







一、子查询
1. 作为计算字段使用子查询
使用子查询的另一方法是创建计算字段。假如需要显示 customers表中每个客户的订单总数。订单与相应的客户ID存储在 orders 表中。
为了执行这个操作,遵循下面的步骤。
(1) 从 customers 表中检索客户列表。
(2) 对于检索出的每个客户,统计其在 orders 表中的订单数目。
正如前两章所述,可使用 SELECT COUNT ( *) 对表中的行进行计数,并且通过提供一条 WHERE 子句来过滤某个特定的客户ID,可仅对该客户的订单进行计数。
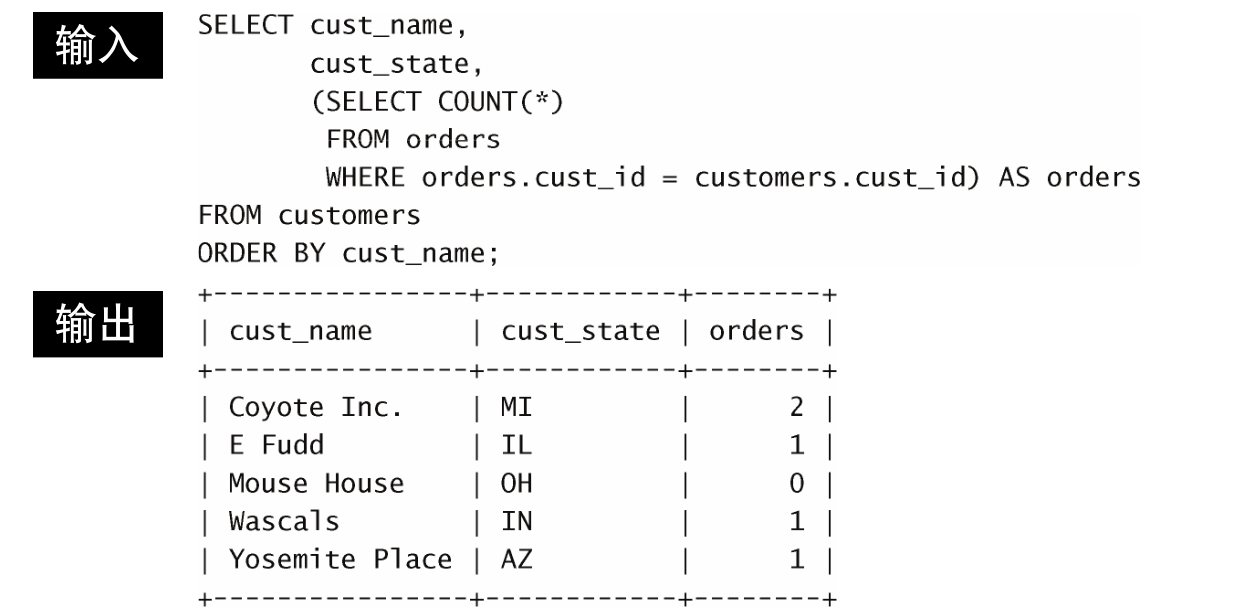
这 条 SELECT 语 句 对 customers 表 中 每 个 客 户 返 回 3 列 :cust_name 、 cust_state 和 orders 。
orders 是一个计算字段,它是子查询建立的。该子查询对检索出的每个客户执行一次。在此例子中,该子查询执行了5次,因为检索出了5个客户。
子查询中的 WHERE 子句与前面使用的 WHERE 子句稍有不同,因为它使用了完全限定列名。下面的语句告诉SQL比较orders 表中的 cust_id 与当前正从 customers 表中检索的 cust_id :
where orders.cust_id = customers.cust_id
-- 查询工资最多的员工的信息
SELECT * FROM emp
WHERE emp.`salary`=(
SELECT MAX(emp.`salary`)
FROM emp
);
-- 查询员工工资小于平均工资的人
SELECT * FROM emp
WHERE emp.`salary` <(
SELECT AVG(emp.`salary`)
FROM emp
);
-- 查询财务部门、销售部门的所有员工信息
SELECT * FROM emp
where emp.dept_id
IN
(select id from dept
where dname='财务部' or dname='销售部'
);
练习
– 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
select t1.ename,t1.joindata,t2.dname
from ( select ename,joindata from emp where emp.joinname > '2011-11-11') t1, dept t2
where t1.deptId = t2.id;
-- 3.查询员工姓名,工资,工资等级
/*
分析:
1.员工姓名,工资 emp 工资等级 salarygrade
2.条件 emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary
emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary
*/
SELECT
t1.ename ,
t1.`salary`,
t2.*
FROM emp t1, salarygrade t2
WHERE t1.`salary` BETWEEN t2.`losalary` AND t2.`hisalary`;
-- 5.查询出部门编号、部门名称、部门位置、部门人数
/*
分析:
1.部门编号、部门名称、部门位置 dept 表。 部门人数 emp表
2.使用分组查询。按照 emp.dept_id 完成分组,查询 count(id)
3.使用子查询将第2步的查询结果和dept表进行关联查询
*/
SELECT dept_id,COUNT(id) renshu
FROM emp
GROUP BY dept_id;
SELECT
t1.`id`,t1.`dname`,t1.`loc`,t2.renshu
FROM
dept t1,
(SELECT dept_id,COUNT(id) renshu FROM emp GROUP BY dept_id) t2
WHERE
t1.id=t2.dept_id;
-- 6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
/*
分析:
1. emp.mgr = emp.id
2. 在同一张表 emp表中查询
3. emp t1与 emp t2,t1 左外连接 t2,即使没有领导也查出来
*/
-- 内连接了自身(等值连接)
SELECT t1.id as 员工id, t1.name as 员工姓名, t2.id as 领导id, t2.name as 领导姓名
FROM emp t1,emp t2
WHERE t1.`mgr`=t2.`id`;
-- 外连接了自身(左外连接)
SELECT t1.id as 员工id, t1.name as 员工姓名, t2.id as 领导id, t2.name as 领导姓名
FROM emp t1 LEFT OUTER JOIN emp t2
ON t1.`mgr`=t2.`id`;
二、连接查询
按功能分类:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接
右外连接
全外连接
交叉连接
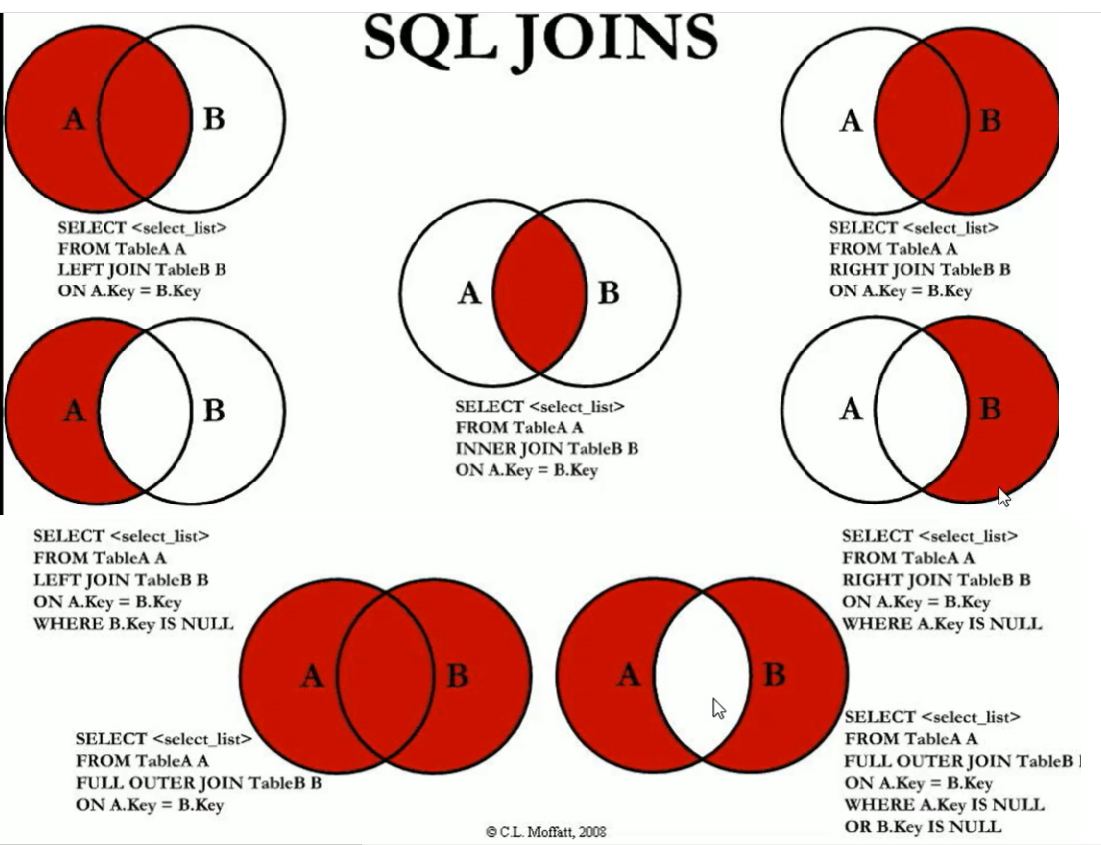
应该总是提供联结条件,否则会得出笛卡儿积。
- 隐式内连接:使用where条件消除无用数据,where根据等于判断,就是等值连接
-- 例子:
-- 查询所有员工信息和对应的部门信息
SELECT * FROM emp,dept WHERE emp.ept_id = dept.id;
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
SELECT t1.name, t1.gender, t2.name
FROM emp t1,dept t2
WHERE
t1.`dept_id` = t2.`id`;
#案例:查询每个工种的工种名和员工的个数,并且按员工个数降序
SELECT job_title,COUNT(*)
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`
GROUP BY job_title
ORDER BY COUNT(*) DESC;
#7、可以实现三表连接?
#案例:查询员工名、部门名和该部门所在的城市
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`
AND city LIKE 's%'
ORDER BY department_name DESC;
- 显式内连接:INNER JOIN [表名] …ON [条件]
-- 语法: select 字段列表 from 表名1 [inner] join 表名2 on 条件
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`;
-- 3. 内连接查询:
1. 从哪些表中查询数据
2. 条件是什么
3. 查询哪些字段

- 外连接:如果主表中想要查询的条件值不在本表中,在另一个表中,可以使用外连接与另一个表进行连接
-- 左外连接:左边的是主表
SELECT emp.`ename`,dept.`dname`
FROM emp
LEFT OUTER JOIN dept
ON emp.`dept_id`=dept.`id`;
-- 右外连接: 右边是主表
SELECT emp.`ename`,dept.`dname`
FROM emp
RIGHT OUTER JOIN dept
ON emp.`dept_id`=dept.`id`;
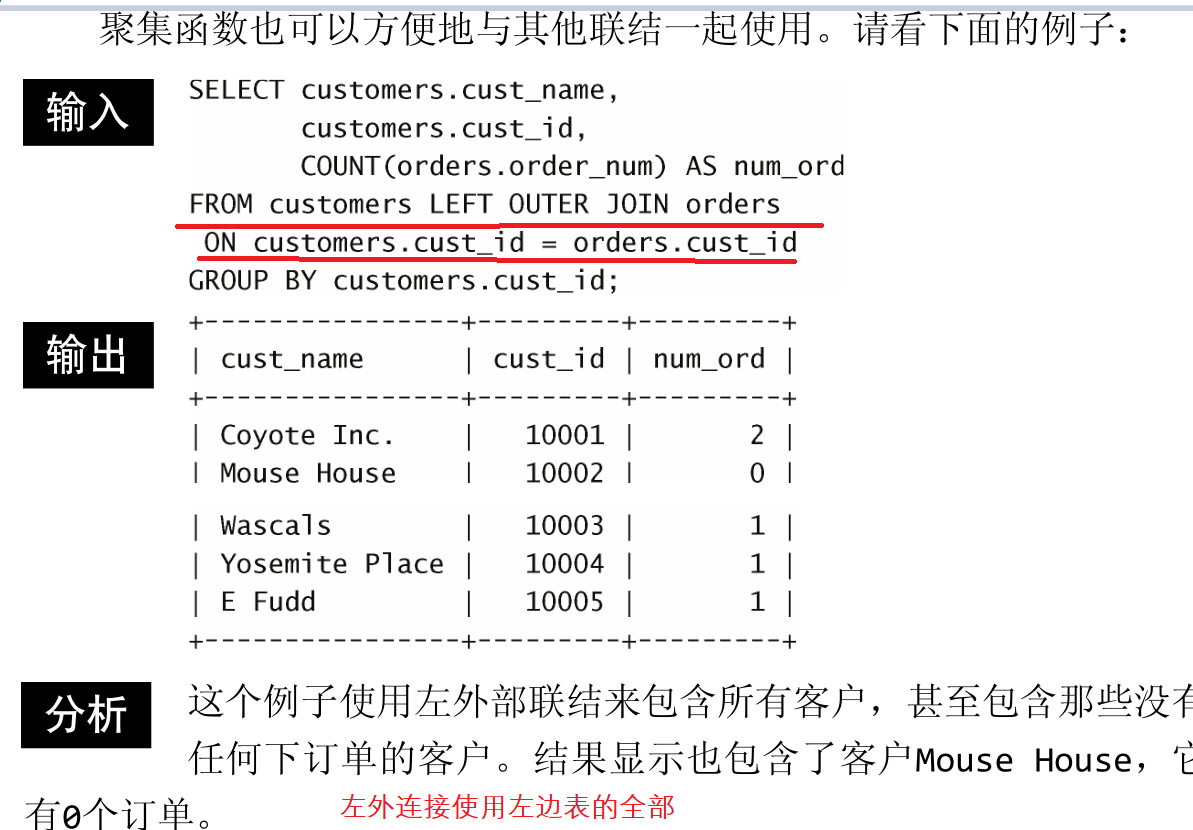
- 全外连接:Full outer jion
查询结果=内连接结果+主表中有但从表中没有的字段+主表中没有但从表中有的字段
- 交叉连接:cross join 两表进行笛卡尔乘积
三、组合查询 :UNION
多数SQL查询都只包含从一个或多个表中返回数据的单条 SELECT 语句。MySQL也允许执行多个查询(多条 SELECT 语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)。
有两种基本情况,其中需要使用组合查询:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
组合查询和多个 WHERE 条件 多数情况下,组合相同表的两个查询完成的工作与具有多个 WHERE 子句条件的单条查询完成的
工作相同。换句话说,任何具有多个 WHERE 子句的 SELECT 语句都可以作为一个组合查询给出,在以下段落中可以看到这一点。
这两种技术在不同的查询中性能也不同。因此,应该试一下这两种技术,以确定对特定的查询哪一种性能更好。
1. 使用UNION
UNION 的使用很简单。所需做的只是给出每条 SELECT 语句,在各条语句之间放上关键字 UNION 。
举一个例子,假如需要价格小于等于 5 的所有物品的一个列表,而且还想包括供应商 1001 和 1002 生产的所有物品(不考虑价格)。当然,可以利用 WHERE 子句来完成此工作,不过这次我们将使用 UNION 。
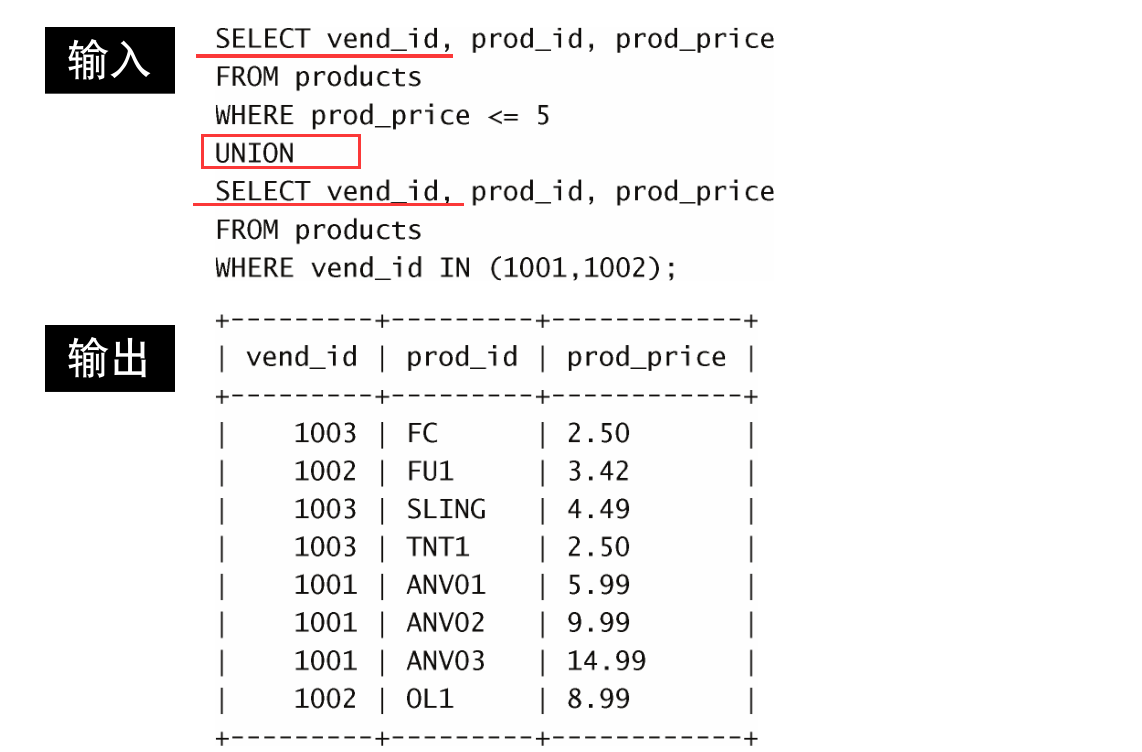
这条语句由前面的两条 SELECT 语句组成,语句中用 UNION 关键字分隔。 UNION 指示MySQL执行两条 SELECT 语句,并把输出组
合成单个查询结果集。

2. 使用Union的规则
-
UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关
键字 UNION 分隔(因此,如果组合4条 SELECT 语句,将要使用3个
UNION 关键字)。 -
UNION 中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
-
列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
-
如果遵守了这些基本规则或限制,则可以将并用于任何数据检索任务。
4. 包含或取消重复的行
请返回到17.2.1节,考察一下所用的样例 SELECT 语句。我们注意到,在分别执行时,第一条 SELECT 语句返回4行,第二条 SELECT 语句返回5行。但在用 UNION 组合两条 SELECT 语句后,只返回了8行而不是9行。UNION 从查询结果集中自动去除了重复的行(换句话说,它的行为与单条 SELECT 语句中使用多个 WHERE 子句条件一样)。
因为供应商 1002 生产的一种物品的价格也低于 5 ,所以两条 SELECT 语句都返回该行。在使用UNION 时,重复的行被自动取消。
这是 UNION 的默认行为,但是如果需要,可以改变它。事实上,如果想返回所有匹配行,可使用 UNION ALL 而不是 UNION 。
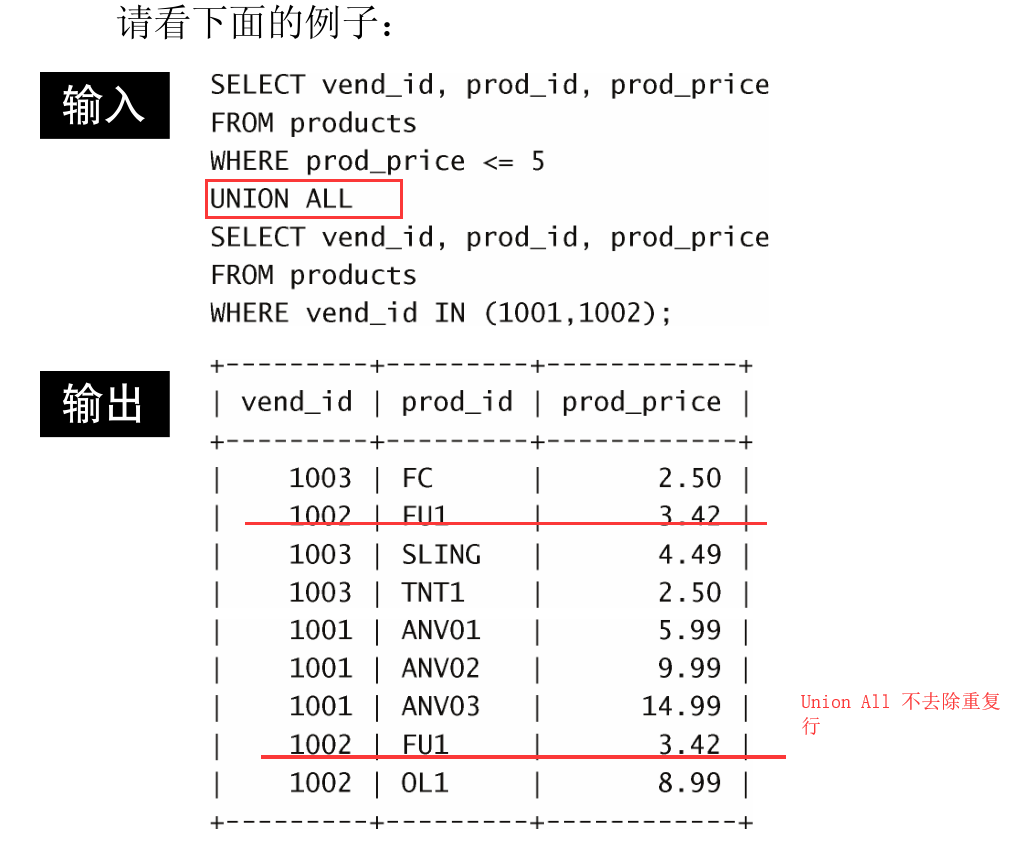
5. 对组合查询结果排序
SELECT 语句的输出用 ORDER BY 子句排序。在用 UNION 组合查询时,只能使用一条 ORDER BY 子句,它必须出现在最后一条 SELECT 语句之后。
对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条 ORDER BY 子句。

这条 UNION 在最后一条 SELECT 语句后使用了 ORDER BY 子句。虽然 ORDER BY 子句似乎只是最后一条 SELECT 语句的组成部分,但实际上MySQL将用它来排序所有 SELECT 语句返回的所有结果。

















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











