







 本文介绍了如何使用JavaScript和Tesseract.js库在Web应用中实现图片文字识别功能,包括文件上传、图像预处理和实时文字识别,用户可以直接在图片上选中并复制文字,适用于文档管理等场景。
本文介绍了如何使用JavaScript和Tesseract.js库在Web应用中实现图片文字识别功能,包括文件上传、图像预处理和实时文字识别,用户可以直接在图片上选中并复制文字,适用于文档管理等场景。
如何直接选中复制图片中的文字:前端OCR实现指南
在现代Web开发中,从图片中提取文字是一个常见需求。无论是处理扫描的文档图片,还是用户上传的图片,通过OCR (光学字符识别) 技术,我们可以实现从图像中提取文字的功能。本文将详细介绍如何使用JavaScript(借助Tesseract.js库)从图片中提取,并可供复制的文字。
实现效果参考微信图片的图片文字识别。
第一步:页面布局与样式定义
我们的HTML页面包含基本的文件上传控件、进度条显示、以及用于展示图片和文字覆盖的容器。CSS用于简单设定进度条及图片展示的样式。
<input type="file" id="upload" accept="image/*">
<div id="progressContainer">
<div id="progressBar"></div>
</div>
<div id="textOverlays" style="position:relative;">
<img id="display" src="" alt="Uploaded Image" style="position: absolute;">
<canvas id="canvas" style="display:none;"></canvas>
</div>
第二步:文件上传与图像预处理
当用户选择文件后,我们通过FileReader对象将上传的图片文件转换为数据URL,然后使用<canvas>元素来对图片进行预处理。预处理的目的是调整图像的亮度阈值,以优化后续的文字识别过程。
document.getElementById('upload').addEventListener('change', function (event) {
var file = event.target.files[0];
var reader = new FileReader();
reader.onload = function (e) {
var img = new Image();
img.onload = function () {
var canvas = document.getElementById('canvas');
var ctx = canvas.getContext('2d');
canvas.width = img.width;
canvas.height = img.height;
ctx.drawImage(img, 0, 0);
/* 灰度与二值化过程 */
var imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
var data = imageData.data;
for (var i = 0; i < data.length; i += 4) {
var brightness = 0.34 * data[i] + 0.5 * data[i + 1] + 0.16 * data[i + 2];
var threshold = brightness < 128 ? 0 : 255;
data[i] = data[i + 1] = data[i + 2] = threshold;
}
ctx.putImageData(imageData, 0, 0);
document.getElementById('display').src = e.target.result;
};
img.src = e.target.result;
};
reader.readAsDataURL(file);
});
第三步:文字识别与展示
我们使用Tesseract.js库对处理后的图像进行OCR识别。识别过程中,实时更新进度条,并在识别完成后将识别的文字以覆盖在原图上的形式展示。这里我们动态创建<span>元素,绝对定位到原图对应文字的位置。
Tesseract.recognize(
canvas,
'chi_sim', // 指定中文简体进行识别
{
logger: m => {
console.log(m);
if (m.status === 'recognizing text') {
var progress = Math.floor(m.progress * 100);
document.getElementById('progressBar').style.width = progress + '%';
}
}
}
).then(({ data: { text, words } }) => {
for (let word of words) {
const el = document.createElement("span");
el.style.position = "absolute";
el.style.left = `${word.bbox.x0}px`;
el.style.top = `${word.bbox.y0}px`;
el.style.color = "red";
el.style.fontSize = `${word.font_size}px`;
el.textContent = word.text;
document.getElementById('textOverlays').appendChild(el);
}
});
完整代码实现
这里的代码可以直接复制到一个html文件中使用
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>IMG to Text OCR</title>
<style>
#progressBar {
width: 0%;
height: 20px;
background-color: green;
}
#progressContainer {
width: 100%;
background-color: #ddd;
}
</style>
</head>
<body>
<input type="file" id="upload" accept="image/*">
<div id="progressContainer">
<div id="progressBar"></div>
</div>
<div id="textOverlays" style="position:relative;">
<img id="display" src="" alt="Uploaded Image" style="position: absolute;user-select:none;">
<canvas id="canvas" style="display:none;"></canvas>
</div>
<script src="https://cdn.jsdelivr.net/npm/tesseract.js@2"></script>
<script>
document.getElementById('upload').addEventListener('change', function (event) {
var file = event.target.files[0];
var reader = new FileReader();
reader.onload = function (e) {
var img = new Image();
img.onload = function () {
var canvas = document.getElementById('canvas');
var ctx = canvas.getContext('2d');
canvas.width = img.width;
canvas.height = img.height;
ctx.drawImage(img, 0, 0);
var imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
var data = imageData.data;
for (var i = 0; i < data.length; i += 4) {
var brightness = 0.34 * data[i] + 0.5 * data[i + 1] + 0.16 * data[i + 2];
var threshold = brightness < 128 ? 0 : 255;
data[i] = data[i + 1] = data[i + 2] = threshold;
}
ctx.putImageData(imageData, 0, 0);
document.getElementById('display').src = e.target.result; // Display the original image
Tesseract.recognize(
canvas,
'chi_sim',
{
logger: m => {
console.log(m);
if (m.status === 'recognizing text') {
var progress = Math.floor(m.progress * 100);
document.getElementById('progressBar').style.width = progress + '%';
}
}
}
).then(({ data: { text, words } }) => {
for (let word of words) {
const el = document.createElement("span");
el.style.position = "absolute";
el.style.left = `${word.bbox.x0}px`;
el.style.top = `${word.bbox.y0}px`;
el.style.color = `rgba(0,0,0,0)`;
el.style.fontSize = `${((word.bbox.y1 - word.bbox.y0) + (word.bbox.x1 - word.bbox.x0))/2}px`;
el.textContent = word.text;
document.getElementById('textOverlays').appendChild(el);
}
});
};
img.src = e.target.result;
};
reader.readAsDataURL(file);
});
</script>
</body>
</html>
效果
1 选择一张本地图片,等待进度条完成
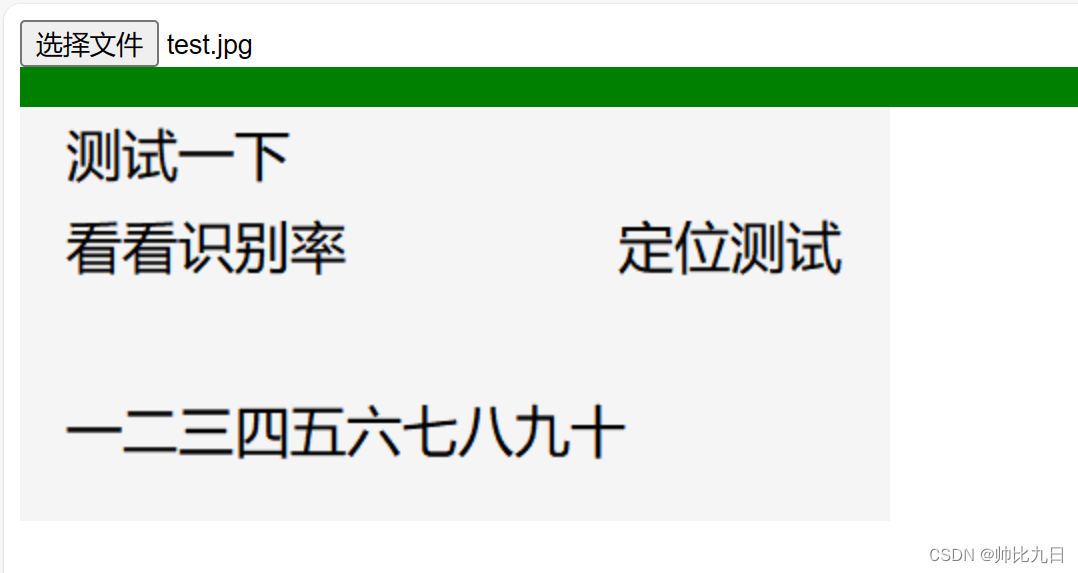
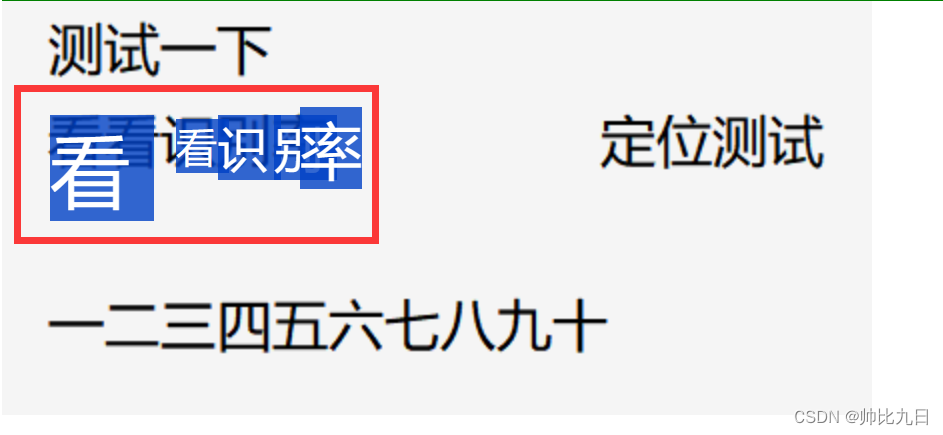
2 用鼠标选中文字区域
会发现图片中的文字已经被识别出来,并且定位到图片位置了。现在我们可以直接再图片上选中,并且复制文字
小结
通过这样的步骤,我们可以实现一个可以识别图片中文字并进行展示的Web应用。用户上传图片后,应用不仅显示文字识别的进程,更可以直接在图片上查看到识别后的文字,甚至可以支持选择和复制。这种技术可以广泛应用于文档管理系统、数据入库等多种场景。


















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









