






1谈谈你对面向对象的理解:
面向对象和面向过程经常拿来一起比较,面向过程 就是根据功能的实现逻辑,然后一步一步的设计方法完成。面向对象就是把里面每个对象抽象出来,定义它独属的方法,有点类似于模块化开发,对象只负责自己的方法。然后功能实现的时候就去调用对应对象的方法,这样相对于面向过程来说,它更容易复用维护和扩展,而面向过程的性能要高一些。
它有三个重要的性质:封装继承和多态。封装是指将具体的实现逻辑不对外开放,对外暴露方法名能让外部调用即可。继承,继承父类的方法然后子类可以进行拓展。多态:父类的引用指向子类的实例,这样可以调用子类实例的方法,更加灵活。
2 jdk,jre,jvm的区别和联系
jdk:java的开发工具,它是给java程序员用来开发程序用的。
jre:java运行时环境,程序运行时就需要用到jre。
jvm:java虚拟机,java代码能够一次编译,到处运行就是因为有jvm
Jdk包含jre包含jvm
程序员写的.java文件,然后javac编译为.class文件,然后把.class文件放到jvm上运行,jvm会把它变成机器语言。
3简述final的作用
修饰类:不可以被继承
修饰方法:不可以被子类覆盖,但是可用重载
修饰变量:表示常量,一旦被赋值就不能再被修改
成员变量:必须直接赋值或者构造器中赋值 或者代码块中赋值。
修饰局部变量:可以先声明,但是在使用之前一定要赋值
修饰引用类型:相当于绑定了地址值了,但是内容可用修改
4 重载和重写的区别
重载:同一个类中,方法名相同,参数类型可用不同,个数不同,顺序不同,方法返回值和访问修饰符可用不同,发生在编译时。
重写:发生在父子类中,方法名参数列表必须相同,返回值类型小于等于父类,抛出的异常范围小于等于父类,访问修饰符大于等于父类,父类方法如果修饰符为private,子类不能重写该方法
重载和返回值类型没有关系
//会报错 方法名相同 参数列表相同 返回值类型不同
public int a(){
return 5;
}
public String a(){
return "ahf";
}
5接口和抽象类的区别
1 抽象类可以存在普通成员函数,而接口只能存在public abstract方法
2抽象类的成员变量可用是各种类型 ,而接口的成员变量是public static final修饰
3抽象类只能继承一个,而接口可用实现多个
接口的设计目的:对外提供访问的,封装了内部的实现细节。,它规定了类的行为,但是没有规定具体的实现细节。
抽象类:本质是为了代码复用,当一些类具体有相同的行为时,我们就可以把相同的行为抽象为一个抽象类,不同的部分交由子类取实现,对类的通性的抽象。
所以,当我们关注事务的本质时,使用抽象类,关注具体的行为时使用接口。
6 List和set的区别
list:有序,可重复,按对象进入的顺序保存对象,允许出现多个Null对象,可以使用iterator取出所有元素,也可以通过下标取出元素
set:无序,不可重复 ,最多一个null对象,只能通过iterator取得所有元素。
7 hashcode和equals方法
hashcode和equals都是javaobject类的基本方法,在不重写的情况下:hashcode默认的值是堆中的内存地址 equal和==相同。
在使用时,也分情况,主要是两种情况:是否创建散列表
没有:比如New 两个相同的modle,如果传入相同的参数,那么它们的hashcode不同但是equals(重写过,比较内容)是相同的
如果创建了,那么hashcode也必须要重写,这样才能达到equals相同,然后hashcode相同的目的。可以用hashmap来举例,hashcode相同,分配到同一个位置,然后调equal比较内容是否相同。
8 arrylist和linkedList的区别
arrylist:动态数组,需要连续的内存存储空间,适合下标访问。扩容机制;默认是10 超过后会按1.5倍扩容,具体是新建一个数组,然后将老数组的内容拷贝到新数组中,插入数据时,如果不是尾插法,那么元素会往后移,然后再插入。如果尾插法,效率会非常好
linkedlist:基于链表实现的,可以使用分散的内存空间,适合数据
的修改,不适合查询,因为查询需要逐一的去遍历(迭代器或者for循环),而且不能使用indexof对其进行遍历,因为结构为空会遍历这个链表。
9 concureentHashMap原理
jdk7和8的区别
数据结构:reentrantLock+segment+hashentry 一个segment中包含一个hashenry数组,每个hashentry又是一个链表结构
元素查询时:二次hash。第一次定位到segment片段,第二次定位到元素所在链表的头部。
锁:segment分段锁继承了reentrantLock,锁定的时操作的segment,对其他的segemnt不影响,并发度就是segment的个数,可以通过构造函数知道,数组扩容不影响其他segment
get方法无需加锁,volate保证安全
jdk8:
数据结构:synchronized(扩容 hash冲突时用)+cas+node+红黑树 node的val和next都用volatie修饰,保证可见性,查找替换,赋值操作都使用cas
锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,扩容时,阻塞所有的读写操作,并发扩容。
读操作无锁:node的val和next使用volatile修晒,读写线程对该变量的互相可见,数组用volatile修饰,保证扩容时被线程感知。
总结相比于1.7 1.8锁的粒度更细。1.7分段锁锁住sehment片段,1.8是用synchronized锁链表的头部,volatile锁next和val
10如何实现一个ioc容器
1配置文件配置包扫描路径
2 递归包扫描获取class文件
3反射,确定需要交给ioc管理的表
4对需要注入的类进行依赖注入
11 什么是字节码?采用字节码的好处是什么
我们写的源代码—》编译后(java.c编译)生成.class文件(字节码)—》在jvm上运行,然后被解释为机器可用执行的二进制代码—》机器运行该二进制代码
好处:编译一次就可以在多种不同的计算机上面运行
12 java的类加载器有哪些
jdk自带三个类加载器:bootstrap classloader(爷) extclassloader(父) appclassloader(当前)并不是直接继承:中间通过一个变量来维护,继承classloader可以自定义类加载器
13 双亲委托模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6JuE0kWG-1615612234831)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210306130600642.png)]
解释:向上委派和向下查找,拿到一个类的时候向上委派,查找缓存,找到了就返回,没有找到就继续往上找,到顶了(boostrap)还没有,那就向下查找,找到了就返回,没有找到就继续向下,到了app一般就可以找到了。
14 java中的异常体系
顶级父类:throwable有两个子类:exception和error
error:程序无法处理的错误,一旦出现该错误,程序被迫停止运行
exception不会导致程序停止,又分为运行时异常和检查异常
运行时异常发生在程序运行中,会导致程序当前线程执行失败,检查异常常常发生在程序编译过程中,会导致程序编译不通过。
15 gc如何判断对象可以被回收
引用技术法:每个对象都有一个引用技术属性,新增一个引用时计数+1,引用释放时计数减一,计数为0时,表示可回收
可达性分析法(java采用 要标记两次):从gc root开始向下搜索,搜索所走过的路径为引用链,当一个对象到gc roots没有任何引用链相连时,则证明此对象是不可用的,那么虚拟机就判断是可回收对象。
gcroot对象:栈中引用对象 方法区静态属性引用对象 常量引用的对象 本地方法栈引用的对象
16线程的生命周期
线程有五种状态:创建 就绪(start方法) 运行 阻塞 和死亡
阻塞有三种:
等待阻塞:线程执行wait方法,然后释放占用的所有资源,线程被放入等待池中,只能通过notify唤醒
同步阻塞:线程在获取对象的锁的时候,锁被其他线程占用,那么jvm会把线程放入锁池
其他阻塞:执行sleep jion的方法 或发出io请求时等待io处理完毕。
17 sleep() wait() join() yield()的区别
锁池:所有竞争同步锁的线程都会放在锁池中
等待池:调用wait方法后会把线程放进等待池中,等待池中的线程不回去竞争同步锁
sleep:thread类的本地静态方法,wait是object类的本地方法
sleep不会释放锁,wait会释放锁,然后会把线程放入等待池中。
join:线程进入阻塞状态
yield():让当前线程进入就绪状态
18 说说你对线程安全的理解
我们说的线程安全其实是指内存安全,堆是共享内存,可以被所有线程访问。
堆:是进程和线程共有的空间,分为全局堆和局部堆,全局堆就是所有没有分配的空间,局部堆就是分配给用户的空间,堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是用完了要还给系统,否则就是内存泄漏。
栈是每个线程独有的,保存其运行状态和局部自动变量的,栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是线程安全的,操作系统在切换线程的时候自动切换栈,栈空间不需要再高级序言里面显示的分配和释放。
19 说说你对守护线程的理解
守护线程是对非守护线程提供服务的线程,守护的是jvm所有的非 守护线程。
守护线程的终止自身是无法控制的,所以不要把io,file等重要操作的逻辑分配给它
应用场景:为其他线程提供服务支持 ,如果要求程序结束时,线程必须正常的关闭就可以把该线程作为守护线程来使用,
守护线程中产生的新线程也是守护线程。
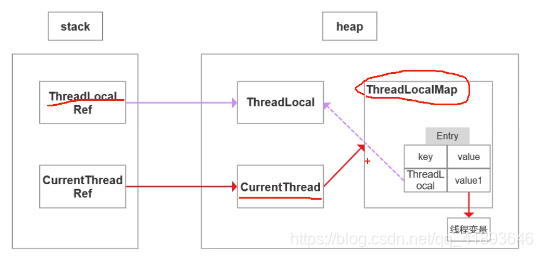
20 threadLocal的原理和使用场景
每一个对象均含有一个threadlocalmap类型的成员变量,它存储本线程所有threadLocal对象及其对应的值。
threadlocalmap由一个个entry对象构成,entry有threadlocal对象和object构成。entry的key就是threadlocal对象,并且是一个弱引用。当没有指向key的强引用后,可以就会被垃圾回收器回收。
执行set方法时,threadlocal会先获取当前线程对象,然后获取当前线程的threadlocalmap对象,然后以threadlocalmap为key,将值存进threadlocalmap中。
get方法类似。threadlocal首先会获取当前线程对象,然后获取当前线程的threadloaclmap对象,再以threadlocal对象为key,获取对应的value。
由于每一条线程均含有各自私有的threadlocalmap容器,所以是线程安全的。
使用场景:
1 在进行对象跨层传递的时候,使用threadlocal可以避免多次传递,打破层次间的约束。
2 线程间的数据隔离
3 进行事物操作,用于存储线程事务信息
4数据库链接,sessio会话管理
21 threadlocal内存泄露的原因,如何避免?
不会再被使用的对象或者变量占用的内存不能被回收,就是内存泄漏。
强引用:最常使用的引用(new),一个对象如果具有强引用,那么就不会被垃圾回收器回收,当内存空间不足,宁愿跑出oom也不会回收这个对象。如果想取消这个强引用,那可以把对象赋值为null,那么合适的时候jvm就会回收这个对象
弱引用:jvm在进行垃圾回收时,弱引用的对象就会被回收。
内存泄露:以threadlocal为弱引用key的entry,如果外部threadloca不存在强引用,那么gc会回收这个key,但是不能回收这个object值,所以就会出现内存泄露,
解决方法:手动调用remove方法清除value值
22 并发 并行 串行的区别
并发:一段时间内有多个线程在执行(单核)
并行:一个时间点有多个线程在执行(多核)
串行:按照顺序来运行,前一个任务没有运行完毕,下一个任务就只能等着。
23 并发的三大特性
原子性:一个操作中cpu不可以中途暂停,然后调度,即不被中断操作,要不全部执行完成,要不都不执行(比如转账,a给b转1000,那a必须减少1000 b必须增加1000)
//分析i++为什么线程不安全 执行i++ 假设i=0 原子+可见就可以实现线程安全 atomicInteger可以让i++安全:volatie(可见+有序)+cas(原子性)
1 将i从主存读到工作内存的副本中
2 将i+1
3 将结果写入工作内存du
//分析:如果不能保证原子性,即123可以分步来操作,那么线程1 2 读取结果都是0,然后完成i+1,写入工作内存后 i的值都是1 这个很明显不对,我们需要让+2次的结果变为2.
//如果保证了原子性,但是不保证可见性。那么线程1即使完成原子操作,但是结果还没有刷进主存中的时候,线程2读取i的结果任然为0,那么它操作后的结果任然为1,这显然时不对的。
4 将工作内存的值刷回主存(这一步是由操作系统来完成的,不确定)
可见性:当多个线程访问一个变量时,一个线程修改了这个变量的值,其他线程立刻看得到修改的值 涉及到两个协议:总线和mesi(缓存一致性协议)这两个协议使得1234步都为原子性操作
有序性:不允许出现指令重排(单线程操作结果不变),如果下面的代码的业务逻辑要依赖上面的代码,那么多线程情况下指令重排就会不安全
补充一下:volatie经常用来修饰对象(new 对象时如果发生指令重排是可能出现返回一个空对象的情况的)
//new一个对象
1 分配一个空间
2 给对象赋值
3 栈中的变量指向对象//指令重排 1 3就返回了 没有给对象赋值。
24 为什么要使用线程池 ,解释一下线程池参数
1 降低资源消耗,提高线程利用率,降低创建和销毁线程的消耗
2提高响应速度:直接就有线程在等待执行,而不需要我们去创建线程
3提高线程的可管理性:线程是稀缺资源,使用线程池可以统一分配调优监控。
参数:核心线程数 最大线程数 超时等待时间(回收非核心线程用的) 时间的单位 任务队列 线程工厂 和拒绝策略
如果来任务了,线程还没有到核心线程数,那就创建线程直到核心线程被创建,如果核心线程数满了,那就把新来的任务放进任务队列中,当任务队列满了,就创建线程直到最大线程数。当最大线程数任务队列也满了,那就使用拒绝策略。
25 线程池中阻塞队列的作用?为什么先添加到队列,而不是先创建最大线程?
1 阻塞队列和一般队列不同,如果一般队列(有限长度的缓冲区)满了,新来的任务是加不进队列中的,那么数据就无法保存,而阻塞可以把任务阻塞,然后保留要入队的任务。
阻塞队列可以使得当任务队列没有任务时,核心线程进入等待池中等待,释放cpu资源。它还自带唤醒功能,在有任务入队的时候就会唤醒线程进行处理。
2 在创建新线程的时候,是要获取全局锁的,这时候其他的线程就得阻塞,影响了整体效果。核心线程可以看作正式员工,非核心可以看成外包。当新任务来了,是可以压一压让正式员工干的,如果超过正式工的极限才会请外包。
26 线程池线程复用原理
线程池是将线程和任务解耦(分开),在线程池中,同一个线程可以不断得获取任务来执行,原理就是 线程池对thread进行了封装,并不是每次执行任务都会调优Thread.start()来启动线程,而是让每个线程去执行一个循环任务,在这个循环任务中不停检查是否有任务需要执行,如果有则直接执行,也就是调优任务中的run方法,将run方法当成一个普通的方法执行,通过这种方式只使用固定线程就将所有的任务的run方法串联起来。
27 什么是spring?
spring是一个容器框架,用来装javabean(java对象),中间层框架可以起一个连接作用,可以让企业开发更快更简洁:
spring是一个控制反转和面向切面的容器框架
1 从大小和开销上来说都是轻量级的
2通过控制反转的技术达到松耦合
3提供了面向切面的丰富支持,允许通过分离应用的业务逻辑和系统级服务进行内聚性开发
4包含并管理应用对象(bean)的配置和生命周期,说明是个容器
5将简单的组件配置,组合成为一个复杂的应用,这个意义上来说是一个框架。
28 谈谈你对aop的理解
系统是由许多不同的组件组成的,每一个组件负责一块特定功能,除了实现自身核心功能之外,这些组件还要实现一些额外的职责:比如日志,事务管理和安全 这样核心服务经常要融入到自身具有核心业务逻辑的组件中去,这些系统服务经常被称为横切关注点,因为它们会跨越系统的多个组件。
所以像我们需要为分散的对象引入公共行为的时候,使用面向对象编程的话就会使得代码重复度很高。比如实现日志功能
日志代码往往水平的分散在所有对象层次中,而与它锁散步到的对象的核心功能毫无关系。
aop:将程序的交叉业务逻辑(比如安全 日志 事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去,aop可以对某个对象或某些对象的功能进行增强,比如对象中的方法进行增强,可以执行某个方法之前额外的做一些事情,在某个方法执行之后额外的做一些事情。
29谈谈你对ioc的理解
容器概念 控制反转 依赖注入
ioc容器:实际上就是个map(key,value),里面存的是各种对象(xml里配置的bean节点@repository,@service,@controller,@compent),在项目启动的时候会读取配置文件里面的bean节点,根据全限定类名使用反射创建对象放到map里,扫描到打上上述注解的类还是反射创建对象放到map里面。
这个时候map里就有各种对象了,接下来我们在代码里需要用到里面的对象时,再通过di注入(autowired resource xml里bean节点内的ref属性,项目启动的时候会读取xml节点ref属性根据id注入,也会扫描这些注解,根据类型或id注入:id就是对象名)
控制反转:没有引入ioc容器之前,对象a依赖于对象b,那么对象a在初始化或者运行到某一点的时候,自己必须注定去创建b或者使用已经创建的对象,无论是创建还是使用对象b,控制权都在自己手上。
引入ioc容器之后,对象a与对象b之间失去了直接联系,当对象a运行到需要的对象b的时候,ioc容器会主动创建一个对象b注入到对象a需要的地方。
通过前后的对比,不难看出对象a获得对象b的过程由主动行为变为了被动,控制权颠倒过来了,这就是控制反转这个名称的由来。
全部的对象控制权全部上缴给第三方ioc容器,所以ioc容器成了整个系统的关键核心。它起到一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个粘合剂,对象与对象之间会彼此失去联系,这就是有人把ioc容器比喻为粘合剂的由来。
30 beanfactory和applicationcontext有什么区别
applicationcontext是beanfactory的子接口
applicationcontext提供了更完整的功能
1 继承messagesource 因此支持国际化
2统一资源文件访问方式
3提供在监听器中注册bean的事件
4同时加载多个配置文件
5载入多个(有继承关系)上下文,使得每一个上下文都专注于一个特定的层次,比如web层。
beanfactory采用的是延迟加载形式来注入bean,即只有在使用到某个bean时,才对该bean进行加载实例化。这样我们就不能发现一些存在的spring的配置问题。如果bean的某一个属性没有注入,beanfactory加载后,直到第一次使用调用getbean方法才会抛出异常。
applicationcontext:它是在容器启动时,一次性创建了所有的bean。这样,在容器启动时,我们就可以发i西安spring中存在的配置错误,这样有利于检查所依赖的属性是否注入。applicationcontext启动后预加载入所有的单实例bean,通过与载入单实例bean,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
相对于基本的beanfactory,applicationcontext唯一的不足是占用内存空间。当应用程序配置bean较多时。程序启动较慢。
beanfactory通常以编程的方式被创建,applicationcontext还能以声明的方式创建,如使用contextloader
beanFactory和applicationcontext都支持beanPostprocessor的使用,但两者的区别是:beanfactory需要手动注册,而application则是自动注册。
31 描述一下springbean的生命周期
1解析类得到beanDefinition
2如果有多个构造方法,则要推断构造方法
3确定好构造方法后,进行实例化得到一个对象
4对对象中的加了@autowired注解的属性进行属性填充(依赖注入)
5回调aware方法,比如beanNameAware,beanfactoryaware
6调用beanpostprocessor的初始化前的方法
7调用初始化方法
8调用beanpostprocessor的初始化后的方法,在这里会进行aop
9如果当前创建的bean是单例的则会把bean放入单例池中。
10使用bean
11 spring 容器关闭时调用disposablebean中的distory方法。
32 spring支持的几种bean的作用域
singleton:默认 每个容器只有一个bean的实例,单例的模式由beanfactory自身来维护,该对象的对象周期是与spring ioc容器一致的(单在第一次被注入时创建)。
prototype为每一个bean请求提供一个实例,在每次注入时都会创建一个新的对象。
request:bean被定义为在每个http请求中创建一个单列对象,也就是说在单个请求都会复用这一个单例对象
seesion:与request范围类似,确保每个session中有一个bean实例,在session中有一个bean实例,在session过期后,bean会随之失效。
application:bean被定义为servletContext的生命周期中复用一个单例对象
websocket:bean被定义为websocket的生命周期中复用一个单例对象。
gloal-session:全局作用域,global-session和portle应用相关。当你的应用部署在protket容器中工作时,它包含很多portlet,如果你想要声明让所有的portlet共有全局的存储变量的话,那么这全局变量需要存储在global-session。全局作用域与servlet中的session作用域效果相同。
33spring框架中的单例bean是线程安全的吗?
不是线程安全的,框架并没有对bean进行多线程处理。
如果bean是有状态的,那就需要开发人员自己来进行线程安全的保证,最简单的办法就是改变bean作用域,把singleton改为property这样每次请求bean就相当于new bean(),这样就可以保证线程安全
有状态就是有数据存储功能,无数据就是不会保存数据 controller service 和dao层本身不是线程安全的,如果只是调用里面的方法,而且多线程调用一个实例的方法,会在内存中复制彬良,这是自己的线程的工作内存,是安全的。
dao会操作数据库connection,connection是带有状态的,比如数据库事务.spring事务管理使用threadlocal为不同线程维护了一套独立的connection副本,保证线程之间不会互相影响(spring 是如何保证事务获取同一个connection的)
不要在bean声明任何有状态的实例变量或类变量,如果必须如此,那么就是要threadlocal把变量变为线程私有的,如果bean的实例变量或类变量需要在多个线程之间共享,那么就只能使用synchronized lock cas等这些实现线程同步的方法了。
34 谈谈你对进程线程的理解
我对进程和线程的理解是循序渐进的,在刚学多线程的时候了解到了这个进程和线程。这里的解释是“进程是资源执行的基本单位,线程是轻量级进程。一个进程可以有多个线程,它们都周期基本相同:创建 就绪 运行 阻塞 销毁这几个状态,进程和线程之间都可以进行对应的通信。后来学习了操作系统,才算真的了解了进线程。进程的解释是:程序动态的执行的一次过程,这里把进程与程序做了一个对比。程序是静态的一段代码,进程则是动态的,它包括了程序运行时的所有信息,包括代码,操作的数据,寄存器等内容。进程在cpu的数据结构叫做pcb,进程控制块。它有三大部分组成:标识符 状态信息,和控制信息。至于线程,我们要理解线程是怎么来的,来干什么。这里与进程作比较,进程是一块一块的内存空间,最初的时候,一个服务的进程只有一个(性能不好),含有许多的功能,后来为了把这些功能分开,又创建了多个进程(开销就很大)。这时候我们想要一种可以并发执行,而且共享相同地址空间的策略,这时候线程就出来了。进程=线程+资源控制,线程是一条执行的流程,但是它也有缺陷,就是一个线程如果崩了,那么进程所属的线程都会崩。
35 spring框架中都用到了哪些设计模式
1简单工厂:由一个工厂类根据传入的参数,动态决定应该创建哪一类产品,spring中的beanfactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否再传入参数前创建对象还是要根据具体的情况来决定。
工厂方法:实现了factorybean接口的bean是一类叫做factory的bean,其特点是spring会在使用getbean()调用获得该bean时,会自动调用该bean的getobject()方法,所以返回的不是factory这个bean,而是这个bean.getObject()方法的返回值
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring对单列的实现,spring中的单例模式完成了后半句话,即提供全局的访问点beanfactory,单没有从构造器级别去控制单例,这是因为spring管理的是任意java对象。
适配器模式:spring定义了一个适配接口,使得每一个controller有一个对应的适配器实现类,让适配器代替controller执行相应的方法,这样在拓展controller时,只需要增加一个适配器类就完成了springmvc的拓展了。
装饰器模式:动态地给一个对象添加一些额外的职责,就增加功能来说,decorator模式相比生产子类更为灵活。spring中用到的包装器模式在类名有两种表现,一种时类名中含义wrapper,另一种时类名中含义decorator
动态代理模式:切面在应用运行的时候织入,一般情况下,在织入漆面时,aop容器会为目标对象动态的创建一个代理对象,springaop就是以这种方式织入切面的。
织入:把切面应用到目标对象并创建新的代理对象的过程
观察者模式:spring的事件驱动模型使用的是 观察者模式,spring中observer模式常用的地方是listener的实现
策略模式:spring框架的资源访问resource接口,该接口提供了更强的资源访问能力,spring跨级本身大量使用了resource接口来访问底层资源。
36 spirng事务的实现方式
在使用spring框架时,可以有两种使用事务的方式,一种时编程Ⅹ的,一种时声明式的。@transactional注解就是声明式的。
首先,事务的这个概念式数据库层面的,spring只是基于数据库中的事务进行了拓展,以及提供了一些能让程序员更加方便操作事务的方式。
比如我们可以通过在某个方法上添加@transactional注解,就可以开启事务,这个方法中所有的sql都会在一个事务中执行,统一失败或成功。
在一个方法上加了@transactional注解后,spring会基于这个类生成一个代理对象,会将这个代理对象作为bean,当在使用这个代理对象的方法时,如果这个放啊上存在这个注解,那么代理逻辑会把事务自动提交设置为false,然后再去执行原本的业务逻辑方法,如果执行业务逻辑方法没有出现异常,那么代理逻辑中就会把事务进行提交,如果执行业务逻辑方法出现了异常,那么就会将事务进行回滚。当然,针对哪些回滚的事务是可以配置的,可以利用@transactional注解中的rollbackfor属性进行配置,默认情况下回对runtimeexception和error进行回滚















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









