









1.迁移和元数据(migrations&metadata)
迁移是负责重新创建同样的数据库架构,每个迁移都有两个名为up.sql和down.sql的文件来表示,其中包含了一些sql脚本,up.sql包含了当你应用某些特定的迁移时应该执行这些脚本,例如:
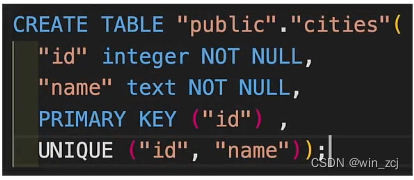
down.sql包含了当你想要回滚时应该执行的的脚本,例如:
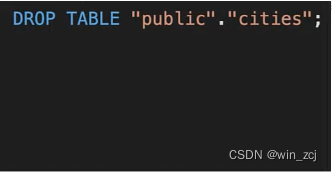
除了迁移我们还有很多其他的东西需要追踪,例如:权限(permissions)、关联关系(relationships)、事件触发器等和其他用于描述暴露数据API的东西,但它们并不属于迁移,因为它们不是数据库,而这些正是元数据发挥作用的地方,元数据是由元数据文件夹下的yml文件,或者说是由元数据文件夹表示的
2.终端hasura-cli
终端安装有两种方式:
- 一种是直接安装,具体方式可以在官网进行查看:hasura-cli
- 另外一种方式是在
docker-compose.yml里面进行配置
version: '3'
services:
...
hasura:
image: hasura/graphql-engine:latest.cli-migrations-v3
...
volumes:
hda-data:
latest是hasura最新的版本,v3是终端的版本
docker方式的配置可以进入到hasura的容器中进行验证,输入:hasura-cli,也可以直接使用docker-compose exec hasura hasura-cli
可以通过运行hasura-cli version查看cli版本
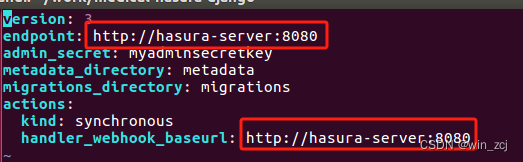
通过运行hasura-cli init 进行初始化,在初始化之前可以先在config.yml文件里面进行配置迁移和元数据的文件夹路径和执行地址
version: 3
endpoint: http://hasura:8080
admin_secret: myadminsecretkey
metadata_directory: metadata
migrations_directory: migrations
actions:
kind: synchronous
handler_webhook_baseurl: http://hasura:8080
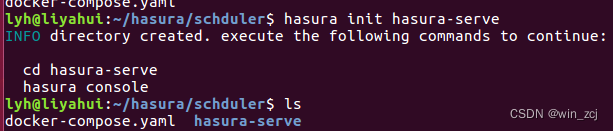
在工作目录下或者在容器里面进行初始化:
hasura init [文件夹名称]
例如:hasura init hasura-server
3.元数据导出
在hasura终端下执行:hasura metadata export
在metadata文件夹下的action.graphql文件会添加hasura的执行脚本,对应的yml文件里面都会生成元数据的可执行脚本语句
4.检查迁移和元数据状态
在hasura终端下执行:hasura migrate status
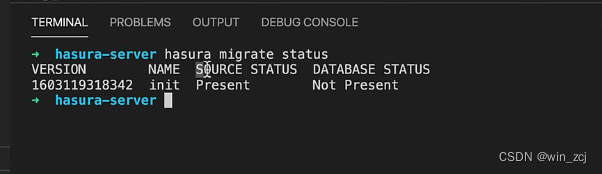
源码状态Present意味着这个迁移在我们的源代码或迁移文件夹中存在,如果看到Not Present意味着该迁移已经在服务器上应用,但在源代码中并不存在,数据库状态显示不存在意味着虽然迁移存在,它还没有应用到数据库中,因为hasura amie grade create 只创建了迁移,但还没有应用它。为了同步源代码的数据库我们必须应用迁移来做到这一点,通常情况下我们只需要执行
hasura migrate apply
但在特殊情况下直接执行将会报错,因为hasura运行迁移脚本试图重新创建已经存在的表
有两种方法来解决这个问题:
- 可以删除数据库然后重启docker容器
- 在执行apply后面添加标志
hasura migrate apply --skip-execution --version 1603119318342
这样将标记迁移为已应用,当执行应用的时候它会跳过执行,但还须明确定义迁移的版本,再次执行 hasura migrate status 这时我们可以看到,迁移现在已经存在源代码和数据库中了。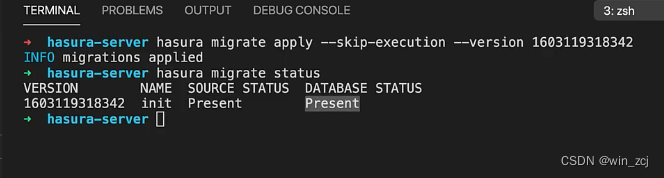
另外,我们不仅可以从本地迁移到本地的hasura实例上,而且还可以迁移到远程上,只需要复制远程hasura/granphql-engine地址
hasura migrate apply --endpoint http://xxx.xxx.xxx.xxx:8080
然后我们可以刷新一下hasura的web服务查看一下,可以看到表已经在web服务中存在,但是它们没有被公开,也没有暴露在图形化中,因为这是元数据的任务。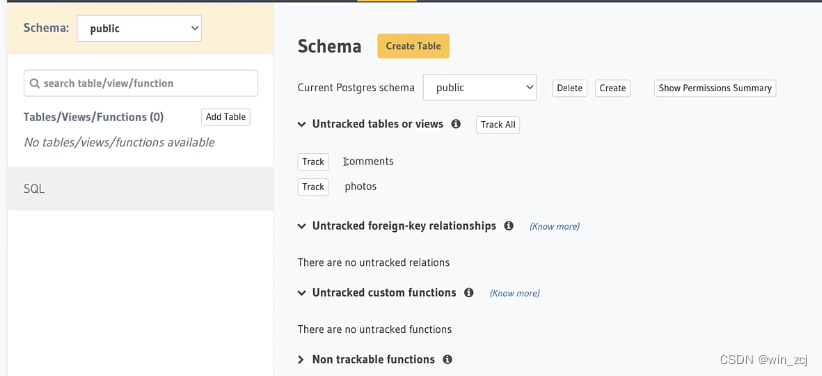
5.怎样应用元数据
- 查看源代码中的元数据metadata定义与应用的不同之处
为了看到区别,可以使用命令:hasura metadata diff
你也可以定义一些具体的文件进行查看,例如:action.yml文件
hasura metadata diff action.yml
- 应用元数据
具体应用元数据我们只需要执行:
hasura metadata apply
如果想要应用到远程上,也可以像执行migration那样添加地址即可:
hasura metadata apply --endpoint http://xxx.xxx.xxx.xxx:8080
执行完成后我们可以再次到web服务端刷新页面查看,这时候表已经加载到granphql-engine里面了
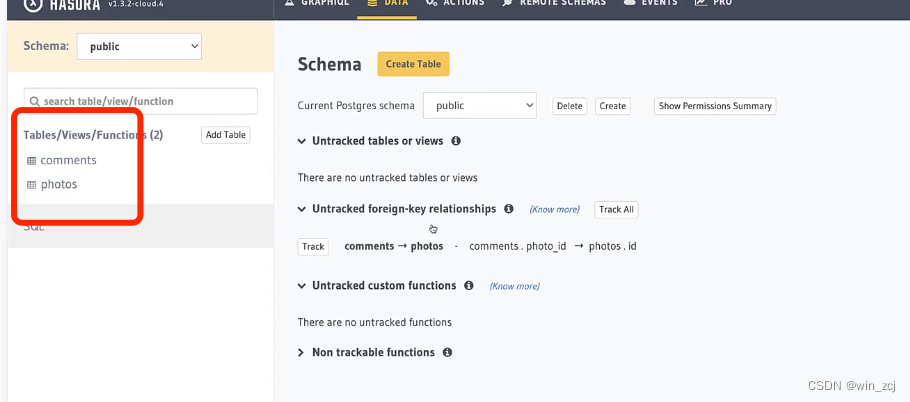
6.如何保留元数据和迁移数据
当我们开发新功能的时候,我们的数据库模式和元数据肯定会发生变化,我们应该保持这些变化始终与我们的迁移保持同步,因为,如果我们错过了至少一个迁移步骤,而不是让开发者进行改变,一种方式是,我们可以通过终端控制台运行命令,hasura migrate create test这样会生成一个带有时间戳的test迁移文件夹,里面包含了up.sql和down.sql两个文件,我们可以在up.sql文件中写自己的sql语句创建表结构或者插入一些数据,但这样会耗费大量的时间,而且也容易出错,然而有一种更好的选择,我们可以在命令行输入hasura console然后会被重定向到一个web控制台,也就是graphql的web页面服务端,当然我们还可以指定一个端口来启动web服务控制台hasura console --console-port 18080,以这种方式打开的控制台我们在上面的操作都会被记录,对数据库和元数据所做的每一个改变都会产生一个新的迁移文件夹和元数据同步
上述以及下面的所有操作都是在本机安装了hasura-cli终端的前提下完成的,如果是docker-compose.yml中配置的hasura-cli终端
我们可以根据官方给出的文档来实现外部的访问,官方文档:hasura console
# Start console:
hasura console
# Start console on a different address and ports:
hasura console --address 0.0.0.0 --console-port 8080 --api-port 8081
# Start console without opening the browser automatically
hasura console --no-browser
# Use with admin secret:
hasura console --admin-secret "<admin-secret>"
# Connect to an instance specified by the flag, overrides the one mentioned in config.yaml:
hasura console --endpoint "<endpoint>"
# Connect to HGE instance running in a container when running CLI inside another container:
hasura console --endpoint <container network endpoint, like: http://host.docker.internal:8080> --no-browser --address 0.0.0.0 --console-hge-endpoint http://0.0.0.0:8080
--endpoint <container network endpoint, like: http://host.docker.internal:8080>此处是容器内的地址,即在config.yml文件中的配置地址
最后在docker-compose.yml中把9695的端口映射到外部就可以了
例如我像改变某个字段的属性和权限
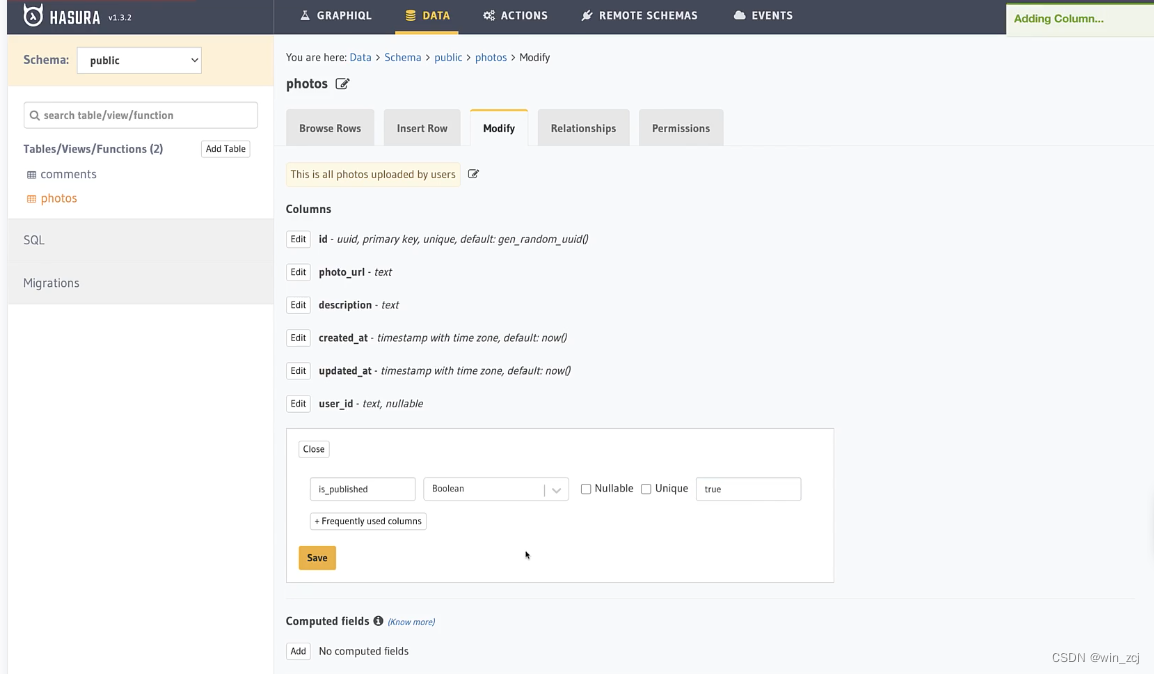
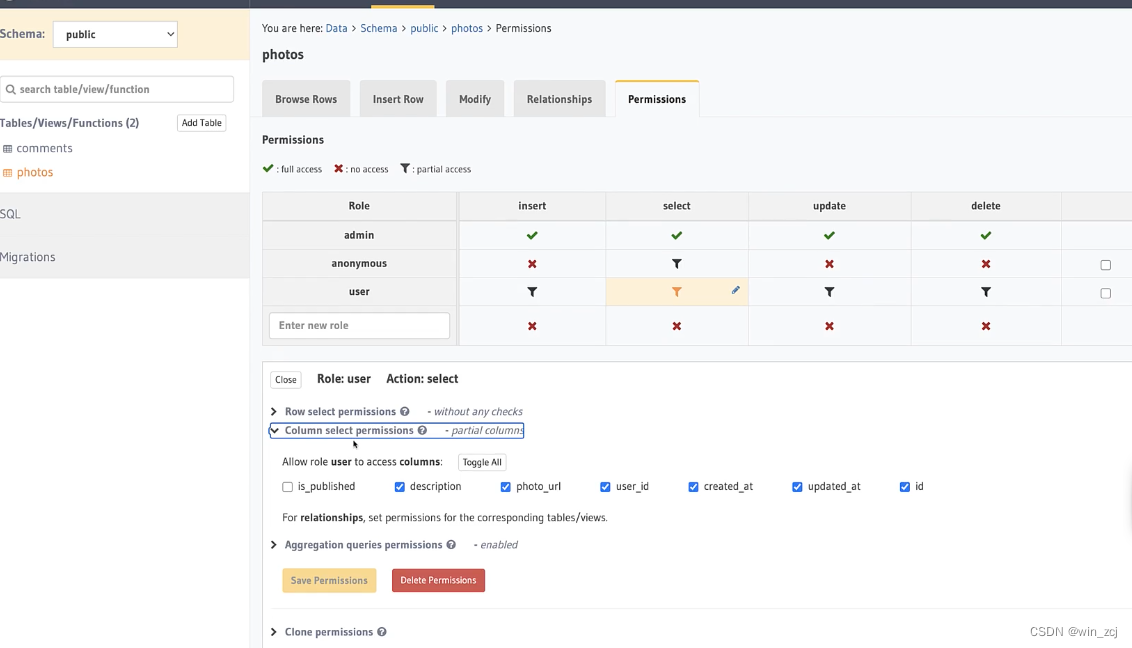
修改保存后我们可以回到项目里面,这时migrations文件夹下已经生成了一个新的迁移文件夹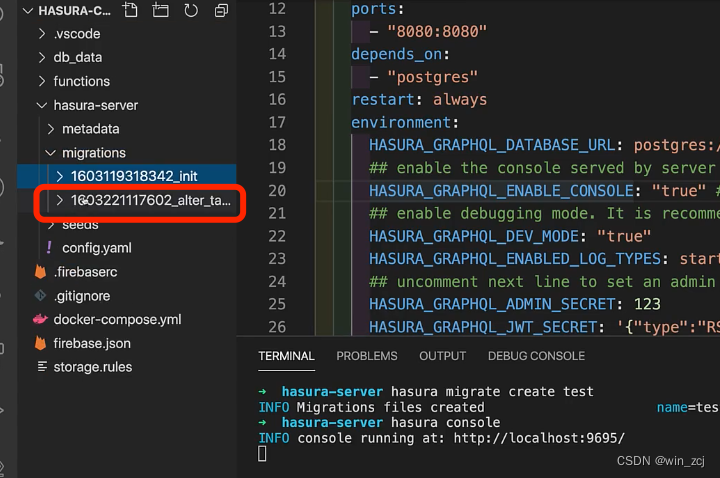
在up.sql文件中是我们要修改为的字段属性
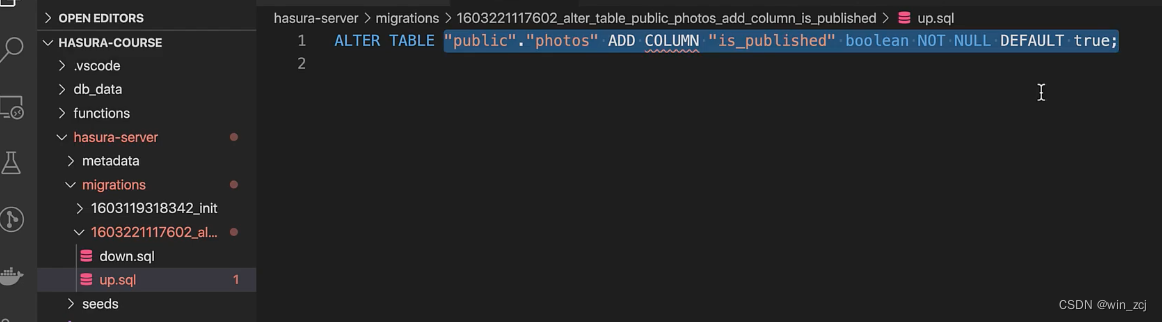
在down.sql文件中是我们移除的字段属性语句
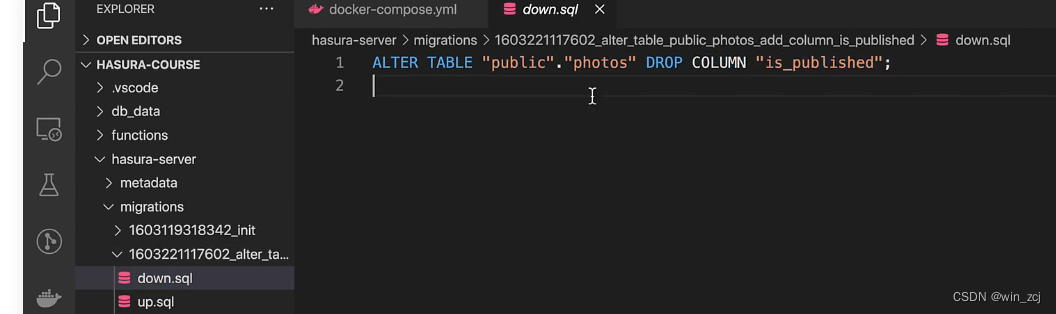
然后我们也可以去metadata文件夹下查看table.yml文件也发生了改变,因为我们修改了权限
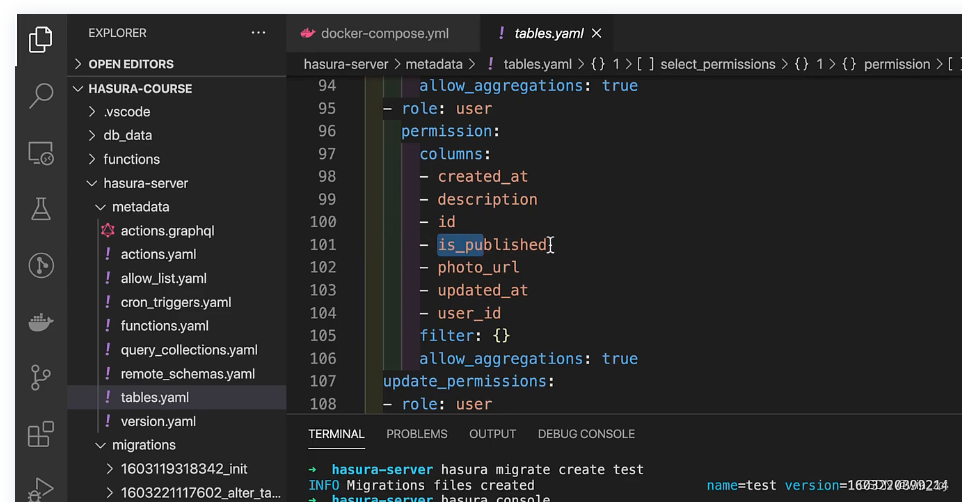
这种超级用法从hasura中得到,我们也可以在docker-compose中设置禁用的方式不能以这种方法去操作,HASURA_GRAPHQL_ENABLE_CONSOLE: "false"
7.多个迁移合并到一起
当我们在web服务控制台对数据库表进行修改,即使是一个很小的改动,但在hasura/migrations下都会产生一个迁移的文件夹,在实际工作中我们会有大量规模的改动,这样的话就会产生很多的迁移文件夹,而且管理起来会非常的困难,也很难理解哪些迁移属于哪个功能的。有一种方式,我们可以把这些迁移压缩成一个迁移文件,这样我们能够保留更少的文件,而且这种按功能分组的方式可以让我们更容易理解每一个具体迁移的意图,这就是hasura的一个迁移合并的功能
hasura migrate squash --name "test squash" --from 1603221117602
–name 后面需要写一些简单的注释,类似于git commit -m ‘注释’,写一些修改的内容之类的,–from是想要从哪个版本开始合并,hasura会提醒你是否要删除之前产生的迁移,yes,在实际生产中最好是不要选择立即删除,可以先测试一下合并后的迁移,在所有都正常的情况下再选择删除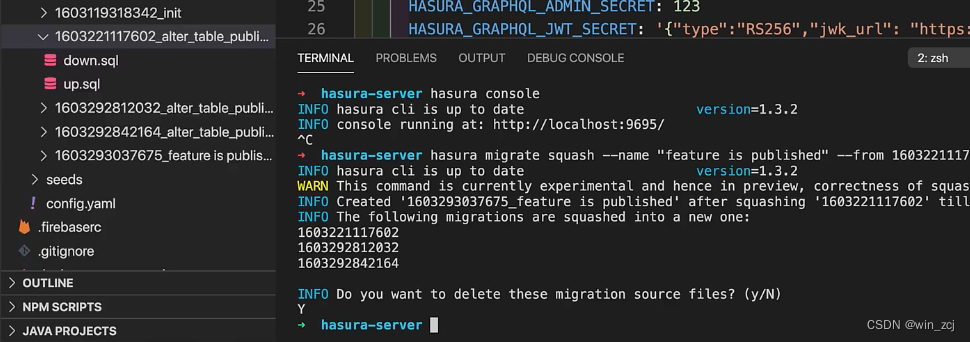 然后我可以看到之前产生的迁移已经合并成了一个
然后我可以看到之前产生的迁移已经合并成了一个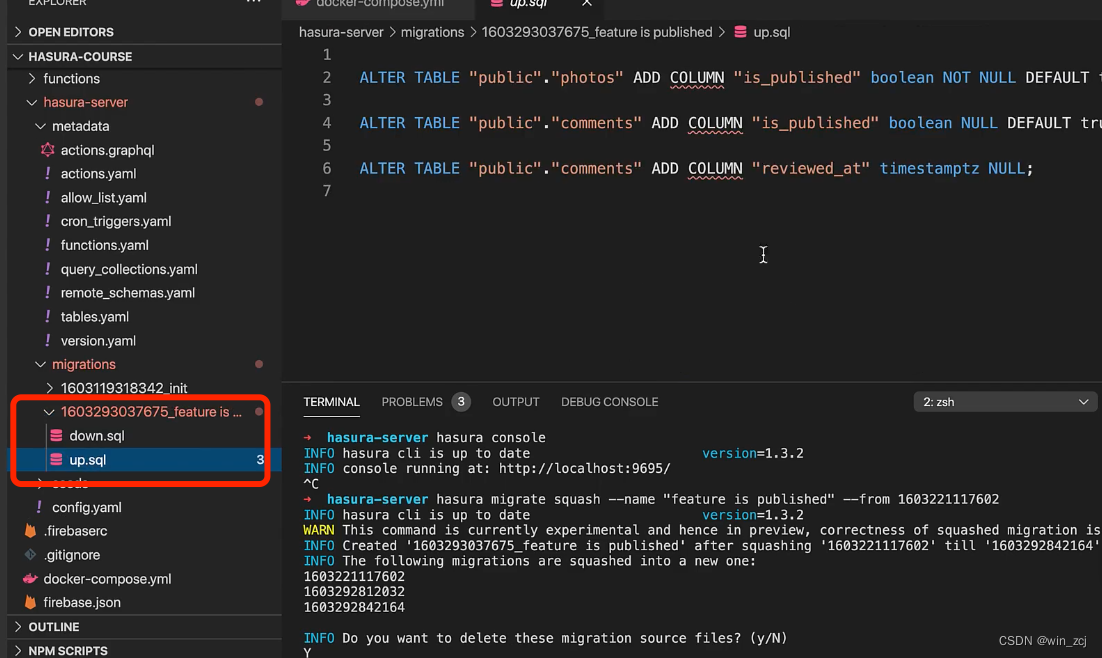
操作完成后我们必须要应用新的迁移,因为如果我们运行hasura migrate status时可以看到它并不存在于数据库中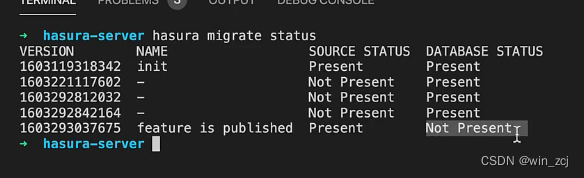
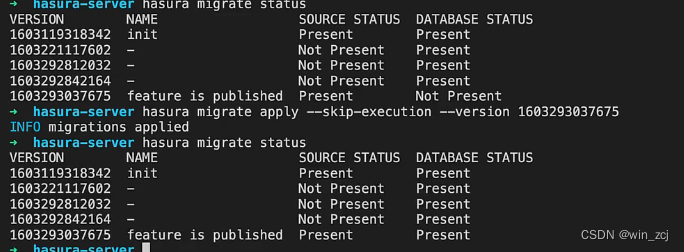
所以我们要执行应用命令应用到数据库中
hasura migrate apply --skip-execution --version 1603293037675
然后再次查看数据库状态的时候已经应用到数据库中了
8.数据备份和导入
如果我们想要把一个表里面的数据插入或者导入到同样结构的空表中应该怎么做呢,hasura有这样一个功能可以帮助我们来实现seeds
如果我们想要向某个表中导入数据我们可以使用hasura seed这个功能,
首先我们要创建一个空的导入文件hasura seeds create cities_feauture然后在终端命令行下可以随便输入一些插入命令 INSET INTO …
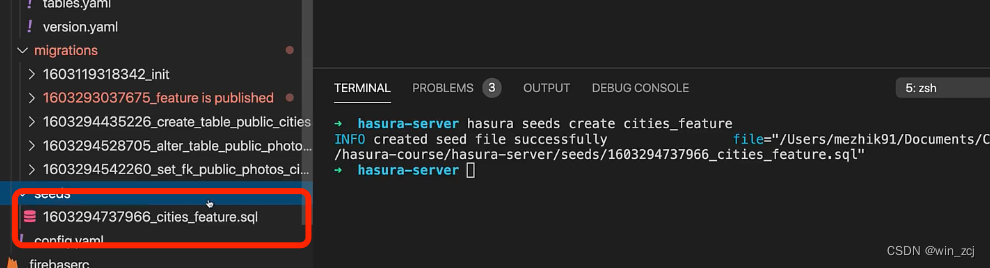
然后在seed文件夹下会产生一个sql文件,我们可以在sql文件里面编写或者粘贴插入数据的sql脚本语句。
我们也可以把某个表里面的数据导出来,然后再导入到新表中,比如城市这张表,
hasura seeds create cities_feauture --from-table cities
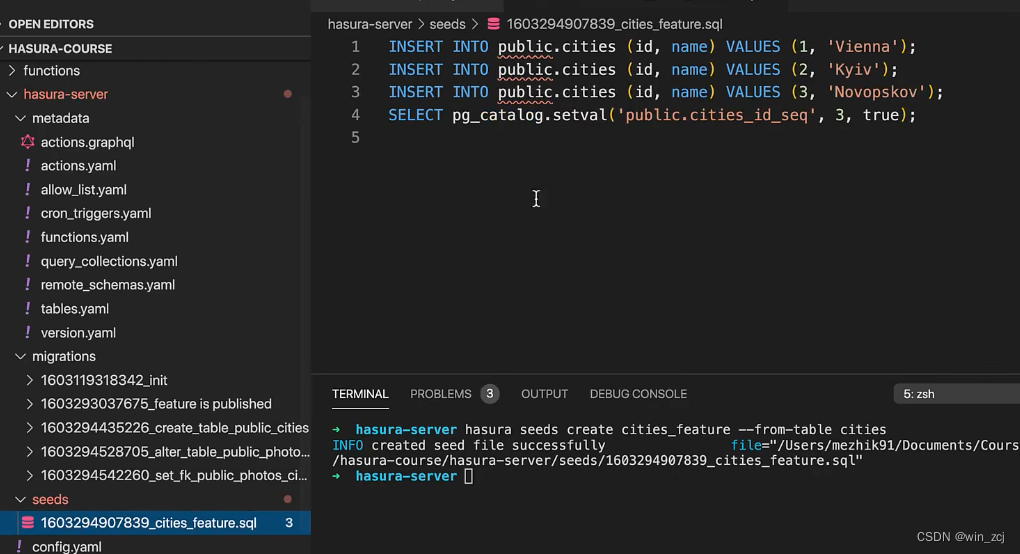
我们想要把自己写的插入sql语句或者导出来的数据插入到对应的表中,需要执行
hasura seeds apply
9.回滚
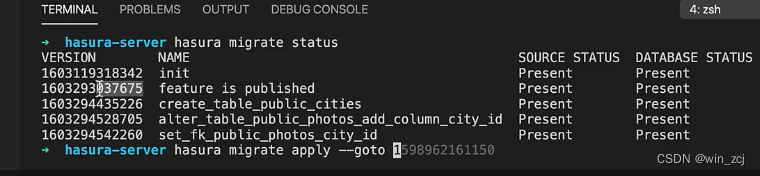
如果我们想要回滚到某一个数据迁移的版本,我需要在终端命令行执行
hasura migrate apply --goto [版本号]
例如:hasura migrate apply --goto 1603293037675
hasura将会执行版本号里面的down.sql文件里面的脚本,这时回到web服务界面查看版本号以后创建和修改的表已经不存在了,如果我们再想回到最新的版本只需要把版本号改成最新的就可以了,或者直接执行hasura migrate apply也会回到最新的版本状态,但不幸的是之前的数据已经被删除了,如果之前做过备份的话我们还可以利用seeds把原来的数据恢复回来 hasura seeds apply
另外,也可以使用hasura migrate apply --version ******* --type up/down进行回滚,如果不写–type类型默认是执行up


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









