










Spring源码分析从功能到实现
1.Spring核心功能.
官网介绍的spring核心技术,包括以下这么多,包括ioc容器,aopAPIS,spring的切面编程等等.spring框架,很庞大,实现的功能很多,很多细节代码也完善了各种坑.源码慢慢看,设计思路,代码的设计模式,算法,慢慢看.
先理解一下控制反转的思想
https://blog.csdn.net/ivan820819/article/details/79744797,
介绍了ioc思想的由来.简单说就是,为了解决对象之间耦合度的问题.提出了"控制反转思路",由主动获取依赖,变成被动获取依赖,控制权交给别人.
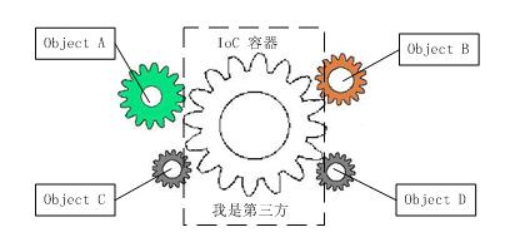
==>获得依赖对象的过程被反转了.
==>齿轮关系图,就很清楚的表达了问题.
==>最后,我们只需要关心,对象本身和容器就可以了.解决了对象之间的耦合性.

2.Spring的主要功能如何实现.
2.1 对象管理
2.1.1 业务分析
主体功能:扫描所有包,获得每一个对象的信息,实例化所有对象,完成依赖的注入,放入容器,等着被调用.
难点:如果只扫描几个类,创建一个容器,再直接管理,这个过程是比较容易的.如果有很多的类,需要管理bean,包括一些jar包.那么就得为容器准备一个合适的创建过程.因为每一个步骤,都有各种小问题需要解决.
如
1.扫描包.整理成beanDefinition
(获取每个对象的信息,依赖信息@autowire,其他配置信息@import.@Bean)
哪些对象可以称为Bean(@component,@resouce),需要不需要对某些bean进行过滤,比如@Conditional
2.什么方式创建对象.
==>构造器?
==>工厂Bean?
1).一些Bean的创建,普通的构造器完成不了功能.
2).一些Bean,想要批量创建,可以使用
==>如果有多个构造器?推断构造方法.
3.依赖关系(set,constructor)
1). 自动装配@Autowire
2). 自动装配4种方式
依赖注入的方式? set方法?构造器方法?(反射也属于set的变体.)
官网有介绍:
https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/core.html#beans-dependencies
4.注入容器
简而言之,需要创建一个合理的过程,完成容器的创建.
2.1.2 需要考虑,解决的问题
这里,关注spring对于业务,设计出来的解决流程.OO思想.设计模式.代码的高效执行(缓存,安全)
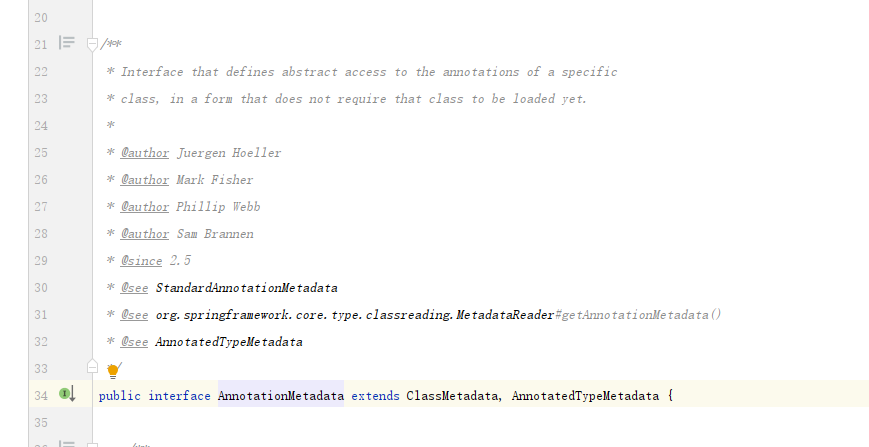
不关心他某些问题的具体处理细节,逻辑代码,比如推断构造方法,asm操作等等.
1.扫描环境,创建所有的beandefinition.
1.我得扫描所有文件,我还得提供接口让用户也能参与扫描文件的过程. 这两个操作有没有先后顺序.?
如果在开过过程中,或者后续扩展过程中,我还需要提前做些.准备工作.而且不仅仅是需要一些扫描,还可能各种初始化配置,等等.
==>spring,抽象出了BeanDefinitionRegistryPostProcessor 这个对象. 专门用来处理创建/整理BeanDefinition的动作.
BeanDefinitionRegistryPostProcessor 是 BeanFactoryPostProcessor 的子类,说明,这个类还可以有配套的后置处理方式.不用创建多个类.
BeanDefinitionRegistryPostProcessor 用面向对象的角度想,这个对象是用来扫描bd的.创建bd.
spring,自己是准备了configurationclasspostprocessor处理扫描,用户自己可以实现这个接口.
加入到这个 创建beanDefinition的过程中去.
那么这里设计的,创建bd的代码,就得保证
1.用户能参与.
那么 BeanDefinitionRegistryPostProcessor,一定不是查询到之后,只执行一次的,先通过一个,找到其他扩展的,那么就得对 BeanDefinitionRegistryPostProcessor 进行扩展,相当于,一个处理内部的,一个处理用户的.
我们可以这样,从容器中,找到我们特殊的BeanDefinitionRegistryPostProcessor,比如,继承更多接口的,order?.依赖这个,先执行我们自己的. 然后再去找用户的.
==>既然用户能参与,那就得我的ioc容器,先找到他们.然后在执行
==>代码如何设计呢?
2.后期可扩展.
已经抽象成BeanDefinitionRegistryPostProcessor动作了,方便扩展
3.创建操作有执行顺序.
DiY_创建bd操作 implements BeanDefinitionRegistryPostProcessor ,order.
或者
DiY_创建bd操作 implements BeanDefinitionRegistryPostProcessor
//伪代码
createbeandefinition(
//1.先执行,ioc初始化过程 Registry BeanDefinitionRegistryPostProcessor
依赖,这个找到,用户添加的BeanDefinitionRegistryPostProcessor.
要不然用户的信息,也不可能加入到容器中.不可能让他提前扫描.
==>所以,这里就是系统先执行自己的BeanDefinitionRegistryPostProcessor,来完成bd的扫描创建
==>比如,去容器找复杂,我们自己的BeanDefinitionRegistryPostProcessor,去完成bd的创建
//2.执行扫描到的 BeanDefinitionRegistryPostProcessor
}
当然,这里的代码,如果更细化,那么可扩展性就能得到提升,具体看源码
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors()


PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
处理bd的核心方法


总结:
以上,完成了 "创建bd" 这个动作的设计.
满足了,程序易扩展(用户可以扩展自己的功能),
易维护(二次开发).
2.spring 如何创建bd的
1.第一种,spring内置的BeanDefinitionRegistryPostProcessor.
spring提供
configurationClasspostProcessor负责完成扫描,这个后置处理器负责找找配置类,然后扫描出来.
ConfigurationClassPostProcessor.postProcessBeanDefinitionRegistry()
==>校验配置类
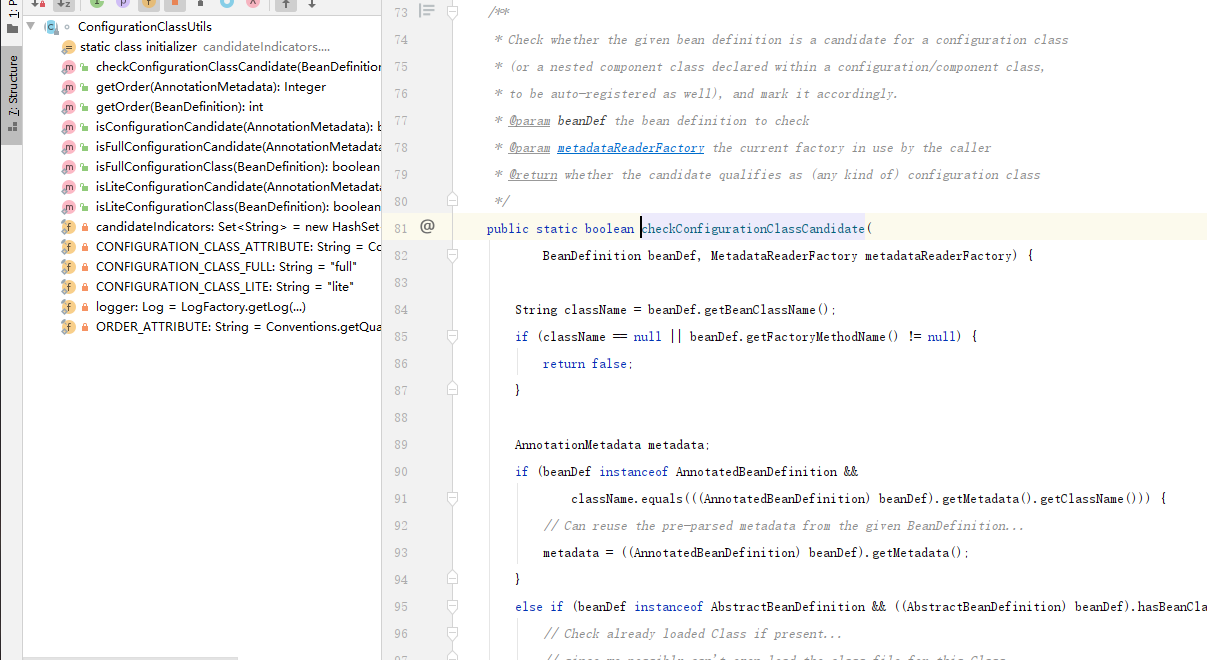
目标:需要校验beanDefinition,是不是配置类. 准备一个ConfigurationClassUtils(容器里有很多bd,要找到配置类)
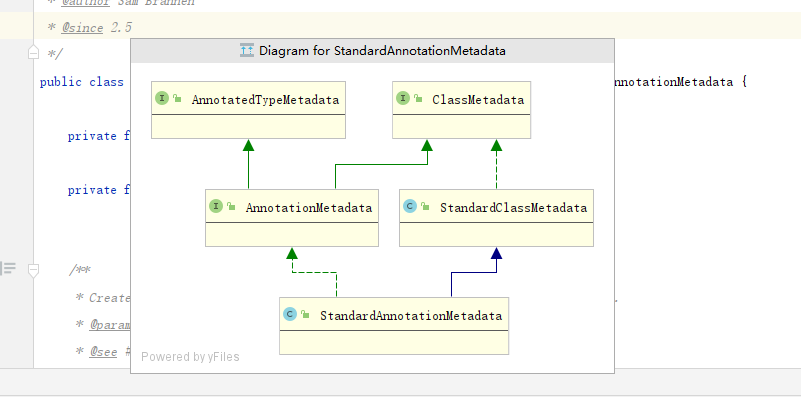
==>元数据载体
目标:解析功能,要分析注解. 创建AnnotationMetadata 的接口,按照功能写具体实现类,或者扩展
创建AnnotationMetadata,职责就是,作为注解数据载体.分析记录Bean相关的注解信息,并且
● 为了服务Annotation AnnotatedElementUtils 创建了工具类. 比如向上递归查找,是否有某
● 为了记录每一个注解的内容,包括注解属性值,提供api获得属性值,或者他就干脆继承了hashmap.把属
性值作为一个整体,按照功能拓展他.AnnotationAttributes
● 当然,为了表达其他功能,比如,排序,比如异常.可以放在一个包里,专门表达注解相关的东西.
==>元数据读取
目标:读取功能 MetadataReader asm操作.
正常我们通过,反射,可以获得类的字节码信息,在获得每一个方法的注解信息. 前提是这个类已经被初始化.
但是,spring的一些工能,不允许我们直接实例化一些类,因为有些类,还没有经过类加载阶段,还是class文件.比如,一些@conditionclass.(x.class) 而且全都反射,也是不安全的操作.还得把所有类都经过类加载阶段.所以,spring,通过asm操作的方式,获得字节文件,再去筛选获得各种原信息. 我们知道,class文件内容,包括,魔数啊,方法表,常量池,每个方法对应的指令,类的各种信息等等,都是16进制文件里.
在你了解class文件结构,就可以通过asm.来操作.==>如果以后需要这种能力,再去看asm框架.
==>解析配置类
目的:需要解析功能,准备一个解析器ConfigurationClassParser.解析配置文件.找到Bean
==>条件功能
因为了提供了 @conditionBean @ConditionClass 功能. 所以,会先校验你这个配置类,该不该解析
ConditionEvaluator 这个类,处理条件问题.当然,校验bean,校验class,直接去容器里找,类加载器里面找.
提供条件筛选功能.
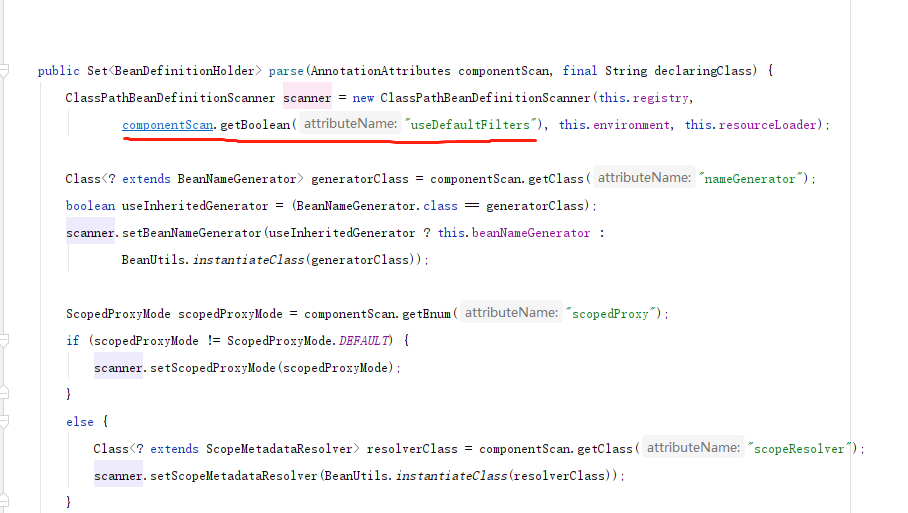
==>扫描功能
目的:提供了@Component 功能,所以得完成批量扫描功能.
● 创建component的扫描器.去负责扫描包.所有,找到符合条件的bean.(@component @configuration. 等等)
ComponentScanAnnotationParser ClassPathBeanDefinitionScanner
● 得进行筛选,(过滤掉非bean的类) 功能
fileter TypeFilter
当我们,自己想要实现扫描包,并且筛选出bean的时候,我们就可以修改这个过滤器规则
这部分代码给人的感觉就是,面向接口编程. 主要核心功能,不变的,写在父类里面,功能大概写在接口里面.
按扩展内容,进行扩展. 比如,mybatis的自定义扫描,就是扩展这里的东西.
● 按照提供的功能@import @import importselector @Bean 写业务代码.
2.第二种,当然就是,BeanDefinitionRegistryPostProcessor 继承合适,接口.然后自己创建bd的.
看到相应框架直接去处理就ok.
校验配置类

元数据载体
元数据读取


扫描配置类
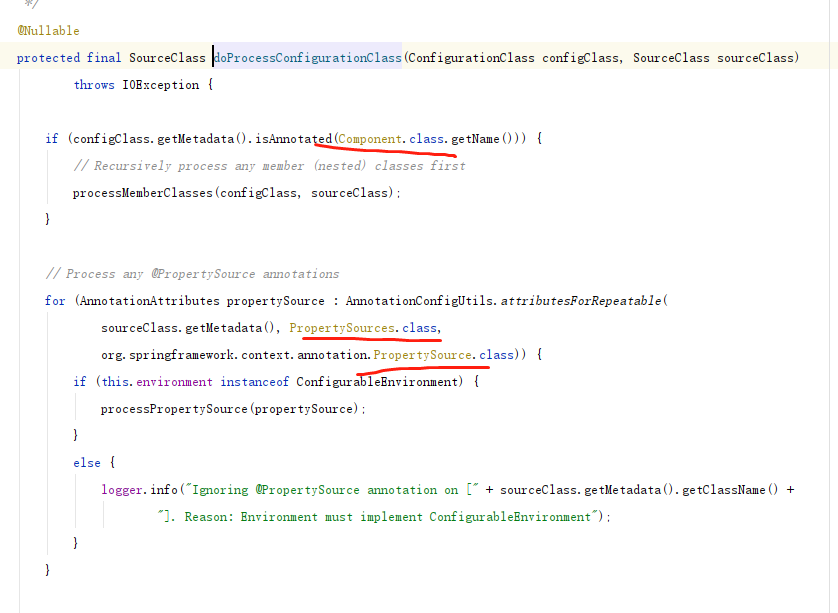



3.spring 通过 beanfactoryPostProcessor 处理,扫描出来的bd
1.前面扫描,创建bd,对bd只是执行了初始赋值. 还可以对bd 进行处理.赋值,以及对beanfactory的数据进行处理.
没看到有什么特殊重要的事.顶多是,对@configuration 的类,创建了代理类. 让@Bean方法获得的对象全局一个.
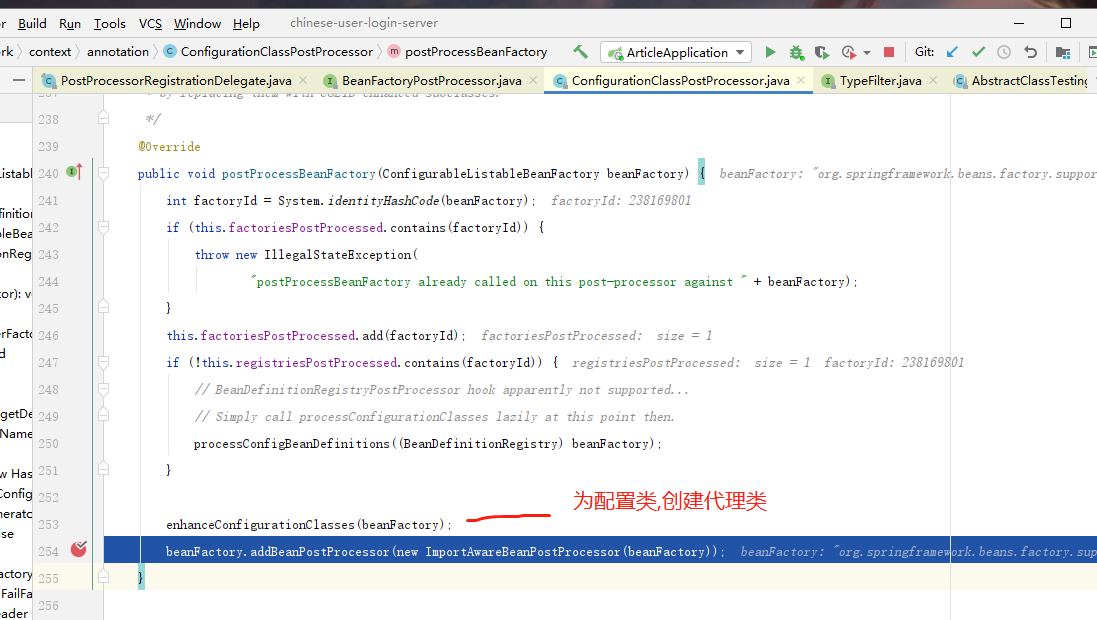
至此,spring的BeanDefinition 的信息,处理完毕.
4.完成Bean的创建
这部分,完成每一个Bean 的创建.如果是,正常面向过程的敲代码,就是,一路执行到底,所有加工过程,一点一点的来.bean的创建是一个复杂的过程,我需要代理,我需要解析注解,我需要找到所有切面,我不想走bean的生命周期,我想添加属性值==>把所有bean的操作,封装成一个一个BeanPostProcessor. 方便扩展,和加入功能.==>oo思想==>Bean对象的创建● 调用构造方法创建.● 如果有多个构造方法就推断 这推断方法,就相当于,一种算法,相当于面对一个业务,如何解决掉.● 如果注入方式是构造器自动注入.那么就执行那些对象的生命周期.==>Bean完成属性注入之前,可以处理的事->创建出来一些bdpp比如InitDestroyAnnotationBeanPostProcessor 完成生命周期回调数据整理 封装成LifecycleMetadata比如AutowiredAnnotationBeanPostProcessor 完成,自动注入内容的完成. 封装成InjectionMetadata可以理解为,在完成注入之前,我提供一些对bean的操作,我可以是整理数据,填充数据 等等.就是对所有bean的操作进行一个分类,提供一个执行顺序,类似BeanDefinitionRegistry的设计.==>Bean属性的注入对用户提供了,几种注入的方式. name class 无,构造方法 @Autowire ==>@Autowire 走的是AutowiredAnnotationBeanPostProcessor 后置处理器,他去完成属性注入,并通过field.set,赋值属性,走的是AutowiredAnnotationBeanPostProcessor去完成获得属性值,以及赋值 ==>自动装配. 通过自省方法,找到自己的set方法,然后bean工厂去找值.这部分功能,可以直接交给beanfactory来做,属于创建对象的范畴. ==>bean的生命周期回调和代理.代理模式: 切面的设计 这个在后面会单独分析.属于嵌入功能.总结: 围绕BeanPostProcessor进行设计.对内,为了完成bean的操作,设计出相应的类和方法.对外,包装成一个某种类型的bean操作.
处理一部分后置处理器.
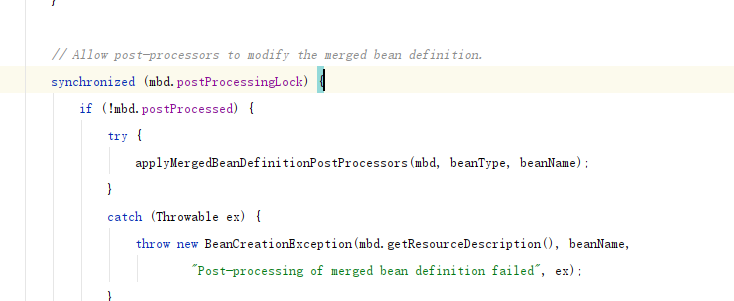
比如InitDestroyAnnotationBeanPostProcessor 为了 整理 LifecycleMetadata 生命周期元数据 . buildLifecycleMetadata(clazz); 构建者模式找到.
AutowiredAnnotationBeanPostProcessor 找到所有 自动注入的元数据@AuwowireInjectionMetadata

AutowiredAnnotationBeanPostProcessor 去完成 @Autowire 内容的注入.提供 字段注入,method注入.成员属性走字段注入,如果是构造方法的自动注入 就是方法上加@autowire 那就走下面那个.把相关功能设计成内部类.AutowiredAnnotationBeanPostProcessor 交给内部类 AutowiredFieldElement 完成注入他需要对象值,那就交给工厂类获得属性值.
交给beanFacoty来完成属性值的创建,合情合理,因为,工厂负责生产对象.负责bean的生命周期
2.1.3 Spring.ioc的大概执行过程.
关键对象:BeanDefinition. 容器中对象的数据结构BeanDefinitionRegistryPostProcessor 依靠这个去扫描文件BeanFactoryPostProcessors BeanDefinition扫描之后,需要的处理BeanDefinitionBeanPostProcessors 完成每一个bean的创建过程.
整个过程:基础对象准备(如beanfactory)------------------------扫描并创建bd------------------- 处理已经注册在beanfactory中的BeanDefinitionRegistryPostProcessor,利用策略模式,执行各种类型的 BeanDefinitionRegistryPostProcessor. 其中: 1).ConfigurationClassPostProcessor 类,完成了各种@configuration@component,@Import,@Bean,各种bean的BeanDefinition的创建. 内部解析器,递归,创建. 2). ------------------------后置处理bd---------------------处理已经注册在beanfactory中的BeanFactoryPostProcessors,利用策略模式,执行各种类型的BeanFactoryPostProcessors1).比如,@configuration,再这里完成了代理.------------------------实例化Bean---------------------执行一系列的后置处理器,完成bean的创建.1).InstantiationAwareBeanPostProcessor 调用这种类型的后置处理器,完成TargetSource类型对象的创建.当然为了完成一些过滤信息的判断,会查询已有bd,并且会把过滤信息进行缓存.2).利用构造器,创建bean. 如果,有多个构造器或者自动装配模式为构造器装配,会推断构造方法.3).创建bean之后,开始解析MergedBeanDefinition,将bean的其他信息,准备好,@Autowire,@Init,等等准备好.4).解决循环依赖,如果支持,就将自己先放入"某种类型工厂" , addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); 先判断,是否允许循环依赖==>向context中,添加factory方法,用来产生bean,防止循环调用逻辑出问题.5).属性注入,自动注入,手动注入都有6).初始化bean,最后一步,完成,生命周期回调,代理对象创建.看代码,就都想出来,不用记他的顺序,只要记"----"部分即可
2.1.4 可以学习的思路
1.OO思想
1.关于BeanPostProcessor接口设计
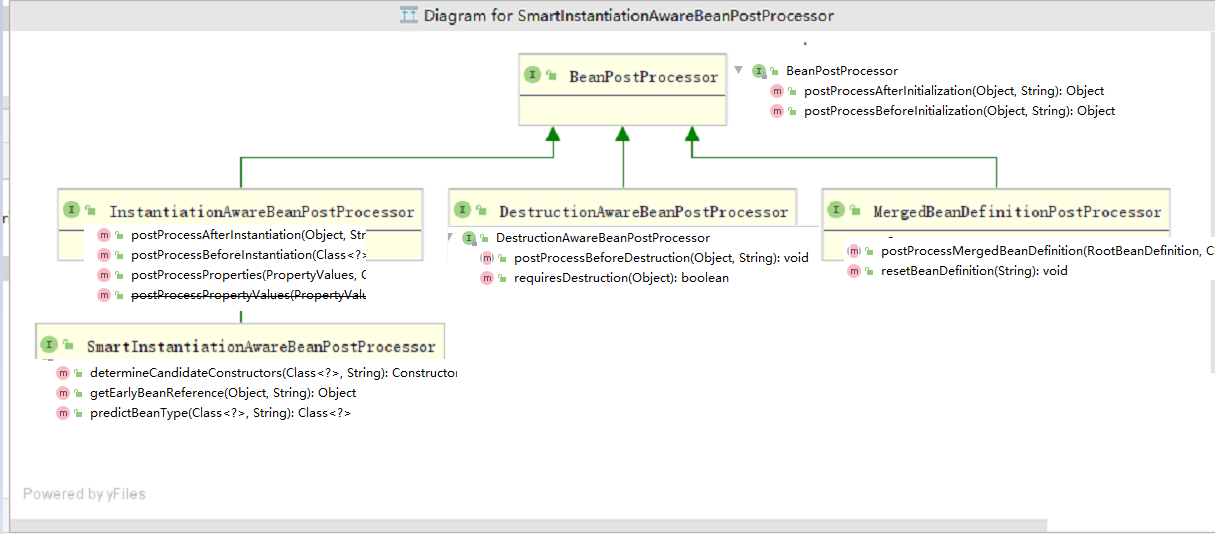

就拿BeanPostProcessor 举例子.
顶级接口 BeanPostProcessor 功能 :实例化之前处理实例化之后处理

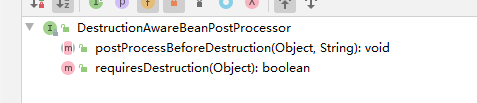
子接口 DestructionAwareBeanPostProcessor 销毁后置处理器功能 :在销毁之前处理是否需要删除
子接口 InstantiationAwareBeanPostProcessor 实例化后置处理器 功能: 实例化之前处理 实例化之后处理 处理属性值.(类的properties,没见有什么特殊的赋值)
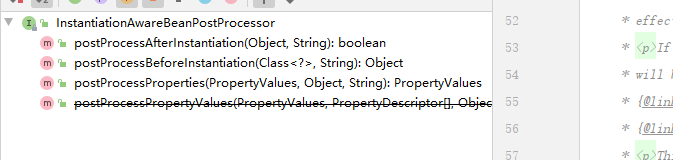
子接口 MergedBeanDefinitionPostProcessor后置处理beandefinition : 处理bd数据用的,比如找到 InjectionMetadata LifecycleMetadata 重置beandefition : 当有一些数据,有问题,想删除什么缓存,想清除什么数据,这就是一个方式.
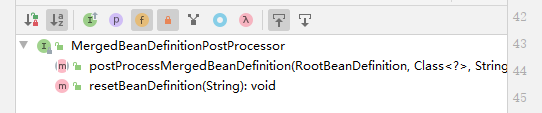
第二层接口 SmartInstantiationAwareBeanPostProcessor 聪明的 实例化 后置处理器添加功能:1.推断备选的构造方法2.getEarlyBeanReference: Obtain a reference for early access to the specified bean, typically for the purpose of resolving a circular reference. 获取指定bean的早期访问引用, 通常用于解析循环引用。3.预测bean的类型. 比如,代理功能,通过beanclass,和beanName,我需要知道原始bean的class 比如,factoryBean,通过beanclass,和beanName,我需要知道原始bean的class或者工厂的class,工厂classname加+比实例化InstantiationAwareBeanPostProcessor更具体的 实例化功能,服务于实例化 的功能.
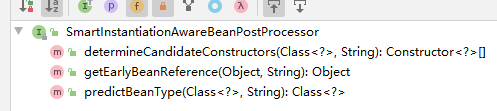
1.描述bean后置处理器的功能. 设置顶层接口,按照要实现的功能,比如实例化,销毁,处理bd,按照功能,设置子接口.>职责 具体化.>如果还能具体化,在添加一层接口.
围绕处理bean的功能,设置一组接口类. 用接口描述功能.
接口类型就相当于一个,类的一个标志,在bean执行生命周期的时候,可以通过这个接口执行具体功能.
该类可以继承其他类,来补充自己的能力,活着继续扩展.看情况定.总而言之,接口可以理解为一种标记
比如bean的生命周期过程:
InstantiationAwareBeanPostProcessor先执行实例化之前的接口方法
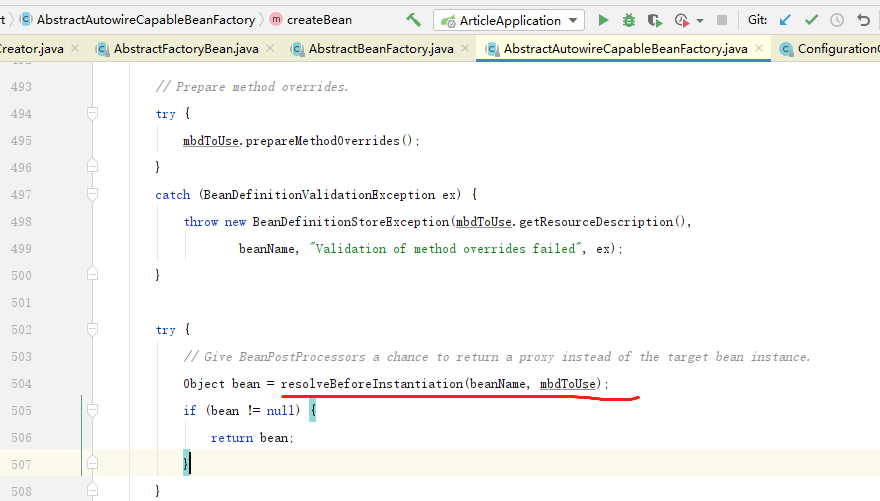

执行MergedBeanDefinitionPostProcessor 相关的接口
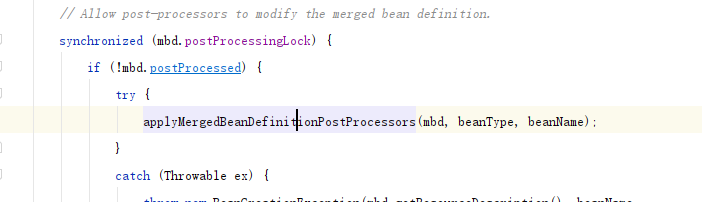
执行smartinstation 相关的

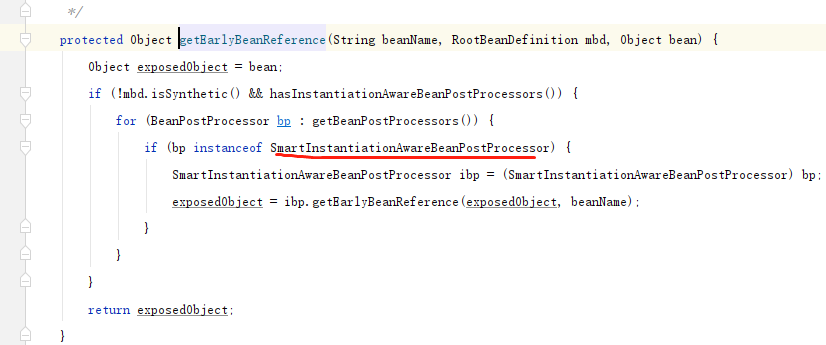
等等.
2. 类,抽象类,的设计.
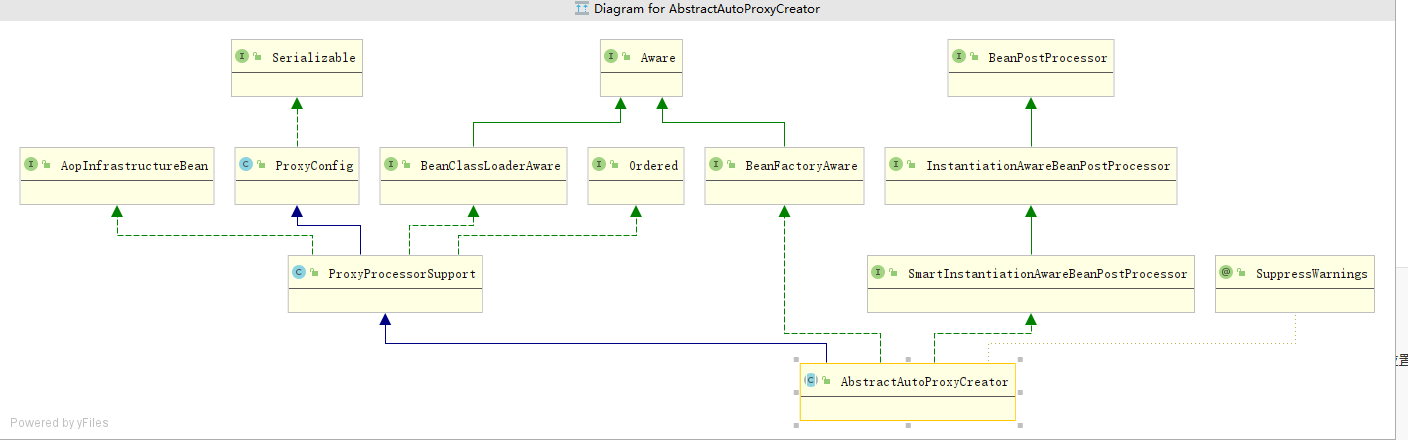
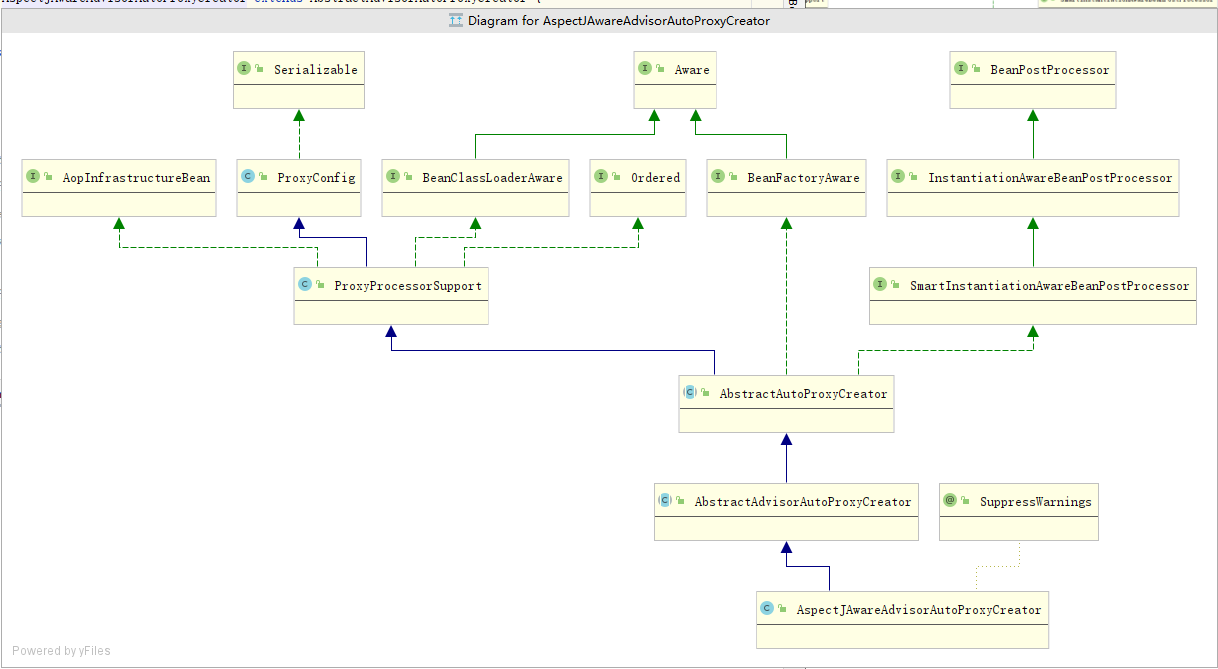
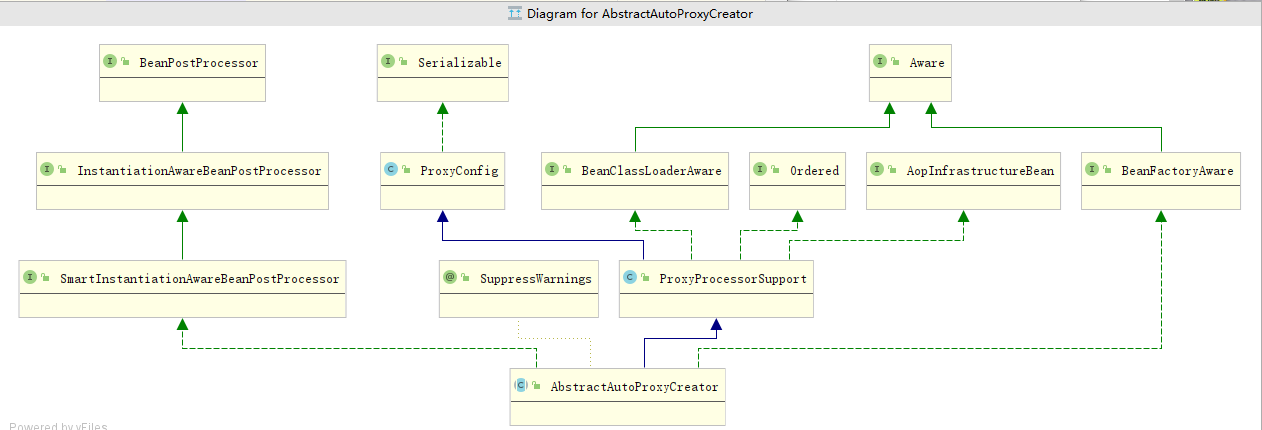
用Proxy,AspectJAwareAdvisorAutoProxyCreator功能举例子.一个服务于切面创建的实现类,他的功能,一定有多个实现者共同完成.全部冗杂在一个类里面,显然要爆炸.先记录他的功能.1.通过他继承的BeanPostProcessor的类型来看,他服务于bean的生命周期阶段.实现接口,标记有这个功能,在spring里面,在合适的时候,被调用.2.AopInfrastructureBean也是为了作为一个标记.作为基础建设类.他会在是否过滤掉的时候,基建类,我也忘了在哪判断,不用多做附加判断. 当做是一个标记.服务于某个功能3.aware 类接口,包括BeanClassloader BeanFactoryAware. 服务于 属性值赋值 功能. spring可以在某个阶段,执行相应的aware接口,完成属性值的赋值. 4.Aop功能==>AopConfigConvenience superclass for configuration used in creating proxies,to ensure that all proxy creators have consistent properties.方便的超类配置用于创建代理,确保所有代理创建者具有一致的属性。Aop功能的基础属性字段 以及字段的set方法 get方法->is方法 直接变成判断了==>ProxyProcessorSupport Base class with common functionality for proxy processors, in particular ClassLoader management and the {@link #evaluateProxyInterfaces} algorithm.具有用于代理处理器的公共功能的基类,特别是类装入器管理和{@link #evaluateProxyInterfaces}算法一些判断功能的类.和基础属性区别开. 这个带有些许计算功能==>AbstractAutoProxyCreatorBeanPostProcessor implementation that wraps each eligible bean with an AOP proxy, delegating to specified interceptors before invoking the bean itself. 用AOP代理包装每个合格bean的BeanPostProcessor实现,在调用bean本身之前委托给指定的拦截器。抽象类,服务于创建代理类.比如,我们完成代理功能. ->需要构建切面 advisors 还得缓存advisor 有切面就得有切点相关的.当然切面可以封装在advisor里面. ->创建代理类. ->判断bean是否需要代理 ->一些beanPostProcessor的功能 ->一些服务于创建代理类需要的属性值 ->各种农判断功能,随着功能越来越完备.会越来越复杂. ==>具体的实现类了,按照功能,再细致 比如AnnotationAwareAspectJAutoProxyCreatorAspectJAwareAdvisorAutoProxyCreatorDefaultAdvisorAutoProxyCreatorInfrastructureAdvisorAutoProxyCreator==>这么理解1.功能嵌入到ioc容器中你要完成代理功能,那么你的代理功能就得实现合适的BeanPostProcessor 加入到bean的生命周期.如果想加入实例化前后,就实现smartinstation,销毁功能,就加入destory,需要在哪里嵌入,就实现什么样的接口.2.代理功能的完成. 完成代理功能,是一个很庞大的过程.比如,你构建了advisor,pointcut,校验,扫描,那么你的功能类就会很庞大.所以要合理"创建"这个功能 ->基础属性拆到一个类 ->基础功能拆到一个类 ->标准工能拆到一个类 ->具体功能,主类创建 我认为这部分,就是实际实现代码的设计了. 最不济通过,面向过程的思路,把代码先顺序执行完,实现功能,在根据设计模式,进行拆分,设计类. 那么基本上,如果底层都知道了,我至少写代码就是个顺序执行的过程.->提代码,大块代码,都可以给他提出来,每一个方法,越短越好,别问我为什么. 哪怕是帧栈消耗过大,也拦不住我->面向对象,利用设计模式,把一些有相同特征的事物,或者围绕一个中心的事务,能提,就提出来.->设计模式,对业务进行设计,利用设计模式,更好的设计之间的关系.写出来合理的代码. 比如 builder思路 Facoty思路.面向功能开发,面向对象开发!!!!!!!
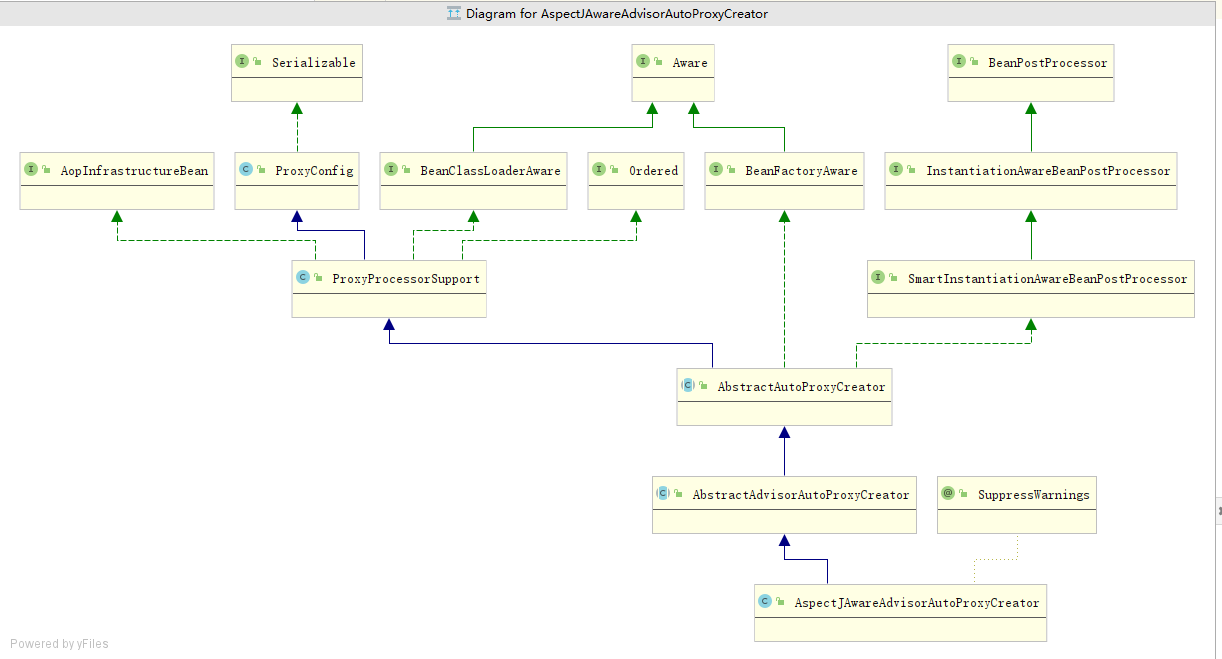
Aopconfig

ProxyProcessorSupport
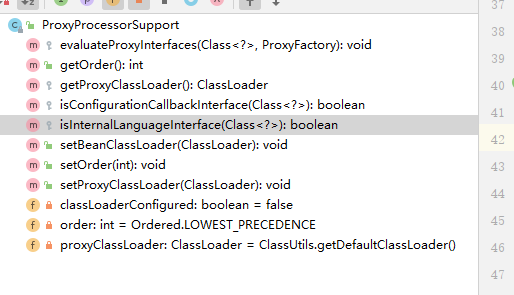
3.接口设计
aware 接口的设计
为了类的一个成员属性的设置.为了完成一批类的成员属性的设置.为了完成的成员属性,在某一个时间段全部设置完.为了,当某个对象创建完,需要赋值给众多类的时候,能够找到这些类,完成功能可以让他们都实现一个接口,找到所有类,同时执行aware的方法.完成设置.接口可以满足一批类的一个功能.接口作为一个标记!!!
AopInfrastructureBean
Marker interface that indicates a bean that is part of Spring's AOP infrastructure. In particular, this implies that any such bean is not subject to auto-proxying, even if a pointcut would match. 也是一个标记作用.
BeanpostProcessor 设计.
3.Spring其他功能的实现.
3.1 Aop切面功能(@Aspect)
3.1.1 功能概述
1.从注解配置角度查看,Aop的功能.@Aspect 切面声明 --> 标记一个切面类.@pointcut 切入点@before @after @.... 修饰方法的 方法的哪个位置插入 他必定得配套切入点信息,因为他修饰怎么通知方法,没说,要通知哪些方法 以上是,aop功能提供的注解.而且还有advisor 方式。2.核心功能aop功能,最后组成的数据结构Advisor 切面PointCut 切点
3.1.2 如何实现
1.切面代码,如何添加到我们的bean中? 1). 在bean的生命周期之后,执行beanPostProcessor的时候,利用动态代理,把切面添加进去。(什么是动态代理,什么是静态代理,代理模式需要完成什么内容,cglib,jdk) 2).在哪添加这个后置处理器??? 他是合实例化之后相关的,所以在生命周期之后,执行对应的后置处理器就行.后置处理器,可以通过@Import, importselector 等方式,加入到容器中2 如何让ioc容器,知道开启了aop功能,并且能完成扫描,完成代理。查看@EnnableAspectJ.. 那个注解就知道了.就通过一个注解,或者什么,触发这个功能.3.当@EnnableAspectJ..开启功能之后,需要找到"基建类",AnnotationAwareAspectJAutoProxyCreator也就是配置切面的类.那么就得找到所有的advisor,以及所有advisor的切面类,以及切面对应的切入点pointcut. 难点在于解析这个匹配关系,咋说得搞点什么算法什么的. 3.如何记录每一个方法的切面情况.在执行每一个bean的生命周期的时候,循环每一个方法,在循环每一个advisor,去匹配他的pointcut.并且缓存.4.当切面已经标记好了,如何执行.利用动态代理,把所有切面封装在一起,作为一个intercept.当代理对象执行的时候,就会执行我们的所有切面.5.方法的切面的执行顺序如何保证.@Before @Aroud @After @Transactional 链式编程+调度器==>这里自己写代码,实现这个链式编程想到这个地步,我们完全可以脱离spring源码,简单的实现一个aspect 功能代码任务: 手写aspect 功能 嵌入到spring功能手动实现,aspectj的功能. 可能实现不了.!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!1.扫描 1).扫描所有的包. ->spring扫描所有包,利用configuration那个后置处理器.在所有已经扫描出来的beanDefin 从容器中包括@CuaAspectJ,利用BeanFacotyUtils找到我们需要的bd ->如果是mybatis扫描bean,就得自己写扫描包了,总不能都加@component吧 ->BeanFacotyutils需要beanFacoty 那就 继承BeanFacoty接口,有这个参数.然后利用工具 类,找到所有beanName. 2).找到Proxy功能的类 比如@AspectJ //spring有这个功能 3).创建基类.2.解析 1).解析基类,找到所有advisor. 2).为advisor,整理pointcut3.创建代理对象 1).递归类的所有方法,找到每一个方法,循环每一个切面,通过切点,缓存所有method对应的切面. (因为切面的切入点是方法级别的) 2).创建代理类,所有的切面封装为一个intercept(内部切面执行顺序,自己写方法控制), 3).执行代理对象
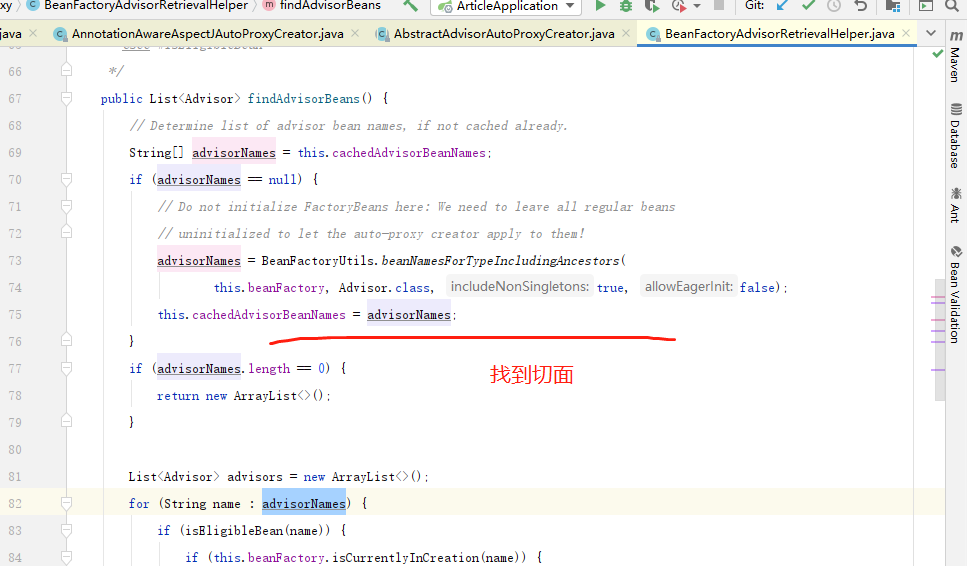
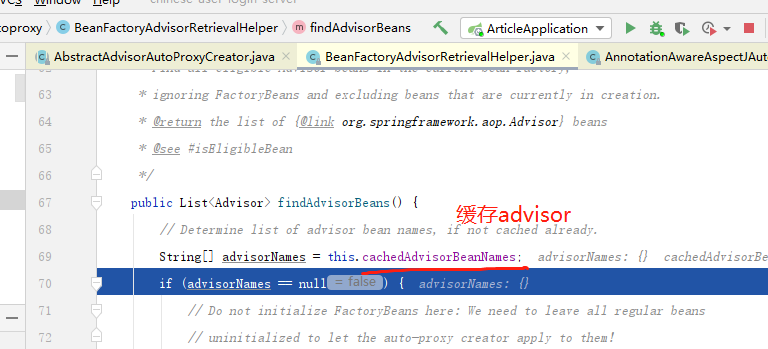
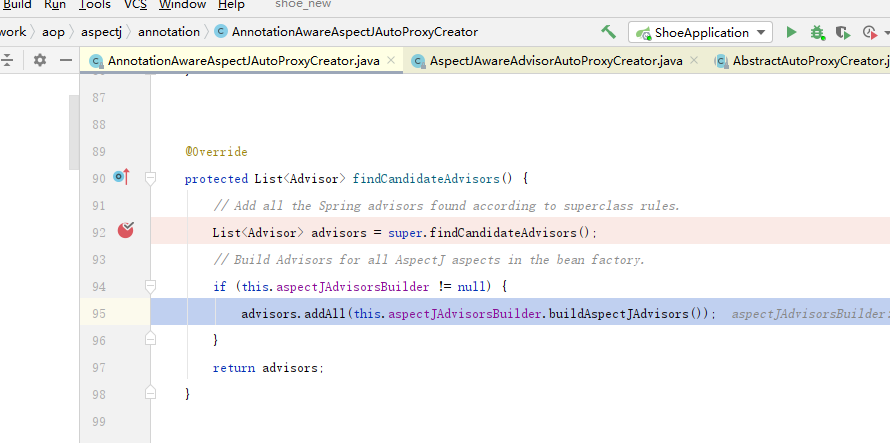
当开启 aspectJ 切面功能的时候. 会注入 AnnotationAwareAspectJAutoProxyCreator 这个后置处理器去完成,扫描Aspect 类型的切面, advisor 类型的切面. ==> 最后都转化成advisor其中,的转化过程.如果细看他的实现,到处都是设计模式,和设计细节.
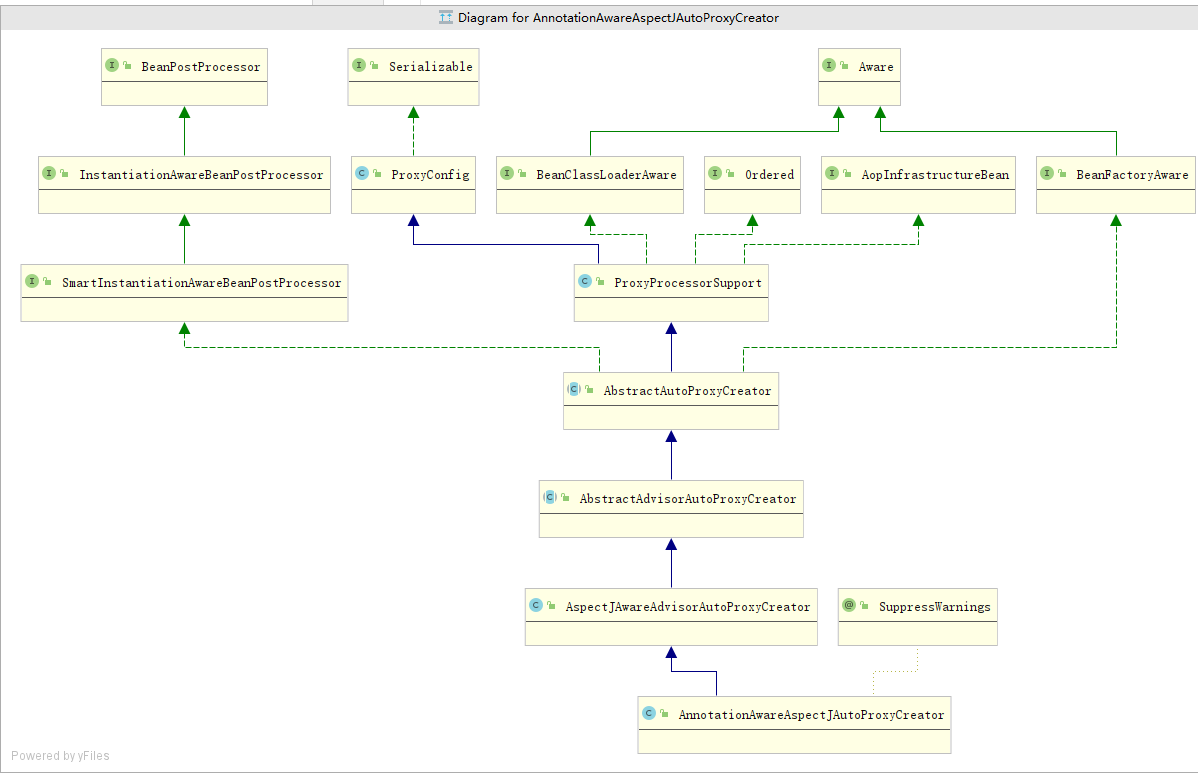
确认是aspect 切面后,将创建advisor 类 放进所有切面中.
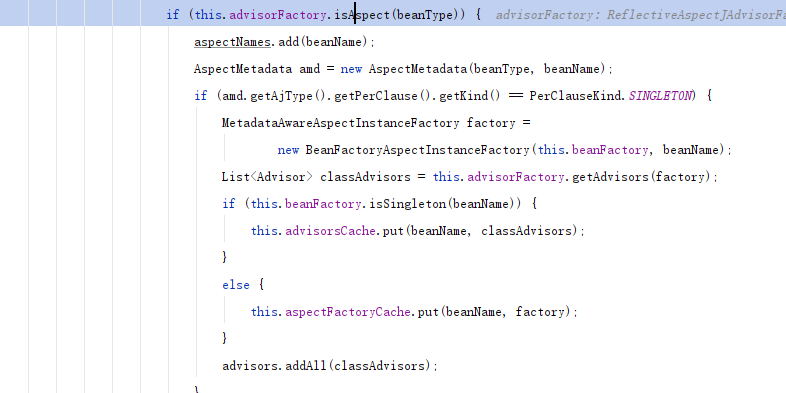
在每一个Bean的生命周期后期,会判断是否需要创建代理类,这个时候,会循环advisor中,去寻找自己的类,
有没有配置切面. (每一个advisor中,的pointcut 的matches 能否匹配到我的类,我的方法.如果有 method<->切面类相对应, 执行方法的时候,会判断,你这个类对应了几个切面,然后按照一定的顺序执行. 创建代理类,会缓存 类对应哪些切面. 缓存,方法对应哪些切面.记不住了,可以debug 切面的执行路线. )

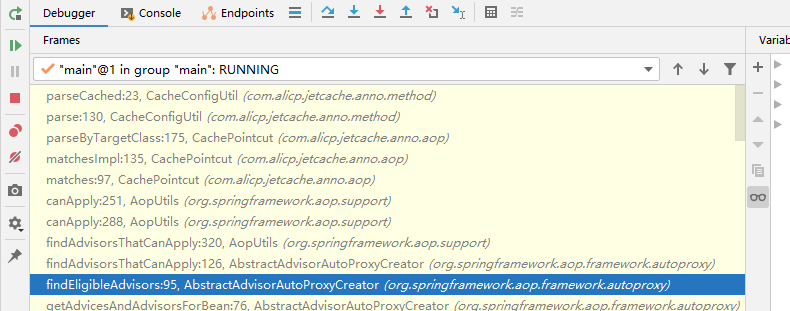
在生命周期之后,进行 advisor->pointcut->matcher->parse 去解决匹配信息,这里代码不想看.头疼.
3.1.3 可以学习的思路
1.在执行切面的时候,链式编程+调度方法
2.method-advisor-pointcut 之间的缓存关系设计.
3.InfrastructureAdvisorAutoProxyCreator . 负责扫描切面信息的创建者的 创建方式可以学习.
通过优先级选择创建者,优先级通过初始化数据获得值. 点方法进去看看就知道了.算是代码技巧了
4.pointcut 类设计(配置缓存类,配置扫描器,OO思想)
5.通用的扫描器,只需要修改过滤器,就可以完成Set parser
3.2 spring事务管理(@Transactional)
功能: 添加@Transactional 完成事务功能.如何实现: ==>实际上,事务功能,就是为bean,再添加一个拦截器就可以了.查看@EnableTransactionalManagement 就知道了.1.创建合适的后置处理器,完成扫描.@Transactional事务的连接事务的隔离级别事务的传播特性,这些都在代码里面当做业务处理就ok了. 比如事务的连接,是放在 DataSourceTransactional啥啥一个同步事务管理里面. threaLocl对象保存的,和mybatis集成的时候,连接就放那儿. 剩下两项,都是业务代码.2.嵌入ioc容器的方式,和aspectj 方式差不多
3.3 缓存功能.
功能: 添加@caching 完成事务功能.如何实现: 本质上,就是在bean上面,添加一个切面. 得自定义扫描器把@caching相关的注解扫描到.看看@EnableCaching是怎么实现的就知道了.
3.4 如何与Mybatis 集成.
3.4.1实现过程
功能: 把Mybatis中,为每一个Mapper准备的DaoMapper,加入到spring容器中,并且能够完成自动注入. String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader);//工厂模式+构建者模式, SqlSession sqlSession = ssf.openSession(); Mapper mapper = sqlSession.getMapper(mapper.class)思路: 0.先明白mybatis中,实例mapper的过程.1.DaoMapper,需要走mybatis的逻辑产生,并且,Mapper的数量很多.-->工厂bean2.扫描mapper包.通过springboot源码包的注解,@MybatisAutoConfiguration 可以看到.通过,各种注解,1.完成sqlSessionfactory的创建.2.每一个mapper,是通过扫描器扫描出来(扫描器继承spring的,然后改过滤器就行了),添加到bdmap中.他们的MapperFactoryBean.bd信息,改成factory类型,需要的参数,也放进去. 某些需要的参数,还利用自动装配(byType,byname)的方式注入进去.比如sqlsessiontemplate.这样,mybatis的数据,就导入到每一个bean中了.直接通过getObject,就可以获取对象.
3.4.2 可以学习的思路
1.MapperFactoryBean的构建思路.->factoryBean 的应用.
3.5 feign 与 Spring 集成.
功能: 从feign的功能上看.他完成了调用端的负载均衡.以及结合了hystrix等功能. 说白了,就是被代理了. 那么这个bean,如何加载到spring容器中,如何完成代理了呢??思路1: 如何需要完成代理,可以想到aop功能,仿造@Transactional的方式, 添加一个advisor,配置好切点.feign数据,通过一个类似事务管理器的东西保存. pointcut 的匹配功能,还得准备匹配缓存,匹配方法,匹配路径,好麻烦. 工程量太大配置一个扫描器,将bd扫描进spring容器.思路2: 使用factoryBean的方式,工厂bean的方式,创建bean. 工厂bean可以在getObject中,完美用自己的构建方式. 需要自定义的配置一个扫描器,扫描出来bd. 这样改动量最小.类似 Mybatis 的整合方式.
3.6 SpringMVC 源码
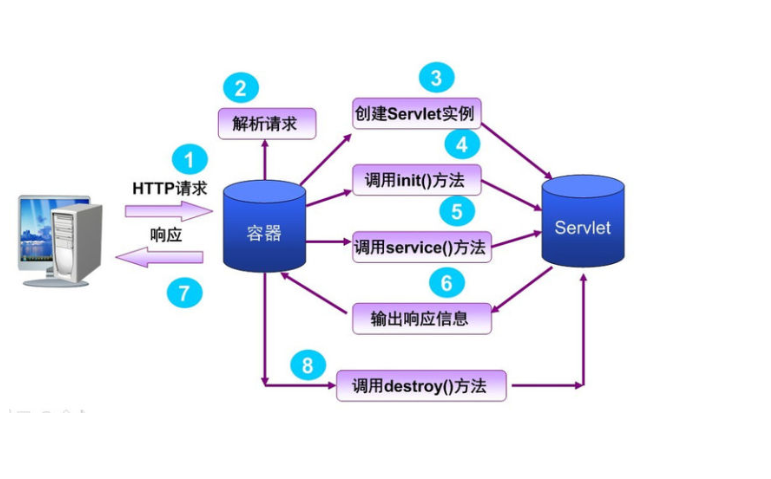
功能: 把web应用服务器封装的Servlet,转化为spring可以使用的"reqiest对象" springmvc,解决了:HandlerMappingHandlerAdapterHandlerExceptionResolver ViewResolverLocaleResolver, LocaleContextResolverMultipartResolver 在我理解,就是一个服务框架,完成各种功能,将servlet,处理的httpRequest 对象 给用户使用.如何和spring容器整合? 如何扫描的controller数据,封装成合适的map?
3.7 Tomcat 与 Spring
tomcat功能: 通过看 startup.bat 文件,还有启动的main方法,大概了解他的初始化过程,他的主要目的是,获得计算机某个端口的监听权. 当端口有http请求访问的时候,将信息,转化为,java程序可以用的servlet.==>springboot如何和这部分整合? ==>tomcat中,哪些设计可以学?==>tomcat,解决了哪些问题?用了什么方法?线程池处理请求















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









