间的终点默认是当前分支的HEAD。
一般只指定[startpoint] ,即指定从某一个commit节点开始,可以使用HEAD^^、HEAD~100、commit ID或者commit ID的头几个字符来指定一个commit节点,比如下面的代码指定重新整理HEAD之前的三个commit节点。
$ git rebase -i HEAD^
git rebase —abort
git rebase --continue2. 模块化软件设计
2.1 编写高质量代码的基本方法
-
通过控制结构简化代码(if else/while/switch)
-
通过数据结构简化代码
-
一定要有错误处理
-
注意性能优先的代价
-
拒绝修修补补要不断重构代码
2.2 模块化设计
模块化的基本原理
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离 (SoC, Separation of Concerns),是由软件工程领域的奠基性人物Edsger Wybe Dijkstra(1930~2002)在1974年提出,没错就是Dijkstra最短路径算法的作者。
关注点的分离在软件工程领域是最重要的原则,我们习惯上称为模块化,翻译成我们中文的表述其实就是“分而治之”的方法。
模块化软件设计的方法如果应用的比较好,最终每一个软件模块都将只有一个单一的功能目标,并相对独立于其他软件模块,使得每一个软件模块都容易理解容易开发。
从而整个软件系统也更容易定位软件缺陷bug,因为每一个软件缺陷bug都局限在很少的一两个软件模块内。
而且整个系统的变更和维护也更容易,因为一个软件模块内的变更只影响很少的几个软件模块。
因此,软件设计中的模块化程度便成为了软件设计有多好的一个重要指标,一般我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。
耦合度(Coupling)
耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合(Tightly Coupled)、松散耦合(Loosely Coupled)和无耦合(Uncoupled)。
一般在软件设计中我们追求松散耦合。

内聚度(Cohesion)
内聚度是指一个软件模块内部各种元素之间互相依赖的紧密程度。
理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性(Feather)。
软件设计中的一些基本方法
KISS(Keep It Simple & Stupid)原则
•一行代码只做一件事
•一个块代码只做一件事
•一个函数只做一件事
•一个软件模块只做一件事
使用本地化外部接口来提高代码的适应能力
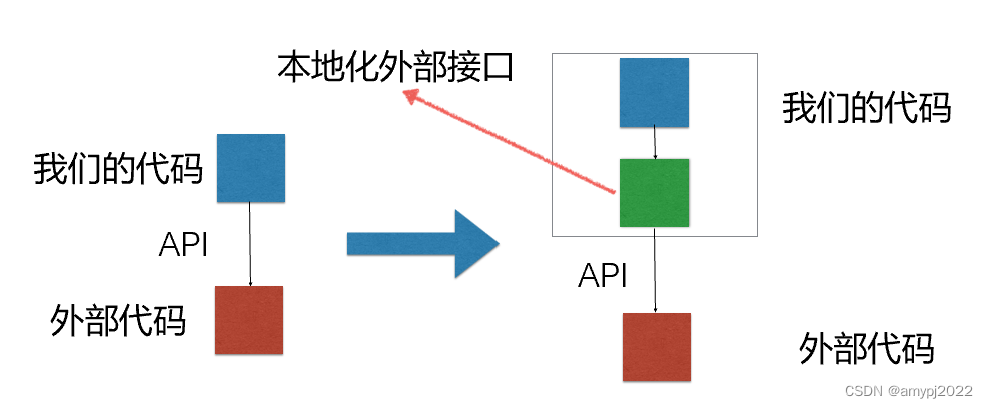
不要和陌生人说话原则
先写伪代码的代码结构更好一些
2.3 可重用软件设计
接口的基本概念
•尽管已经做了初步的模块化设计,但是分离出来的数据结构和它的操作还有很多菜单业务上的痕迹,我们要求这一个软件模块只做一件事,也就是功能内聚,那就要让它做好链表数据结构和对链表的操作,不应该涉及菜单业务功能上的东西;同样我们希望这一个软件模块与其他软件模块之间松散耦合,就需要定义简洁、清晰、明确的接口。
•这时进一步优化这个初步的模块化代码就需要设计合适的接口。定义接口看起来是个很专业的事情,其实在我们生活中无处不在,比如我们看的电视剧中“天王盖地虎,宝塔镇河妖”就是黑社会接头定义的接口,比如两个人对话交流沟通使用的就是汉语普通话或标准英语这么一个接口规范。
•接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。
•在面向过程的编程中,接口一般定义了数据结构及操作这些数据结构的函数;而在面向对象的编程中,接口是对象对外开放(public)的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
接口规格包含五个基本要素
•接口规格是软件系统的开发者正确使用一个软件模块需要知道的所有信息,那么这个软件模块的接口规格定义就必须清晰明确地说明正确使用本软件模块的信息。一般来说,接口规格包含五个基本要素:
•接口的目的;
•接口使用前所需要满足的条件,一般称为前置条件或假定条件;
•使用接口的双方遵守的协议规范;
•接口使用之后的效果,一般称为后置条件;
•接口所隐含的质量属性。
微服务的概念
•由一系列独立的微服务共同组成软件系统的一种架构模式;
•每个微服务单独部署,跑在自己的进程中,也就是说每个微服务可以有一个自己独立的运行环境和软件堆栈;
•每个微服务为独立的业务功能开发,一般每个微服务应分解到最小可变产品(MVP),达到功能内聚的理想状态。微服务一般通过RESTful API接口方式进行封装;
•系统中的各微服务是分布式管理的,各微服务之间非常强调隔离性,互相之间无耦合或者极为松散的耦合,系统通过前端应用或API网关来聚合各微服务完成整体系统的业务功能。
RESTful API
•REST即REpresentational State Transfer的缩写,可以翻译为”表现层状态转化”。有表现层就有背后的信息实体,信息实体就是URI代表的资源,也可以是一种服务,状态转化就是通过HTTP协议里定义的四个表示操作方式的动词:GET、POST、PUT、DELETE,分别对应四种基本操作:
•GET用来获取资源;
•POST用来新建资源(也可以用于更新资源);
•PUT用来更新资源;
•DELETE用来删除资源。
接口与耦合度之间的关系
•对于软件模块之间的耦合度,前文中提到,耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合(Tightly Coupled)、松散耦合(Loosely Coupled)和无耦合(Uncoupled)。一般在软件设计中我们追求松散耦合。
•更细致地对耦合度进一步划分的话,耦合度依次递增可以分为无耦合、数据耦合、标记耦合、控制耦合、公共耦合和内容耦合。这些耦合度划分的依据就是接口的定义方式,我们接下来重点分析一下公共耦合、数据耦合和标记耦合。
•公共耦合
•当软件模块之间共享数据区或变量名的软件模块之间即是公共耦合,显然两个软件模块之间的接口定义不是通过显式的调用方式,而是隐式的共享了共享了数据区或变量名。
•数据耦合
•在软件模块之间仅通过显式的调用传递基本数据类型即为数据耦合。
•标记耦合
•在软件模块之间仅通过显式的调用传递复杂的数据结构(结构化数据)即为标记耦合,这时数据的结构成为调用双方软件模块隐含的规格约定,因此耦合度要比数据耦合高。但相比公共耦合没有经过显式的调用传递数据的方式耦合度要低。
通用接口定义的基本方法
参数化上下文
移除前置条件
参数化上下文之后,我们发现这个接口还是有很大的局限性,就是在调用这个接口时有个前提,就是你有三个数,不是两个数,也不是5个数。必须有三个数就是前置条件。将这个前置条件移除掉,那就是我们可以求任意个数的和 。
int sum(int numbers[], int len);
这个接口显然更通用了,既参数化了上下文又移除了原来的只能三个数求和的约束,但是又增加了一个约束条件,就是len的数值不能超过numbers数组定义的长度,否则会产生越界。后置条件也较为复杂,可能是只对numbers数组前len个数求和,所以后置条件不仅是返回值,还隐含了这个返回值是numbers数组前len个数的和。
简化后置条件
2.4 可重入函数与线程安全
可重入函数
可重入(reentrant)函数可以由多于一个任务并发使用,而不必担心数据错误。相反,不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。可重入函数要么使用局部变量,要么在使用全局变量时保护自己的数据。
可重入函数的基本要求
• 不为连续的调用持有静态数据;
• 不返回指向静态数据的指针;
• 所有数据都由函数的调用者提供;
• 使用局部变量,或者通过制作全局数据的局部变量拷贝来保护全局数据;
• 使用静态数据或全局变量时做周密的并行时序分析,通过临界区互斥避免临界区冲突;
• 绝不调用任何不可重入函数。
什么是线程安全?
•如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
• 线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
函数的可重入性与线程安全之间的关系
• 可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题;
• 不可重入的函数一定不是线程安全的。
CPU指令执行的顺序一致性
•为了提高流水线的运行效率,CPU会对无依赖的前后指令做适当的乱序和调整,对控制依赖的指令做分支预测,对内存访问等耗时操作提前预先处理等,这些都会导致指令乱序执行。
•但是我们编程时一般理解代码在CPU上的执行顺序和代码的逻辑顺序是一致的呀?这有点让人困惑。从单核单线程CPU的角度来看,指令在CPU内部可能是乱序执行的,但是对外表现却是顺序执行的。因为指令集架构(ISA)中的指令和寄存器作为CPU的对外接口,CPU只需要把内部真实的物理寄存器按照指令的执行顺序,顺序映射到ISA寄存器上,也就是CPU只要将结果顺序地提交到ISA寄存器,就可以保证顺序一致性(Sequential consistency)。
3. 需求
什么是需求?
需求分析就是需求分析师对用户期望的软件行为进行表述,并进一步用对象或实体的状态、属性和行为来定义需求。
有哪些类型的需求?
-
功能需求:根据所需的活动描述所需的行为
-
质量需求或非功能需求:描述软件必须具备的一些质量特性
-
设计约束(设计约束): 设计决策,例如选择平台或接口组件
-
过程约束(过程约束): 对可用于构建系统的技术或资源的限制
获取需求的主要方法
•Interviewing stake holders
•Reviewing available documentations
•Observing the current system (if one exists)
•Apprenticing with users to learn about user's task in more details
•Interviewing user or stakeholders in groups
•Using domain specific strategies, such as Joint Application Design
•Brainstorming with current and potential users
Characteristics of Requirements需求的特点
•Correct
•Consistent
•Unambigious无二义性
•Complete
•Feasible
•Relevant无与主要目标不相关的需求
•Testable
•Traceable
3.2 对需求进行分析和建模
需求分析的两类基本方法
•原型化方法(Prototyping)和建模的方法(Modeling)是整理需求的两类基本方法。
•原型化方法可以很好地整理出用户接口方式(UI,User Interface),比如界面布局和交互操作过程。
•建模的方法可以快速给出有关事件发生顺序或活动同步约束的问题,能够在逻辑上形成模型来整顿繁杂的需求细节。
用例
•用例(Use Case)的核心概念中首先它是一个业务过程(business process),经过逻辑整理抽象出来的一个业务过程,这是用例的实质。什么是业务过程?在待开发软件所处的业务领域内完成特定业务任务(business task)的一系列活动就是业务过程。
四个必要条件
必要条件一 :它是不是一个业务过程?
必要条件二:它是不是由某个参与者触发开始?
必要条件三:它是不是显式地或隐式地终止于某个参与者?
必要条件四: 它是不是为某个参与者完成了有用的业务工作?
用例的三个抽象层级
•在准确理解用例概念的基础上,我们可以进一步将用例划分为三个抽象层级:
• • 抽象用例(Abstract use case)。只要用一个干什么、做什么或完成什么业务任务的动名词短语,就可以非常精简地指明一个用例;
• • 高层用例(High level use case)。需要给用例的范围划定一个边界,也就是用例在什么时候什么地方开始,以及在什么时候什么地方结束;
• • 扩展用例(Expanded use case)。需要将参与者和待开发软件系统为了完成用例所规定的业务任务的交互过程一步一步详细地描述出来,一般我们使用一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来。
用例建模的基本步骤
•第一步,从需求表述中找出用例,往往是动名词短语表示的抽象用例;
•第二步,描述用例开始和结束的状态,用TUCBW和TUCEW表示的高层用例;
•第三步,对用例按照子系统或不同的方面进行分类,描述用例与用例、用例与参与者之间的上下文关系,并画出用例图;
•第四步,进一步逐一分析用例与参与者的详细交互过程,完成一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来扩展用例。
•其中第一步到第三步是计划阶段,第四步是增量实现阶段。
继承关系(Inheritance Relationship)
•继承关系表达着两个概念之间具有概括化/具体化(generalization/specialization)的关系。一个概念比另一个概念更加概括/具体。比如车辆是是小汽车的概括,小汽车是一种具体的车辆类型。所以继承关系也被称为“是一种”(IS-A)关系。
聚合关系(Aggregation Relationship)
•聚合关系表示一个对象是另一个对象的一部分的情况。比如发动机引擎是小汽车的一部分。也被称为“部分与整体”(part-of)的关系。
聚合关系使用一个平行四边形的箭头表示
关联关系(Association Relationship)
•关联关系表示继承和聚合以外的一般关系,是业务领域内特定的两个概念之间的关系,
既不是继承关系也不是聚合关系。比如教授参与了退休计划、讲师教授课程、用户拥有账户等都是两个概念之间一般关系,我们用一个直线连起来来表示教授和退休计划两个业务领域概念之间的关联关系
业务领域建模的基本步骤
• • 第一步,收集应用业务领域的信息。聚焦在功能需求层面,也考虑其他类型的需求和资料;
• • 第二步,头脑风暴。列出重要的应用业务领域概念,给出这些概念的属性,以及这些概念之间的关系;
• • 第三步,给这些应用业务领域概念分类。分别列出哪些是类、哪些属性和属性值、以及列出类之间的继承关系、聚合关系和关联关系。
• • 第四步,将结果用 UML 类图画出来。
第一步更多地在获取需求的阶段已经完成,这里不做赘述;第四步 UML 类图的画法前面已经给出,接下来我们重点将头脑风暴的做法和业务领域概念分类的方法具体探讨一下
反范式化
•反范式化在节省你读的代价的同时会带来更新的代价:如果你将零件的名字冗余到产品的文档对象中,那么你想更改某个零件的名字你就必须同时更新所有包含这个零件的产品对象。
•在一个读比写频率高的多的系统里,反范式是有使用的意义的。如果你很经常的需要高效的读取冗余的数据,但是几乎不去变更他的话,那么付出更新上的代价还是值得的。更新的频率越高,这种设计方案的带来的好处越少。
•例如:假设零件的名字变化的频率很低,但是零件的库存变化很频繁,那么你可以冗余零件的名字到产品对象中,但是别冗余零件的库存。
•需要注意的是,一旦你冗余了一个字段,那么对于这个字段的更新将不再是原子的。和上面双向引用的例子一样,如果你在零件对象中更新了零件的名字,那么更新产品对象中保存的名字字段前将会存在短时间的不一致。
反范式化总结
•使用双向引用来优化你的数据库架构,前提是你能接受无法原子更新的代价。
•可以在引用关系中冗余数据到one端或者N端。
•在决定是否采用反范式化时需要考虑下面的因素:
•你将无法对冗余的数据进行原子更新。
•只有读写比比较高的情况下才应该采取反范式化的设计。
3.3 从需求分析到软件设计
统一过程(Unified Process)
•统一过程(UP,Unified Process)的核心要义是用例驱动(Use case driven)、以架构为中心(Architecture centric)、增量且迭代(Incremental and Iterative)的过程。用例驱动就是我们前文中用例建模得到的用例作为驱动软件开发的目标;以架构为中心的架构是后续软件设计的结果,就是保持软件架构相对稳定,减小软件架构层面的重构造成的混乱;增量且迭代体现在下图中。
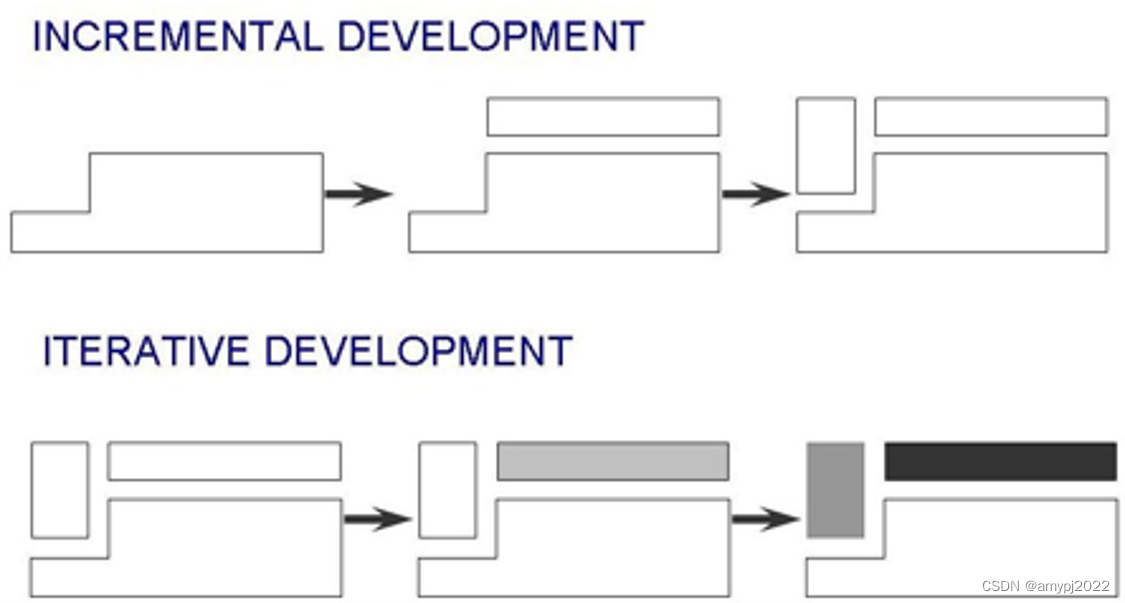
敏捷统一过程的计划阶段
•在项目正式动手开工之前,敏捷统一过程要求进行精心周密的构思完成计划阶段。计划阶段要做的工作有如下几点:
• • 首先明确项目的动机、业务上的实际需求,以及对项目动机和业务需求可供替代选择的多种可能性;
• • 然后充分调研获取需求并明确定义需求规格;
• • 在明确需求规格的基础上进行项目的可行性研究;
• • 如果项目可行,接下来接着进行用例建模并给出用例图;
• • 同时明确需求和用例之间的可跟踪矩阵;
• • 从而形成项目的概念模型草案;
• • 以及项目可能的日程安排、需要的资源以及大致的预算范围。
敏捷统一过程的四个关键步骤
•第一,确定需求;
•第二,通过用例的方式来满足这些需求;
•第三,分配这些用例到各增量阶段;
•第四,具体完成各增量阶段所计划的任务。
•显然,第一到第三步主要是计划阶段的工作,第四步是接下来要进一步详述的增量阶段的工作。
敏捷统一过程的增量阶段
•在每一次增量阶段的迭代过程中,都要进行从需求分析到软件设计实现的过程,具体敏捷统一过程将增量阶段分为五个步骤:
• • 用例建模(Use case modeling);
• • 业务领域建模(Domain modeling);
• • 对象交互建模(Object Interaction modeling);
• • 形成设计类图(design class diagram);
• • 软件的编码实现和软件应用部署;
对象交互建模的基本步骤
•具体来说对象交互建模的基本步骤就是在扩展用例的基础上完成如下步骤:
•第一步,在扩展用例中右侧一列中找出关键步骤(nontrivial steps)。关键步骤是那些需要在背后进行业务过程处理的步骤,而不是仅仅在表现层(presentation layer, i.e., the Graphical User Interface or GUI)与参与者进行用户接口层面交互的琐碎步骤。
•第二步,对于每一个关键步骤,从关键步骤在扩展用例两列表格中的左侧作为开始,完成剧情描述(scenario),描述一步一步的对象交互过程,直到执行完该关键步骤。
•第三步,如果需要的话,将剧情描述(scenario)进一步转换成剧情描述表(scenario table)。
•第四步,将剧情描述(scenario)或剧情描述表(scenario table)转换成序列图。
•对象交互建模的四个基本步骤以某个用例的扩展用例为输入,中间借助业务领域知识及业务领域建模中的相关对象、属性等,最终产出结果为序列图。
4. 软件科学基础概论
三种系统类型
S系统:有规范定义,可从规范派生
矩阵操纵矩阵运算
P系统:需求基于问题的近似解,但现实世界保持稳定
象棋程序
E系统:嵌入现实世界并随着世界的变化而变化(大多数软件都属于这个类型)
预测经济运行方式的软件(但经济尚未被完全理解)
软件具有复杂性和易变性,从而难以达成概念的完整性与一致性。(需求的达成永远赶不上需求的变化)
4.1 设计模式
设计模式的优点
•正确使用设计模式具有以下优点。
• • 可以提高程序员的思维能力、编程能力和设计能力。
• • 使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
• • 使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
什么设计模式?
•设计模式的本质是面向对象设计原则的实际运用总结出的经验模型。对类的封装性、继承性和多态性以及类的关联关系和组合关系的充分理解的基础上才能准确理解设计模式。
设计模式一般由四个部分组成
• 该设计模式的名称;
• 该设计模式的目的,即该设计模式要解决什么样的问题;
• 该设计模式的解决方案;
• 该设计模式的解决方案有哪些约束和限制条件。
设计模式的分类
根据模式是主要用于类上还是主要用于对象上来划分的话,可分为类模式和对象模式两种类型的设计模式:
• 类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。比如模板方法模式等属于类模式。
• 对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。由于组合关系或聚合关系比继承关系耦合度低,因此多数设计模式都是对象模式。
根据设计模式可以完成的任务类型来划分的话,可以分为创建型模式、结构型模式和行为型模式 3 种类型的设计模式:
• 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。比如单例模式、原型模式、建造者模式等属于创建型模式。
• 结构型模式:用于描述如何将类或对象按某种布局组成更大的结构,比如代理模式、适配器模式、桥接模式、装饰模式、外观模式、享元模式、组合模式等属于结构型模式。结构型模式分为类结构型模式和对象结构型模式,前者采用继承机制来组织接口和类,后者釆用组合或聚合来组合对象。由于组合关系或聚合关系比继承关系耦合度低,所以对象结构型模式比类结构型模式具有更大的灵活性。
• 行为型模式:用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。比如模板方法模式、策略模式、命令模式、职责链模式、观察者模式等属于行为型模式。行为型模式分为类行为模式和对象行为模式,前者采用继承在类间分配行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,所以对象行为模式比类行为模式具有更大的灵活性。
职责链(Chain of Responsibility)
职责链(Chain of Responsibility)模式:为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。通过这种方式将多个请求处理者串联为一个链表,去除请求发送者与它们之间的耦合
4.2 设计模式背后的设计原则
开闭原则(Open Closed Principle,OCP)
软件应当对扩展开放,对修改关闭
Liskov替换原则(Liskov Substitution Principle,LSP)
继承必须确保超类所拥有的性质在子类中仍然成立
依赖倒置原则(Dependence Inversion Principle,DIP)
高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象
其核心思想是:要面向接口编程,不要面向实现编程
单一职责原则(Single Responsibility Principle,SRP)
单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分
单一职责原则的核心就是控制类的粒度大小、提高其内聚度
迪米特法则(Law of Demeter,LoD)
又叫作最少知识原则
其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
合成复用原则(Composite Reuse Principle,CRP)
又叫组合/聚合复用原则(Composition/Aggregate Reuse Principle,CARP)。它要求在软件复用时,要尽量先使用组合或者聚合关系来实现,其次才考虑使用继承关系来实现。如果要使用继承关系,则必须严格遵循Liskov替换原则。
继承复用虽然有简单和易实现的优点,但它也存在以下缺点。
• 继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为“白箱”复用。
• 子类与父类的耦合度高。父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展与维护。
• 继承复用限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生变化。
合成复用的优点
采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能,它有以下优点。
• 组合或聚合复用维持了类的封装性。因为属性对象的内部细节是新对象看不见的,所以这种复用又称为“黑箱”复用。
• 新旧类之间的耦合度低。这种复用所需的依赖较少,新对象存取属性对象的唯一方法是通过属性对象的接口。
• 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与属性对象类型相同的对象。
观察者(Observer)模式
观察者(Observer)模式:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为,这样所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式。
4.3 常见的软件架构举例
三层架构

MVC架构
MVC即为Model-View-Controller(模型-视图-控制器),MVC是一种设计模式,以MVC设计模式为主体结构实现的基础代码框架一般称为MVC框架,如果MVC设计模式决定了整个软件的架构,不管是直接实现了MVC模式还是以某一种MVC框架为基础,只要软件的整体结构主要表现为MVC模式,我们就称为该软件的架构为MVC架构。
MVC中M、V和C所代表的含义如下:
• Model(模型)代表一个存取数据的对象及其数据模型。
• View(视图)代表模型包含的数据的表达方式,一般表达为可视化的界面接口。
• Controller(控制器)作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图。控制器可以使视图与模型分离开解耦合。
MVC架构 vs. 三层架构
模型和视图有着业务层面的业务数据紧密耦合关系,控制器的核心工作就是业务逻辑处理,显然MVC架构和三层架构有着某种对应关系,但又不是层次架构的抽象接口依赖关系,因此为了体现它们的区别和联系,我们在MVC的结构示意图中将模型和视图上下垂直对齐表示它们内在的业务层次及业务数据的对应关系,而将控制器放在左侧表示控制器处于优先重要位置,放在模型和视图的中间位置是为了与三层架构对应与业务逻辑层处于相似的层次。
MVC架构中的模型、视图与控制器
在MVC架构下,模型用来封装核心数据和功能,它独立于特定的输出表示和输入行为,是执行某些任务的代码,至于这些任务以什么形式显示给用户,并不是模型所关注的问题。模型只有纯粹的功能性接口,也就是一系列的公开方法,这些方法有的是取值方法,让系统其它部分可以得到模型的内部状态,有的则是写入更新数据的方法,允许系统的其它部分修改模型的内部状态。
在MVC架构下,视图用来向用户显示信息,它获得来自模型的数据,决定模型以什么样的方式展示给用户。同一个模型可以对应于多个视图,这样对于视图而言,模型就是可重用的代码。一般来说,模型内部必须保留所有对应视图的相关信息,以便在模型的状态发生改变时,可以通知所有的视图进行更新。
在MVC架构下,控制器是和视图联合使用的,它捕捉鼠标移动、鼠标点击和键盘输入等事件,将其转化成服务请求,然后再传给模型或者视图。软件的用户是通过控制器来与系统交互的,他通过控制器来操纵模型,从而向模型传递数据,改变模型的状态,并最后导致视图的更新。
什么是MVVM?
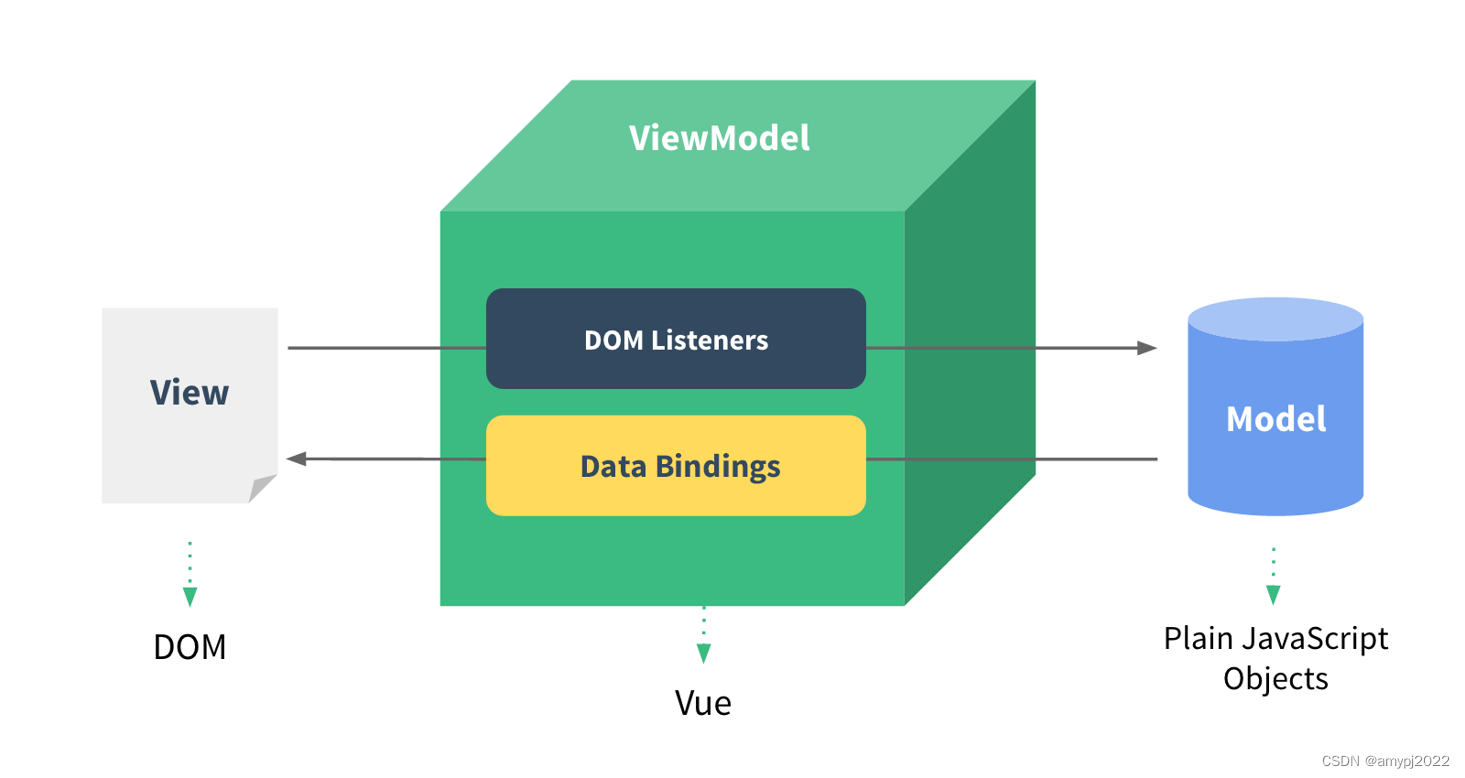
MVVM即 Model-View-ViewModel,最早由微软提出来,借鉴了桌面应用程序的MVC模式的思想,是一种针对WPF、Silverlight、Windows Phone的设计模式,目前广泛应用于复杂的Javacript前端项目中。
随着前端页面越来越复杂,用户对于交互性要求也越来越高,jQuery是远远不够的,于是MVVM被引入到Javascript前端开发中。
MVVM的优点
MVVM模式和MVC模式一样,主要目的是分离视图(View)和模型(Model),有几大优点:
• 低耦合。视图(View)可以独立于Model变化和修改,一个ViewModel可以绑定到不同的"View"上,当View变化的时候Model可以不变,当Model变化的时候View也可以不变。
• 可重用性。你可以把一些视图逻辑放在一个ViewModel里面,让很多View重用这段视图逻辑。
• 独立开发。开发人员可以专注于业务逻辑和数据的开发(ViewModel),设计人员可以专注于页面设计。
• 可测试。界面素来是比较难于测试的,测试可以针对ViewModel来写。
4.4 软件架构风格与描述方法
两种不同层级的软件架构复用方法
• 克隆(Cloning),完整地借鉴相似项目的设计方案,甚至代码,只需要完成一些细枝末节处的修改适配工作。
• 重构(Refactoring),构建软件架构模型的基本方法,通过指引我们如何进行系统分解,并在参考已有的软件架构模型的基础上逐步形成系统软件架构的一种基本建模方法。
这两种软件架构复用方法与生物世界的无性繁殖和有性繁殖极为相似,比如单细胞生物通过细胞分裂实现增殖,实际上就是克隆;而有性繁殖重构了DNA双螺旋结构。复杂系统方面的研究表明在不同层次上的复杂系统常常表现出来相似的结构,这又是一个例证。
软件架构模型至关重要的作用
大型软件系统的软件架构模型在整个项目中起到至关重要的作用。
首先,软件架构模型有助于项目成员从整体上理解整个系统;
其次,给复用提供了一个高层视图,既可以辅助决定从其他系统中复用设计或组件,也给我们构建的软件架构模型未来的复用提供了更多可能性;
再次,软件架构模型为整个项目的构建过程提供了一个蓝图,贯穿于整个项目的生命周期;
最后,软件架构模型有助于理清系统演化的内在逻辑、有助于跟踪分析软件架构上的依赖关系、有助于项目管理决策和项目风险管理等。
软件架构模型
软件架构模型是在高层抽象上对系统中关键要素的描述,而且表现出抽象的层次结构。
构建软件架构模型的基本方法就是在不同层次上分解(decomposition)系统并抽象出其中的关键要素。
分解的常见方法
• 面向功能的分解方法,用例建模即是一种面向功能的分解方法;
• 面向特征的分解方法,根据数量众多的某种系统显著特征在不同抽象层次上划分模块的方法;
• 面向数据的分解方法,在业务领域建模中形成概念业务数据模型即应用了面向数据的分解方法;
• 面向并发的分解方法,在一些系统中具有多种并发任务的特点,那么我们可以将系统分解到不同的并发任务中(进程或线程),并描述并发任务的时序交互过程;
• 面向事件的分解方法,当系统中需要处理大量的事件,而且往往事件会触发复杂的状态转换关系,这时系统就要考虑面向事件的分解方法,并内在状态转换关系进行清晰的描述;
• 面向对象的分解方法,是一种通用的分析设计范式,是基于系统中抽象的对象元素在不同抽象层次上分解的系统的方法。
分解和视图
在合理的分解和抽象基础上抽取系统的关键要素,进一步描述关键要素之间的关系,比如面向数据分解之后形成的数据关系模型、面向事件分析之后总结出的状态转换图、面向并发分解之后总结出的并发任务的时序交互过程等,都是软件架构模型中的某种关键视图(Views)。
软件架构模型是通过一组关键视图来描述的,同一个软件架构,由于选取的视角不同(Perspective)可以得到不同的视图,这样一组关键视图搭配起来可以完整地描述一个逻辑自洽的软件架构模型。一般来说,我们常用的几种视图有分解视图、依赖视图、泛化视图、执行视图、实现视图、部署视图和工作任务分配视图。
在具体了解软件架构的视图之前,为了理解软件架构中的关键要素所表现出来的特征,我们先来看看软件架构的风格和策略,然后在逐一分析软件架构的视图。
软件架构风格与策略
管道-过滤器
管道-过滤器风格的软件架构是面向数据流的软件体系结构,最典型的应用是编译系统。 一个普通的编译系统包括词法分析器、语法分析器、语义分析与中间代码生成器、目标代码生成器等一系列对源代码进行处理的过程。就像如图:管道-过滤器风格示意图,对源代码处理的过滤器通过管道连接起来,实现了端到端的从源代码到编译目标的完整系统。

客户-服务
Client/Server(C/S)和Browser/Server(B/S)是我们常用的对软件的网络结构特点的表述方式,但它们背后蕴含着一种普遍存在的软件架构风格,即客户-服务模式的架构风格。
客户-服务模式的架构风格是指客户代码通过请求和应答的方式访问或者调用服务代码。这里的请求和应答可以是函数调用和返回值,也可以是TCP Socket中的send和recv,还可以是HTTP协议中的GET请求和响应。
在客户-服务模式中,客户是主动的,服务是被动的。客户知道它向哪个服务发出请求,而服务却不知道它正在为哪个客户提供服务,甚至不知道正在为多少客户提供服务。
客户-服务模式的架构风格具有典型的模块化特征,降低了系统中客户和服务构件之间耦合度,提高了服务构件的可重用性。
P2P
P2P(peer-to-peer)架构是客户-服务模式的一种特殊情形,P2P架构中每一个构件既是客户端又是服务端,即每一个构件都有一种接口,该接口不仅定义了构件提供的服务,同时也指定了向同类构件发送的服务请求。这样众多构件一起形成了一种对等的网络结构,如图:P2P网络结构示意图。
P2P架构典型的应用有文件共享网络、比特币网络等。
发布-订阅
在发布-订阅架构中,有两类构件:发布者和订阅者。如果订阅者订阅了某一事件,则该事件一旦发生,发布者就会发布通知给该订阅者。观察者模式体现了发布-订阅架构的基本结构。
在实际应用中往往会需要不同的订阅组,以及不同的发布者。由于订阅者数量庞大往往在消息推送时采用消息队列的方式延时推送。如图:包含消息队列的发布-订阅架构示意图。
CRUD
CRUD 是创建(Create)、 读取(Read)、更新(Update)和删除(Delete)四种数据库持久化信息的基本操作的助记符,表示对于存储的信息可以进行这四种持久化操作。CRUD也代表了一种围绕中心化管理系统关键数据的软件架构风格。一般常见的各类信息系统,比如ERP、CRM、医院信息化平台等都可以用CRUD架构来概括。
层次化
较为复杂的系统中的软件单元,仅仅从平面展开的角度进行模块化分解是不够的,还需要从垂直纵深的角度将软件单元按层次化组织,每一层为它的上一层提供服务,同时又作为下一层的客户。
通信网络中的OSI(Open System Interconnection)参考模型是典型的层次化架构风格,如图:OSI参考模型示意图。在OSI参考模型中每一层都将相邻底层提供的通信服务抽象化,隐藏它的实现细节,同时为相邻的上一层提供服务。
软件架构的描述方法
软件架构模型是通过一组关键视图来描述的,同一个软件架构,由于选取的视角(Perspective)和抽象层次不同可以得到不同的视图,这样一组关键视图搭配起来可以完整地描述一个逻辑自洽的软件架构模型。一般来说,我们常用的几种视图有分解视图、依赖视图、泛化视图、执行视图、实现视图、部署视图和工作任务分配视图。
• 分解视图 Decomposition View
• 依赖视图 Dependencies View
• 泛化视图 Generalization View
• 执行视图 Execution View
• 实现视图 Implementation View
• 部署视图 Deployment View
• 工作任务分配视图 Work-assignment View
分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。由于前述分解方法中已经明确呈现出了分解视图的特征,我们这里简要了解一下分解视图中常见的软件模块术语。
• 子系统(Subsystem),一个系统可能有一些列子系统组成;
• 包(Package),子系统又由包组成;
• 类(Class),包又由类组成;
• 组件(Component),一般用来表示一个运行时的单元;
• 库(Library)是具有明确定义的接口的共享软件代码的集合,可以是代码库,也可以是由代码库编译打包后的静态库,还可以构建成动态链接库;
• 软件模块(Module)用来指软件代码的结构化单元,模块化(modular)是在软件架构中各部分都被明确定义的接口所描述时使用,也就是可以明确无误地指定各部分的外部可见行为。
• 软件单元(Software unit)是在不明确该部分的类型时使用。
依赖视图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关系。
依赖视图在项目计划中有比较典型的应用。比如它能帮助我们找到没有依赖关系的软件模块或子系统,以便独立开发和测试,同时进一步根据依赖关系确定开发和测试软件模块的先后次序。
依赖视图在项目的变更和维护中也很有价值。比如它能有效帮助我们理清一个软件模块的变更对其他软件模块带来影响范围。
泛化视图
泛化视图展现了软件模块之间的一般化或具体化的关系,典型的例子就是面向对象分析和设计方法中类之间的继承关系。值得注意的是,采用对象组合替代继承关系,并不会改变类之间的泛化特征。因此泛化是指软件模块之间的一般化或具体化的关系,不能局限于继承概念的应用。
泛化视图有助于描述软件的抽象层次,从而便于软件的扩展和维护。比如通过对象组合或继承很容易形成新的软件模块与原有的软件架构兼容。
执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
执行实体可以最终分解到软件的基本元素和软件的基本结构,因而与软件代码具有比较直接的映射关系。在设计与实现过程中,我们一般将执行视图转换为伪代码之后,再进一步转换为实现代码。
实现视图
实现视图是描述软件架构与源文件之间的映射关系。比如软件架构的静态结构以包图或设计类图的方式来描述,但是这些包和类都是在哪些目录的哪些源文件中具体实现的呢?一般我们通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
实现视图有助于码农在海量源代码文件中找到具体的某个软件单元的实现。实现视图与软件架构的静态结构之间映射关系越是对应的一致性高,越有利于软件的维护,因此实现视图是一种非常关键的架构视图。
部署视图
部署视图是将执行实体和计算机资源建立映射关系。这里的执行实体的粒度要与所部署的计算机资源相匹配,比如以进程作为执行实体那么对应的计算机资源就是主机,这时应该描述进程对应主机所组成的网络拓扑结构,这样可以清晰地呈现进程间的网络通信和部署环境的网络结构特点。当然也可以用细粒度的执行实体对应处理器、存储器等。
部署视图有助于设计人员分析一个设计的质量属性,比如软件处理网络高并发的能力、软件对处理器的计算需求等。
工作分配视图
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,也有利于在个项目团队和成员之间合理地分配和调整项目资源,甚至在项目计划阶段工作分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。
每个视图都是从不同的角度对软件架构进行描述和建模,比如从功能的角度、从代码结构的角度、从运行时结构的角度、从目录文件的角度,或者从项目团队组织结构的角度。
软件架构代表了软件系统的整体设计结构,它应该是所有这些视图的集合。但我们不会将不同角度的这些视图整合起来,因为不便于阅读和更新。不过我们会有意识地将不同角度的视图之间的映射关系和重叠部分了然于胸,从而深刻理解软件架构内在的一致性和完整性,这就是系统概念原型。
4.5 什么是高质量软件?
软件质量的含义
•生产商:产品符合标准规范
•消费者:产品适于使用且带来益处
•按照我们一般的常识理解,质量是指和其他竞争者相比产品或服务有更高的标准,也就是所谓,不怕不识货就怕货比货,质量是在比较中衡量的。
•按照字典的解释,质量是指较好的一类或优秀的等级。
IEEE的软件质量定义
•IEEE将软件质量定义为,一个系统、组件或过程符合指定要求的程度,或者满足客户或用户期望的程度。
•软件质量是许多质量属性的综合体现,各种质量属性反映了软件质量的方方面面。人们通过改善软件的各种质量属性,从而提高软件的整体质量 。
几种重要的软件质量属性
• 易于修改维护(Modifiability)
• 良好的性能表现(Performance)
• 安全性(Security)
• 可靠性(Reliability)
• 健壮性(Robustness)
• 易用性(Usability)
• 商业目标(Business goals)
5. 软件危机和软件过程
没有银弹的含义
1986年,Brooks发表了一篇著名的论文“没有银弹“:在10年内无法找到解决软件危机的杀手锏(银弹)。
软件中的根本困难,即软件概念结构(conceptual structure)的复杂性,无法达成软件概念的完整性 和一致性,自然无法从根本上解决软件危机带来的困境。
5.1 软件过程模型
软件的生命周期
一般来讲,我们将软件的生命周期划分为:分析、设计、实现、交付和维护这么五个阶段。
• 分析阶段的任务是需求分析和定义,比如在敏捷统一过程中用例建模和业务领域建模就属于分析阶段。分析阶段一般会在深入理解业务的情况下,形成业务概念原型,业务概念原型是业务功能和业务数据模型的有机统一体,比如用例的集合和业务数据模型,每一个用例在逻辑上都可以通过操作业务数据模型完成关键的业务过程。
• 设计阶段分为软件架构设计和软件详细设计,前者一般和分析阶段联系紧密,一般合称为“分析与设计”;后者一般和实现阶段联系紧密,一般合称为“设计与实现”。
• 实现阶段分为编码和测试,其中测试又涉及到单元测试、集成测试、系统测试等。
• 交付阶段主要是部署、交付测试和用户培训等。
• 维护阶段一般是软件生命周期中持续时间最长的一个阶段,而且在维护阶段很可能会形成单独的项目,从而经历分析、设计、实现、交付几个阶段,最终又合并进维护阶段。
软件过程
软件过程又分为描述性的(descriptive)过程和说明性的(prescriptive)过程。
描述性的过程试图客观陈述在软件开发过程中实际发生什么。我们想象一下软件开发过程中实际会发生什么?比如测试时发现了一个bug是对需求的错误理解造成的,那必须返回到分析阶段重新调整软件概念模型,比如用户使用过程中出现闪退现象,我们需要返回到系统测试试图重现闪退,乃至回到设计阶段调整设计方案从根本上解决闪退的根源问题。
说明性的过程试图主观陈述在软件开发过程中应该会发生什么。显然说明性的过程是抽象的过程模型,有利于整个软件项目团队对软件开发过程形成一致的理解,能够在与实际软件开发过程比较时找出项目过程中的问题。
采用不同的过程模型时应该能反映出要达到的过程目标,比如构建高质量软件、早发现缺陷、满足预算和日程约束等。不同的模型适用于不同的情况,我们常见的过程模型,比如瀑布模型、V模型、原型化模型等都有它们所能达到的过程目标和适用的情况。
瀑布模型
瀑布模型(Waterfall Model)是第一个软件过程开发模型,对于能够完全透彻理解的需求且几乎不会发生需求变更的项目瀑布模型是适用的。但是由于瀑布模型能够将软件开发过程按顺序组织过程活动,非常简单和易于理解,因此瀑布模型被广泛应用于解释项目进展情况及所处的阶段。瀑布模型中的主要阶段通过里程碑(milestones)和交付产出来划分的。
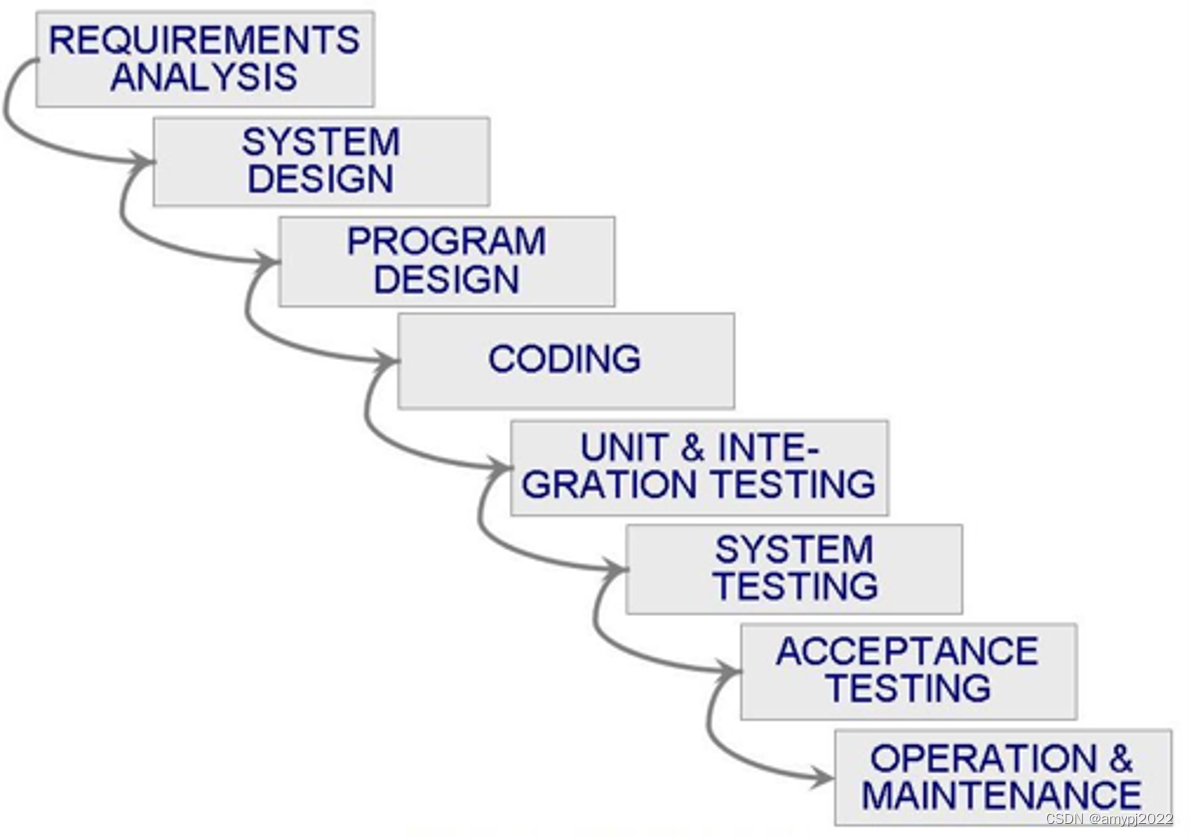
瀑布模型是一个过程活动的顺序结构,没有任何迭代,而大多数软件开发过程都会包含大量迭代过程。瀑布模型不能为处理开发过程中的变更提供任何指导意义,因为瀑布模型假定需求不会发生任何变化。由此看来,瀑布模型将软件开发过程看作类似于工业生产制造的过程,而不是一个创造性的开发过程。工业生产制造的过程就是没有任何迭代活动,直接产出最终产品。瀑布模型视角下的软件开发过程也一样,只有等待整个软件开发过程完成后,才能看到最终软件产品。
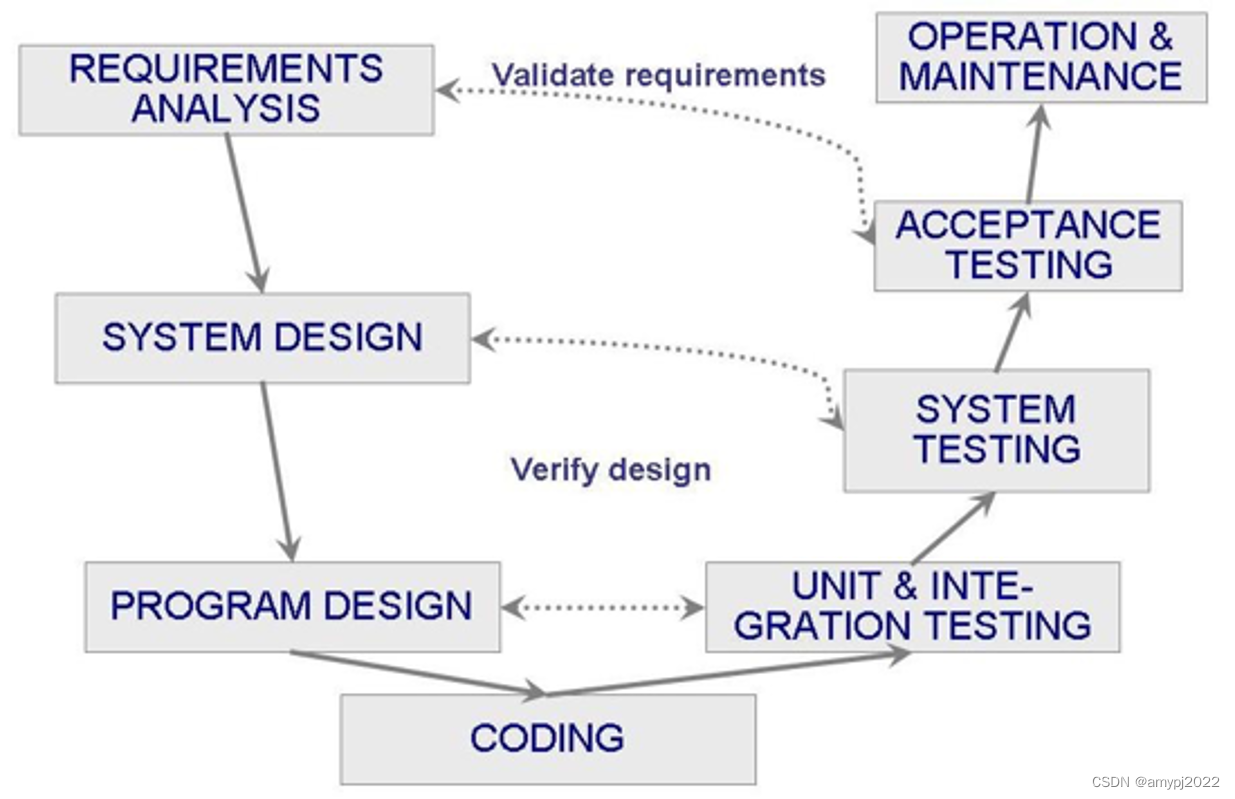
V模型
V模型也是在瀑布模型基础上发展出来的,我们发现单元测试、集成测试和系统测试是为了在不同层面验证设计,而交付测试则是确认需求是否得到满足。也就是瀑布模型中前后两端的过程活动具有内在的紧密联系,如果将模块化设计的思想拿到软件开发过程活动的组织中来,可以发现通过将瀑布模型前后两端的过程活动结合起来,可以提高过程活动的内聚度,从而改善软件开发效率。这就是V模型。
分阶段的增量和迭代开发过程
分阶段开发可以让客户在没有开发完成之前就可以使用部分功能,也就是每次可以交付系统的一小部分,从而缩短开发迭代的周期。如图所示,分阶段开发还可以让产品系统和开发系统并行进行。
分阶段开发的交付策略分为两种,一是增量开发(Incremental development),二是迭代开发(Iterative development)。
增量开发就是从一个功能子系统开始交付,每次交付会增加一些功能,这样逐步扩展功能最终完成整个系统功能的开发。
迭代开发是首先完成一个完整的系统或者完整系统的框架,然后每次交付会升级其中的某个功能子系统,这样反复迭代逐步细化最终完成系统开发。

分阶段开发有着显著的优点:
• 能够在系统没有开发完成之前,开始进行交付和用户培训;
• 频繁的软件发布可以让开发者敏捷地应对始料未及的问题;
• 开发团队可以在不同的版本聚焦于不同的功能领域,从而提升开发效率;
• 还有助于提前布局抢占市场。
任何一颗苍天大树最初都是由一粒小小的种子所规定的。分阶段增量和迭代开发就相当于软件开发过程模型的一颗种子,从这颗种子里我们可以看到敏捷方法的意味、能看到持续集成持续交付的感觉、能看到反复迭代中过程改进和重构的可能性。
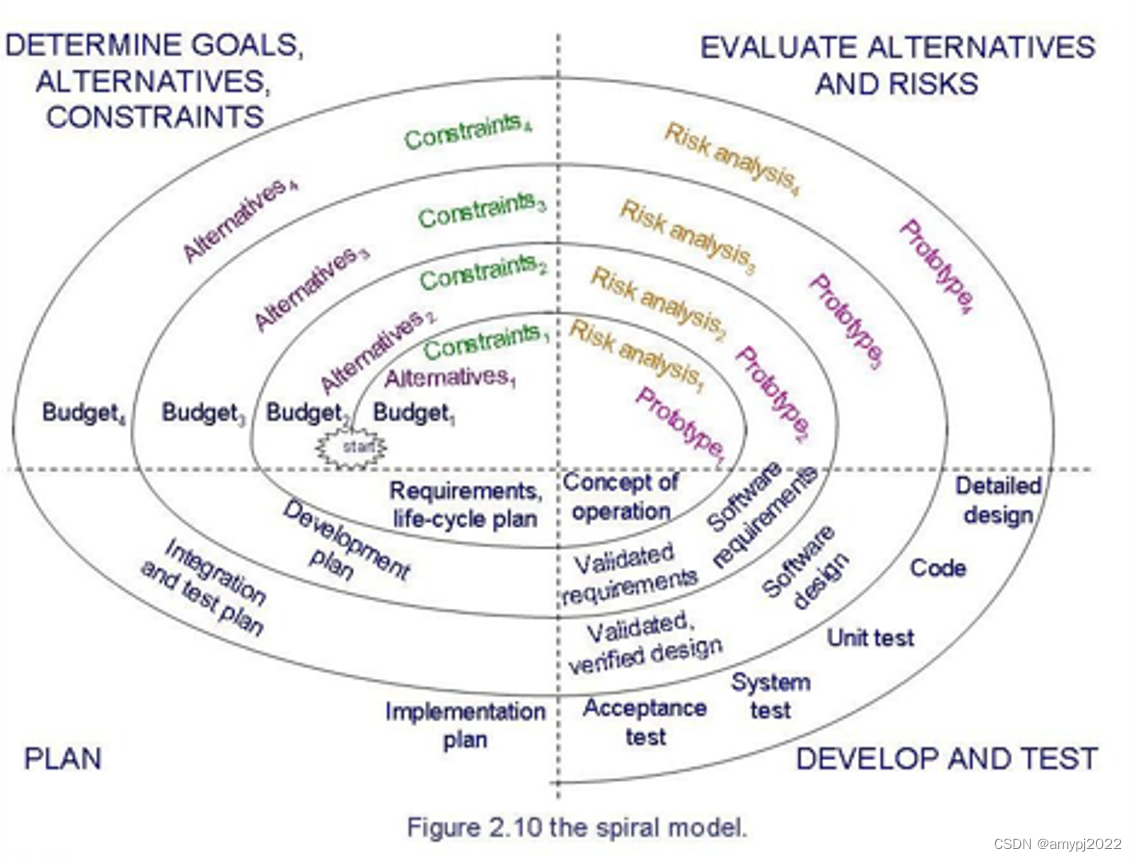
螺旋模型
螺旋模型将每一次迭代过程分为四个主要阶段:
• Plan
• Determine goals, alternatives and constraints
• Evaluate alternatives and risks
• Develop and test
5.2 个人和团队
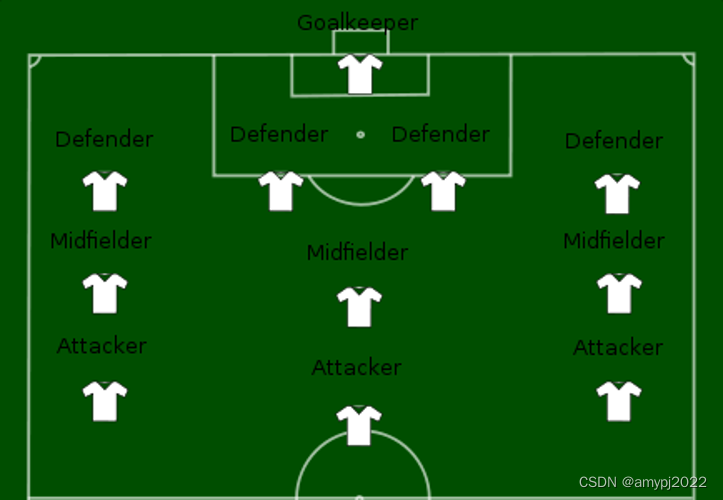
如果将软件开发与足球比赛类比的话,个人训练项目和团队训练项目具有很大的差异,比如足球运动员个人训练可能有基本的体能、各种足球技能,以及良好的足球意识;而足球球队的训练可能会将重点放在阵型、配合和临场发挥上。软件开发过程的训练与此类似,需要分为个人软件过程的训练和团队软件过程的训练。

5.3 CMM/CMMI
继SW-CMM首次发布后,CMU/SEI还开发了其他领域的成熟度模型,包括系统工程、采购、人力资源管理和集成产品开发等领域。虽然各个模型针对的专业领域不同,但彼此之间也有一定的重叠,毕竟它们同出一辙。当CMU/SEI开始开发新一代成熟度模型的时候,开始整合不同模型中的最佳实践,建立统一模型,从而覆盖不同领域,以便为企业提供整个组织的全面过程改进。2001年12月正式发布了能力成熟度集成模型CMMI(Capability Maturity Model Integration) 1.1版本。
CMM/CMMI的5个等级
CMM/CMMI用于评价软件生产能力并帮助其改善软件质量的方法,成为了评估软件能力与成熟度的一套标准,它侧重于软件开发过程的管理及工程能力的提高与评估,是国际软件业的质量管理标准。
CMMI共有5个级别,代表软件团队能力成熟度的5个等级,数字越大,成熟度越高,高成熟度等级表示有比较强的软件综合开发能力。

• CMMI一级,初始级。在初始级水平上,软件组织对项目的目标与要做的努力很清晰,项目的目标可以实现。但是由于任务的完成带有很大的偶然性,软件组织无法保证在实施同类项目时仍然能够完成任务。项目实施能否成功主要取决于实施人员。
• CMMI二级,管理级。在管理级水平上,所有第一级的要求都已经达到,另外,软件组织在项目实施上能够遵守既定的计划与流程,有资源准备,权责到人,对项目相关的实施人员进行了相应的培训,对整个流程进行监测与控制,并联合上级单位对项目与流程进行审查。二级水平的软件组织对项目有一系列管理程序,避免了软件组织完成任务的偶然性,保证了软件组织实施项目的成功率。
• CMMl三级,已定义级。在已定义级水平上,所有第二级的要求都已经达到,另外,软件组织能够根据自身的特殊情况及自己的标准流程,将这套管理体系与流程予以制度化。这样,软件组织不仅能够在同类项目上成功,也可以在其他项目上成功。科学管理成为软件组织的一种文化,成为软件组织的财富。
• CMMI四级,量化管理级。在量化管理级水平上,所有第三级的要求都已经达到,另外,软件组织的项目管理实现了数字化。通过数字化技术来实现流程的稳定性,实现管理的精度,降低项目实施在质量上的波动。
• CMMI五级,持续优化级。在持续优化级水平上,所有第四级的要求都已经达到,另外,软件组织能够充分利用信息资料,对软件组织在项目实施的过程中可能出现的问题予以预防。能够主动地改善流程,运用新技术,实现流程的优化。
由上述的5个级别可以看出,每一个级别都是更高一级的基石。要上高层台阶必须首先踏上所有下层的台阶。
作者:335
参考资料 代码中的软件工程 https://gitee.com/mengning997/se














 2475
2475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









